k8s-日志收集架构
日志收集
Kubernetes 集群中监控系统的搭建,除了对集群的监控报警之外,还有一项运维工作是非常重要的,那就是日志的收集。
介绍
应用程序和系统日志可以帮助我们了解集群内部的运行情况,日志对于我们调试问题和监视集群情况也是非常有用的。而且大部分的应用都会有日志记录,对于传统的应用大部分都会写入到本地的日志文件之中。对于容器化应用程序来说则更简单,只需要将日志信息写入到 stdout 和 stderr 即可,容器默认情况下就会把这些日志输出到宿主机上的一个 JSON 文件之中,同样我们也可以通过 docker logs 或者 kubectl logs 来查看到对应的日志信息。
但是,通常来说容器引擎或运行时提供的功能不足以记录完整的日志信息,比如,如果容器崩溃了、Pod 被驱逐了或者节点挂掉了,我们仍然也希望访问应用程序的日志。所以,日志应该独立于节点、Pod 或容器的生命周期,这种设计方式被称为 cluster-level-logging,即完全独立于 Kubernetes 系统,需要自己提供单独的日志后端存储、分析和查询工具。
Kubernetes 中的基本日志
下面这个示例是 Kubernetes 中的一个基本日志记录的示例,直接将数据输出到标准输出流,如下:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']
将上面文件保存为 counter-pod.yaml,该 Pod 每秒输出一些文本信息,创建这个 Pod:
$ kubectl create -f counter-pod.yaml
pod "counter" created
创建完成后,可以使用 kubectl logs 命令查看日志信息:
$ kubectl logs counter
0: Thu Dec 27 15:47:04 UTC 2018
1: Thu Dec 27 15:47:05 UTC 2018
2: Thu Dec 27 15:47:06 UTC 2018
3: Thu Dec 27 15:47:07 UTC 2018
......
Kubernetes 日志收集
Kubernetes 集群本身不提供日志收集的解决方案,一般来说有主要的3种方案来做日志收集:
- 在节点上运行一个 agent 来收集日志
- 在 Pod 中包含一个 sidecar 容器来收集应用日志
- 直接在应用程序中将日志信息推送到采集后端
节点日志采集代理
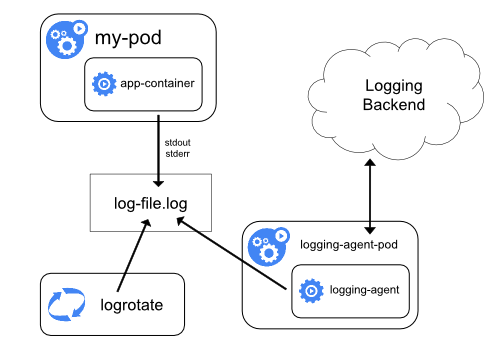 node agent
node agent
通过在每个节点上运行一个日志收集的 agent 来采集日志数据,日志采集 agent 是一种专用工具,用于将日志数据推送到统一的后端。一般来说,这种 agent 用一个容器来运行,可以访问该节点上所有应用程序容器的日志文件所在目录。
由于这种 agent 必须在每个节点上运行,所以直接使用 DaemonSet 控制器运行该应用程序即可。在节点上运行一个日志收集的 agent 这种方式是最常见的一直方法,因为它只需要在每个节点上运行一个代理程序,并不需要对节点上运行的应用程序进行更改,对应用程序没有任何侵入性,但是这种方法也仅仅适用于收集输出到 stdout 和 stderr 的应用程序日志。
以 sidecar 容器收集日志
我们看上面的图可以看到有一个明显的问题就是我们采集的日志都是通过输出到容器的 stdout 和 stderr 里面的信息,这些信息会在本地的容器对应目录中保留成 JSON 日志文件,所以直接在节点上运行一个 agent 就可以采集到日志。但是如果我们的应用程序的日志是输出到容器中的某个日志文件的话呢?这种日志数据显然只通过上面的方案是采集不到的了。
用 sidecar 容器重新输出日志
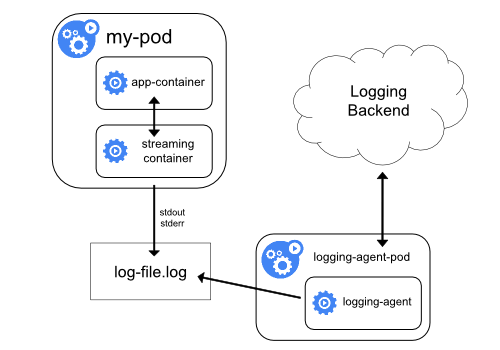 sidecar agent
sidecar agent
对于上面这种情况我们可以直接在 Pod 中启动另外一个 sidecar 容器,直接将应用程序的日志通过这个容器重新输出到 stdout,这样是不是通过上面的节点日志收集方案又可以完成了。
由于这个 sidecar 容器的主要逻辑就是将应用程序中的日志进行重定向打印,所以背后的逻辑非常简单,开销很小,而且由于输出到了 stdout 或者 stderr,所以我们也可以使用 kubectl logs 来查看日志了。
