记录一次hadoop2.8.4版本RM接入zk ha问题
背景:
公司将线上hadoop RM接入ZK 实现高可用 但ZK Znode 默认存储1M,当存储数据量大时候可能导致线上业务的崩溃
处理方案如下:
1,修改ZK配置 增加默认存储上限
2,修改RM数据存储在zk中的路径结构 使结构拆分能支撑更大的数据
问题一 修改ZK配置 增加默认存储上限
主要为修改配置参数
在zk各节点上修改配置 (修改为10M大小)
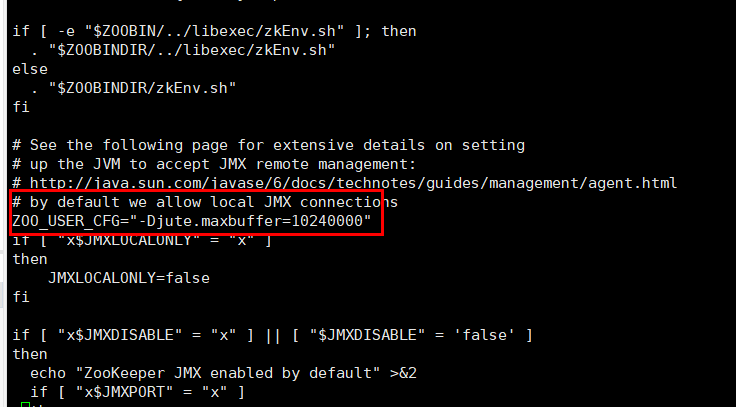
vi zkServer.sh
新增配置到图中位置 ZOO_USER_CFG="-Djute.maxbuffer=10240000"
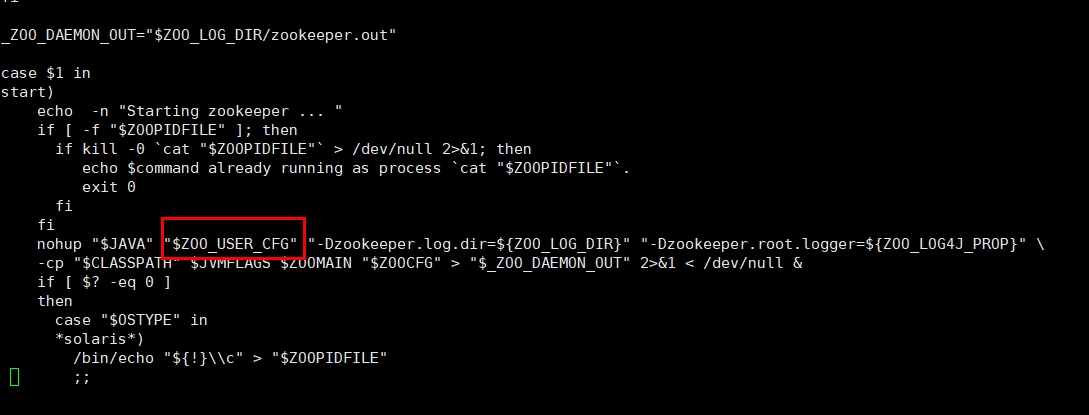
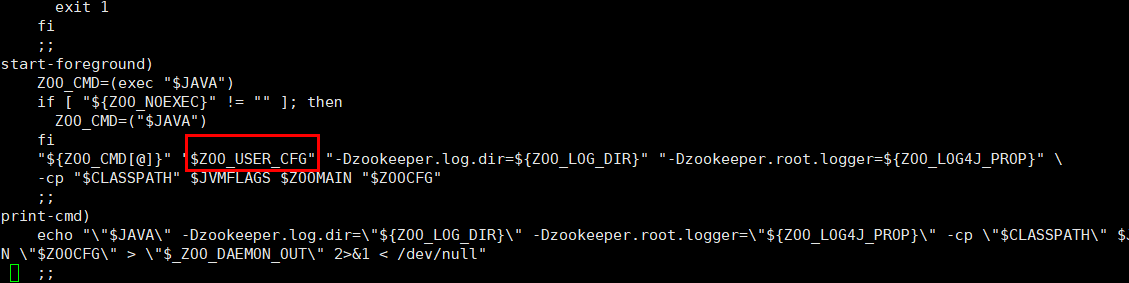
修改zkCli.sh (不修改 客户端命令行 将不能取得超出1M的数据)
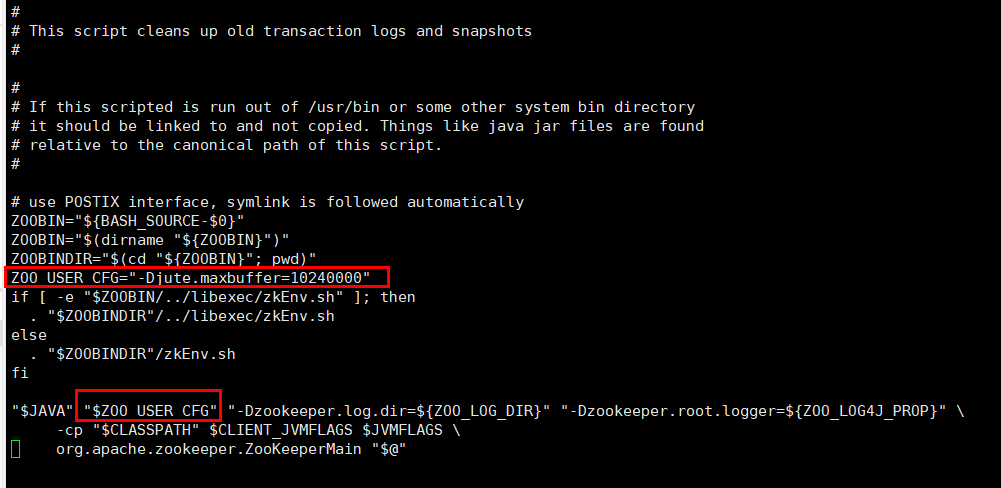
即使如此 当我们代码客户端也不能取得超出大小的数据 需要添加环境变量 如下
System.setProperty("jute.maxbuffer",String.valueOf(10240000));
同样的yarn的配置也要修改 不然也是白搭
yarn-env.sh
新增一行
YARN_RESOURCEMANAGER_OPTS="$YARN_RESOURCEMANAGER_OPTS -Djute.maxbuffer=10240000"
问题2 优化zk中存储结构 yarn 在zk中的存储如下
ROOT_DIR_PATH
|--- VERSION_INFO
|--- EPOCH_NODE
|--- RM_ZK_FENCING_LOCK
|--- RM_APP_ROOT
| |----- (#ApplicationId1)
| | |----- (#ApplicationAttemptIds)
| |
| |----- (#ApplicationId2)
