[转载] ReLU和BN层简析
[转载] ReLU和BN层简析
来源:https://blog.csdn.net/huang_nansen/article/details/86619108
卷积神经网络中,若不采用非线性激活,会导致神经网络只能拟合线性可分的数据,因此通常会在卷积操作后,添加非线性激活单元,其中包括logistic-sigmoid、tanh-sigmoid、ReLU等。
sigmoid激活函数应用于深度神经网络中,存在一定的局限性,当数据落在左右饱和区间时,会导致导数接近0,在卷积神经网络反向传播中,每层都需要乘上激活函数的导数,由于导数太小,这样经过几次传播后,靠前的网络层中的权重很难得到很好的更新,这就是常见的梯度消失问题。这也是ReLU被使用于深度神经网络中的一个重要原因。
- Dead ReLU
若数据落在负区间中,ReLU的结果为0,导数也是0,就会导致反向传播无法将误差传递到这个神经元上,这会导致该神经元永远不会被激活,导致Dead ReLU问题。解决方法:
1)Leraning Rate
导致Dead ReLU问题的其中一个潜在因素为Learning Rate太大,假设在某次更新中,误差非常大,这时候若LR也很大,会导致权重参数更新后,神经元的数据变化剧烈,若该层中多数神经元的输出向负区间偏向很大,导致了大部分权重无法更新,会陷入Dead ReLU问题中。当然,小learning rate也是有可能会导致Dead ReLU问题的,于是出现了Leaky ReLU和PReLU。
2)Leaky ReLU
普通的ReLU为:
Leaky ReLU为:
其中取一个很小的数,作者的默认值为0.01,这样可以保证输出小于0的神经元也会进行很小幅度的更新。
3)PReLU
PReLU是Leaky ReLU的进一步优化版,公式表达为:其中是一个可以学习的参数,更新是反向传播使用的是momentum来更新,更新方式如下:
其中为动量,为学习率。文章中初始化为0.25,且不添加正则化,因为很有可能会很大可能被置0,变成ReLU。
- Batch Normalization
在SegNet网络简析的博文中,我提到过BN层的基本操作和作用。BN层的出现,主要是为了解决机器学习IID问题,即训练集和测试集保持独立同分布。如果输入的分布不能保持稳定,那么训练就会很难收敛,而在图像处理领域的白化处理,即将输入数据转换为以0为均值,1为方差的正态分布。这样能够让神经网络更快更好的收敛,而这就是BN层所要做的。
“深度神经网络之所以收敛慢,是由于输入的分布逐渐向非线性函数的两端靠拢”,而BN层的作用,就是将输入的分布,拉回到均值为0,方差为1的正态分布上,这样就使输入激活函数的值,在反向传播史能够产生更明显的梯度,更容易收敛,避免了梯度消失的问题。之所以能够在反向传播时产生更明显的变化,我们将输入分布变为标准正态分布后,输入的值靠近中心的概率会变大,若我们的激活函数为sigmoid函数,那么即使输入存在微小的变化,也能够在反向传播时产生很明显的变化。
每层神经网络在线性激活后,通过如下公式进行转换,这个转换就是BN层的操作。
公式中的x是经过该层线性变换后的值,即x = wu+b,u为上一层神经层的输出。
通过这个操作,将输入非线性激活函数的输入值,尽量拉伸到变化较大的区域,即激活函数中间区域。这样能够增大激活函数的导数值,使收敛更快速。而这样也会引入一个问题,强行变换分布后,会导致部分特征无法学习到,因此引入了另一种操作Scale,操作如下:
mean和variance是不会进行学习的,而gamma和beta两个参数是可以通过反向传播学习的,通过这两个参数对数据进行扩大和平移,恢复部分特征的分布。
BN层的主要功能总结为两点:
1)归一化scale
没有BN层时,若LR设置较大,在配合ReLU激活函数时,容易出现Dead ReLU问题。
2)数据初始化集中,缓解overfitting(这里还理解得不是很透彻)
Overfitting主要发生在一些较远的便捷点,BN操作可以使初始化数据在数据内部。
通常提到BN层,我们会想到,若使用sigmoid激活函数时,它可以将数据归一化到梯度较大的区域,便于梯度更新。
但很少有人提到BN层和ReLU的联系,https://blog.csdn.net/wfei101/article/details/79997708这篇转载文章中有提到。
在BN中的gamma对于ReLU的影响很小,因为数值的收缩,不会影响是否大于0。但是如果没有偏移量beta,就会出现数据分布在以0为中心的位置,强行将一半的神经元输出置零。因此偏移量beta是必不可少的。


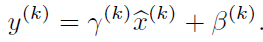
另外一篇文章中也提到了BN层的一个作用:
来源:https://blog.csdn.net/xys430381_1/article/details/85141702
首先来说归一化的问题,神经网络训练开始前,都要对数据做一个归一化处理,归一化有很多好处,原因是网络学习的过程的本质就是学习数据分布,一旦训练数据和测试数据的分布不同,那么网络的泛化能力就会大大降低,另外一方面,每一批次的数据分布如果不相同的话,那么网络就要在每次迭代的时候都去适应不同的分布,这样会大大降低网络的训练速度,这也就是为什么要对数据做一个归一化预处理的原因。另外对图片进行归一化处理还可以处理光照,对比度等影响。
网络一旦训练起来,参数就要发生更新,出了输入层的数据外,其它层的数据分布是一直发生变化的,因为在训练的时候,网络参数的变化就会导致后面输入数据的分布变化,比如第二层输入,是由输入数据和第一层参数得到的,而第一层的参数随着训练一直变化,势必会引起第二层输入分布的改变,把这种改变称之为:Internal Covariate Shift,BN就是为了解决这个问题的。

[转载] ReLU和BN层简析的更多相关文章
- [转载] Thrift原理简析(JAVA)
转载自http://shift-alt-ctrl.iteye.com/blog/1987416 Apache Thrift是一个跨语言的服务框架,本质上为RPC,同时具有序列化.发序列化机制:当我们开 ...
