python笔记9 线程进程 threading多线程模块 GIL锁 multiprocessing多进程模块 同步锁Lock 队列queue IO模型
线程与进程
进程
进程就是一个程序在一个数据集上的一次动态执行过程。进程一般由程序、数据集、进程控制块三部分组成。我们编写的程序用来描述进程要完成哪些功能以及如何完成;数据集则是程序在执行过程中所需要使用的资源;进程控制块用来记录进程的外部特征,描述进程的执行变化过程,系统可以利用它来控制和管理进程,它是系统感知进程存在的唯一标志。
线程
线程的出现是为了降低上下文切换的消耗,提高系统的并发性,并突破一个进程只能干一样事的缺陷,使到进程内并发成为可能。
进程和线程的关系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)CPU分给线程,即真正在CPU上运行的是线程。
串行 并行 并发

多年前单核cpu同时执行两个程序就是并发执行.
同步异步
在计算机领域,同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。举个例子,打电话时就是同步通信,发短息时就是异步通信。
进程实例
from multiprocessing import Process
import threading
import os
import time
def info(name):
print('父进程:',os.getppid()) #打印当前调用函数进程的父进程号
print('进程',os.getpid(),name) #打印当前调用函数进程的进程号
print('----------------------------')
if __name__ == '__main__': #判断是被调用还是在当前文件执行
info('主线程') #先打印当前进程的进程号与打印当前调用函数进程的父进程
p1 = Process(target=info,args=('多进程1',)) #开多进程1打印子进程的进程号与父进程的进程号
p2 = Process(target=info,args=('多进程2',)) #开多进程2打印子进程的进程号与父进程的进程号
p1.start()
p2.start() 父进程: #父进程是pycharm的进程号
进程 主线程 #当前进程号是pycharm调用python.exe的进程号
----------------------------
父进程: #子进程的父进程号是朱金成浩
进程 多进程2
----------------------------
父进程: #主进程下开多个子进程,共有的是一个主进程号
进程 多进程1
---------------------------
threading模块
普通执行脚本时 是串行
import time def coun(n):
print('running on number: %s' % n)
time.sleep(n) start = time.time()
coun(3)
coun(2)
print('用时:%s秒' % (time.time() - start)) #串行,从上到下依次执行,执行完共耗时5秒 running on number: 3
running on number: 2
用时:5.0006632804870605秒
多线程
import time
import threading #开多线程的模块 def coun(n):
print('running on number: %s' % n)
time.sleep(n) start = time.time()
t1 = threading.Thread(target=coun,args=(3,)) #此处 开第一个子线程实传入参数3 此处还是主线程执行的
t2 = threading.Thread(target=coun,args=(2,)) #此处 开第二个子线程实传入参数2 此处也是主线程执行的
t1.start() #到此处执行子线程1
t2.start() #到此处执行子线程2
print('用时:%s秒' % (time.time() - start)) #整个代码除了 t1.start() t2.start()是子线程执行的其他都是主线程执行的 running on number: 3
running on number: 2
用时:0.000995635986328125秒 #主线程并没有 执行函数,因此主线程耗时0.0秒 函数由子线程执行
当启动子线程时,子线程和主线程 并发着一起执行
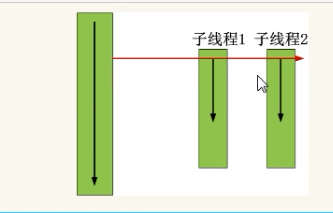
join()
在子线程运行完之前,这个子线程的主线程一直被阻塞,等子线程运行完在继续运行主线程
import time
import threading #开多线程的模块 def coun(n):
print('running on number: %s' % n)
time.sleep(n)
print('执行结束') start = time.time()
t1 = threading.Thread(target=coun,args=(3,)) #此处 开第一个子线程实传入参数3
t2 = threading.Thread(target=coun,args=(2,)) #此处 开第二个子线程实传入参数3
t1.start() #到此处执行子线程1
t2.start() #到此处执行子线程2
t1.join() #在t1运行完之前,主线程一直被阻塞
t2.join() #在t2运行完之前,主线程一直被阻塞
print('用时:%s秒' % (time.time() - start)) #只有在t1和t2共同 运行完之后才继续运行主线程 running on number: 3
