吴裕雄--天生自然python机器学习:支持向量机SVM
基于最大间隔分隔数据

import matplotlib
import matplotlib.pyplot as plt from numpy import * xcord0 = []
ycord0 = []
xcord1 = []
ycord1 = []
markers =[]
colors =[]
fr = open('F:\\machinelearninginaction\\Ch06\\testSet.txt')#this file was generated by 2normalGen.py
for line in fr.readlines():
lineSplit = line.strip().split('\t')
xPt = float(lineSplit[0])
yPt = float(lineSplit[1])
label = int(lineSplit[2])
if (label == 0):
xcord0.append(xPt)
ycord0.append(yPt)
else:
xcord1.append(xPt)
ycord1.append(yPt) fr.close()
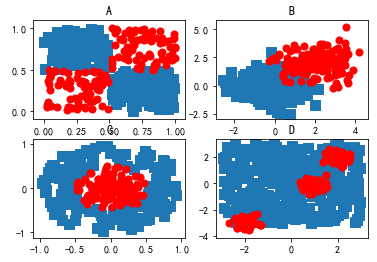
fig = plt.figure()
ax = fig.add_subplot(221)
xcord0 = []; ycord0 = []; xcord1 = []; ycord1 = []
for i in range(300):
[x,y] = random.uniform(0,1,2)
if ((x > 0.5) and (y < 0.5)) or ((x < 0.5) and (y > 0.5)):
xcord0.append(x); ycord0.append(y)
else:
xcord1.append(x); ycord1.append(y)
ax.scatter(xcord0,ycord0, marker='s', s=90)
ax.scatter(xcord1,ycord1, marker='o', s=50, c='red')
plt.title('A')
ax = fig.add_subplot(222)
xcord0 = random.standard_normal(150); ycord0 = random.standard_normal(150)
xcord1 = random.standard_normal(150)+2.0; ycord1 = random.standard_normal(150)+2.0
ax.scatter(xcord0,ycord0, marker='s', s=90)
ax.scatter(xcord1,ycord1, marker='o', s=50, c='red')
plt.title('B')
ax = fig.add_subplot(223)
xcord0 = []
ycord0 = []
xcord1 = []
ycord1 = []
for i in range(300):
[x,y] = random.uniform(0,1,2)
if (x > 0.5):
xcord0.append(x*cos(2.0*pi*y)); ycord0.append(x*sin(2.0*pi*y))
else:
xcord1.append(x*cos(2.0*pi*y)); ycord1.append(x*sin(2.0*pi*y))
ax.scatter(xcord0,ycord0, marker='s', s=90)
ax.scatter(xcord1,ycord1, marker='o', s=50, c='red')
plt.title('C')
ax = fig.add_subplot(224)
xcord1 = zeros(150); ycord1 = zeros(150)
xcord0 = random.uniform(-3,3,350); ycord0 = random.uniform(-3,3,350);
xcord1[0:50] = 0.3*random.standard_normal(50)+2.0; ycord1[0:50] = 0.3*random.standard_normal(50)+2.0 xcord1[50:100] = 0.3*random.standard_normal(50)-2.0; ycord1[50:100] = 0.3*random.standard_normal(50)-3.0 xcord1[100:150] = 0.3*random.standard_normal(50)+1.0; ycord1[100:150] = 0.3*random.standard_normal(50)
ax.scatter(xcord0,ycord0, marker='s', s=90)
ax.scatter(xcord1,ycord1, marker='o', s=50, c='red')
plt.title('D')
plt.show()


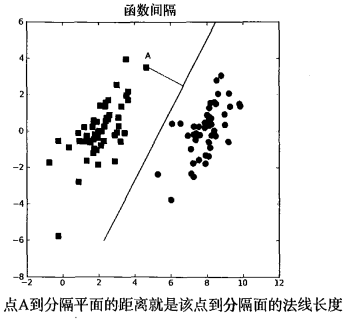
寻找最大间隔
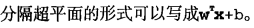
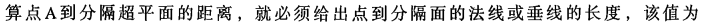
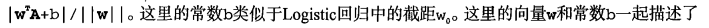

分类器求解的优化问题
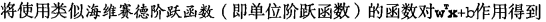
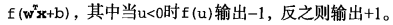
这里的类别标签为什么采用-1和+1,而不是0和 1呢?这是由于-1和+1仅仅相差一个符号,
方便数学上的处理。我们可以通过一个统一公式来表示间隔或者数据点到分隔超平面的距离,同
时不必担心数据到底是属于-1还是+1类。




