时间序列数据库(TSDB)初识与选择(InfluxDB、OpenTSDB、Druid、Elasticsearch对比)
背景
这两年互联网行业掀着一股新风,总是听着各种高大上的新名词。大数据、人工智能、物联网、机器学习、商业智能、智能预警啊等等。
以前的系统,做数据可视化,信息管理,流程控制。现在业务已经不仅仅满足于这种简单的管理和控制了。数据可视化分析,大数据信息挖掘,统计预测,建模仿真,智能控制成了各种业务的追求。
“所有一切如泪水般消失在时间之中,时间正在死去“,以前我们利用互联网解决现实的问题。现在我们已经不满足于现实,数据将连接成时间序列,可以往前可以观其历史,揭示其规律性,往后可以把握其趋势性,预测其走势。
于是,我们开始存储大量时间相关的数据(如日志,用户行为等),并总结出这些数据的结构特点和常见使用场景,不断改进和优化,创造了一种新型的数据库分类——时间序列数据库(Time Series Database).
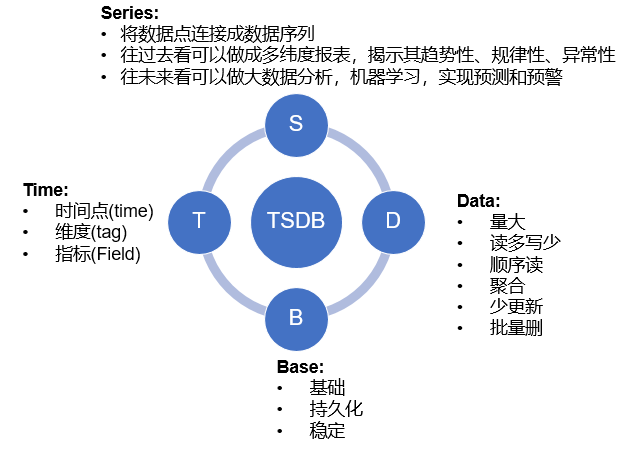
时间序列模型
时间序列数据库主要用于指处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,带时间标签的数据也称为时间序列数据。
每个时序点结构如下:
timestamp: 数据点的时间,表示数据发生的时间。
metric: 指标名,当前数据的标识,有些系统中也称为name。
value: 值,数据的数值,一般为double类型,如cpu使用率,访问量等数值,有些系统一个数据点只能有一个value,多个value就是多条时间序列。有些系统可以有多个value值,用不同的key表示
tag: 附属属性。
实现
比如我想记录一系列传感器的时间序列数据。数据结构如下:
- * 标识符:device_id,时间戳
* 元数据:location_id,dev_type,firmware_version,customer_id
* 设备指标:cpu_1m_avg,free_mem,used_mem,net_rssi,net_loss,电池
* 传感器指标:温度,湿度,压力,CO,NO2,PM10
如果使用传统RDBMS存储,建一张如下结构的表即可:
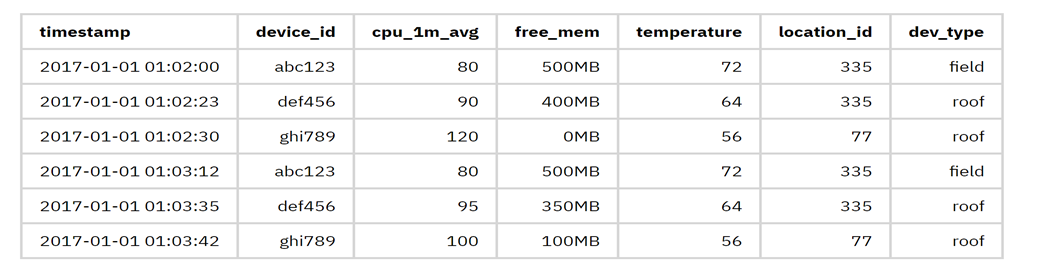
如此便是一个最简单的时间序列库了。但这只是满足了数据模型的需要。我们还需要在性能,高效存储,高可用,分布式和易用性上做更多的事情。
大家可以思考思考,如果让你自己来实现一个时间序列数据库,你会怎么设计,你会考虑哪些性能上的优化,又如何做到高可用,怎样做到简单易用。
Timescale
这个数据库其实就是一个基于传统关系型数据库postgresql改造的时间序列数据库。了解postgresql的同学都知道,postgresql是一个强大的,开源的,可扩展性特别强的一个数据库系统。
