0160 十分钟看懂时序数据库(I)-存储
摘要:2017年时序数据库忽然火了起来。开年2月Facebook开源了beringei时序数据库;到了4月基于PostgreSQL打造的时序数据库TimeScaleDB也开源了,而早在2016年7月,百度云在其天工物联网平台上发布了国内首个多租户的分布式时序数据库产品TSDB,成为支持其发展制造,交通,能源,智慧城市等产业领域的核心产品,同时...
2017年时序数据库忽然火了起来。开年2月Facebook开源了beringei时序数据库;到了4月基于PostgreSQL打造的时序数据库TimeScaleDB也开源了,而早在2016年7月,百度云在其天工物联网平台上发布了国内首个多租户的分布式时序数据库产品TSDB,成为支持其发展制造,交通,能源,智慧城市等产业领域的核心产品,同时也成为百度战略发展产业物联网的标志性事件。时序数据库作为物联网方向一个非常重要的服务,业界的频频发声,正说明各家企业已经迫不及待的拥抱物联网时代的到来。
本文会从时序数据库的基本概念、使用场景、解决的问题一一展开,最后会从如何解决时序数据存储这一技术问题入手进行深入分析。
1. 背景
百度无人车在运行时需要监控各种状态,包括坐标,速度,方向,温度,湿度等等,并且需要把每时每刻监控的数据记录下来,用来做大数据分析。每辆车每天就会采集将近8T的数据。如果只是存储下来不查询也还好(虽然已经是不小的成本),但如果需要快速查询“今天下午两点在后厂村路,速度超过60km/h的无人车有哪些”这样的多纬度分组聚合查询,那么时序数据库会是一个很好的选择。
2. 什么是时序数据库
先来介绍什么是时序数据。时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。
对比传统数据库仅仅记录了数据的当前值,时序数据库则记录了所有的历史数据。同时时序数据的查询也总是会带上时间作为过滤条件。
时序数据示例
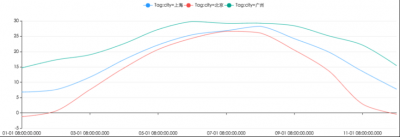
p1-北上广三地2015年气温变化图
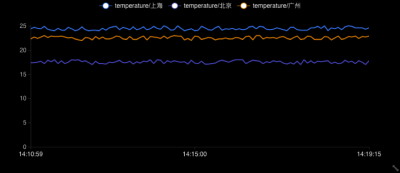
p2-北上广三地当前温度实时展现
下面介绍下时序数据库的一些基本概念(不同的时序数据库称呼略有不同)。
metric: 度量,相当于关系型数据库中的table。
data point: 数据点,相当于关系型数据库中的row。
timestamp:时间戳,代表数据点产生的时间。
field: 度量下的不同字段。比如位置这个度量具有经度和纬度两个field。一般情况下存放的是会随着时间戳的变化而变化的数据。
tag: 标签,或者附加信息。一般存放的是并不随着时间戳变化的属性信息。timestamp加上所有的tags可以认为是table的primary key。
如下图,度量为Wind,每一个数据点都具有一个timestamp,两个field:direction和speed,两个tag:sensor、city。它的第一行和第三行,存放的都是sensor号码为95D8-7913的设备,属性城市是上海。随着时间的变化,风向和风速都发生了改变,风向从23.4变成23.2;而风速从3.4变成了3.3。
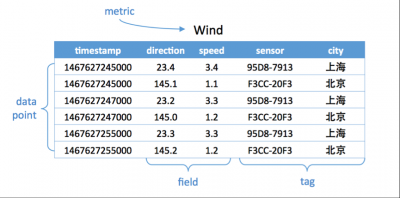
p3-时序数据库基本概念图
3. 时序数据库的场景
所有有时序数据产生,并且需要展现其历史趋势、周期规律、异常性的,进一步对未来做出预测分析的,都是时序数据库适合的场景。
在工业物联网环境监控方向,百度天工的客户就遇到了这么一个难题,由于工业上面的要求,需要将工况数据存储起来。客户每个厂区具有20000个监测点,500毫秒一个采集周期,一共20个厂区。这样算起来一年将产生惊人的26万亿个数据点。假设每个点50Byte,数据总量将达1P(如果每台服务器10T的硬盘,那么总共需要100多台服务器)。这些数据不只是要实时生成,写入存储;还要支持快速查询,做可视化的展示,帮助管理者分析决策;并且也能够用来做大数据分析,发现深层次的问题,帮助企业节能减排,增加效益。最终客户采用了百度天工的时序数据库方案,帮助他解决了难题。
在互联网场景中,也有大量的时序数据产生。百度内部有大量服务使用天工物联网平台的时序数据库。举个例子,百度内部服务为了保障用户的使用体验,将用户的每次网络卡顿、网络延迟都会记录到百度天工的时序数据库。由时序数据库直接生成报表以供技术产品做分析,尽早的发现、解决问题,保证用户的使用体验。
