# 机器学习算法总结-第一天(KNN、决策树)
KNN算法总结
KNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别。(监督)
k近邻算法(knn)是一种基本的分类与回归的算法,k-means是一种基本的聚类方法。
在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
缺点:它无法给出任何数据的基础结构信息,因此我们无法知道平均实例样本和典型事例样本的特征。
KNN中的K值手工输入或者由我们经验决定。
1、“肘部原则”
2、在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法(简单来说,就是一部分样本做训练集,一部分做测试集)来选择最优的K值。
K值较小,则模型复杂度较高,容易发生过拟合。
K值选取的太大,导致分类模糊。
决策树
选择分裂属性是要找出能够使所有孩子节点数据最纯的属性,决策树使用信息增益或者信息增益率作为选择属性的依据。
信息增益
用信息增益表示分裂前后跟的数据复杂度和分裂节点数据复杂度的变化值,计算公式表示为:
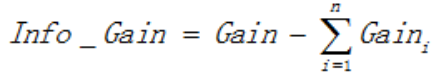
其中Gain表示节点的复杂度,Gain越高,说明复杂度越高。信息增益说白了就是分裂前的数据复杂度减去孩子节点的数据复杂度的和,信息增益越大,分裂后的复杂度减小得越多,分类的效果越明显。
节点的复杂度可以用以下两种不同的计算方式:
- 熵(熵描述了数据的混乱程度,熵越大,混乱程度越高,也就是纯度越低;反之,熵越小,混乱程度越低,纯度越高。 熵的计算公式如下所示:)
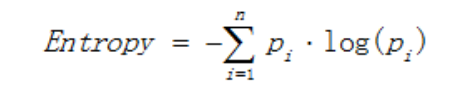
其中Pi表示类i的数量占比。以二分类问题为例,如果两类的数量相同,此时分类节点的纯度最低,熵等于1;如果节点的数据属于同一类时,此时节点的纯度最高,熵 等于0。
- 基尼值(和熵一样描述数据的混乱度)
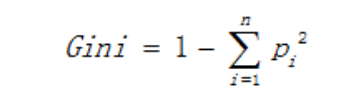
其中Pi表示类i的数量占比。其同样以上述熵的二分类例子为例,当两类数量相等时,基尼值等于0.5 ;当节点数据属于同一类时,基尼值等于0 。基尼值越大,数据越不纯。
例子:https://www.cnblogs.com/yonghao/p/5061873.html
信息增益率
使用信息增益作为选择分裂的条件有一个不可避免的缺点:倾向选择分支比较多的属性进行分裂。为了解决这个问题,引入了信息增益率这个概念。信息增益率是在信息增益的基础上除以分裂节点数据量的信息增益
剪枝
决策树是充分考虑了所有的数据点而生成的复杂树,有可能出现过拟合的情况,决策树越复杂,过拟合的程度会越高。
怎么剪
两种方案:先剪枝和后剪枝
1、先剪枝说白了就是提前结束决策树的增长,跟上述决策树停止生长的方法一样。
2、后剪枝是指在决策树生长完成之后再进行剪枝的过程。这里介绍三种后剪枝方案:
REP—错误率降低剪枝(顾名思义,该剪枝方法是根据错误率进行剪枝,如果一棵子树修剪前后错误率没有下降,就可以认为该子树是可以修剪的。)
PEP—悲观剪枝(悲观剪枝认为如果决策树的精度在剪枝前后没有影响的话,则进行剪枝。怎样才算是没有影响?如果剪枝后的误差小于剪枝前经度的上限,则说明剪枝后的效果与剪枝前的效果一致,此时要进行剪枝。)
CCP—代价复杂度剪枝(代价复杂度选择节点表面误差率增益值最小的非叶子节点,删除该非叶子节点的左右子节点,若有多个非叶子节点的表面误差率增益值相同小,则选择非叶子节点中子节点数最多的非叶子节点进行剪枝。)
决策树的构建算法主要有ID3、C4.5、CART三种,其中ID3和C4.5是分类树,CART是分类回归树。
ID3
ID3是基本的决策树构建算法,作为决策树经典的构建算法,其具有结构简单、清晰易懂的特点。虽然ID3比较灵活方便,但是有以下几个缺点:
(1)采用信息增益进行分裂,分裂的精确度可能没有采用信息增益率进行分裂高
(2)不能处理连续型数据,只能通过离散化将连续性数据转化为离散型数据
(3)不能处理缺省值
(4)没有对决策树进行剪枝处理,很可能会出现过拟合的问题
细节参考这篇文章:https://www.cnblogs.com/yonghao/p/5096358.html
C4.5
C4.5在ID3的基础上对上述三个方面进行了相应的改进:
a) C4.5对节点进行分裂时采用信息增益率作为分裂的依据;
b) 能够对连续数据进行处理;(先根据连续型属性进行排序,然后采用一刀切的方式将数据砍成两半,计算每一个切割点切割后的信息增益,然后选择使分裂效果最优的切割点。)
c) C4.5采用剪枝的策略,对完全生长的决策树进行剪枝处理,一定程度上降低过拟合的影响。(悲观剪枝方法)
具体例子参考这篇:https://www.cnblogs.com/yonghao/p/5122703.html
CART
(1)CART既能是分类树,又能是回归树;
(2)当CART是分类树时,采用GINI值作为节点分裂的依据;当CART是回归树时,采用样本的最小方差作为节点分裂的依据;
GINI值的计算公式:
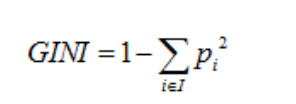
回归方差计算公式:
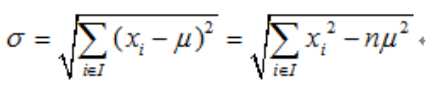
(3)CART是一棵二叉树。
(4)CART采用CCP(代价复杂度)剪枝方法
具体分类树、回归树sklearn的算法看pdf,内容就不在这里帖了。
# 机器学习算法总结-第一天(KNN、决策树)的更多相关文章
- 机器学习算法 - 最近邻规则分类KNN
上节介绍了机器学习的决策树算法,它属于分类算法,本节我们介绍机器学习的另外一种分类算法:最近邻规则分类KNN,书名为k-近邻算法. 它的工作原理是:将预测的目标数据分别跟样本进行比较,得到一组距离的数 ...
