The Mean of the Sample Mean|Standard Deviation of the Sample Mean|SE
7.2 The Mean and Standard Deviation of the Sample Mean
Recall that the mean of a variable is denoted μ, subscripted if necessary with the letter representing the variable. So the mean of x is written as μx , the mean of y as μy , and so on. In particular, then, the mean of x¯ is written as μx¯; similarly, the standard deviation of x¯ is written as σx¯.
There is a simple relationship between the mean of the variable x¯ and the mean of the variable under consideration: They are equal, or μx¯ = μ.
Example:
Sample size:2
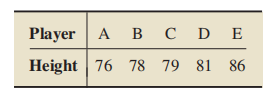
The mean of population:
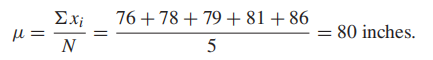
基于:
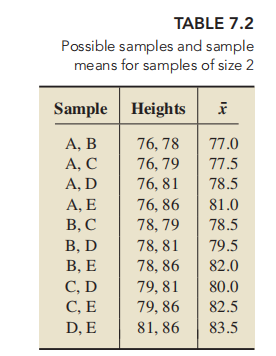
Mean of the Sample Mean:

所以:

Standard Deviation of the Sample Mean:(研究population 方差与sample mean的方差的关系)
Standard Deviation of population:
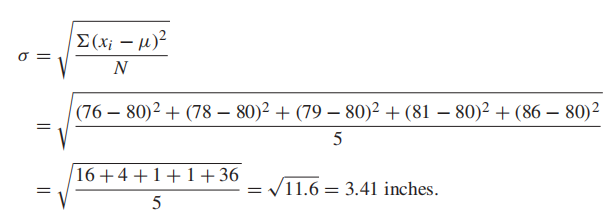
Standard Deviation of the Sample Mean:
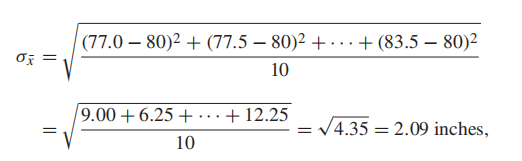
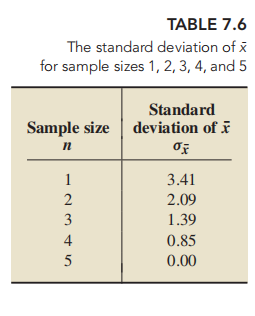
the standard deviation of x¯ gets smaller as the sample size gets larger.(因为公式二中n作为分母,方差随分母变小而变大)
When sampling is done without replacement from a finite population(无放回是指每次抽取的两个样本绝不相同,eg,76,78;所以本例中是无放回)