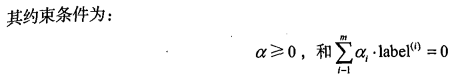

S V M 应用的一般框架




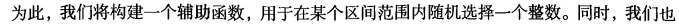
from numpy import *
from time import sleep def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(random.uniform(0,m))
return j def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj
dataMat,labelMat = loadDataSet('F:\\machinelearninginaction\\Ch06\\testSet.txt')
print(labelMat)

可以看得出来,这里采用的类别标签是-1和1


def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose()
b = 0; m,n = shape(dataMatrix)
alphas = mat(zeros((m,1)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])#if checks if an example violates KKT conditions
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i,m)
fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H:
print("L==H")
continue
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0:
print("eta>=0")
continue
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001):
print("j not moving enough")
continue
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])#update i by the same amount as j
#the update is in the oppostie direction
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
if (0 < alphas[i]) and (C > alphas[i]):
b = b1
elif (0 < alphas[j]) and (C > alphas[j]):
b = b2
else:
b = (b1 + b2)/2.0
alphaPairsChanged += 1
print("iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
if (alphaPairsChanged == 0): iter += 1
else: iter = 0
print("iteration number: %d" % iter)
return b,alphas
该函数有5个输人参数,分别
是:数据集、类别标签、常数C 、容错率和取消前最大的循环次数。
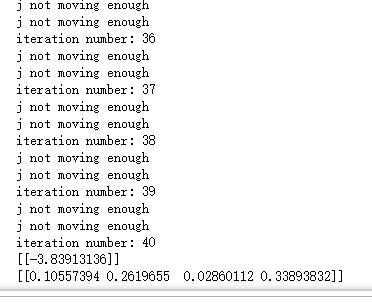
b,alphas = smoSimple(dataMat,labelMat, 0.6, 0.001, 40)
print(b)
print(alphas[alphas>0])
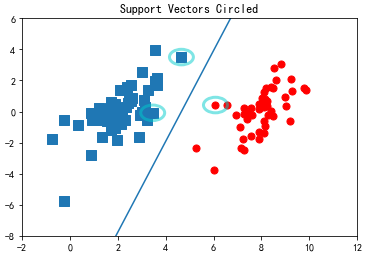
在原始数据集上对这些支持向量画圈之后的结果
import matplotlib
import matplotlib.pyplot as plt from numpy import *
from matplotlib.patches import Circle xcord0 = []
ycord0 = []
xcord1 = []
ycord1 = []
markers =[]
colors =[]
fr = open('F:\\machinelearninginaction\\Ch06\\testSet.txt')#this file was generated by 2normalGen.py
for line in fr.readlines():
lineSplit = line.strip().split('\t')
xPt = float(lineSplit[0])
yPt = float(lineSplit[1])
label = int(lineSplit[2])
if (label == -1):
xcord0.append(xPt)
ycord0.append(yPt)
else:
xcord1.append(xPt)
ycord1.append(yPt) fr.close()
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord0,ycord0, marker='s', s=90)
ax.scatter(xcord1,ycord1, marker='o', s=50, c='red')
plt.title('Support Vectors Circled')
circle = Circle((4.6581910000000004, 3.507396), 0.5, facecolor='none', edgecolor=(0,0.8,0.8), linewidth=3, alpha=0.5)
ax.add_patch(circle)
circle = Circle((3.4570959999999999, -0.082215999999999997), 0.5, facecolor='none', edgecolor=(0,0.8,0.8), linewidth=3, alpha=0.5)
ax.add_patch(circle)
circle = Circle((6.0805730000000002, 0.41888599999999998), 0.5, facecolor='none', edgecolor=(0,0.8,0.8), linewidth=3, alpha=0.5)
ax.add_patch(circle)
#plt.plot([2.3,8.5], [-6,6]) #seperating hyperplane
b = -3.75567
w0=0.8065
w1=-0.2761
x = arange(-2.0, 12.0, 0.1)
y = (-w0*x - b)/w1
ax.plot(x,y)
ax.axis([-2,12,-8,6])
plt.show()




