TensorFlow 多元线性回归【波士顿房价】
1数据读取
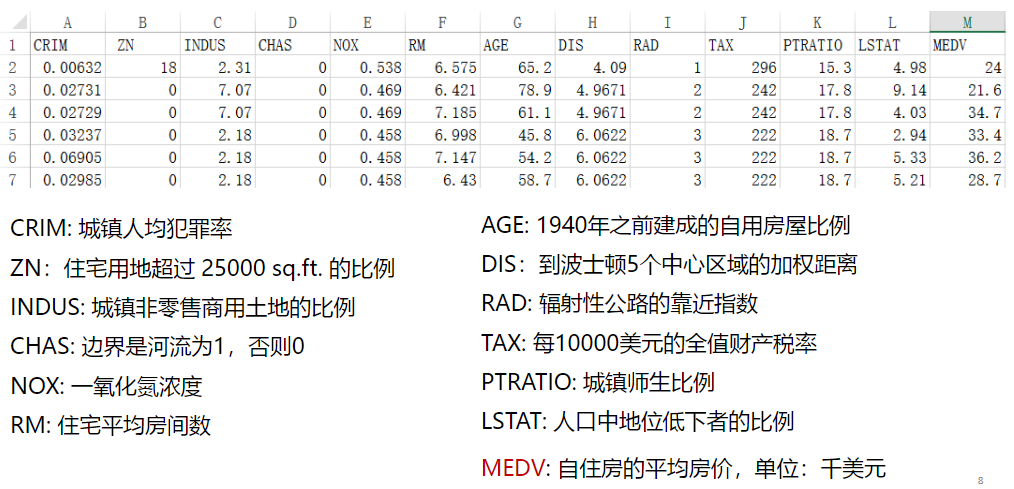
1.1数据集解读
1.2引入包
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle1.2.1pandas介绍
1.2.2TensorFlow下安装pandas
1、激活tensorflow: Activate tensorflow
2、安装Pandas: conda install pandas1.2.3出现“No module named 'sklearn'”错误
原因:未安装sklearn模块
方法:
在anaconda 中安装: conda install scikit-learn1.3显示数据
# 读取数据文件 boston.csv文件位置自填
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 显示数据摘要描述信息
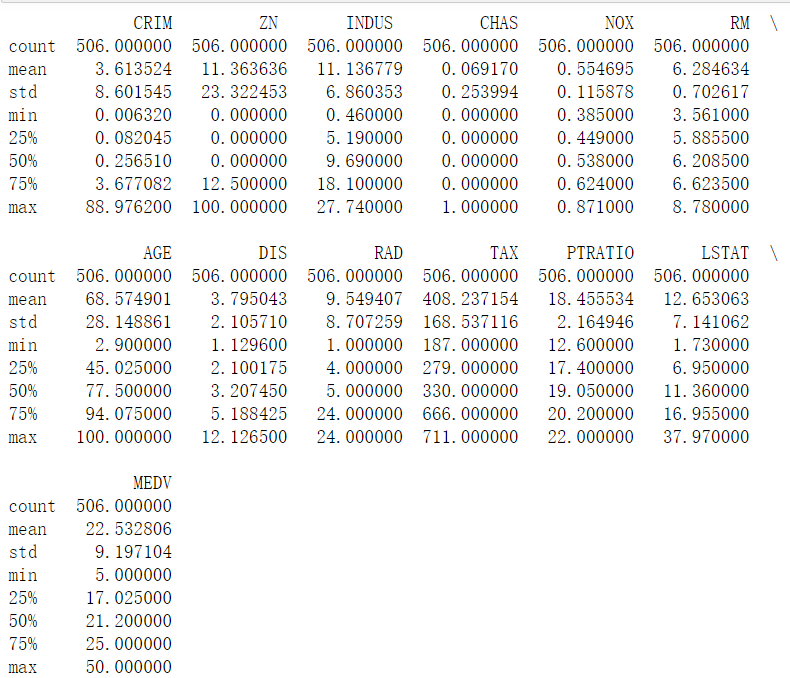
print(df.describe()
# 打印所有数据,只显示前30行和后三十行
print(df)
# 获取df的值
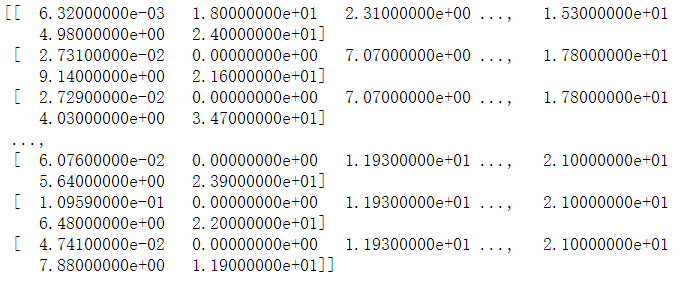
df = df.values
print(df)
# 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df)
# x_data为前12列的数据,实际上是0 - 11列;y_data为最后一列的数据,即12列
x_data = df[:,:12]
y_data = df[:,12]
print(x_data,"\nshape = ",x_data.shape)
print(y_data,"\nshape = ",y_data.shape)
2模型定义
2.1定义训练的占位符
#定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列)2.2定义模型结构
定义模型函数
# 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b)3模型训练
3.1设置训练超参数
# 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.013.2定义均方差损失函数
#定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2))3.3选择优化器
# 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function)常用优化器包括:
tf.train.GradientDescentOptimizer
tf.train.AdadeltaOptimizer
tf.train.AdagradOptimizer