| | |----- (#ApplicationAttemptIds)
| ....
|
|--- RM_DT_SECRET_MANAGER_ROOT
|----- RM_DT_SEQUENTIAL_NUMBER_ZNODE_NAME
|----- RM_DELEGATION_TOKENS_ROOT_ZNODE_NAME
| |----- Token_1
| |----- Token_2
| ....
|
|----- RM_DT_MASTER_KEYS_ROOT_ZNODE_NAME
| |----- Key_1
| |----- Key_2
....
|--- AMRMTOKEN_SECRET_MANAGER_ROOT
|----- currentMasterKey
|----- nextMasterKey
更新为:
* The znode structure is as follows:
* ROOT_DIR_PATH
* |--- VERSION_INFO
* |--- EPOCH_NODE
* |--- RM_ZK_FENCING_LOCK
* |--- RM_APP_ROOT
* | |----- HIERARCHIES
* | | |----- 1
* | | | |----- (#ApplicationId barring last character)
* | | | | |----- (#Last character of ApplicationId)
* | | | | | |----- (#ApplicationAttemptIds)
* | | | ....
* | | |
* | | |----- 2
* | | | |----- (#ApplicationId barring last 2 characters)
* | | | | |----- (#Last 2 characters of ApplicationId)
* | | | | | |----- (#ApplicationAttemptIds)
* | | | ....