running on number: 2
执行结束
执行结束
用时:3.002174139022827秒
循环多个子线程并在最慢的运行完成后结束主线程的方法:
import time
import threading # 开多线程的模块 def c(a):
print('%s开始' %(a))
if a == 5: #如果是5等待1秒
time.sleep(1)
print('%s运行完成'% (a))
elif a == 1: #如果是1等待5秒
time.sleep(5)
print('%s运行完成' % (a))
else:
time.sleep(a)
print('%s运行完成' % (a)) threadd_list = []
d = time.time()
for i in range(1, 6): #循环开新的子进程
t = threading.Thread(target=c,args=(i,))
threadd_list.append(t) #将每个子线程的t加入到列表
t.start() #启动子进程
for i in threadd_list:
i.join() #循环等待所有子进程结束在继续运行 print('共用时%s' % (time.time() - d)) #共耗时 5秒,最慢的线程5秒
1开始
2开始
3开始
4开始
5开始
5运行完成
2运行完成
3运行完成
4运行完成
1运行完成
共用时5.00162410736084
错误方法1:
import time
import threading # 开多线程的模块 def c(a):
print('%s开始' %(a))
if a == 5: #如果是5等待1秒
time.sleep(1)
print('%s运行完成'% (a))
elif a == 1: #如果是1等待5秒
time.sleep(5)
print('%s运行完成' % (a))
else:
time.sleep(a)
print('%s运行完成' % (a)) threadd_list = []
d = time.time()
for i in range(1, 6): #循环开新的子进程
t = threading.Thread(target=c,args=(i,))
threadd_list.append(t)
t.start() #启动子进程
t.join() #这样在循环里join()会在每次循环时都要等待,结果和串行一样
print('共用时%s' % (time.time() - d)) #共耗时 1开始
1运行完成
2开始
2运行完成
3开始
3运行完成
4开始
4运行完成
5开始
5运行完成
共用时15.006914854049683
错误方法2:
import time
import threading # 开多线程的模块 def c(a):
print('%s开始' %(a))
if a == 5: #如果是5等待1秒
time.sleep(1)
print('%s运行完成'% (a))
elif a == 1: #如果是1等待5秒
time.sleep(5)
print('%s运行完成' % (a))
else:
time.sleep(a)
print('%s运行完成' % (a)) threadd_list = []
d = time.time()
for i in range(1, 6): #循环开新的子进程
t = threading.Thread(target=c,args=(i,))
threadd_list.append(t)
t.start() #启动子进程
t.join() #放在循环外,当循环结束时,会执行最后循环的t ,最后的是5对应是1秒
print('共用时%s' % (time.time() - d)) #共耗时 1开始
2开始
3开始
4开始
5开始
5运行完成
共用时1.0022823810577393
2运行完成
3运行完成
4运行完成
1运行完成
setDaemon(True)
将线程声明为守护线程,必须在start()方法之前设置,作用是当主线程运行完成后,不管子线程是否运行完,都随主线程一起退出,与join的作用相反,join是主线程等待子线程结束在继续往下执行
import time
import threading # 开多线程的模块 def c(a):
print('%s开始' %(a))
if a == 5: #如果是5等待1秒
time.sleep(1)
print('%s运行完成'% (a))
elif a == 1: #如果是1等待5秒
time.sleep(5)
print('%s运行完成' % (a))
else:
time.sleep(a)
print('%s运行完成' % (a)) threadd_list = []
d = time.time()
for i in range(1, 6): #循环开新的子进程
t = threading.Thread(target=c,args=(i,))
threadd_list.append(t)
t.setDaemon(True) #主程序结束子程序结束
t.start() #启动子进程 print('共用时%s' % (time.time() - d)) 1开始
2开始
3开始
4开始
5开始
共用时0.0019898414611816406 #主程序共耗时0秒,主程序结束子程序也结束
当有多个子线程而只设置一个守护线程则没有意义,
因为其他子线程并没有运行完,所以主线程并没有真正意义上的运行完,只有所有的子线程都是守护线程才能在主线程运行完直接全部结束,
否则只要有一个子线程在运行都要继续等待.