tf.train.AdagradDAOptimizer
tf.train.MomentumOptimizer
tf.train.AdamOptimizer
tf.train.FtrlOptimizer
tf.train.ProximalGradientDescentOptimizer
tf.train.ProximalAdagradOptimizer
tf.train.RMSPropOptimizer3.4声明会话
#声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()
#启动会话
sess.run(init)3.5迭代训练
#迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
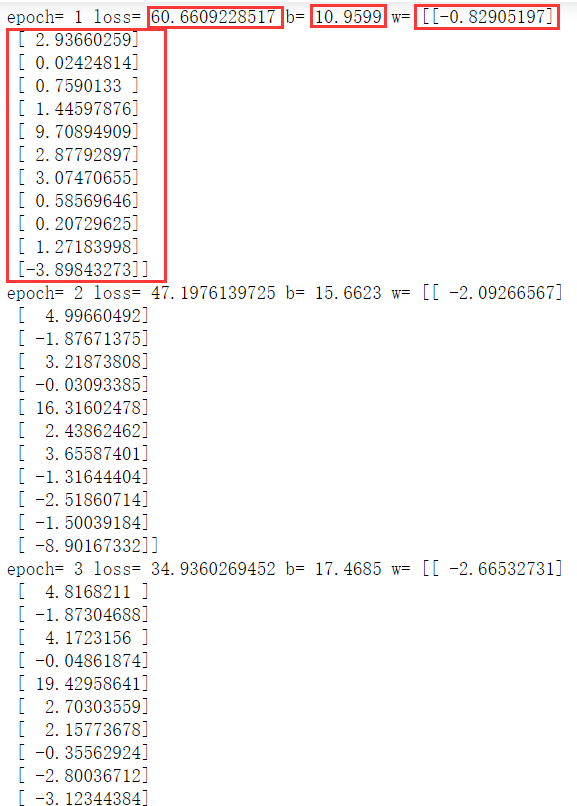
loss_average = loss_sum / len(y_data) print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)
注:训练结果异常
3.6异常明示
3.6.1原因
3.6.2方法
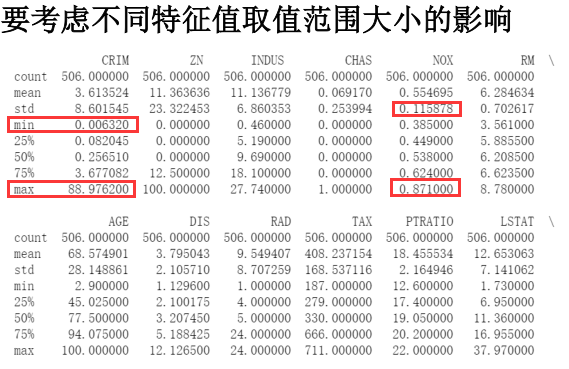
4特征归一化版本
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle # 读取数据文件
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 显示数据摘要描述信息
print(df.describe()) # 获取df的值
df = df.values
print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df)特征归一化
# 对特征数据 【0到11】列 做 (0-1)归一化
for i in range(12):
df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12]
#y_data 为最后一列标签数据 y_data = df[:,12]#定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b) # 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.01 #定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()
#启动会话
sess.run(init) #迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum / len(y_data) print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)
注:Done!