* | | |
* | | |----- 3
* | | | |----- (#ApplicationId barring last 3 characters)
* | | | | |----- (#Last 3 characters of ApplicationId)
* | | | | | |----- (#ApplicationAttemptIds)
* | | | ....
* | | |
* | | |----- 4
* | | | |----- (#ApplicationId barring last 4 characters)
* | | | | |----- (#Last 4 characters of ApplicationId)
* | | | | | |----- (#ApplicationAttemptIds)
* | | | ....
* | | |
* | |----- (#ApplicationId1)
* | | |----- (#ApplicationAttemptIds)
* | |
* | |----- (#ApplicationId2)
* | | |----- (#ApplicationAttemptIds)
* | ....
* |
* |--- RM_DT_SECRET_MANAGER_ROOT
* |----- RM_DT_SEQUENTIAL_NUMBER_ZNODE_NAME
* |----- RM_DELEGATION_TOKENS_ROOT_ZNODE_NAME
* | |----- 1
* | | |----- (#TokenId barring last character)
* | | | |----- (#Last character of TokenId)
* | | ....
* | |----- 2
* | | |----- (#TokenId barring last 2 characters)
* | | | |----- (#Last 2 characters of TokenId)
* | | ....
* | |----- 3
* | | |----- (#TokenId barring last 3 characters)
* | | | |----- (#Last 3 characters of TokenId)
* | | ....
* | |----- 4
* | | |----- (#TokenId barring last 4 characters)
* | | | |----- (#Last 4 characters of TokenId)
* | | ....
* | |----- Token_1
* | |----- Token_2
* | ....
* |
* |----- RM_DT_MASTER_KEYS_ROOT_ZNODE_NAME
* | |----- Key_1
* | |----- Key_2
* ....
* |--- AMRMTOKEN_SECRET_MANAGER_ROOT
* |----- currentMasterKey
* |----- nextMasterKey
*
* |-- RESERVATION_SYSTEM_ROOT
* |------PLAN_1
* | |------ RESERVATION_1
* | |------ RESERVATION_2
* | ....
* |------PLAN_2
* ....
yarn-siting.xml文件新增一个配置项
<property>
<description>Index at which last section of application id (with each section
separated by _ in application id) will be split so that application znode
stored in zookeeper RM state store will be stored as two different znodes
(parent-child). Split is done from the end.
For instance, with no split, appid znode will be of the form
application_1352994193343_0001. If the value of this config is 1, the
appid znode will be broken into two parts application_1352994193343_000
and 1 respectively with former being the parent node.
application_1352994193343_0002 will then be stored as 2 under the parent
node application_1352994193343_000. This config can take values from 0 to 4.
0 means there will be no split. If configuration value is outside this
range, it will be treated as config value of 0(i.e. no split). A value
larger than 0 (up to 4) should be configured if you are storing a large number
of apps in ZK based RM state store and state store operations are failing due to
LenError in Zookeeper.</description>
<name>yarn.resourcemanager.zk-appid-node.split-index</name>
<value>0</value>
</property>
参考:https://cloud.tencent.com/developer/article/1491079
参考:https://issues.apache.org/jira/browse/YARN-2368
参考:https://issues.apache.org/jira/browse/YARN-2962
记录一次hadoop2.8.4版本RM接入zk ha问题的更多相关文章
- Hadoop2.6.0版本MapReudce示例之WordCount(二)
继<Hadoop2.6.0版本MapReudce示例之WordCount(一)>之后,我们继续看MapReduce的WordCount示例,看看如何监控作业运行或查看历史记录,以及作业运行 ...
- 关于hadoop2.4.2版本学习时遇到的问题
问题一:namenode启动失败 描述:在初始化后hadoop后,发现datanode启动失败,namenode则可以正常启动,如果把用户换成root权限,再次启动时,则namenode和datano ...
- (个人记录)Python2 与Python3的版本区别
现在还有些开源模块还没有更新到python3 ,不了解版本区别,无法对不合适的地方进行更改. 由于只追求向Python3靠近,所以对于python2的特别用法不探究. 此文不补全所有版本区别,仅作档案 ...