下面的示例是在 Pod 中将日志记录在了容器的两个本地文件之中:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
由于 Pod 中容器的特性,我们可以利用另外一个 sidecar 容器去获取到另外容器中的日志文件,然后将日志重定向到自己的 stdout 流中,可以将上面的 YAML 文件做如下修改:(two-files-counter-pod-streaming-sidecar.yaml)
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
直接创建上面的 Pod:
$ kubectl create -f two-files-counter-pod-streaming-sidecar.yaml
pod "counter" created
运行成功后,我们可以通过下面的命令来查看日志的信息:
$ kubectl logs counter count-log-1
0: Mon Jan 1 00:00:00 UTC 2001
1: Mon Jan 1 00:00:01 UTC 2001
2: Mon Jan 1 00:00:02 UTC 2001
...
$ kubectl logs counter count-log-2
Mon Jan 1 00:00:00 UTC 2001 INFO 0
Mon Jan 1 00:00:01 UTC 2001 INFO 1
Mon Jan 1 00:00:02 UTC 2001 INFO 2
...
这样前面节点上的日志采集 agent 就可以自动获取这些日志信息,而不需要其他配置。
这种方法虽然可以解决上面的问题,但是也有一个明显的缺陷,就是日志不仅会在原容器文件中保留下来,还会通过 stdout 输出后占用磁盘空间,这样无形中就增加了一倍磁盘空间。
使用 sidecar 运行日志采集 agent
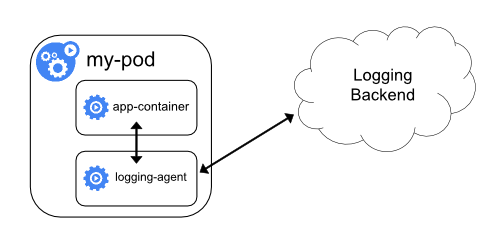 sidecar agent
sidecar agent
如果你觉得在节点上运行一个日志采集的代理不够灵活的话,那么你也可以创建一个单独的日志采集代理程序的 sidecar 容器,不过需要单独配置和应用程序一起运行。
不过这样虽然更加灵活,但是在 sidecar 容器中运行日志采集代理程序会导致大量资源消耗,因为你有多少个要采集的 Pod,就需要运行多少个采集代理程序,另外还无法使用 kubectl logs 命令来访问这些日志,因为它们不受 kubelet 控制。
举个例子,你可以使用的Stackdriver,它使用fluentd作为记录剂。以下是两个可用于实现此方法的配置文件。第一个文件包含配置流利的ConfigMap。
下面是 Kubernetes 官方的一个 fluentd 的配置文件示例,使用 ConfigMap 对象来保存:
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>
上面的配置文件是配置收集原文件 /var/log/1.log 和 /var/log/2.log 的日志数据,然后通过 google_cloud 这个插件将数据推送到 Stackdriver 后端去。
下面是我们使用上面的配置文件在应用程序中运行一个 fluentd 的容器来读取日志数据:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
上面的 Pod 创建完成后,容器 count-agent 就会将 count 容器中的日志进行收集然后上传。当然,这只是一个简单的示例,我们也完全可以使用其他的任何日志采集工具来替换 fluentd,比如 logstash、fluent-bit 等等。
直接从应用程序收集日志
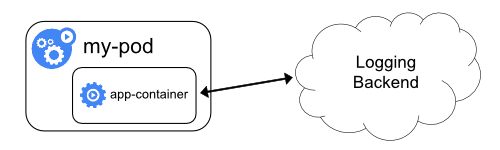 app log
app log
k8s-日志收集架构的更多相关文章
- k8s日志收集及存档
k8s日志收集架构图 利用阿里开源的工具log-pilot,往kafka内写日志,然后吐一份至es,另外一份用flume消费kafka数据落盘
- k8s日志收集方案
k8s日志收集方案 三种收集方案的优缺点: 下面我们就实践第二种日志收集方案: 一.安装ELK 下面直接采用yum的方式安装ELK(源码包安装参考:https://www.cnblogs.com/De ...