5模型应用
5.1做预测
# 指定一条数据
n = 345
x_test = x_data[n] x_test = x_test.reshape(1,12)
predict = sess.run(pred,feed_dict={x:x_test})
print("预测值:%f" % predict) target = y_data[n]
print("标签值:%f" % target
# 随机确定一条数据
n = np.random.randint(506)
print(n)
x_test = x_data[n] x_test = x_test.reshape(1,12)
predict = sess.run(pred,feed_dict={x:x_test})
print("预测值:%f" % predict) target = y_data[n]
print("标签值:%f" % target)

6可视化训练过程中的损失值
6.1每轮训练后添加一个这一轮的Loss值
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle # 读取数据文件
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 获取df的值
df = df.values
print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12):
df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12]
#y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b) # 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.01 #定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()
#启动会话
sess.run(init)# 用于保存 loss值得列表
loss_list = [] #迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
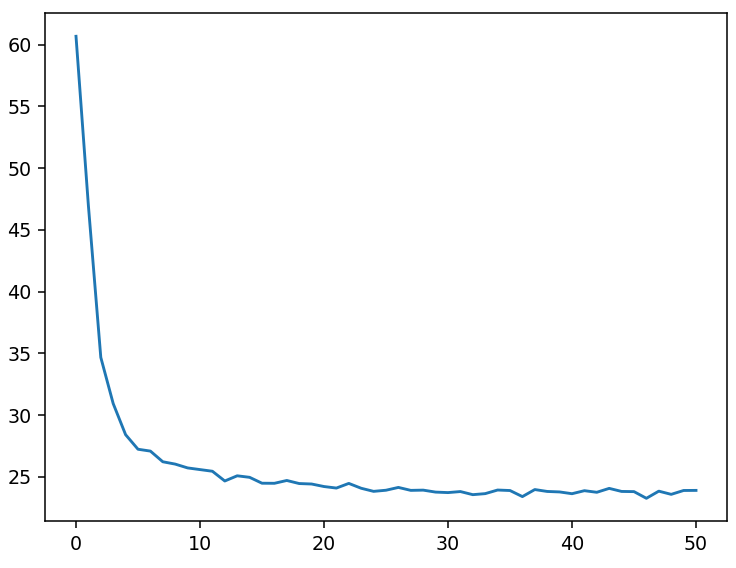
loss_average = loss_sum / len(y_data) loss_list.append(loss_average) # 每轮训练后添加一个这一轮得loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)6.1.2可视化损失值
plt.figure()
plt.plot(loss_list)
# 指定一条数据
n = 345
x_test = x_data[n] x_test = x_test.reshape(1,12)
predict = sess.run(pred,feed_dict={x:x_test})
print("预测值:%f" % predict) target = y_data[n]
print("标签值:%f" % target)
6.2每步(单个样本)训练后添加这个Loss值
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle # 读取数据文件
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 获取df的值
df = df.values