import time
import threading # 开多线程的模块 def c(a):
print('%s开始' %(a))
if a == 5: #如果是5等待1秒
time.sleep(1)
print('%s运行完成'% (a))
elif a == 1: #如果是1等待5秒
time.sleep(5)
print('%s运行完成' % (a))
else:
time.sleep(a)
print('%s运行完成' % (a)) threadd_list = []
d = time.time()
for i in range(1, 6): #循环开新的子进程
t = threading.Thread(target=c,args=(i,))
threadd_list.append(t)
if i == 1: #只开启1的守护线程,
t.setDaemon(True)
t.start() #启动子进程 print('共用时%s' % (time.time() - d)) #共耗时 1开始
2开始
3开始
4开始
5开始
共用时0.0009970664978027344
5运行完成
2运行完成
3运行完成
4运行完成 #此处缺少1运行完成,因为当1运行完时之前其他所有子线程都运行结束了,也意味着主线程结束了,因此1与主线程一起结束了
GIL锁
由于GIL锁的存在,python不能并行,只能并发, 因此python不能算是真正意义上的多线程并行运算.,只能是占用一个cpu的一个线程的并发运算
因此,对于密集型运算,python不适用 threading多线程模块
密集型计算串行:
import time
import threading # 开多线程的模块 def aa():
a = 1
for i in range(1,100000):
a *= i
def bb():
a = 1
for i in range(1,100000):
a *= i
c = time.time()
aa()
bb()
print('耗时%s' %(time.time() - c)) 耗时5.802525758743286 #密集型并行计算总耗时5.8秒
密集型threading多线程计算 并发:
import time
import threading # 开多线程的模块 def aa():
a = 1
for i in range(1,100000):
a *= i
def bb():
a = 1
for i in range(1,100000):
a *= i
c = time.time()
t1 = threading.Thread(target=aa)
t2 = threading.Thread(target=bb)
t1.start()
t2.start()
t1.join()
t2.join()
print('耗时%s' %(time.time() - c)) 耗时6.302755832672119 #密集型threading多线程计算并发 耗时6.3秒 , 计算量越大差距越大
对于密集型计算的开启multiprocessing多进程会快 ,但是我们不可能无限量开进程
multiprocessing多进程模块
def aa():
a = 1
for i in range(1, 100000):
a *= i def bb():
a = 1
for i in range(1, 100000):
a *= i
if __name__ == '__main__': #多进程模块必须这样写if判断,否则报错
import time
import multiprocessing # 引用多进程模块
c = time.time()
t1 = multiprocessing.Process(target=aa) #和多线程用法基本一致
t2 = multiprocessing.Process(target=bb)
t1.start()
t2.start()
t1.join() #也有join和setDaemon()方法
t2.join()
print('耗时%s' %(time.time() - c))
耗时4.506261587142944
同步锁Lock
同步锁保证数据的安全,当一个线程获取这把锁后,只有他释放了其他线程才能获取继续执行,以此类推
不加同步锁:
import threading
import time
def jnum():
global num
xx = num #每次代码走到这里都把num的值赋值给xx,因为是多线程,每个线程在循环时,在0.1秒内就循环完成了 因此每个线程的值都是10
time.sleep(0.1)
num = xx - #每个线程都是执行10- num =
thread_list = []
for i in range():
f1 = threading.Thread(target=jnum,)
thread_list.append(f1)
f1.start()
for i in thread_list:
i.join()
print(num)
加同步锁:
import threading
import time
R=threading.Lock() #同步锁
def jnum():
R.acquire() #加锁,每个锁只能给一个线程, 当以一个线程运行到这里获取到锁时,往后的线程会处在等待状态,等待第一个锁释放时在获取锁,以此类推.