4. 时序数据库遇到的挑战
很多人可能认为在传统关系型数据库上加上时间戳一列就能作为时序数据库。数据量少的时候确实也没问题,但少量数据是展现的纬度有限,细节少,可置信低,更加不能用来做大数据分析。很明显时序数据库是为了解决海量数据场景而设计的。
可以看到时序数据库需要解决以下几个问题
l 时序数据的写入:如何支持每秒钟上千万上亿数据点的写入。
l 时序数据的读取:又如何支持在秒级对上亿数据的分组聚合运算。
l 成本敏感:由海量数据存储带来的是成本问题。如何更低成本的存储这些数据,将成为时序数据库需要解决的重中之重。
这些问题不是用一篇文章就能含盖的,同时每个问题都可以从多个角度去优化解决。在这里只从数据存储这个角度来尝试回答如何解决大数据量的写入和读取。
5. 数据的存储
数据的存储可以分为两个问题,单机上存储和分布式存储。
单机存储
如果只是存储起来,直接写成日志就行。但因为后续还要快速的查询,所以需要考虑存储的结构。
传统数据库存储采用的都是B tree,这是由于其在查询和顺序插入时有利于减少寻道次数的组织形式。我们知道磁盘寻道时间是非常慢的,一般在10ms左右。磁盘的随机读写慢就慢在寻道上面。对于随机写入B tree会消耗大量的时间在磁盘寻道上,导致速度很慢。我们知道SSD具有更快的寻道时间,但并没有从根本上解决这个问题。
对于90%以上场景都是写入的时序数据库,B tree很明显是不合适的。
业界主流都是采用LSM tree替换B tree,比如Hbase, Cassandra等nosql中。这里我们详细介绍一下。
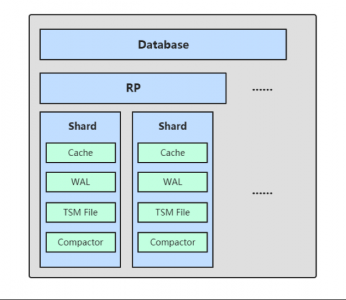
LSM tree包括内存里的数据结构和磁盘上的文件两部分。分别对应Hbase里的MemStore和HLog;对应Cassandra里的MemTable和sstable。
LSM tree操作流程如下:
1. 数据写入和更新时首先写入位于内存里的数据结构。为了避免数据丢失也会先写到WAL文件中。
2. 内存里的数据结构会定时或者达到固定大小会刷到磁盘。这些磁盘上的文件不会被修改。
3. 随着磁盘上积累的文件越来越多,会定时的进行合并操作,消除冗余数据,减少文件数量。
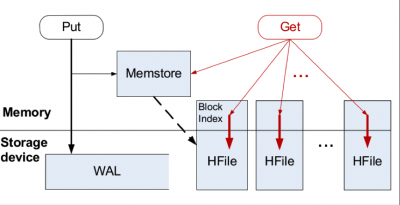
p4-Hbase LSM tree结构介绍(注1)
可以看到LSM tree核心思想就是通过内存写和后续磁盘的顺序写入获得更高的写入性能,避免了随机写入。但同时也牺牲了读取性能,因为同一个key的值可能存在于多个HFile中。为了获取更好的读取性能,可以通过bloom filter和compaction得到,这里限于篇幅就不详细展开。
分布式存储
时序数据库面向的是海量数据的写入存储读取,单机是无法解决问题的。所以需要采用多机存储,也就是分布式存储。
分布式存储首先要考虑的是如何将数据分布到多台机器上面,也就是 分片(sharding)问题。下面我们就时序数据库分片问题展开介绍。分片问题由分片方法的选择和分片的设计组成。
分片方法
时序数据库的分片方法和其他分布式系统是相通的。
哈希分片:这种方法实现简单,均衡性较好,但是集群不易扩展。
一致性哈希:这种方案均衡性好,集群扩展容易,只是实现复杂。代表有Amazon的DynamoDB和开源的Cassandra。
范围划分:通常配合全局有序,复杂度在于合并和分裂。代表有Hbase。
分片设计
分片设计简单来说就是以什么做分片,这是非常有技巧的,会直接影响写入读取的性能。
结合时序数据库的特点,根据metric+tags分片是比较好的一种方式,因为往往会按照一个时间范围查询,这样相同metric和tags的数据会分配到一台机器上连续存放,顺序的磁盘读取是很快的。再结合上面讲到的单机存储内容,可以做到快速查询。
进一步我们考虑时序数据时间范围很长的情况,需要根据时间范围再将分成几段,分别存储到不同的机器上,这样对于大范围时序数据就可以支持并发查询,优化查询速度。
如下图,第一行和第三行都是同样的tag(sensor=95D8-7913;city=上海),所以分配到同样的分片,而第五行虽然也是同样的tag,但是根据时间范围再分段,被分到了不同的分片。第二、四、六行属于同样的tag(sensor=F3CC-20F3;city=北京)也是一样的道理。