print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12):
df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12]
#y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b) # 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.01 #定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()
#启动会话
sess.run(init)
# 用于保存 loss值得列表
loss_list = [] #迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss
loss_list.append(loss) # 每步添加一次 #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum / len(y_data) print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)6.2.2可视化损失值
plt.figure()
plt.plot(loss_list)
# 指定一条数据
n = 345
x_test = x_data[n] x_test = x_test.reshape(1,12)
predict = sess.run(pred,feed_dict={x:x_test})
print("预测值:%f" % predict) target = y_data[n]
print("标签值:%f" % target)
7加上 TensorBoard 可视化代码
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle # 读取数据文件
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 获取df的值
df = df.values
print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12):
df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12]
#y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b) # 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.01 #定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()
#启动会话
sess.run(init) # 用于保存 loss值得列表
loss_list = [] #迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,loss = sess.run([optimizer,loss_function],feed_dict={x:xs,y:ys}) loss_sum = loss_sum + loss #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum / len(y_data) loss_list.append(loss_average) # 每轮训练后添加一个这一轮得loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)8为TensorFlow可视化准备数据
8.1修改代码
%matplotlib notebook import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.utils import shuffle # 读取数据文件
df = pd.read_csv("D:\学习资料\课程学习资料\深度学习\TensorFlow/boston.csv",header = 0) # 获取df的值
df = df.values
print(df) # 将df转换成np的数组格式 ,内部存储格式不同,方便以后使用np的功能
df = np.array(df)
print(df) # 对特征数据 【0到11】列 做 (0-1)归一化 for i in range(12):
df[:,i] = (df[:,i] - df[:,i].min()) / (df[:,i].max() - df[:,i].min()) #x_data 为归一化后的前12列特征数据 x_data = df[:,:12]
#y_data 为最后一列标签数据 y_data = df[:,12] #定义特征数据和标签数据的占位符
#shape中 None 表示行的数量未知,在实际训练时决定一次代入多少行样本,从一
#个样本的随机SDG到批量SDG都可以
x = tf.placeholder(tf.float32,[None,12],name = "X") #12个特征数据(12列)
y = tf.placeholder(tf.float32,[None,1],name = "Y") #1个标签数据(1列) # 定义一个命名空间
with tf.name_scope("model"):
# w 初始化值为shape = (12,1)的随机数 stddev为标准差
w = tf.Variable(tf.random_normal([12,1],stddev = 0.01),name = "w")
# b 初始化值为 1.0
b = tf.Variable(1.0,name = "b")
#w和x是矩阵相乘,用matmul,不能用mutiply或*
def model(x,w,b):
return tf.matmul(x,w) + b #预测计算操作,前向计算节点
pred = model(x,w,b) # 迭代轮次
train_epochs = 50 # 学习率
learning_rate = 0.01 #定义均方差损失函数
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y -pred,2)) # 创建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function) #声明回话
sess = tf.Session()
#定义初始化变量的操作
init = tf.global_variables_initializer()8.1.1设置日志存储目录
# 设置日志存储目录
logdir = 'd:/log'8.1.2创建一个操作,用于记录损失值loss ,后面在TensorBoard 中SCALARS 栏可见
# 创建一个操作,用于记录损失值loss ,后面在TensorBoard 中SCALARS 栏可见
sum_loss_op = tf.summary.scalar("loss",loss_function)8.1.3把所有需要记录摘要日志文件得合并,方便一次性写入