于是timescale.inc开发了Timescale,一款兼容sql的时序数据库, 底层存储架构在postgresql上。 作为一个postgresql的扩展提供服务。其特点如下:
基础:
PostgreSQL原生支持的所有SQL,包含完整SQL接口(包括辅助索引,非时间聚合,子查询,JOIN,窗口函数)
用PostgreSQL的客户端或工具,可以直接应用到该数据库,不需要更改。
时间为导向的特性,API功能和相应的优化。
可靠的数据存储。
扩展:
透明时间/空间分区,用于放大(单个节点)和扩展
高数据写入速率(包括批量提交,内存中索引,事务支持,数据备份支持)
单个节点上的大小合适的块(二维数据分区),以确保即使在大数据量时即可快速读取。
块之间和服务器之间的并行操作
劣势:
因为TimescaleDB没有使用列存技术,它对时序数据的压缩效果不太好,压缩比最高在4X左右
目前暂时不完全支持分布式的扩展(正在开发相关功能),所以会对服务器单机性能要求较高
其实大家都可以去深入了解一下这个数据库。对RDBMS我们都很熟悉,了解这个可以让我们对RDBMS有更深入的了解,了解其实现机制,存储机制。在对时间序列的特殊化处理之中,我们又可以学到时间序列数据的特点,并学习到如何针对时间序列模型去优化RDBMS。
之后我们也可以写一篇文章来深入的了解一下这个数据库的特点和实现。
Influxdb
Influxdb是业界比较流行的一个时间序列数据库,特别是在IOT和监控领域十分常见。其使用go语言开发,突出特点是性能。
特性:
高效的时间序列数据写入性能。自定义TSM引擎,快速数据写入和高效数据压缩。
无额外存储依赖。
简单,高性能的HTTP查询和写入API。
以插件方式支持许多不同协议的数据摄入,如:graphite,collectd,和openTSDB
SQL-like查询语言,简化查询和聚合操作。
索引Tags,支持快速有效的查询时间序列。
保留策略有效去除过期数据。
连续查询自动计算聚合数据,使频繁查询更有效。
Influxdb已经将分布式版本转为闭源。所以在分布式集群这块是一个弱点,需要自己实现。
OpenTSDB
The Scalable Time Series Database. 打开OpenTSDB官网,第一眼看到的就是这句话。其将Scalable作为其重要的特点。OpenTSDB运行在Hadoop和HBase上,其充分利用HBase的特性。通过独立的Time Series Demon(TSD)提供服务,所以它可以通过增减服务节点来轻松扩缩容。
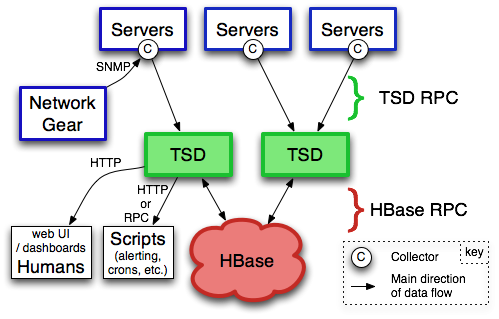
Opentsdb是一个基于Hbase的时间序列数据库(新版也支持Cassandra)。
其基于Hbase的分布式列存储特性实现了数据高可用,高性能写的特性。受限于Hbase,存储空间较大,压缩不足。依赖整套HBase, ZooKeeper