global num
xx = num
time.sleep(0.1)
num = xx -
R.release() #解锁 num =
thread_list = []
for i in range():
f1 = threading.Thread(target=jnum,)
thread_list.append(f1)
f1.start()
for i in thread_list:
i.join()
print(num)
0
队列queue
import queue #队列
q = queue.Queue() #创建队列,默认先进先出模式:FIFO q.put() #put存
q.put()
q.put()
print(q.get()) #get取
print(q.get())
print(q.get())
print(q.get()) #无值阻塞,等待新的值进入
maxsize
import queue #队列
q = queue.Queue(maxsize=) #创建队列,默认先进先出模式:FIFO maxsize=3 只能存3个值,如果要在往里存,需要取出来才能存 q.put() #put存
q.put()
q.put()
print(q.get()) #get取
print(q.get())
print(q.get())
print(q.get()) #无值阻塞,等待新的值进入
import queue #队列
q = queue.Queue(maxsize=) #创建队列,默认先进先出模式:FIFO q.put() #put存
q.put()
q.put()
q.put(,False) #加False当存满后又有值进来会报错
print(q.get()) #get取
print(q.get())
print(q.get())
print(q.get()) #无值阻塞,等待新的值进入 Traceback (most recent call last):
File "F:/python24期/L010-老男孩教育-Python24期VIP视频-mp4/练习/lianxi.py", line 8, in <module>
q.put(444,False) #加False当存满后又有值进来会报错
File "C:\Python36\lib\queue.py", line 130, in put
raise Full
queue.Full
import queue #队列
q = queue.Queue(maxsize=) #创建队列,默认先进先出模式:FIFO q.put() #put存
q.put()
q.put() print(q.get()) #get取
print(q.get())
print(q.get())
print(q.get(block=False)) #加block=False 当取完时 再取会报错 111
Traceback (most recent call last):
222
File "F:/python24期/L010-老男孩教育-Python24期VIP视频-mp4/练习/lianxi.py", line 12, in <module>
333
print(q.get(block=False)) #无值阻塞,等待新的值进入
File "C:\Python36\lib\queue.py", line 161, in get
raise Empty
queue.Empty
此包中的常用方法(q = Queue.Queue()):
q.qsize() 返回队列的大小
q.empty() 如果队列为空,返回True,反之False
q.full() 如果队列满了,返回True,反之False
q.full 与 maxsize 大小对应
q.get([block[, timeout]]) 获取队列,timeout等待时间
q.get_nowait() 相当q.get(False)非阻塞
q.put(item) 写入队列,timeout等待时间
q.put_nowait(item) 相当q.put(item, False)
q.task_done() 在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号
q.join() 实际上意味着等到队列为空,再执行别的操作
LifoQueue创建队列后进先出
import queue #队列
q = queue.LifoQueue() #后进先出队列
q.put() #put存
q.put()
q.put() print(q.get()) #get取
print(q.get())
print(q.get())
queue.PriorityQueue创建优先级队里
import queue #队列
q = queue.PriorityQueue() #创建优先级队里 根据优先级取
q.put([,]) #put存
q.put([,])
q.put([,]) print(q.get()) #get取
print(q.get())
print(q.get()) [, ]
[, ]
[, ]
生产者消费者模型
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
这就像,在餐厅,厨师做好菜,不需要直接和客户交流,而是交给前台,而客户去饭菜也不需要不找厨师,直接去前台领取即可,这也是一个结耦的过程。
import random, time
import queue, threading q = queue.Queue() def chushi(name): #厨师做包子
count =
while count < : #做十次
print('making.........')
s = random.randrange() #随机生成3以内的随机数
time.sleep(s)
q.put(count) #把生成的包子放到消息队列,等待客人来取
print('%s制作了%s个包子' % (name, count))
count +=
print('OK........') def keren(name):
count =
while count < :
print('%s来了' %(name))
s = random.randrange()
time.sleep(s)
print('%s等待了%s秒' %(name,s))
if not q.empty():
data = q.get()
print('%s吃了%s个包子'%(name,data))
else:
print('没有包子')
count +=
p = threading.Thread(target=chushi,args=('庖丁',))
c = threading.Thread(target=keren,args=('小张',))
c1 = threading.Thread(target=keren,args=('小王',))
c2 = threading.Thread(target=keren,args=('小李',))
p.start()
c.start()
c1.start()
c2.start()
IO模型
linux下的 network IO.