#把所有需要记录摘要日志文件得合并,方便一次性写入
merged = tf.summary.merge_all()#启动会话
sess.run(init)8.1.4创建摘要得文件写入器(FileWriter)
#创建摘要write,将计算图写入摘要,后面的在TensorBoard中GRAPHS可见
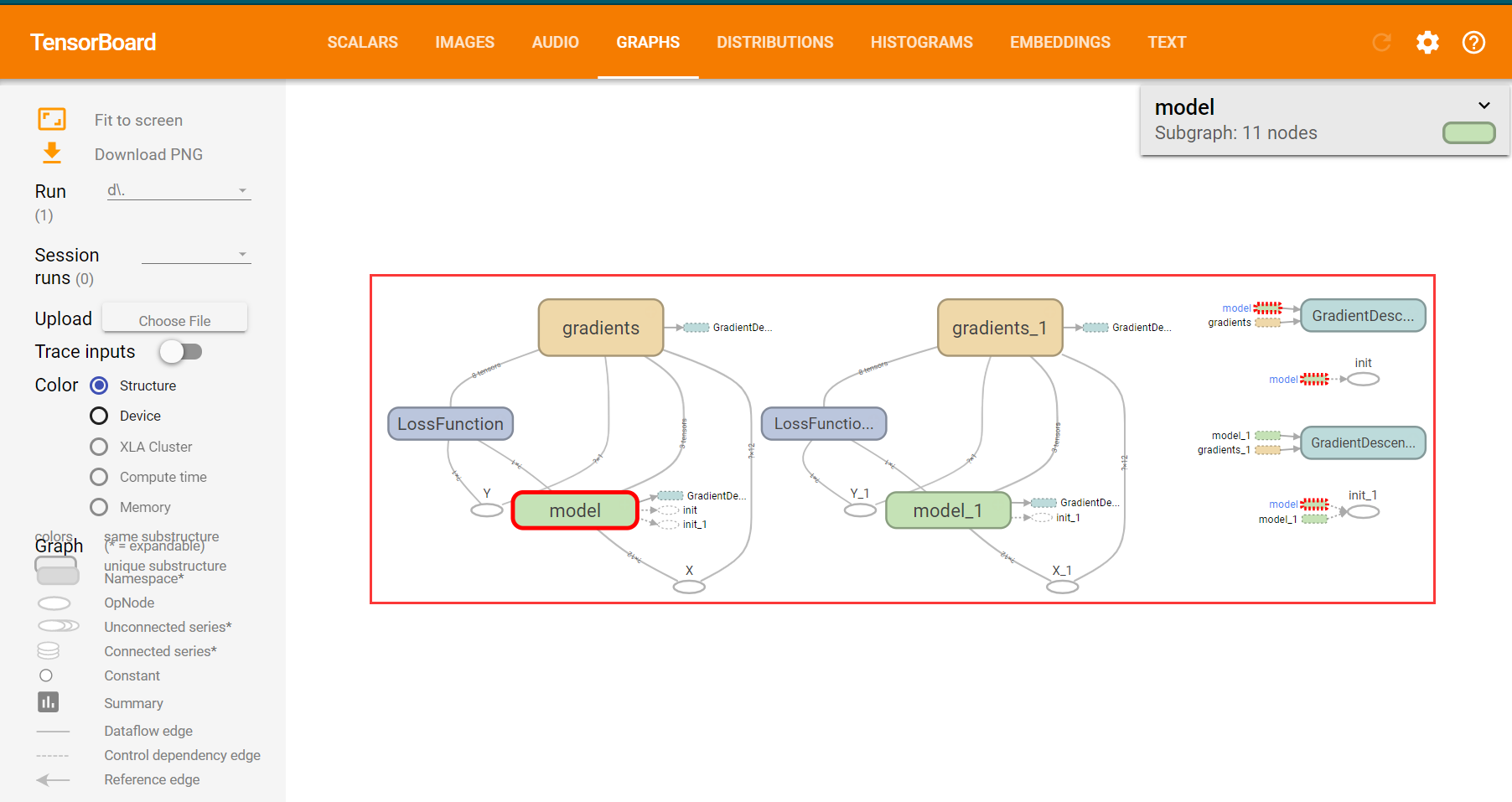
writer = tf.summary.FileWriter(logdir,sess.graph)8.1.5writer.add_summary(summary_str, epoch)
# 用于保存 loss值得列表
loss_list = [] #迭代训练
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data,y_data): #x_data得到的是一维数组,要变成二维数组;y_data得到的是一个常量,要变成二维数组
xs = xs.reshape(1,12)
ys = ys.reshape(1,1)
# Feed 数据必须和Placeholder 的shape 一致
_,summary_str,loss = sess.run([optimizer,sum_loss_op,loss_function],feed_dict={x:xs,y:ys}) writer.add_summary(summary_str,epoch)
loss_sum = loss_sum + loss #打乱数据顺序
x_data,y_data = shuffle(x_data,y_data) b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum / len(y_data) loss_list.append(loss_average) # 每轮训练后添加一个这一轮得loss平均值 print("epoch=",epoch+1,"loss=",loss_average,"b=",b0temp,"w=",w0temp)8.2运行TensorBoard
8.2.1打开Anaconda Prompt
激活TensorFlow: Activate tensorflow
进入日志存储目录 : cd d:\log
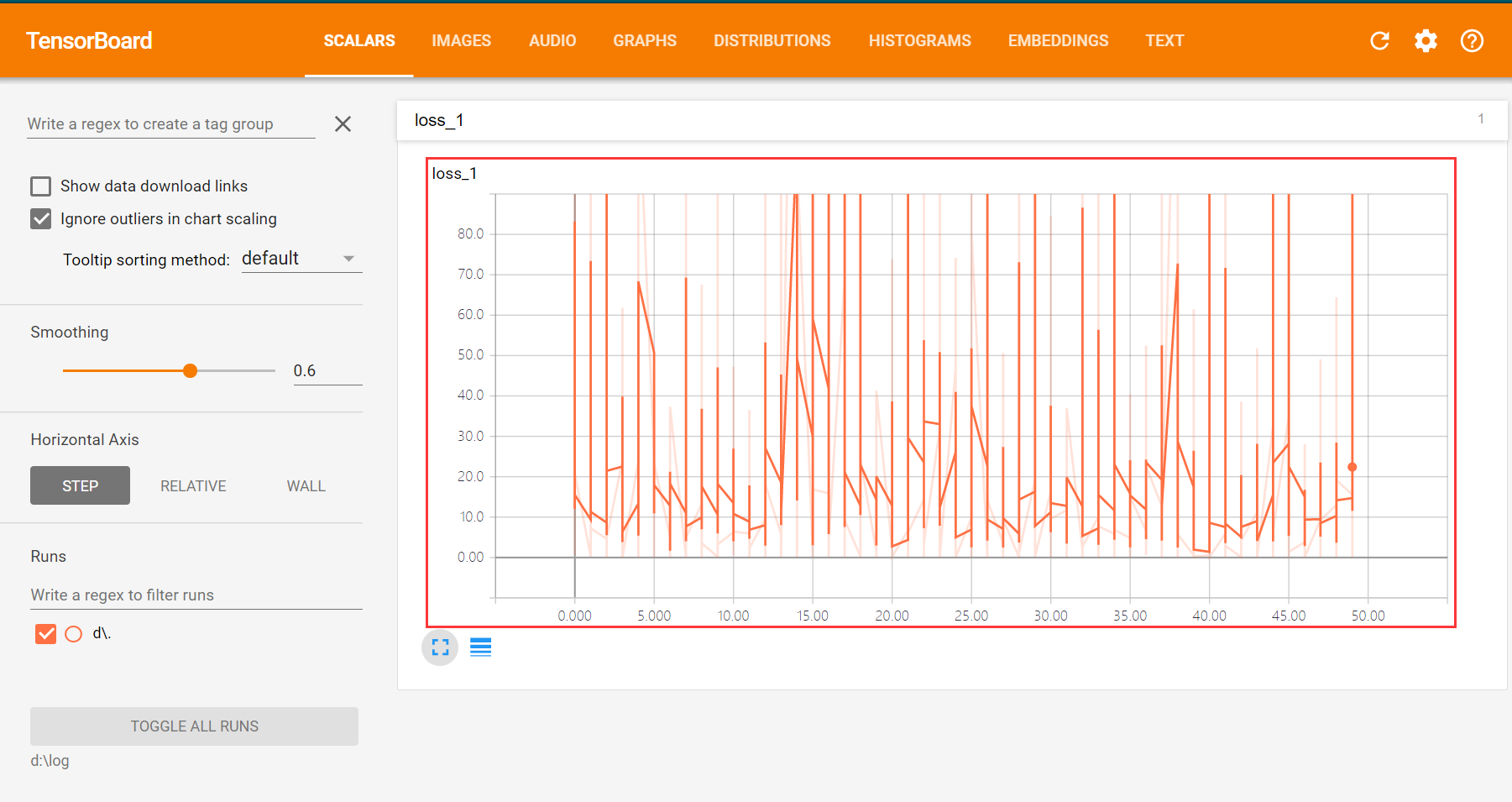
打开TensorBoard: tensorboard --logdir=d:\log8.2.2TensorBoard 查看loss
8.2.3TensorBoard查看计算图














TensorFlow 多元线性回归【波士顿房价】的更多相关文章
- TensorFlow多元线性回归实现
多元线性回归的具体实现 导入需要的所有软件包: 因为各特征的数据范围不同,需要归一化特征数据.为此定义一个归一化函数.另外,这里添加一个额外的固定输入值将权重和偏置结合起来.为此定义函数 appe ...
- Tensorflow之多元线性回归问题(以波士顿房价预测为例)
一.根据波士顿房价信息进行预测,多元线性回归+特征数据归一化 #读取数据 %matplotlib notebook import tensorflow as tf import matplotlib. ...
- TensorFlow从0到1之TensorFlow实现多元线性回归(16)
在 TensorFlow 实现简单线性回归的基础上,可通过在权重和占位符的声明中稍作修改来对相同的数据进行多元线性回归. 在多元线性回归的情况下,由于每个特征具有不同的值范围,归一化变得至关重要.这里 ...