- 【转载】 Pytorch(1) pytorch中的BN层的注意事项
原文地址: https://blog.csdn.net/weixin_40100431/article/details/84349470 ------------------------------- ...
- 【转载】 Caffe BN+Scale层和Pytorch BN层的对比
原文地址: https://blog.csdn.net/elysion122/article/details/79628587 ------------------------------------ ...
- 【转载】 【caffe转向pytorch】caffe的BN层+scale层=pytorch的BN层
原文地址: https://blog.csdn.net/u011668104/article/details/81532592 ------------------------------------ ...
- Batch normalization简析
Batch normalization简析 What is batch normalization 资料来源:https://www.bilibili.com/video/av15997678/?p= ...
- 【HANA系列】SAP Vora(SAP HANA和Hadoop)简析
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[HANA系列]SAP Vora(SAP HAN ...
- SimpleDateFormat使用简析
title: SimpleDateFormat使用简析 date: 2016-07-11 11:48:20 tags: Java SimpleDateFormat --- [转载自博客:http:// ...
- 简析TCP的三次握手与四次分手【转】
转自 简析TCP的三次握手与四次分手 | 果冻想http://www.jellythink.com/archives/705 TCP是什么? 具体的关于TCP是什么,我不打算详细的说了:当你看到这篇文 ...
- PHP单一文件入口框架简析
<?php /** * PHP单一文件框架设计简析 * 1.MVC架构实现 * 2.URL路由原理 */ //URL路由原理 /** * 路由作用 * 获取url中的c和a变量,执行c类对应的方 ...
随机推荐
- Undo Segment/Undo Retention
undo_retention简单定义,就是最多数据的最少保留时间.AUM模式下,undo_retention参数用于事务commit后undo数据保留的时间.单位为秒.这是个no guarantee的 ...
- 前端知识点回顾——Javascript篇(六)
fetch 在原生ajax+es6promise的基础上封装的一个语法糖,返回promise对象. fetch(url, initObj) .then(res=>res.json()) .the ...
- webpack publicpath path
一.publicpath 用绝对路径:如 /assets/ 会在支援路径前 加上 /assets/ devServer publicpath 如果没有设置的话,取 publicpath 所以 一般要 ...
- C#实现MJPEG服务器
实现流写入,将图像作为mjpeg写入 public class MjpegWriter : IDisposable { , }; , , , }; private string _Boundary; ...
- leetcode1284 转化为全零矩阵的最少反转次数
m == mat.length n == mat[0].length 1 <= m <= 3 1 <= n <= 3 mat[i][j] 是 0 或 1 . BFS, 代码来自 ...
- SqlServer/Oracle 通过一个sql判断新增/修改
if (Config.DbInfo.DbType.Equals(DBType.SQLServer)) { sql = ].GetString() + ].GetString() + ].GetStri ...
- JavaScript(7)——DOM
什么是 DOM? DOM是 Document Object Model(文档对象模型)的缩写 DOM是 W3C(万维网联盟)的标准. DOM 定义了访问 HTML 和 XML 文档的标准: “W3C ...
- react 添加 react-redux 基本用法
安装 yarn add react-redux 创建文件.文件夹 |- redux |- actions.js |- reducer.js |- store.js actions.js export ...
- 20190925 - 使 macOS 的 rm 命令删除到回收站的不完美办法
今天使用 macOS 时,使用 rm 删除了一个不重要文件,为保证以后不删除重要文件,找到一个让 rm 命令更安全的办法. 使用 MacPorts 安装 rmtrash 命令. sudo port i ...
- day33 网络编程之UDP与进程了解
UDP 什么是UDP协议 在上节课的练习中,使用TCP进行网络编程时,我们会遇到粘包问题,这是因为TCP是流式协议,而今天学习的UDP协议不是流式协议,其发送的数据是数据报格式的,在进行数据发送时该协 ...