1.阻塞模型 blocking IO
全程阻塞
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据。对于network io来说,很多时候数据在一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候kernel就要等待足够的数据到来。而在用户进程这边,整个进程会被阻塞。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
我们常写的都拿基本都是阻塞模型
2.非阻塞模型 nonblocking IO
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。所以,用户进程其实是需要不断的主动询问kernel数据好了没有。
在网络IO时候,非阻塞IO也会进行recvform系统调用,检查数据是否准备好,与阻塞IO不一样,”非阻塞将大的整片时间的阻塞分成N多的小的阻塞, 所以进程不断地有机会 ‘被’ CPU光顾”。即每次recvform系统调用之间,cpu的权限还在进程手中,这段时间是可以做其他事情的,
也就是说非阻塞的recvform系统调用调用之后,进程并没有被阻塞,内核马上返回给进程,如果数据还没准备好,此时会返回一个error。进程在返回之后,可以干点别的事情,然后再发起recvform系统调用。重复上面的过程,循环往复的进行recvform系统调用。这个过程通常被称之为轮询。轮询检查内核数据,直到数据准备好,再拷贝数据到进程,进行数据处理。需要注意,拷贝数据整个过程,进程仍然是属于阻塞的状态。
服务端
import time
import socket
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sk.setsockopt
sk.bind(('127.0.0.1',))
sk.listen()
sk.setblocking(False) #非阻塞
while True:
try:
print ('waiting client connection .......')
connection,address = sk.accept() # 进程主动轮询
print("+++",address)
client_messge = connection.recv()
print(str(client_messge,'utf8'))
connection.close()
except Exception as e:
print (e)
time.sleep()
客户端
import time
import socket
sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) while True:
sk.connect(('127.0.0.1',))
print("hello")
sk.sendall(bytes("hello","utf8"))
time.sleep()
break
优点:能够在等待任务完成的时间里干其他活了(包括提交其他任务,也就是 “后台” 可以有多个任务在同时执行)。
缺点:任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
3 IO多复路 IO multiplexing(select,poll,epoll) ****
服务端
import socket
import select
sk=socket.socket()
sk.bind(("127.0.0.1",))
sk.listen()
sk.setblocking(False)
inputs=[sk,] #创建一个列表存放套接字,第一个列表放socket对象sk. while True:
r,w,e=select.select(inputs,[],[],) #监听事件驱动 一但inputs列表里有变动,就将变动的值赋给r,如果有链接进来就是sk有变动,r就等于sk. for obj in r:
if obj==sk: #如果r等于sk .
conn,add=obj.accept() #取sk的conn
inputs.append(conn) #将conn添加至列表 此时因sk变动发生的执行结束,并且将conn加入到inputs列表,因此列表有变动,变动为conn,conn赋值给r继续执行.
else: #此时r为conn不是sk 执行else data_byte=obj.recv() #以下为正常socket的tcp连接
print(str(data_byte,'utf8'))
if not data_byte: #在linux系统时,如果强行关掉了客户端 客户端的返回值是空
inputs.remove(obj) #删除此时的客户端的conn连接
continue
inp=input('回答%s: >>>'%inputs.index(obj))
obj.sendall(bytes(inp,'utf8'))
客户端
import socket
sk=socket.socket()
sk.connect(('127.0.0.1',)) while True:
inp=input(">>>>") # how much one night?
sk.sendall(bytes(inp,"utf8"))
data=sk.recv()
print(str(data,'utf8'))
4. 异步 asynchronous IO
python笔记9 线程进程 threading多线程模块 GIL锁 multiprocessing多进程模块 同步锁Lock 队列queue IO模型的更多相关文章
- python笔记9-多线程Threading之阻塞(join)和守护线程(setDaemon)
python笔记9-多线程Threading之阻塞(join)和守护线程(setDaemon) 前言 今天小编YOYO请xiaoming和xiaowang吃火锅,吃完火锅的时候会有以下三种场景: - ...
- python笔记-1(import导入、time/datetime/random/os/sys模块)
python笔记-6(import导入.time/datetime/random/os/sys模块) 一.了解模块导入的基本知识 此部分此处不展开细说import导入,仅写几个点目前的认知即可.其 ...