- 【TensorFlow篇】--Tensorflow框架初始,实现机器学习中多元线性回归
一.前述 TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理.Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,T ...
- 利用TensorFlow实现多元线性回归
利用TensorFlow实现多元线性回归,代码如下: # -*- coding:utf-8 -*- import tensorflow as tf import numpy as np from sk ...
- TensorFlow简单线性回归
TensorFlow简单线性回归 将针对波士顿房价数据集的房间数量(RM)采用简单线性回归,目标是预测在最后一列(MEDV)给出的房价. 波士顿房价数据集可从http://lib.stat.cmu.e ...
- machine learning 之 多元线性回归
整理自Andrew Ng的machine learning课程 week2. 目录: 多元线性回归 Multivariates linear regression /MLR Gradient desc ...
- 多元线性回归(Multivariate Linear Regression)简单应用
警告:本文为小白入门学习笔记 数据集: http://openclassroom.stanford.edu/MainFolder/DocumentPage.php?course=DeepLearnin ...
- 斯坦福机器学习视频笔记 Week2 多元线性回归 Linear Regression with Multiple Variables
相比于week1中讨论的单变量的线性回归,多元线性回归更具有一般性,应用范围也更大,更贴近实际. Multiple Features 上面就是接上次的例子,将房价预测问题进行扩充,添加多个特征(fea ...
随机推荐
- OpenStack官方镜像无法ssh登陆
0x00 序 当前主流的Linux系统都有提供可以在OpenStack中直接使用cloud镜像,但当使用从官方网站下载的镜像创建云主机时,你会发现Linux下经常使用的ssh竟然无法登陆新创建好的云主 ...
- Java入门教程七(数组)
数组是最常见的一种数据结构,它是相同类型的用一个标识符封装到一起的基本类型数据序列或者对象序列.数组使用一个统一的数组名和不同的下标来唯一确定数组中的元素.实质上,数组是一个简单的线性序列,因此访问速 ...
- 大厂面试题:集群部署时的分布式 session 如何实现?
面试官心理分析 面试官问了你一堆 dubbo 是怎么玩儿的,你会玩儿 dubbo 就可以把单块系统弄成分布式系统,然后分布式之后接踵而来的就是一堆问题,最大的问题就是分布式事务.接口幂等性.分布式锁, ...
- docker 搭建本地私有仓库
1.使用registry镜像创建私有仓库 安装docker后,可以通过官方提供的 registry 镜像来简单搭建一套本地私有仓库环境: docker run -d -p : registry: 这将 ...
- 基于JWT实现token验证
JWT的介绍 Json Web Token(JWT)是目前比较流行的跨域认证解决方案,是一种基于JSON的开发标准,由于数据是可以经过签名加密的,比较安全可靠,一般用于前端和服务器之间传递信息,也可以 ...
- linux使用php动态安装模块mysqli.so(ext/mysqlnd/mysqlnd.h: 没有那个文件或目录)
由于我先安装的php,再安装的mysql! 正常过程: 1.安装mysql 2.安装php configure时带–with-mysql参数 现在我不想重装,因此使用phpize动态安装mysqli, ...
- HashMap 速描
HashMap 速描 之前简单的整理了Java集合的相关知识,发现HashMap并不是三言两语能够讲明白的,所以专门整理一下HashMap的相关知识. HashMap 存储结构 HashMap是一个哈 ...
- Fabric 源码学习:如何实现批量管理远程服务器?
前不久,我写了一篇<Fabric教程>,简单来说,它是一个用 Python 开发的轻量级的远程系统管理工具,在远程登录服务器.执行 Shell 命令.批量管理服务器.远程部署等场景中,十分 ...
- Notepad++远程连接Linux
为方便编辑Linux上的文件,我们可以用Notepad++的NppFTP插件 工具:Notepad++.CentOS 1.通过ifconfig命令找到主机ip 2.打开Notepad++插件NppFT ...
- 机器学习实用案例解析(1) 使用R语言
简介 统计学一直在研究如何从数据中得到可解释的东西,而机器学习则关注如何将数据变成一些实用的东西.对两者做出如下对比更有助于理解“机器学习”这个术语:机器学习研究的内容是教给计算机一些知识,再让计算机 ...