def kernelTrans(X, A, kTup): #calc the kernel or transform data to a higher dimensional space
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin':
K = X * A.T #linear kernel
elif kTup[0]=='rbf':
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #divide in NumPy is element-wise not matrix like Matlab
else: raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
return K
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
self.K = mat(zeros((self.m,self.m)))
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup) def calcEk(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek def selectJ(i, oS, Ei): #this is the second choice -heurstic, and calcs Ej
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei] #set valid #choose the alpha that gives the maximum delta E
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: #loop through valid Ecache values and find the one that maximizes delta E
if k == i: continue #don't calc for i, waste of time
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #in this case (first time around) we don't have any valid eCache values
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej def updateEk(oS, k):#after any alpha has changed update the new value in the cache
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
def innerL(i, oS):
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #this has been changed from selectJrand
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H:
print("L==H")
return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j] #changed for kernel
if eta >= 0:
print("eta>=0")
return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j) #added this for the Ecache
if (abs(oS.alphas[j] - alphaJold) < 0.00001):
print("j not moving enough")
return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else:
return 0
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #full Platt SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0
entireSet = True
alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print("iteration number: %d" % iter)
return oS.b,oS.alphas
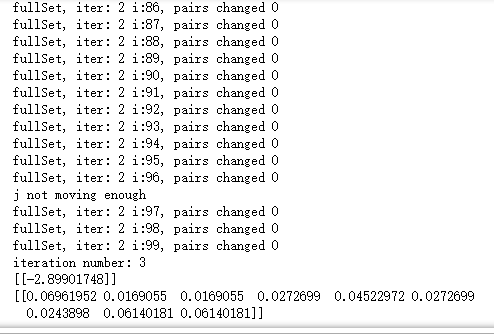
b,alphas = smoP(dataMat,labelMat, 0.6, 0.001, 40)
print(b)
print(alphas[alphas>0])
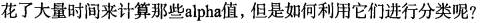

下面列出的一个小函数可
以用于实现上述任务:
def calcWs(alphas,dataArr,classLabels):
X = mat(dataArr); labelMat = mat(classLabels).transpose()
m,n = shape(X)
w = zeros((n,1))
for i in range(m):
w += multiply(alphas[i]*labelMat[i],X[i,:].T)
return w
w = calcWs(alphas,dataMat,labelMat)
print(w)

r = mat(dataMat[0])*w+b
print(r)
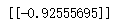

print(labelMat[0])

利用核函数将数据映射到高维空间
数据点处于一个圆中,人类的大脑能够意识到这一点。然而,对于分类器而言,
它只能识别分类器的结果是大于0还是小于0。如果只在1和^轴构成的坐标系中插人直线进行分类
的话,我们并不会得到理想的结果。我们或许可以对圆中的数据进行某种形式的转换,从而得到
某些新的变量来表示数据。在这种表示情况下,我们就更容易得到大于0或者小于0的测试结果。
在这个例子中,我们将数据从一个特征空间转换到另一个特征空间。在新空间下,我们可以很容
易利用巳有的工具对数据进行处理。数学家们喜欢将这个过程称之为从一个特征空间到另一个特
择空间的映射。在通常情况下,这种映射会将低维特征空间映射到高维空间。
这种从某个特征空间到另一个特征空间的映射是通过核函数来实现的。