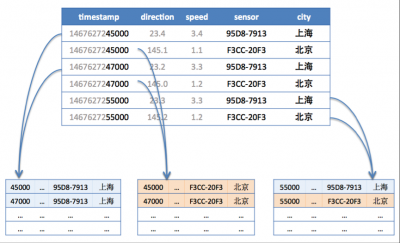
p5-时序数据分片说明
6. 真实案例
下面我以一批开源时序数据库作为说明。
InfluxDB:
非常优秀的时序数据库,但只有单机版是免费开源的,集群版本是要收费的。从单机版本中可以一窥其存储方案:在单机上InfluxDB采取类似于LSM tree的存储结构TSM;而分片的方案InfluxDB先通过<database>+<timestamp>(事实上还要加上retentionPolicy)确定ShardGroup,再通过<metric>+<tags>的hash code确定到具体的Shard。
这里timestamp默认情况下是7天对齐,也就是说7天的时序数据会在一个Shard中。
p6-Influxdb TSM结构图(注2)
Kairosdb:
底层使用Cassandra作为分布式存储引擎,如上文提到单机上采用的是LSM tree。
Cassandra有两级索引:partition key和clustering key。其中partition key是其分片ID,使用的是一致性哈希;而clustering key在一个partition key中保证有序。
Kairosdb利用Cassandra的特性,将 <metric>+<timestamp>+<数据类型>+<tags>作为partition key,数据点时间在timestamp上的偏移作为clustering key,其有序性方便做基于时间范围的查询。
partition key中的timestamp是3周对齐的,也就是说21天的时序数据会在一个clustering key下。3周的毫秒数是18亿正好小于Cassandra每行列数20亿的限制。
OpenTsdb:
底层使用Hbase作为其分布式存储引擎,采用的也是LSM tree。
Hbase采用范围划分的分片方式。使用row key做分片,保证其全局有序。每个row key下可以有多个column family。每个column family下可以有多个column。

上图是OpenTsdb的row key组织方式。不同于别的时序数据库,由于Hbase的row key全局有序,所以增加了可选的salt以达到更好的数据分布,避免热点产生。再由与timestamp间的偏移和数据类型组成column qualifier。
他的timestamp是小时对齐的,也就是说一个row key下最多存储一个小时的数据。并且需要将构成row key的metric和tags都转成对应的uid来减少存储空间,避免Hfile索引太大。下图是真实的row key示例。

p7-open tsdb的row key示例(注3)
7. 结束语
可以看到各分布式时序数据库虽然存储方案都略有不同,但本质上是一致的,由于时序数据写多读少的场景,在单机上采用更加适合大吞吐量写入的单机存储结构,而在分布式方案上根据时序数据的特点来精心设计,目标就是设计的分片方案能方便时序数据的写入和读取,同时使数据分布更加均匀,尽量避免热点的产生。
数据存储是时序数据库设计中很小的一块内容,但也能管中窥豹,看到时序数据库从设计之初就要考虑时序数据的特点。后续我们会从其他的角度进行讨论。
作者:百度云时序数据库资深工程师
注1:来源http://tristartom.github.io/research.html
注2:来源http://blog.fatedier.com/2016/08/05/detailed-in-influxdb-tsm-storage-engine-one/
注3:来源http://opentsdb.net/docs/build/html/user_guide/backends/hbase.html
原文地址:https://blog.csdn.net/junlinbo/article/details/85055593
0160 十分钟看懂时序数据库(I)-存储的更多相关文章
- 十分钟看懂AES加密
十分钟看懂AES加密算法 今天看了Moserware的<A Stick Figure Guide to the Advanced Encryption Standard(AES)>收获了不 ...