- 如何解读「量子计算应对大数据挑战:中国科大首次实现量子机器学习算法」?——是KNN算法吗?
作者:知乎用户链接:https://www.zhihu.com/question/29187952/answer/48519630 我居然今天才看到这个问题,天……本专业,有幸听过他们这个实验的组会来 ...
- 机器学习算法整理(五)决策树_随机森林——鹃尾花实例 Python实现
以下均为自己看视频做的笔记,自用,侵删! 还参考了:http://www.ai-start.com/ml2014/ In [8]: %matplotlib inline import pandas a ...
- scikit-learn中的机器学习算法封装——kNN
接前面 https://www.cnblogs.com/Liuyt-61/p/11738399.html 回过头来看这张图,什么是机器学习?就是将训练数据集喂给机器学习算法,在上面kNN算法中就是将特 ...
- 机器学习算法·KNN
机器学习算法应用·KNN算法 一.问题描述 验证码目前在互联网上非常常见,从学校的教务系统到12306购票系统,充当着防火墙的功能.但是随着OCR技术的发展,验证码暴露出的安全问题越来越严峻.目前对验 ...
- 机器学习算法实践:决策树 (Decision Tree)(转载)
前言 最近打算系统学习下机器学习的基础算法,避免眼高手低,决定把常用的机器学习基础算法都实现一遍以便加深印象.本文为这系列博客的第一篇,关于决策树(Decision Tree)的算法实现,文中我将对决 ...
- 【机器学习算法-python实现】决策树-Decision tree(1) 信息熵划分数据集
(转载请注明出处:http://blog.csdn.net/buptgshengod) 1.背景 决策书算法是一种逼近离散数值的分类算法,思路比較简单,并且准确率较高.国际权威的学术组织,数据挖掘国际 ...
- 机器学习算法总结(二)——决策树(ID3, C4.5, CART)
决策树是既可以作为分类算法,又可以作为回归算法,而且在经常被用作为集成算法中的基学习器.决策树是一种很古老的算法,也是很好理解的一种算法,构建决策树的过程本质上是一个递归的过程,采用if-then的规 ...
- 机器学习(一)之KNN算法
knn算法原理 ①.计算机将计算所有的点和该点的距离 ②.选出最近的k个点 ③.比较在选择的几个点中那个类的个数多就将该点分到那个类中 KNN算法的特点: knn算法的优点:精度高,对异常值不敏感,无 ...
随机推荐
- Hibernate fetch相关
fetch=FetchType.LAZY 时,spring boot jackson 返回数据时会出错. 可配置使用Hibernate4Module 帮助解决: @Configurationpubli ...
- NIO单一长连接——dubbo通信模型实现
转: NIO单一长连接——dubbo通信模型实现 峡客 1.2 2018.07.15 19:04* 字数 2552 阅读 6001评论 30喜欢 17 前言 前一段时间看了下dubbo,原想将dubb ...
- nginx重新编译不停服
找到安装nginx的源码根目录,如果没有就下载新的安装包 .tar.gz 查看ngixn版本极其编译参数 /usr/local/nginx/sbin/nginx -V 进入nginx源码目录 cd n ...
- 初识MyBatis之HelloWorld
1.先下载MyBatis相关Jar包. 2. 创建数据库和表 CREATE TABLE tbl_employee( id ) PRIMARY KEY AUTO_INCREMENT, last_name ...
- 关于sws安全助手企业政府版的停止维护以及无法购买(官方已公开永久可用免费序列号并将软件开源)
sws安全助手企业政府版官方公布的永久可用系列号:XGVPP-NMH47-7TTHJ-W3FW7-8HV2C 安装程序官网下载地址:https://swssoftwareshare.gitee.io/ ...
- 2019-10-20 李宗盛 linux
Linux Linux简介(了解) Linux介绍:Linux是类UNIX计算机的统称 Linux操作系统的内核也是Linux Linux是由芬兰大学生Linux Torvalds于1991年编写 L ...
- 2019-10-20 李宗盛 spss作业
SPSS: 1.有关SPSS数据字典的说法,正确的是 A.SPSS数据集的数据字典可以复制到其他数据集中 B.SPSS数据集的数据字典是不能复制的 C.SPSS的数据字典可以通过“复制”和“粘贴”在不 ...
- js函数(4)闭包
8.6闭包 背景:3.10 变量作用域 在函数体内,局部变量的优先级高于同名的全局变量.如果在函数内声明一个局部变量或者函数参数中带有的变量和全局变量重名,则局部变量会覆盖全局变量: 在全局作用域编写 ...
- Sumitomo Mitsui Trust Bank Programming Contest 2019 Task F. Interval Running
Link. There is a nice approach to this problem that involves some physical insight. In the following ...
- jsp获取Session中的值
摘要:这个问题算是老生常谈了,我也是一段时间没弄过了,所以感觉有些忘了,就记录一下. 一.后端通过shiro在session中存储数据: // username是前台传过来的用户名 if (subje ...