核函数并不仅仅应用于支持向量机,很多其他的机器学习算法也都用到核函数。
径向基核函数

上述高斯核函数将数据从其特征空间映射到更高维的空间,具体来说这里是映射到一个无穷
维的空间。
高斯核函数只是一个常用的核函数,使用
者并不需要确切地理解数据到底是如何表现的,而且使用高斯核函数还会得到一个理想的结果。
def kernelTrans(X, A, kTup): #calc the kernel or transform data to a higher dimensional space
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin':
K = X * A.T #linear kernel
elif kTup[0]=='rbf':
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #divide in NumPy is element-wise not matrix like Matlab
else: raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
return K
在测试中使用核函数
利用核函数进行分类的径向基测试函数
def testRbf(k1=1.3):
dataArr,labelArr = loadDataSet('F:\\machinelearninginaction\\Ch06\\testSetRBF.txt')
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', k1)) #C=200 important
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd] #get matrix of only support vectors
labelSV = labelMat[svInd];
print("there are %d Support Vectors" % shape(sVs)[0])
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]):
errorCount += 1
print("the training error rate is: %f" % (float(errorCount)/m))
dataArr,labelArr = loadDataSet('F:\\machinelearninginaction\\Ch06\\testSetRBF2.txt')
errorCount = 0
datMat=mat(dataArr)
labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]):
errorCount += 1
print("the test error rate is: %f" % (float(errorCount)/m))
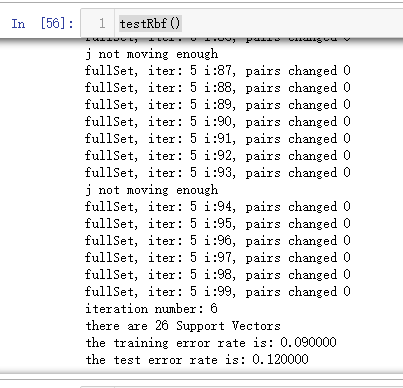
吴裕雄--天生自然python机器学习:支持向量机SVM的更多相关文章
- 吴裕雄--天生自然python机器学习:基于支持向量机SVM的手写数字识别
from numpy import * def img2vector(filename): returnVect = zeros((1,1024)) fr = open(filename) for i ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 吴裕雄--天生自然python机器学习:朴素贝叶斯算法
分类器有时会产生错误结果,这时可以要求分类器给出一个最优的类别猜测结果,同 时给出这个猜测的概率估计值. 概率论是许多机器学习算法的基础 在计算 特征值取某个值的概率时涉及了一些概率知识,在那里我们先 ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 吴裕雄--天生自然python机器学习:使用K-近邻算法改进约会网站的配对效果
在约会网站使用K-近邻算法 准备数据:从文本文件中解析数据 海伦收集约会数据巳经有了一段时间,她把这些数据存放在文本文件(1如1^及抓 比加 中,每 个样本数据占据一行,总共有1000行.海伦的样本主 ...
- 吴裕雄--天生自然python机器学习:机器学习简介
除却一些无关紧要的情况,人们很难直接从原始数据本身获得所需信息.例如 ,对于垃圾邮 件的检测,侦测一个单词是否存在并没有太大的作用,然而当某几个特定单词同时出现时,再辅 以考察邮件长度及其他因素,人们 ...
- 吴裕雄--天生自然python机器学习:使用Logistic回归从疝气病症预测病马的死亡率
,除了部分指标主观和难以测量外,该数据还存在一个问题,数据集中有 30%的值是缺失的.下面将首先介绍如何处理数据集中的数据缺失问题,然 后 再 利 用 Logistic回 归 和随机梯度上升算法来预测 ...
- 吴裕雄--天生自然python机器学习:Logistic回归
假设现在有一些数据点,我们用 一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归.利用Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类 ...
- 吴裕雄--天生自然python机器学习:使用朴素贝叶斯过滤垃圾邮件
使用朴素贝叶斯解决一些现实生活中 的问题时,需要先从文本内容得到字符串列表,然后生成词向量. 准备数据:切分文本 测试算法:使用朴素贝叶斯进行交叉验证 文件解析及完整的垃圾邮件测试函数 def cre ...
随机推荐
- id就是方法名,如何调用;批量input怎么获取他们的key值作为参数
1.很多Dom的时候,一个个写会比较麻烦,我用ID记载他的方法名: 2.很多input,在数据交互的时候一个个获取会比较繁琐,给一个方法,批量获取. <div id="searchSt ...
- mysql锁探究和实验
如何保证数据并发访问的一致性.有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素.从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂. 表锁和行锁 mysql最显 ...
- 使用AJAX(阿贾克斯)创建级联菜单
1. html页面 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> < ...
- nginx反向代理和负载均衡的实现
反向代理和负载均衡的关系可以理解为,一个ip的负载均衡就是反向代理. 反向代理使用的是:proxy_pass指令 负载均衡使用的是:proxy_pass指令+upstream指令 负载均衡的3中方 ...
- delphi 文本 记录 流式 读写文件
unit Unit1; interface uses Winapi.Windows, Winapi.Messages, System.SysUtils, System.Variants, System ...
- SQL基础教程(第2版)第5章 复杂查询:5-1 视图和表
本章将以此前学过的SELECT语句,以及嵌套在SELECT语句中的视图和子查询等技术为中心进行学习.由于视图和子查询可以像表一样进行使用,因此如果能恰当地使用这些技术,就可以写出更加灵活的 SQL 了 ...
- Java之创建线程的方式三:实现Callable接口
import java.util.concurrent.Callable;import java.util.concurrent.ExecutionException;import java.util ...
- C语言-再论指针与数组
指针与数组的天生姻缘1.以指针方式来访问数组元素(1).数组元素使用时不能整体访问,只能是单个访问.访问形式有两种:数组形式和指针形式.(2).数组形式访问数组元素:数组名[下标]:(下标从0开始(3 ...
- SpringBoot+SpringSecurity+jwt整合及初体验
原来一直使用shiro做安全框架,配置起来相当方便,正好有机会接触下SpringSecurity,学习下这个.顺道结合下jwt,把安全信息管理的问题扔给客户端, 准备 首先用的是SpringBoot, ...
- [Java-基础]反射_Class对象_动态操作
动态性 动态语言 在程序运行时,可以改变程序结构或变量类型,典型的语言: Python,ruby,javascript 如: function test(){ var s = "var a= ...