- 十分钟看懂,未来Web前端开发最新趋势
首先,展望未来趋势我们就要弄懂过去的一年,也就是18年,web前端开发的重要新闻.重要事件和JavaScript的各种流行框架.模式发展趋势. 我们来快速回顾一下. NPM热门前端框架下载 先来看最热 ...
- 小白之入口即化——十分钟看懂while循环,字符串格式化,运算符
while循环 while循环-死循环 while空格+条件+冒号 缩进+循环体 3.打断死循环 break--终止当前循环 while True: print(123) print(234) bre ...
- [转帖]10分钟看懂Docker和K8S
10分钟看懂Docker和K8S https://zhuanlan.zhihu.com/p/53260098 2010年,几个搞IT的年轻人,在美国旧金山成立了一家名叫“dotCloud”的公司. 这 ...
- [转帖]一文看懂mysql数据库本质及存储引擎innodb+myisam
一文看懂mysql数据库本质及存储引擎innodb+myisam https://www.toutiao.com/i6740201316745740807/ 原创 波波说运维 2019-09-29 0 ...
- 十分钟搞懂什么是CGI
原文:CGI Made Really Easy,在翻译的过程中,我增加了一些我在学习过程中找到的更合适的资料,和自己的一些理解.不能算是严格的翻译文章,应该算是我的看这篇文章的过程的随笔吧. CGI真 ...
- 十分钟搞懂什么是CGI(转)
原文:CGI Made Really Easy,在翻译的过程中,我增加了一些我在学习过程中找到的更合适的资料,和自己的一些理解.不能算是严格的翻译文章,应该算是我的看这篇文章的过程的随笔吧. CGI真 ...
- 5分钟看懂Code128条形码
什么是Code128条形码? 相信大家看到这个都不陌生吧 1.前言 条形码种类很多,常见的大概有二十多种码制,其中包括:Code39码(标准39码).Codabar码(库德巴码).Code25码(标准 ...
- 10分钟看懂Docker和K8S
本文来源:鲜枣课堂 2010年,几个搞IT的年轻人,在美国旧金山成立了一家名叫"dotCloud"的公司. 这家公司主要提供基于PaaS的云计算技术服务.具体来说,是和LXC有关的 ...
随机推荐
- ML_Review_GMM(Ch10)
Note sth about GMM(Gaussian Mixtrue Model) 高斯混合模型的终极理解 高斯混合模型(GMM)及其EM算法的理解 这两篇博客讲得挺好,同时讲解了如何解决GMM参数 ...
- layui跨域问题的解决
跨域问题的解决 由于浏览器存在同源策略,所以如果 layui(里面含图标字体文件)所在的地址与你当前的页面地址不在同一个域下,即会出现图标跨域问题.所以要么你就把 layui 与网站放在同一服务器 ...
- 《你不知道的JavaScript(上)》笔记——this全面解析
首先要理解调用位置: 调用位置就是函数在代码中被调用的位置(而不是声明的位置). 最重要的是要分析调用栈(就是为了到达当前执行位置所调用的所有函数). 我们关心的调用位置就在当前正在执行的函数的前一个 ...
- Android 摇一摇监听实现
package com.loaderman.androiddemo; import android.content.Context; import android.hardware.Sensor; i ...
- 002-创建型-04-建造者模式(Builder)、JDK1.7源码中的建造者模式、Spring中的建造者模式
一.概述 建造者模式的定义:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示. 工厂类模式提供的是创建单个类的模式,而建造者模式则是将各种产品集中起来进行管理,用来创建复合对象 ...
- IFC数据模型构件控制
控制ifc构件的隐藏与显示.着色 osg::ref_ptr<osg::Geode> geode1 = new osg::Geode(); osg::ref_ptr<osg::Stat ...
- osg create shape
osg::ref_ptr<osg::Node> OSG_Qt_::createSimple() { osg::ref_ptr<osg::Geode> geode = new o ...
- React——嵌入已有项目 && jsx
Add React to a Website React has been designed from the start for gradual adoption, and you can use ...
- OLE导出EXCEL 问题处理
需求: 2.资产负债表.利润表导出优化,由于项目公司门店较多,需要增加批量导出功能.按纳税主体维度导出execl文件,输入了几个纳税主体,就生成几个execl文件. 实现: 用程序ZFIR0014XL ...
- 【微信小程序】wx.navigateBack() 携带参数返回
第一个页面: go_pick_time:function(e){ var that = this; var type = e.currentTarget.dataset.type; wx.naviga ...