《动手学深度学习》系列笔记 —— 语言模型(n元语法、随机采样、连续采样)
一段自然语言文本可以看作是一个离散时间序列,给定一个长度为\(T\)的词的序列\(w_1, w_2, \ldots, w_T\),语言模型的目标就是评估该序列是否合理,即计算该序列的概率:
\]
1. 语言模型
假设序列\(w_1, w_2, \ldots, w_T\)中的每个词是依次生成的,我们有
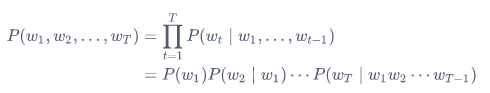
例如,一段含有4个词的文本序列的概率
\]
语言模型的参数就是词的概率以及给定前几个词情况下的条件概率。设训练数据集为一个大型文本语料库,如维基百科的所有条目,词的概率可以通过该词在训练数据集中的相对词频来计算,例如,\(w_1\)的概率可以计算为:
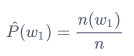
其中\(n(w_1)\)为语料库中以\(w_1\)作为第一个词的文本的数量,\(n\)为语料库中文本的总数量。
类似的,给定\(w_1\)情况下,\(w_2\)的条件概率可以计算为:
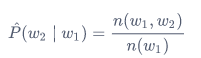
其中\(n(w_1, w_2)\)为语料库中以\(w_1\)作为第一个词,\(w_2\)作为第二个词的文本的数量。
2. n元语法
序列长度增加,计算和存储多个词共同出现的概率的复杂度会呈指数级增加。\(n\)元语法通过马尔可夫假设(一个词的出现只与前面\(n\)个词相关,即\(n\)阶马尔可夫链(Markov chain of order \(n\)))来简化模型。如果\(n=1\),那么有\(P(w_3 \mid w_1, w_2) = P(w_3 \mid w_2)\)。基于\(n-1\)阶马尔可夫链,我们可以将语言模型改写为
\]
以上也叫\(n\)元语法(\(n\)-grams),它是基于\(n - 1\)阶马尔可夫链的概率语言模型。例如,当\(n=2\)时,含有4个词的文本序列的概率就可以改写为:
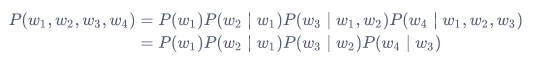
当\(n\)分别为1、2和3时,我们将其分别称作一元语法(unigram)、二元语法(bigram)和三元语法(trigram)。
例如,长度为4的序列\(w_1, w_2, w_3, w_4\)在一元语法、二元语法和三元语法中的概率分别为

当\(n\)较小时,\(n\)元语法往往并不准确。例如,在一元语法中,由三个词组成的句子“你走先”和“你先走”的概率是一样的。然而,当\(n\)较大时,\(n\)元语法需要计算并存储大量的词频和多词相邻频率。
- n元语法的缺陷有哪些?
- 参数空间过大
- 数据稀疏
3. 语言模型数据集
3.1 读取数据集
with open('/home/kesci/input/jaychou_lyrics4703/jaychou_lyrics.txt') as f:
corpus_chars = f.read()
print(len(corpus_chars))
print(corpus_chars[: 40])
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[: 10000]
3.2 建立字符索引
idx_to_char = list(set(corpus_chars)) # 去重,得到索引到字符的映射
char_to_idx = {char: i for i, char in enumerate(idx_to_char)} # 字符到索引的映射
vocab_size = len(char_to_idx)
print(vocab_size)
corpus_indices = [char_to_idx[char] for char in corpus_chars] # 将每个字符转化为索引,得到一个索引的序列
sample = corpus_indices[: 20]
print('chars:', ''.join([idx_to_char[idx] for idx in sample]))
print('indices:', sample)
定义函数load_data_jay_lyrics,在后续章节中直接调用。
def load_data_jay_lyrics():
with open('/home/kesci/input/jaychou_lyrics4703/jaychou_lyrics.txt') as f:
corpus_chars = f.read()
corpus_chars = corpus_chars.replace('\n', ' ').replace('\r', ' ')
corpus_chars = corpus_chars[0:10000]
idx_to_char = list(set(corpus_chars))
char_to_idx = dict([(char, i) for i, char in enumerate(idx_to_char)])
vocab_size = len(char_to_idx)
corpus_indices = [char_to_idx[char] for char in corpus_chars]
return corpus_indices, char_to_idx, idx_to_char, vocab_size
4. 时序数据的采样
在训练中我们需要每次随机读取小批量样本和标签。与之前章节的实验数据不同的是,时序数据的一个样本通常包含连续的字符。假设时间步数为5,样本序列为5个字符,即“想”“要”“有”“直”“升”。该样本的标签序列为这些字符分别在训练集中的下一个字符,即“要”“有”“直”“升”“机”,即\(X\)=“想要有直升”,\(Y\)=“要有直升机”。
现在我们考虑序列“想要有直升机,想要和你飞到宇宙去”,如果时间步数为5,有以下可能的样本和标签:
- \(X\):“想要有直升”,\(Y\):“要有直升机”
- \(X\):“要有直升机”,\(Y\):“有直升机,”
- \(X\):“有直升机,”,\(Y\):“直升机,想”
- ...
