#论文阅读# Universial language model fine-tuing for text classification

论文链接:https://aclweb.org/anthology/P18-1031
对文章内容的总结
文章研究了一些在general corous上pretrain LM,然后把得到的model transfer到text classiffication上 整个过程的训练技巧。这些技巧的切入点是learning rate. 主要是三个:(1)discriminative fine-tuning (其中的discriminative 指 fine-tune each layer with different learning rate LR)(2)slanted triangular learning rate (在训练过程中先增加LR,增到预设的最大值后减小(减小速度<增加速度,所以LR随训练步数的曲线看起来是slanted triangle))(3)在训练text classiffication model时, perform gradual unfreezing. (即先锁住所有层的参数,训练过程中从最后一层开始,每训练一个epoch向前放开一层)
以下是ABSTACT和INTRODUCTION主要内容的翻译:
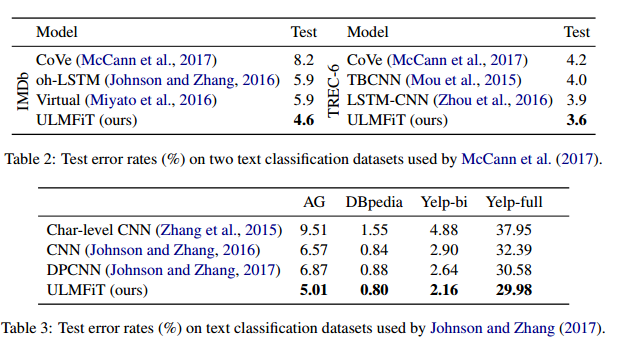

Contributions:
#论文阅读# Universial language model fine-tuing for text classification的更多相关文章
- 论文笔记 - Noisy Channel Language Model Prompting for Few-Shot Text Classification
Direct && Noise Channel 进一步把语言模型推理的模式分为了: 直推模式(Direct): 噪声通道模式(Noise channel). 直观来看: Direct ...
- 论文列表——text classification
https://blog.csdn.net/BitCs_zt/article/details/82938086 列出自己阅读的text classification论文的列表,以后有时间再整理相应的笔 ...
- 论文分享|《Universal Language Model Fine-tuning for Text Classificatio》
https://www.sohu.com/a/233269391_395209 本周我们要分享的论文是<Universal Language Model Fine-tuning for Text ...
- 【论文翻译】KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Grained Relationships
KLMo:建模细粒度关系的知识图增强预训练语言模型 (KLMo: Knowledge Graph Enhanced Pretrained Language Model with Fine-Graine ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- NLP问题特征表达基础 - 语言模型(Language Model)发展演化历程讨论
1. NLP问题简介 0x1:NLP问题都包括哪些内涵 人们对真实世界的感知被成为感知世界,而人们用语言表达出自己的感知视为文本数据.那么反过来,NLP,或者更精确地表达为文本挖掘,则是从文本数据出发 ...
- YOLO 论文阅读
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快.截止到目前为止(2017年2月初),YO ...
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
随机推荐
- js 跨域请求原理及常见解决方案
一.同源策略: 说到跨域请求,首先得说说同源策略: 1995年,同源政策是由 Netscape 公司引入浏览器的.目前,所有浏览器都实行了这个政策. 同源策略是浏览器的一种安全策略,所谓同源是指,域名 ...
- webstorm双击鼠标出现光标块
将Vim 选项对勾去掉
- 【概率论】4-1:随机变量的期望(The Expectation of a Random Variable Part II)
title: [概率论]4-1:随机变量的期望(The Expectation of a Random Variable Part II) categories: - Mathematic - Pro ...
- MySQl的库操作、表操作和数据操作
一.库操作 1.1库的增删改查 (1)系统数据库: performance_schema:用来收集数据库服务器的性能参数,记录处理查询时发生的各种事件.锁等现象 mysql:授权库,主要存储系统用户的 ...
- Android Jenkins 自动化打包构建
前言 在测试app项目过程中,通常都是需要开发打测试包给到测试,但是无论是iOS还是Android的打包过程都是相当漫长的,频繁的回归测试需要频繁的打包,对于开发同学影响还是蛮大的.因此在这种情况下, ...
- ERRORS: ?: (corsheaders.E013) Origin '*' in CORS_ORIGIN_WHITELIST is missing scheme or netloc HINT:
报错信息 ERRORS: ?: (corsheaders.E013) Origin '*' in CORS_ORIGIN_WHITELIST is missing scheme or netloc H ...
- 【java中的static关键字】
文章转自:https://www.cnblogs.com/dolphin0520/p/3799052.html 一.static关键字的用途 在<Java编程思想>P86页有这样一段话: ...
- uiautomator2 wifi连接手机
[实施方法] 手机和电脑同时连接到同一个wifi上 1.开启远程adb #开启远端adb,这一步需要手机通过USB连接到电脑 adb tcpip 5555 #结果如下:restarting in TC ...
- Maven的安装和配置(Windows 10)
1. 官网下载Maven管理工具 官网:https://maven.apache.org/download.cgi 系统要求: JDK:Maven 3.3以上需要JDK 1.7以上版本支持 Memor ...
- java经典算法题50道
原文 JAVA经典算法50题[程序1] 题目:古典问题:有一对兔子,从出生后第3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少?1.程序 ...