采用无模式的tagset数据结构(sys.cpu.user 1436333416 23 host=web01 user=10001)
结构简单,多value查询不友好
HTTP-DSL查询
OpenTSDB在HBase上针对TSDB的表设计和RowKey设计是值得我们深入学习的一个特点。有兴趣的同学可以找一些详细的资料学习学习。
Druid
Druid是一个实时在线分析系统(LOAP)。其架构融合了实时在线数据分析,全文检索系统和时间序列系统的特点,使其可以满足不同使用场景的数据存储需求。
采用列式存储:支持高效扫描和聚合,易于压缩数据。
可伸缩的分布式系统:Druid自身实现可伸缩,可容错的分布式集群架构。部署简单。
强大的并行能力:Druid各集群节点可以并行地提供查询服务。
实时和批量数据摄入:Druid可以实时摄入数据,如通过Kafka。也可以批量摄入数据,如通过Hadoop导入数据。
自恢复,自平衡,易于运维:Druid自身架构即实现了容错和高可用。不同的服务节点可以根据响应需求添加或减少节点。
容错架构,保证数据不丢失:Druid数据可以保留多副本。另外可以采用HDFS作为深度存储,来保证数据不丢失。
索引:Druid对String列实现反向编码和Bitmap索引,所以支持高效的filter和groupby。
基于时间分区:Druid对原始数据基于时间做分区存储,所以Druid对基于时间的范围查询将更高效。
自动预聚合:Druid支持在数据摄入期就对数据进行预聚合处理。
Druid架构蛮复杂的。其按功能将整个系统细分为多种服务,query、data、master不同职责的系统独立部署,对外提供统一的存储和查询服务。其以分布式集群服务的方式提供了一个底层数据存储的服务。
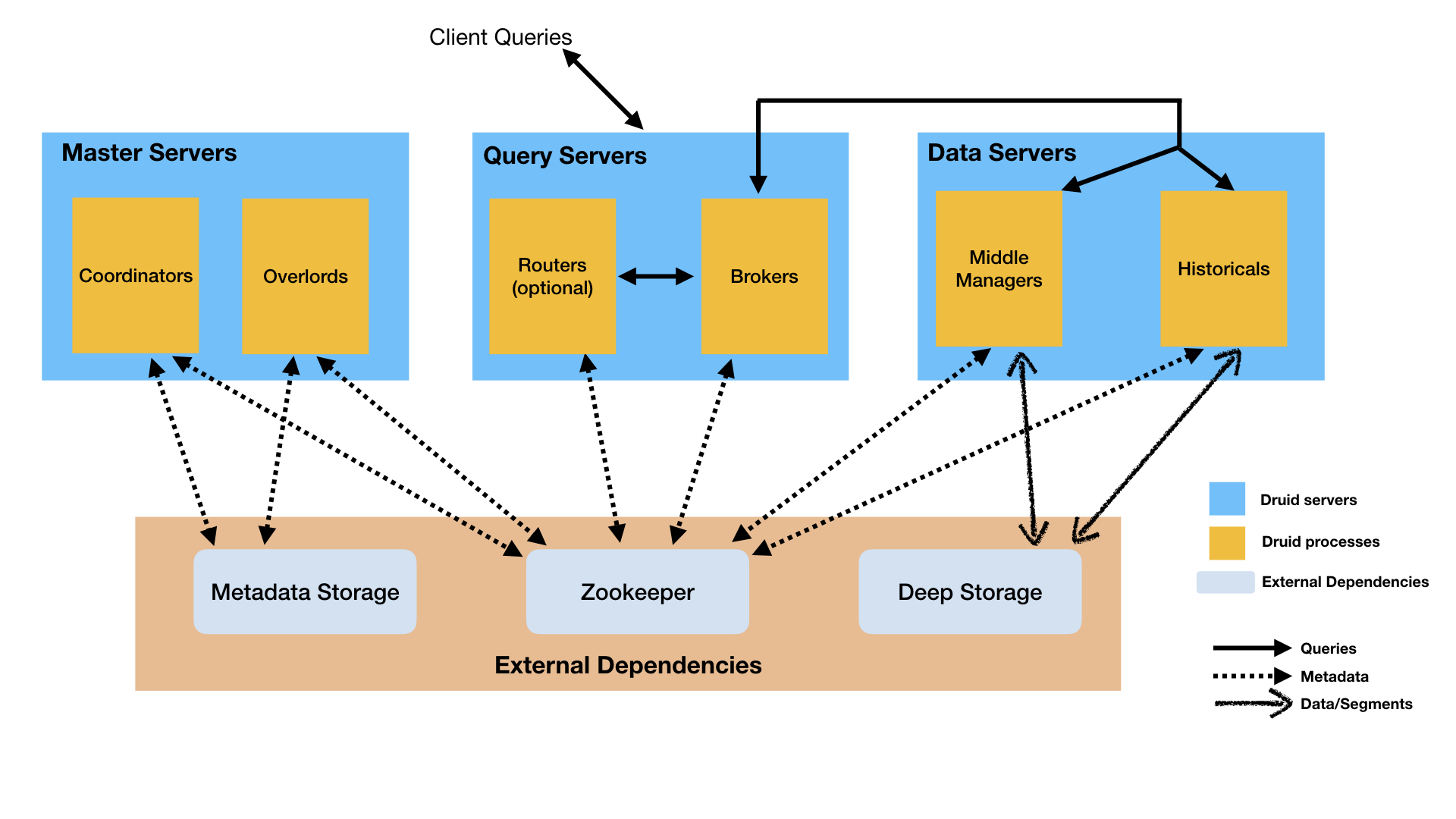
Druid在架构上的设计很值得我们学习。如果你不仅仅对时间序列存储感兴趣,对分布式集群架构也有兴趣,不妨看看Druid的架构。另外Druid在segment(Druid的数据存储结构)的设计也是一大亮点,既实现了列式存储,又实现了反向索引。
Elasticsearch
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名。
Elasticsearch以ELK stack被人所熟知。许多公司基于ELK搭建日志分析系统和实时搜索系统。之前我们在ELK的基础上开始开发metric监控系统。即想到了使用Elasticsearch来存储时间序列数据库。对Elasticserach的mapping做相应的优化,使其更适合存储时间序列数据模型,收获了不错的效果,完全满足了业务的需求。后期发现Elasticsearch新版本竟然也开始发布Metrics组件和APM组件,并大量的推广其全文检索外,对时间序列的存储能力。真是和我们当时的想法不谋而合。