- 人生苦短之我用Python篇(线程/进程、threading模块:全局解释器锁gil/信号量/Event、)
线程: 有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元.是一串指令的集合.线程是程序中一个单一的顺序控制流程.进程内一个相对独立的.可调度的执行单元,是 ...
- python笔记7-多线程threading之函数式
前言 1.python环境3.62.threading模块系统自带 单线程 1.平常写的代码都是按顺序挨个执行的,就好比吃火锅和哼小曲这两个行为事件,定义成两个函数,执行的时候,是先吃火锅再哼小曲,这 ...
- python网络编程(进程与多线程)
multiprocessing模块 由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程. multiproce ...
- Python笔记(十一):多线程
(二)和(三)不感兴趣的可以跳过,这里参考了<深入理解计算机系统>第一章和<Python核心编程>第四章 (一) 多线程编程 一个程序包含多个子任务,并且子任务之间相 ...
- 15.python并发编程(线程--进程--协程)
一.进程:1.定义:进程最小的资源单位,本质就是一个程序在一个数据集上的一次动态执行(运行)的过程2.组成:进程一般由程序,数据集,进程控制三部分组成:(1)程序:用来描述进程要完成哪些功能以及如何完 ...
- Python进阶(3)_进程与线程中的lock(线程中互斥锁、递归锁、信号量、Event对象、队列queue)
1.同步锁 (Lock) 当全局资源(counter)被抢占的情况,问题产生的原因就是没有控制多个线程对同一资源的访问,对数据造成破坏,使得线程运行的结果不可预期.这种现象称为“线程不安全”.在开发过 ...
- Python学习之==>线程&&进程
一.什么是线程(thread) 线程是操作系统能够进行运算调度的最小单位.它被包含在进程之中,是进程中的实际运作单位.一个线程指的是进程中一个单一顺序的控制流,一个进程中可以包含多个线程,每条线程并行 ...
随机推荐
- 科大讯飞语音识别Demo创建
1.下载官方SDK https://www.xfyun.cn/sdk/dispatcher 2.打开AS,选择import project 3.导入mscV5PlusDemo 4.解决ERROR: ...
- Educational Codeforces Round 41 (Rated for Div. 2) D. Pair Of Lines (几何,随机)
D. Pair Of Lines time limit per test 2 seconds memory limit per test 256 megabytes input standard in ...
- 基本排序-冒泡/选择/插入(python)
# -*- coding: utf-8 -*- import random def bubble_sort(seq): n = len(seq) for i in range(n-1): print( ...
- can't assign to struct fileds in map
原文: https://haobook.readthedocs.io/zh_CN/latest/periodical/201611/zhangan.html --------------------- ...
- Parameter 0 of method redisTemplate in org.springframework.boot.autoconfigure.data.redis.RedisAutoConfiguration required a bean of type 'org.springframework.data.redis.connection.RedisConnectionFactor
Error starting ApplicationContext. To display the conditions report re-run your application with 'de ...
- VBA字典
'字典并不存在于VBA中,需要调用 '调用方式1(前期绑定): '工具 --引用 - -浏览 - -找到scrrun.dll - 确定 '调用方式2 (后期绑定): ' Set d = CreateO ...
- 如何在没有代理的情况下编译 tidb server
这里主要介绍 tidb server 的编译, ti kv 和 ti pd 的编译不在本文范围内: go 语言 1.11 版本之后支持 go.mod, 依赖包在 go.mod 里生成, 如果 go. ...
- 学到了林海峰,武沛齐讲的Day18-4 文件操作
print(data.decode('utf-8')) 转换utf-8格式f.write('杨件'.encode('utf-8')) 转换为bytes# f.write(bytes('1111\n', ...
- exam8.3
rank25凉凉好吧......T1:... 一开始完全** 手玩给的那张图(不放图,我太饿把图吃了) 发现对于任一个节点,减去上一个比他小的斐波那契数就是父 ...
- 【IOI2019】2048矩形模拟
/* dos windows 25*80 */ #include <algorithm> #include <windows.h> #include <iostream& ...