- k8s 日志收集之 EFK
如今越来越多的应用部署在容器之中,如何收集日志也是一个很重要的问题.服务出问题了,排查问题需要给开发看日志.服务一般会在多个不同的 pod 中,一个一个的登进去看也的确不方便.业务数据统计也需要日志. ...
- K8S学习笔记之k8s日志收集实战
0x00 简介 本文主要介绍在k8s中收集应用的日志方案,应用运行中日志,一般情况下都需要收集存储到一个集中的日志管理系统中,可以方便对日志进行分析统计,监控,甚至用于机器学习,智能分析应用系统问题, ...
- Kubernetes 日志:日志收集架构
应用程序和系统日志可以帮助我们了解集群内部的运行情况,日志对于我们调试问题和监视集群情况也是非常有用的.而且大部分的应用都会有日志记录,对于传统的应用大部分都会写入到本地的日志文件之中.对于容器化应用 ...
- k8s日志收集配置
容器日志样例 172.101.32.1 - - [03/Jun/2019:17:14:10 +0800] "POST /ajaxVideoQueues!queryAllUser.action ...
- 关于K8s集群器日志收集的总结
本文介绍了kubernetes官方提供的日志收集方法,并介绍了Fluentd日志收集器并与其他产品做了比较.最后介绍了好雨云帮如何对k8s进行改造并使用ZeroMQ以消息的形式将日志传输到统一的日志处 ...
- 微服务从代码到k8s部署应有尽有系列(十一、日志收集)
我们用一个系列来讲解从需求到上线.从代码到k8s部署.从日志到监控等各个方面的微服务完整实践. 整个项目使用了go-zero开发的微服务,基本包含了go-zero以及相关go-zero作者开发的一些中 ...
- 基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
- 基于Flume的美团日志收集系统(一)架构和设计【转】
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
随机推荐
- Nginx 之负载均衡与反向代理
负载均衡服务器策略: 1.轮循 每个请求逐个分发到后端服务器 2.加权轮循 按照分配的权重将请求分发到后端服务器 3.ip hash 轮询的基础上,保持一个客户端多次请求分发到一台后端服务器上 一 ...
- Python语法 - 推导式
推导式分为列表推导式(list),字典推导式(dict),集合推导式(set)三种 列表推导式(list comprehension)最擅长的方式就是对整个列表分别做相同的操作,并且返回得到一个新的列 ...
- Oracle JDBC 连接池
1.简介 数据库连接池负责分配.管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个:释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据 ...
- SCRIPT438: 对象不支持“trim”属性或方法
关于ie9以下不支持trim()方法 可以在自己封装的框架中加入如下.或直接调用也行. if(!String.prototype.trim) { String.prototype.trim = fun ...
- MapReduce Combiner
Combiner编程(可选步骤,视情况而定!) combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能. 如果不用combiner,那么所有的结果都是reduce ...
- 慎用array_filter函数
array_filter (PHP 4 >= 4.0.6, PHP 5, PHP 7) array_filter - 用回调函数过滤数组中的单元 说明 array array_filter ( ...
- Android Popwindow使用总结
Android Popwindow使用总结 转 https://www.jianshu.com/p/3812ff5ef272 1.基本使用方法 View view = getLayoutInflate ...
- web开发的三层架构
Web层 接收客户端发送过来的数据,然后需要将数据传递给service层 Service层 业务逻辑层:业务:比如检验用户名的是否存在,如果不存在则需要把用户的数据存储在数据库中,如果存在,给web返 ...
- CISCN 2019 writeup
划水做了两个pwn和两个逆向...... 二进制题目备份 Re easyGO Go语言,输入有Please字样,ida搜索sequence of bytes搜please的hex值找到字符串变量,交叉 ...
- save()和savaorupdate的区别
hibernate的保存 hibernate对于对象的保存提供了太多的方法,他们之间有很多不同,在这里细说一下,以便区别: 一.预备知识: 在所有之前,说明一下,对于hibernate,它的对 ...