Elasticsearch的时序优化可以参考一下这篇文章:《elasticsearch-as-a-time-series-data-store》
也可以去了解一下Elasticsearch的Metric组件:Elastic Metrics
Beringei
Beringei是Facebook在2017年最新开源的一个高性能内存时序数据存储引擎。其具有快速读写和高压缩比等特性。
2015年Facebook发表了一篇论文《Gorilla: A Fast, Scalable, In-Memory Time Series Database 》,Beringei正是基于此想法实现的一个时间序列数据库。
Beringei使用Delta-of-Delta算法存储数据,使用XOR编码压缩数值。使其可以用很少的内存即可存储下大量的数据。
如何选择一个适合自己的时间序列数据库
Data model
时间序列数据模型一般有两种,一种无schema,具有多tag的模型,还有一种name、timestamp、value型。前者适合多值模式,对复杂业务模型更适合。后者更适合单维数据模型。
Query language
目前大部分TSDB都支持基于HTTP的SQL-like查询。
Reliability
可用性主要体现在系统的稳定高可用上,以及数据的高可用存储上。一个优秀的系统,应该有一个优雅而高可用的架构设计。简约而稳定。
Performance
性能是我们必须考虑的因素。当我们开始考虑更细分领域的数据存储时,除了数据模型的需求之外,很大的原因都是通用的数据库系统在性能上无法满足我们的需求。大部分时间序列库倾向写多读少场景,用户需要平衡自身的需求。下面会有一份各库的性能对比,大家可以做一个参考。
Ecosystem
我一直认为生态是我们选择一个开源组件必须认真考虑的问题。一个生态优秀的系统,使用的人多了,未被发现的坑也将少了。另外在使用中遇到问题,求助于社区,往往可以得到一些比较好的解决方案。另外好的生态,其周边边界系统将十分成熟,这让我们在对接其他系统时会有更多成熟的方案。
Operational management
易于运维,易于操作。
Company and support
一个系统其背后的支持公司也是比较重要的。背后有一个强大的公司或组织,这在项目可用性保证和后期维护更新上都会有较大的体验。
性能对比
| Timescale | InfluxDB | OpenTSDB | Druid | Elasticsearch | Beringei | |
|---|---|---|---|---|---|---|
| write(single node) | 15K/sec | 470k/sec | 32k/sec | 25k/sec | 30k/sec | 10m/sec |
| write(5 node) | 128k/sec | 100k/sec | 120k/sec |
总结
可以按照以下需求自行选择合适的存储:
小而精,性能高,数据量较小(亿级): InfluxDB
简单,数据量不大(千万级),有联合查询、关系型数据库基础:timescales
数据量较大,大数据服务基础,分布式集群需求: opentsdb、KairosDB
分布式集群需求,olap实时在线分析,资源较充足:druid
性能极致追求,数据冷热差异大:Beringei
兼顾检索加载,分布式聚合计算: elsaticsearch
如果你兼具索引和时间序列的需求。那么Druid和Elasticsearch是最好的选择。其性能都不差,同时满足检索和时间序列的特性,并且都是高可用容错架构。
最后
之后我们可以来深入了解一两个TSDB,比如Influxdb,OpenTSDB,Druid,Elasticsearch等。并可以基于此学习一下行存储与列存储的不同,LSM的实现原理,数值数据的压缩,MMap提升读写性能的知识等。
系列推荐
Mysql:小主键,大问题
Mysql大数据量问题与解决
你应该知道一些其他存储——列式存储
时间序列数据库(TSDB)初识与选择(InfluxDB、OpenTSDB、Druid、Elasticsearch对比)
十分钟了解Apache Druid(集数据仓库、时间序列、全文检索于一体的存储方案)
Apache Druid 底层存储设计(列存储与全文检索)
Apache Druid 的集群设计与工作流程
关注公众号,深入了解TSDB,Druid。获取更多技术内容。

时间序列数据库(TSDB)初识与选择
时间序列数据库(TSDB)初识与选择(InfluxDB、OpenTSDB、Druid、Elasticsearch对比)的更多相关文章
- 时间序列数据库(TSDB)初识与选择
时间序列数据库(TSDB)初识与选择 本文作者由 MageByte 团队的 「借来方向」编写,关注公众号 给你更多硬核技术 背景 这两年互联网行业掀着一股新风,总是听着各种高大上的新名词.大数据.人工 ...
- [转帖]时间序列数据库 (TSDB)
时间序列数据库 (TSDB) https://www.jianshu.com/p/31afb8492eff 0.3392019.01.28 10:51:33字数 5598阅读 4030 背景 2017 ...
- 时间序列数据库调研之InfluxDB
基于 Go 语言开发,社区非常活跃,项目更新速度很快,日新月异,关注度高 测试版本 1.0.0_beta2-1 安装部署 wget https://dl.influxdata.com/influxdb ...
- OpenTSDB介绍——基于Hbase的分布式的,可伸缩的时间序列数据库,而Hbase本质是列存储
原文链接:http://www.jianshu.com/p/0bafd0168647 OpenTSDB介绍 1.1.OpenTSDB是什么?主要用途是什么? 官方文档这样描述:OpenTSDB is ...