When sampling is done with replacement from a finite population(有放回是指每次抽取的两个样本有可能相同,eg,76,76)
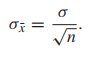
When the sample size is small relative to the population size, there is little difference between sampling with and without replacement.(极端值便是每次抽一个样本,放回和不放回都一样)
As a rule of thumb, we say that the sample size is small relative to the population size if the size of the sample does not exceed 5% of the size of the population (n ≤ 0.05N)
因为实际操作来说,我们能取到得样本数绝对远小于population,所以本书中使用公式二近似公式一
In most practical applications, the sample size is small relative to the population size, so in this book, we use the second formula only
This explains mathematically why the standard deviation of x¯ decreases as the sample size increases.
所以,采用更大sample size对于估计总体均值有帮助:
1.The larger the sample size, the smaller is the standard deviation of x¯.
2.The smaller the standard deviation of x¯, the more closely the possible values of x¯(the possible sample means) cluster around the mean of x¯.
3.The mean of x¯ equals the population mean.
the standard error of x¯变少,所以,sample errors 变少, 所以在这里引入标准差:In general, the standard deviation of a statistic used to estimate a parameter is called the standard error (SE) of the statistic.
The Mean of the Sample Mean|Standard Deviation of the Sample Mean|SE的更多相关文章
- 对于随机变量的标准差standard deviation、样本标准差sample standard deviation、标准误差standard error的解释
参考:http://blog.csdn.net/ysuncn/article/details/1749729
- range|Sample Standard Deviation|标准差几何意义
Measures of Variation 方差:measures of variation or measures of spread 源于range发现range不足以评估整个set(因为只用到l ...
- How to Find the Standard Deviation in Minitab
Standard deviation, represented by the Greek Letter sigma σ, is a measure of dispersement in statist ...
- Mean, Median, Mode, Range, and Standard Deviation
Descriptive statistics tell you about the distribution of data points in data set. The most common m ...
- 标准差(standard deviation)和标准误差(standard error)你能解释清楚吗?
by:ysuncn(欢迎转载,请注明原创信息) 什么是标准差(standard deviation)呢?依据国际标准化组织(ISO)的定义:标准差σ是方差σ2的正平方根:而方差是随机变量期望的二次偏差 ...
- 标准差(standard deviation)和标准错误(standard error)你能解释一下?
by:ysuncn(欢迎转载,转载请注明原始消息) 什么是标准差(standard deviation)呢?依据国际标准化组织(ISO)的定义:标准差σ是方差σ2的正平方根.而方差是随机变量期望的二次 ...
- 方差(variance)、标准差(Standard Deviation)、均方差、均方根值(RMS)、均方误差(MSE)、均方根误差(RMSE)
方差(variance).标准差(Standard Deviation).均方差.均方根值(RMS).均方误差(MSE).均方根误差(RMSE) 2017年10月08日 11:18:54 cqfdcw ...
- Mathematics | Mean, Variance and Standard Deviation
Mean is average of a given set of data. Let us consider below example These eight data points have t ...
- 均方根值(RMS)+ 均方根误差(RMSE)+标准差(Standard Deviation)
均方根值(RMS)+ 均方根误差(RMSE)+标准差(Standard Deviation) 1.均方根值(RMS)也称作为效值,它的计算方法是先平方.再平均.然后开方. 2.均方根误差,它是观测值 ...
随机推荐
- js获取指定日期n天之后的日期
function addDays(date, days,seperator='-') { let oDate = new Date(date).valueOf(); let nDate = oDate ...
- Django1.11序列化与反序列化
django序列化与反序列化 from rest_framwork import serializers serializers.ModelSerializer 模型类序列化器,必须依据模型类创建序列 ...
- 18个Java8日期处理的实践,太有用了
专注于Java领域优质技术,欢迎关注 作者:胖先森 Java 8 推出了全新的日期时间API,在教程中我们将通过一些简单的实例来学习如何使用新API. Java处理日期.日历和时间的方式一直为社区所诟 ...
- Thread--synchronized不能被继承?!?!!!
参考:http://bbs.csdn.net/topics/380248188 其实真相是这样的,“synchronized不能被继承”,这句话有2种不同意思,一种是比较正常的.很容易让人想到的意思: ...
- Java开学测试感想
开学第一堂课就是测试,测试暑假的自学成果,老师说试卷适当提高了难度,所以允许查书和使用网络查询,经过近三个钟头的努力奋斗和痛苦挣扎,我只完成了一小部分的代码,只有简单的set()get()函数,以及简 ...
- Excel Old format or invalid type library 错误原因
Old format or invalid type library 错误原因 调用excel方法失败,Old format or invalid type library 解决方案: 1,这是Exc ...
- 完整注册登陆php源码,附带session验证。
1.首先先写表单页面login.html. <!DOCTYPE html> <html lang="en"> <head> <me ...
- 计蒜客 置换的玩笑(DFS)
传送门 题目大意: 小蒜头又调皮了.这一次,姐姐的实验报告惨遭毒手. 姐姐的实验报告上原本记录着从 1 到 n 的序列,任意两个数字间用空格间隔.但是“坑姐”的蒜头居然把数字间的空格都给删掉了,整个数 ...
- catalina.out日志膨胀问题解决实例,日志门面commons-logging的实践
声明:迁移自本人CSDN博客https://blog.csdn.net/u013365635 笔者在公司的时候,遇到一个问题,2个模块A.B Tomcat中的catalina.out及catalina ...
- PAT Advanced A1104 Sum of Number Segments (20) [数学问题]
题目 Given a sequence of positive numbers, a segment is defined to be a consecutive subsequence. For e ...