- \(X\):“要和你飞到”,\(Y\):“和你飞到宇”
- \(X\):“和你飞到宇”,\(Y\):“你飞到宇宙”
- \(X\):“你飞到宇宙”,\(Y\):“飞到宇宙去”
可以看到,如果序列的长度为\(T\),时间步数为\(n\),那么一共有\(T-n\)个合法的样本,但是这些样本有大量的重合,我们通常采用更加高效的采样方式。我们有两种方式对时序数据进行采样,分别是随机采样和相邻采样。
4.1 随机采样
下面的代码每次从数据里随机采样一个小批量。其中批量大小batch_size是每个小批量的样本数,num_steps是每个样本所包含的时间步数。
在随机采样中,每个样本是原始序列上任意截取的一段序列,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
import torch
import random
def data_iter_random(corpus_indices, batch_size, num_steps, device=None):
# 减1是因为对于长度为n的序列,X最多只有包含其中的前n - 1个字符
num_examples = (len(corpus_indices) - 1) // num_steps # 下取整,得到不重叠情况下的样本个数
example_indices = [i * num_steps for i in range(num_examples)] # 每个样本的第一个字符在corpus_indices中的下标
random.shuffle(example_indices)
def _data(i):
# 返回从i开始的长为num_steps的序列
return corpus_indices[i: i + num_steps]
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
for i in range(0, num_examples, batch_size):
# 每次选出batch_size个随机样本
batch_indices = example_indices[i: i + batch_size] # 当前batch的各个样本的首字符的下标
X = [_data(j) for j in batch_indices]
Y = [_data(j + 1) for j in batch_indices]
yield torch.tensor(X, device=device), torch.tensor(Y, device=device)
测试一下这个函数,我们输入从0到29的连续整数作为一个人工序列,设批量大小和时间步数分别为2和6,打印随机采样每次读取的小批量样本的输入X和标签Y。
my_seq = list(range(30))
for X, Y in data_iter_random(my_seq, batch_size=2, num_steps=6):
print('X: ', X, '\nY:', Y, '\n')

4.2 相邻采样
在相邻采样中,相邻的两个随机小批量在原始序列上的位置相毗邻。
def data_iter_consecutive(corpus_indices, batch_size, num_steps, device=None):
if device is None:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
corpus_len = len(corpus_indices) // batch_size * batch_size # 保留下来的序列的长度
corpus_indices = corpus_indices[: corpus_len] # 仅保留前corpus_len个字符
indices = torch.tensor(corpus_indices, device=device)
indices = indices.view(batch_size, -1) # resize成(batch_size, )
batch_num = (indices.shape[1] - 1) // num_steps
for i in range(batch_num):
i = i * num_steps
X = indices[:, i: i + num_steps]
Y = indices[:, i + 1: i + num_steps + 1]
yield X, Y
同样的设置下,打印相邻采样每次读取的小批量样本的输入X和标签Y。相邻的两个随机小批量在原始序列上的位置相毗邻。
for X, Y in data_iter_consecutive(my_seq, batch_size=2, num_steps=6):
print('X: ', X, '\nY:', Y, '\n')
my_seq = list(range(11))
for X, Y in data_iter_consecutive(my_seq, batch_size=2, num_steps=2):
print('X: ', X, '\nY:', Y, '\n')

《动手学深度学习》系列笔记 —— 语言模型(n元语法、随机采样、连续采样)的更多相关文章
- 对比《动手学深度学习》 PDF代码+《神经网络与深度学习 》PDF
随着AlphaGo与李世石大战的落幕,人工智能成为话题焦点.AlphaGo背后的工作原理"深度学习"也跳入大众的视野.什么是深度学习,什么是神经网络,为何一段程序在精密的围棋大赛中 ...
- 【动手学深度学习】Jupyter notebook中 import mxnet出错
问题描述 打开d2l-zh目录,使用jupyter notebook打开文件运行,import mxnet 出现无法导入mxnet模块的问题, 但是命令行运行是可以导入mxnet模块的. 原因: 激活 ...