- 时间序列数据库概览——基于文件(RRD)、K/V数据库(influxDB)、关系型数据库
一般人们谈论时间序列数据库的时候指代的就是这一类存储.按照底层技术不同可以划分为三类. 直接基于文件的简单存储:RRD Tool,Graphite Whisper.这类工具附属于监控告警工具,底层没有 ...
- 重新定义数据库历史的时刻——时间序列数据库Schwartz认为InfluxDB最有前途,Elasticsearch也不错
转自:http://www.infoq.com/cn/news/2017/04/redefine-database-history 提起VividCortex公司的创建者兼CEO Baron Schw ...
- 时间序列数据库武斗大会之 KairosDB 篇
[编者按] 刘斌,OneAPM后端研发工程师,拥有10多年编程经验,参与过大型金融.通信以及Android手机操作系的开发,熟悉Linux及后台开发技术.曾参与翻译过<第一本Docker书> ...
- 时间序列数据库——索引用ES、聚合分析时加载数据用什么?docvalues的列存储貌似更优优势一些
加载 如何利用索引和主存储,是一种两难的选择. 选择不使用索引,只使用主存储:除非查询的字段就是主存储的排序字段,否则就需要顺序扫描整个主存储. 选择使用索引,然后用找到的row id去主存储加载数据 ...
- 时间序列数据库选型——本质是列存储,B-tree索引,抑或是搜索引擎中的倒排索引
时间序列数据库最多,使用也最广泛.一般人们谈论时间序列数据库的时候指代的就是这一类存储.按照底层技术不同可以划分为三类. 直接基于文件的简单存储:RRD Tool,Graphite Whisper.这 ...
随机推荐
- 2013 ACM网络搜索与数据挖掘国际会议
ACM网络搜索与数据挖掘国际会议" title="2013 ACM网络搜索与数据挖掘国际会议"> 编者按:ACM网络搜索与数据挖掘国际会议(6th ACM Conf ...
- CentOS-SendMail服务
title date tags layout music-id CentOS6.5 SendMail服务安装与配置 2018-09-04 Centos6.5服务器搭建 post 456272749 一 ...
- android愤怒小鸟游戏、自定义View、掌上餐厅App、OpenGL自定义气泡、抖音电影滤镜效果等源码
Android精选源码 精练的范围选择器,范围和单位可以自定义 自定义View做的小鸟游戏 android popwindow选择商品规格颜色尺寸效果源码 实现Android带有锯齿背景的优惠样式源码 ...
- android完整智能家居、备忘录、蓝牙配对、3D动画库、购物车页面、版本更新自动安装等源码
Android精选源码 app 版本更新.下载完毕自动自动安装 android指针式分数仪表盘 ANdroid蓝牙设备搜索.配对 Android 图片水印框架,支持隐形数字水印 android3D旋转 ...
- php获取服务器和mysql等信息输出到页面(基于ci框架)
function show($varName) { switch($result = get_cfg_var($varName)) { case 0: return '< ...
- CLOUD列表字段数据汇总
- SLIQ/SPRINT
SLIQ/SPRINT */--> SLIQ/SPRINT Before SLIQ, most classification alogrithms have the problem that t ...
- [LC] 105. Construct Binary Tree from Preorder and Inorder Traversal
Given preorder and inorder traversal of a tree, construct the binary tree. Note:You may assume that ...
- Linux_centos安装后无法进入图形界面
问题 直接默认进入字符界面 root之后init 5也没用 解决方法 出现问题的原因在于安装时选择了最小安装,如图所示
- Logarithmic transformation|Data transfer|MASS|Box-Cox
数据转换(Data transfer) 方差分析的前提是方差齐性,可以使用transfer改变方差使得方差变齐.不正态和outlier. Logarithmic transformation使方差聚合 ...