Spark文档阅读之一:Spark Overview
1. spark的几种执行方式
1)交互式shell:bin/spark-shell
2)python: bin/pyspark & bin/spark-submit xx.py
3)R:bin/sparkR & bin/spark-submit xx.R
2. 任务的提交
bin/spark-submit \
--class <main-class> \ # 任务入口
--master <master-url> \ # 支持多种cluster manager
--deploy-mode <deploy-mode> \ # cluster / client,默认为client
--conf <key>=<value> \
... # other options,如--supervise(非0退出立即重启), --verbose(打印debug信息), --jars xx.jar(上传更多的依赖,逗号分隔,不支持目录展开)
<application-jar> \ # main-class来自这个jar包,必须是所有节点都可见的路径,hdfs://或file://
[application-arguments] # 入口函数的参数 bin/spark-submit \
--master <master-url> \
<application-python> \
[application-arguments]
3. cluster模式
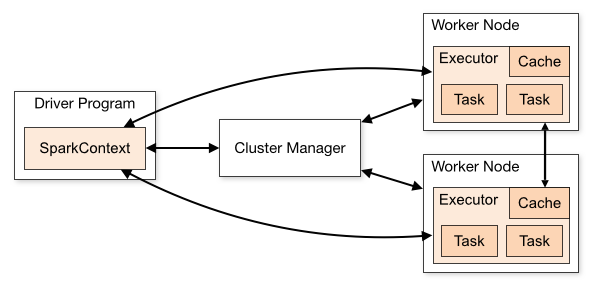
术语表
|
术语
|
含义
|
|
Application
|
任务,用户的spark程序,包含位于集群的一个driver和多个executors
|
|
Application jar
|
一个包含用户spark任务和依赖的jar包,不应包含hadoop或spark库
|
|
Driver program
|
任务main()函数和SparkContext所在的进程
|
|
Cluster manager
|
获取集群资源的外部服务
|
|
Deploy mode
|
用来区分driver进程在cluster还是client(即非cluster机器)上执行
|
|
Worker node
|
任何可以跑任务代码的节点
|
|
Executor
|
在worker node上载入并运行了用户任务的一个进程,它执行了tasks并且在内存或存储中保存数据,每个application独占它自己的executors
|
|
Task
|
一组被发送到一个executor的工作
|
|
Job
|
一个多tasks的并行计算单元,对应一个spark操作(例如save, collect)
|
|
Stage
|
每个job可以划分成的更小的tasks集合,类似MapReduce中的map/reduce,stages相互依赖
|


Spark文档阅读之一:Spark Overview的更多相关文章
- Spark文档阅读之二:Programming Guides - Quick Start
Quick Start: https://spark.apache.org/docs/latest/quick-start.html 在Spark 2.0之前,Spark的编程接口为RDD (Resi ...
- 转:苹果Xcode帮助文档阅读指南
一直想写这么一个东西,长期以来我发现很多初学者的问题在于不掌握学习的方法,所以,Xcode那么好的SDK文档摆在那里,对他们也起不到什么太大的作用.从论坛.微博等等地方看到的初学者提出的问题,也暴露出 ...
- Django文档阅读-Day1
Django文档阅读-Day1 Django at a glance Design your model from djano.db import models #数据库操作API位置 class R ...
- Django文档阅读-Day3
Django文档阅读-Day3 Writing your first Django app, part 3 Overview A view is a "type" of Web p ...
- Node.js的下载、安装、配置、Hello World、文档阅读
Node.js的下载.安装.配置.Hello World.文档阅读
- 我的Cocos Creator成长之路1环境搭建以及基本的文档阅读
本人原来一直是做cocos-js和cocos-lua的,应公司发展需要,现转型为creator.会在自己的博客上记录自己的成长之路. 1.文档阅读:(cocos的官方文档) http://docs.c ...
- Keras 文档阅读笔记(不定期更新)
目录 Keras 文档阅读笔记(不定期更新) 模型 Sequential 模型方法 Model 类(函数式 API) 方法 层 关于 Keras 网络层 核心层 卷积层 池化层 循环层 融合层 高级激 ...
- Django文档阅读-Day2
Django文档阅读 - Day2 Writing your first Django app, part 1 You can tell Django is installed and which v ...
- Spark Streaming + Flume整合官网文档阅读及运行示例
1,基于Flume的Push模式(Flume-style Push-based Approach) Flume被用于在Flume agents之间推送数据.在这种方式下,Spark Stre ...
随机推荐
- 三、HTML元素
嵌套的HTML元素 <!--以下实例包含了三个HTML元素,分别是<html>.<body>.<p>--> <!DOCTYPE html> ...
- Python小技巧:如何批量更新已安装的库?
众所周知,升级某个库(假设为 xxx),可以用pip install --upgrade xxx 命令,或者简写成pip install -U xxx . 如果有多个库,可以依次写在 xxx 后面,以 ...
- python常见面试题讲解(二)计算字符个数
题目描述 写出一个程序,接受一个由字母和数字组成的字符串,和一个字符,然后输出输入字符串中含有该字符的个数.不区分大小写. 输入描述: 第一行输入一个有字母和数字以及空格组成的字符串,第二行输入一个字 ...
- ajax 请求PHP返回json格式的处理
php返回代码格式 public function json(){ if (request()->isAjax()){ $data = [ 'code'=>'1', 'msg'=>' ...
- JSP+SSM+Mysql实现的图书馆预约占座管理系统
项目简介 项目来源于:https://gitee.com/gepanjiang/LibrarySeats 因原gitee仓库无数据库文件且存在水印,经过本人修改,现将该仓库重新上传至个人gitee仓库 ...
- 题解 P4071 【[SDOI2016]排列计数】 (费马小定理求组合数 + 错排问题)
luogu题目传送门! luogu博客通道! 这题要用到错排,先理解一下什么是错排: 问题:有一个数集A,里面有n个元素 a[i].求,如果将其打乱,有多少种方法使得所有第原来的i个数a[i]不在原来 ...
- 服务器开发 Ubuntu
一.Ubuntu安装: 为什么用Ubuntu,作为服务器初学者开发,如果真的要买苹果系统电脑性价比不高,所以在window系统中安装Linux虚拟机是不二之选.为什么用Ubuntu不多说了,开始安装吧 ...
- bootstrap table Showing 1 to 5 of 5 rows 页码显示英文
注意导包先后顺序bootstrap-table-zh-CN.js链接:https://cdn.bootcdn.net/ajax/libs/bootstrap-table/1.16.0/locale/b ...
- tmux简单使用
tmux简单使用 Tmux ("Terminal Multiplexer"的简称), 是一款优秀的终端复用软件,类似 GNU screen,但比screen更出色.tmux来自于O ...
- 一文彻底搞懂BERT
一.什么是BERT? 没错下图中的小黄人就是文本的主角Bert ,而红色的小红人你应该也听过,他就是ELMo.2018年发布的BERT 是一个 NLP 任务的里程碑式模型,它的发布势必会带来一个 NL ...