- 小白学习之pytorch框架(2)-动手学深度学习(begin-random.shuffle()、torch.index_select()、nn.Module、nn.Sequential())
在这向大家推荐一本书-花书-动手学深度学习pytorch版,原书用的深度学习框架是MXNet,这个框架经过Gluon重新再封装,使用风格非常接近pytorch,但是由于pytorch越来越火,个人又比 ...
- 《动手学深度学习》系列笔记—— 1.2 Softmax回归与分类模型
目录 softmax的基本概念 交叉熵损失函数 模型训练和预测 获取Fashion-MNIST训练集和读取数据 get dataset softmax从零开始的实现 获取训练集数据和测试集数据 模型参 ...
- 动手学深度学习14- pytorch Dropout 实现与原理
方法 从零开始实现 定义模型参数 网络 评估函数 优化方法 定义损失函数 数据提取与训练评估 pytorch简洁实现 小结 针对深度学习中的过拟合问题,通常使用丢弃法(dropout),丢弃法有很多的 ...
- 动手学深度学习9-多层感知机pytorch
多层感知机 隐藏层 激活函数 小结 多层感知机 之前已经介绍过了线性回归和softmax回归在内的单层神经网络,然后深度学习主要学习多层模型,后续将以多层感知机(multilayer percetro ...
- 动手学深度学习6-认识Fashion_MNIST图像数据集
获取数据集 读取小批量样本 小结 本节将使用torchvision包,它是服务于pytorch深度学习框架的,主要用来构建计算机视觉模型. torchvision主要由以下几个部分构成: torchv ...
- 动手学深度学习1- pytorch初学
pytorch 初学 Tensors 创建空的tensor 创建随机的一个随机数矩阵 创建0元素的矩阵 直接从已经数据创建tensor 创建新的矩阵 计算操作 加法操作 转化形状 tensor 与nu ...
- mxnet 动手学深度学习
http://zh.gluon.ai/chapter_crashcourse/introduction.html 强化学习(Reinforcement Learning) 如果你真的有兴趣用机器学习开 ...
随机推荐
- git 修改分支 删除分支 新增分支
一.修改分支名 1.本地分支重命名 git branch -m oldName newName 2.将重命名后的分支推送到远程 git push origin newName 3.重新更新所有分支 g ...
- SpringData学习笔记一
Spring Data : 介绍: Spring 的一个子项目.用于简化数据库访问,支持NoSQL 和 关系数据存储.其主要目标是使数据库的访问变得方便快捷. SpringData 项目所支持 NoS ...
- windows安装ActiveMQ以及点对点以及发布订阅
一.MQ产品的分类 1.RabbitMQ 是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级 ...
- luogu P2280 激光炸弹(二维前缀和)
由题给的xi, yi范围,可以建立二维地图maze[i][j],记录i j范围上的所有目标的价值总和 即有maze[xi][yi] += wi 然后接下来的目标就是求出该二维数组的前缀和 可得到前缀和 ...
- C语言中的变量和常量的区别和使用
变量 定义一个变量:类型 变量名=值; int a =0; // 变量,可以在赋值 常量 定义一个常量 const 常量类型 常量名称 = 值 const int LENTHER = 521 // 定 ...
- 无需密码攻击 Microsoft SQL Server
最近的一次渗透测试里,在我们捕获的一些数据包中发现了一些未经加密的 Microsoft SQL Server(MSSQL) 流量.起初,我们认为这样就可以直接嗅探到认证凭证,然而,MSSQL 加密了认 ...
- Acwing779 最长公共字符串后缀
题目大意:给定n个字符串,让你找到他们的最长公共字符串后缀是什么,可能为空. 分析:题目数据范围比较小,可以O(n*n)暴力匹配,即可解决这道问题.之所以写这道题的题解还是因为写字符串的题还不够多啊, ...
- liunx开源打印驱动foo2zjs编译小坑
在编译foo2zjs时出现 ## Dependencies...# *** *** Error: gs is not installed! *** *** Install ghostscript (g ...
- Linux centosVMware vim 编辑模式、vim命令模式、vim实践
一.编辑模式.命令模式 在一般模式下输入:或/可进入命令模式.在该模式下可进行走索某个字符或字符串,也可保存.替换.退出.显示行号等. /word:在光标之后查找一个字符串word,按n向后继续搜索 ...
- Day9 - G - Doing Homework HDU - 1074
有n个任务,每个任务有一个截止时间,超过截止时间一天,要扣一个分.求如何安排任务,使得扣的分数最少.Input有多组测试数据.第一行一个整数表示测试数据的组数第一行一个整数n(1<=n<= ...