python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)
现在我们现在一个分机上引入一个SCRAPY的爬虫项目,要求数据存储在MONGODB中
现在我们需要在SETTING.PY设置我们的爬虫文件
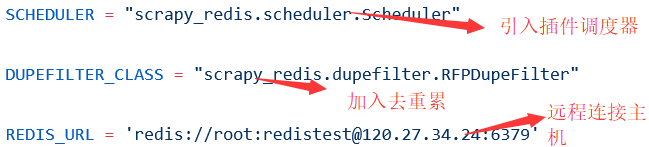
再添加PIPELINE

注释掉的原因是爬虫执行完后,和本地存储完毕还需要向主机进行存储会给主机造成压力
设置完这些后,在MASTER主机开启REDIS服务,将代码复制放在其它主机中,注意操作系统类型以及配置
然后分别在各个主机上进行爬取,爬取速度加大并且结果不同

setting中加入这个可以保证爬虫不会被清空

设置这个决定重新爬取时队列是否清空,一般都用FALSE
我们现在是否分别到主机上执行爬取,现在我想直接在一台主机上控制所有的爬虫程序,现在引入SCRAPYD,他会启动WEB服务来管理所有的项目
看下步骤
1启动SCRAPYD
2可以远程访问
3运用SCPRAPYD-CLIENT来打包项目
4修改爬虫的scrapy.cfg文件
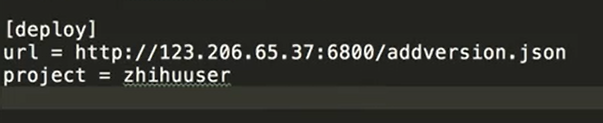
将地址改为远程的SCRAPYD服务地址
执行此命令完成部署

开启一个远程进程
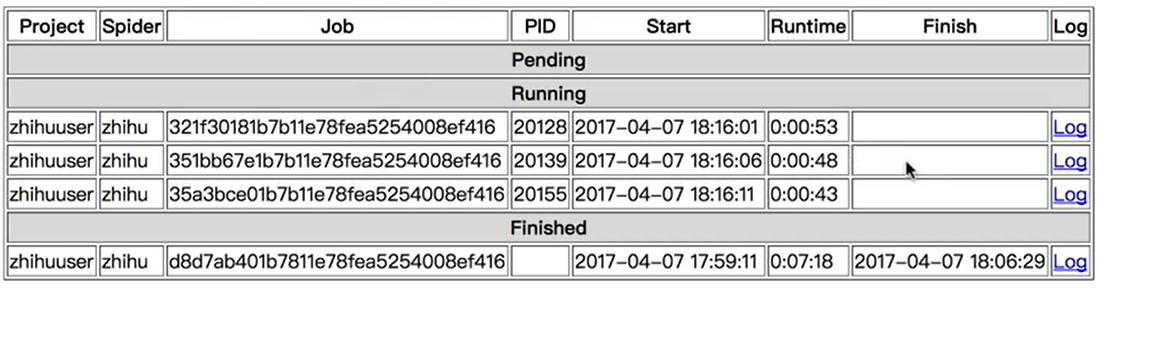
开几条指令,执行几条进程,每一个JOB都个ID如果是多个机器的任务那么ID则不同
python3下scrapy爬虫(第十四卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之执行)的更多相关文章
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 21天打造分布式爬虫-Spider类爬取糗事百科(七)
7.1.糗事百科 安装 pip install pypiwin32 pip install Twisted-18.7.0-cp36-cp36m-win_amd64.whl pip install sc ...
- 21天打造分布式爬虫-Crawl类爬取小程序社区(八)
8.1.Crawl的用法实战 新建项目 scrapy startproject wxapp scrapy genspider -t crawl wxapp_spider "wxapp-uni ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- 21天打造分布式爬虫-Selenium爬取拉钩职位信息(六)
6.1.爬取第一页的职位信息 第一页职位信息 from selenium import webdriver from lxml import etree import re import time c ...
- 21天打造分布式爬虫-requests库(二)
2.1.get请求 简单使用 import requests response = requests.get("https://www.baidu.com/") #text返回的是 ...
- 21天打造分布式爬虫-urllib库(一)
1.1.urlopen函数的用法 #encoding:utf-8 from urllib import request res = request.urlopen("https://www. ...
- python分布式爬虫打造搜索引擎--------scrapy实现
最近在网上学习一门关于scrapy爬虫的课程,觉得还不错,以下是目录还在更新中,我觉得有必要好好的做下笔记,研究研究. 第1章 课程介绍 1-1 python分布式爬虫打造搜索引擎简介 07:23 第 ...
随机推荐
- 大数据高可用集群环境安装与配置(02)——配置ntp服务
NTP服务概述 NTP服务器[Network Time Protocol(NTP)]是用来使计算机时间同步化的一种协议,它可以使计算机对其服务器或时钟源(如石英钟,GPS等等)做同步化,它可以提供高精 ...
- 桥接 brctl
把eth0和wlan0桥接在一起 作用:测试wlan0网卡的并发性能 两个网卡桥接后把linux主机模拟成一个“无线路由交换机” Vi br0.sh #!/bin/bash ifconfig ...
- wepy 小程序定时器(验证码倒计时) 数据绑定页面无刷新
每次改变数据的时候记得调用 this.$apply() 验证码倒计时 使用的vant-weapp UI组件 wxml: <van-col span="10" style= ...
- 直击JDD | 京东技术全景图首次展示 四大重磅智能技术驱动产业未来!
11月19日,主题为"突破与裂变"的2019京东全球科技探索者大会(JDDiscovery)在京盛大开幕,京东集团展示了完整的技术布局与先进而丰富的对外技术服务,对外明确诠释了&q ...
- [LC] 863. All Nodes Distance K in Binary Tree
We are given a binary tree (with root node root), a target node, and an integer value K. Return a li ...
- 【One by one系列】一步步学习TypeScript
TypeScript Quick Start 1.TypeScript是什么? TypeScript是ES6的超集. TS>ES7>ES6>ES5 Vue3.0已经宣布要支持ts,至 ...
- Linux--Centos7开机启动 mysql5.7.19
参考:http://www.cnblogs.com/Anker/p/3551508.html
- Maven - No plugin found for prefix 'tomcat7' in the current project
问题发现: 在构建Maven项目的时候,出现了No plugin found for prefix 'tomcat7' in the current project的错误. 是需要在Maven的Pom ...
- JavaScript—面向对象 贪吃蛇最终
效果 代码 //食物对象 ;(function () { function Food(element) { this.width = 20 this.height = 20 this.backgrou ...
- Spring Cloud Alibaba 教程 | Nacos(六)
集群模式部署 前面我们已经学习了Nacos作为注册中心.配置中心的相关功能,但是我们之前启动Nacos是通过单实例模式启动的,只适合在学习和开发阶段,生产环境需要保证Nacos的高可用,所以今天我们来 ...