- 记录一次Git远程仓库版本回退
操作过程: 首先查看远程仓库版本,如下图所见,最近一次提交为2018-03-19 22:16:25 第一步:使用git log命令查看历史提交记录,选择要回退的版本号,commit后面一串字符,这里我 ...
- 记录一下Vray5中文汉化版本中导出EXR或vrimg多通道文件的那些坑和解决方法
最近在给一个培训机构代课,学生英语基础差,就安装了Vray5的中文版,噩梦从此开始. 做过合成的都知道,需要输出多通道到NUKE或者AE中进行合成,通常情况下把多个pass分成不同的文件对硬盘反复读写 ...
- 记录一次MongoDB3.0.6版本wiredtiger与MMAPv1引擎的写入耗时对比
一.MongoDB3.0.x的版本特性(相对于MongoDB2.6及以下): 增加了wiredtiger引擎: 开源的存储引擎: 支持多核CPU.充分利用内存/芯片级别缓存(注:10月14日刚刚发布的 ...
- 错误记录:vue跟vue编译器版本不一致
错误如下: error in ./src/Utils.vue Module build failed: Error: Vue packages version mismatch: - vue@ - v ...
- maven 使用记录之修改 maven默认jdk版本
maven package执行的时候会遇到jdk版本不对的问题 :原因是 maven所指定的jdk版本与项目使用的jdk版本不一致 1.项目属性的 java compiler可以设置 2.直接修改 m ...
- 记录一次spring与jdk版本不兼容的报错
由于公司项目是普通的web工程,没有用上maven,所以笔者在jdk1.8版本下运行项目报了这样的错误 [ERROR]: 2020-03-09 09:38:50 [org.springframewor ...
随机推荐
- word黏贴图片显示不出来
word图片转存,是指UEditor为了解决用户从word中复制了一篇图文混排的文章粘贴到编辑器之后,word文章中的图片数据无法显示在编辑器中,也无法提交到服务器上的问题而开发的一个操作简便的图片转 ...
- 51 Nod 1700 首尾排序法
1700 首尾排序法 有一个长度为n的数组 p1, p2, p3, ⋯, pnp1, p2, p3, ⋯, pn ,里面只包含1到n的整数,且每个数字都不一样.现在要对这个数组进行从小到大排序,排序的 ...
- 【概率论】4-2:期望的性质(Properties of Expectation)
title: [概率论]4-2:期望的性质(Properties of Expectation) categories: - Mathematic - Probability keywords: - ...
- 微服务springboot视频最新SpringBoot2.0.3版本技术视频教程【免费学习】
超火爆的springboot微服务技术怎么学,看这里,springboot超详细的教程↓↓↓↓↓↓https://ke.qq.com/course/179440?tuin=9b386640 01.sp ...
- c isnormal
Returns whether x is a normal value: i.e., whether it is neither infinity, NaN, zero or subnormal. / ...
- Qt pro工程文件介绍
app - 建立一个应用程序的makefile.这是默认值,所以如果模板没有被指定,这个将被使用. lib - 建立一个库的makefile. vcapp - 建立一个应用程序的Visual Stud ...
- ybatis 逆向工程 自动生成的mapper文件没有 主键方法
1.数据表没有设置主键 设置个主键就好 2.在mybits配置文档里设置了某些属性值为false 在mybatis配置文档里查看 enableSelectByPrimaryKey="true ...
- SQL-W3School-高级:SQL Date 函数
ylbtech-SQL-W3School-高级:SQL Date 函数 1.返回顶部 1. SQL 日期 当我们处理日期时,最难的任务恐怕是确保所插入的日期的格式,与数据库中日期列的格式相匹配. 只要 ...
- 修改Eclipse启动时的选择工作空间
对于eclipse的默认的工作空间,如果不需要正常切换workspace的用户很方便,打开eclipse便自动进入默认的工作空间.而如果用户经常在多个workspace之间切换的话,启动eclipse ...
- mysql物理备份innobackupex
一.全量备份 1.安装xtrabackup # wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.4/b ...