openstack共享组件--rabbitmq消息队列(1)
一、MQ 全称为 Message Queue, 消息队列( MQ )
是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。
消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。
排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。udp
二、AMQP 即 Advanced Message Queuing Protocol
高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。消息中间件(用于两个或多个软件之间的软件)主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
AMQP 的主要特征是面向消息、队列、路由(包括点对点和发布 / 订阅)、可靠性、安全。通过rabbitmq实现
三、 Rabbitmq概念:
属于一个流行的开源消息队列系统。属于AMQP( 高级消息队列协议 ) 标准的一个 实现。是应用层协议的一个开放标准,为面向消息的中间件设计。用于在分布式系统中存储转发消息,在 易用性、扩展性、高可用性等方面表现不俗。
RabbitMQ特点:
使用Erlang编写
支持持久化
支持HA
提供C# , erlang,java,perl,python,ruby等的client开发端
四、什么是耦合、解耦合
一、耦合
1、耦合是指两个或两个以上的体系或两种运动形式间通过相互作用而彼此影响以至联合起来的现象。
2、在软件工程中,对象之间的耦合度就是对象之间的依赖性。对象之间的耦合越高,维护成本越高,因此对象的设计应使类和构件之间的耦合最小。
3、分类:有软硬件之间的耦合,还有软件各模块之间的耦合。耦合性是程序结构中各个模块之间相互关联的度量。它取决于各个模块之间的接口的复杂程度、调用模块的方式以及哪些信息通过接口。
二、解耦
1、解耦,字面意思就是解除耦合关系。
2、在软件工程中,降低耦合度即可以理解为解耦,模块间有依赖关系必然存在耦合,理论上的绝对零耦合是做不到的,但可以通过一些现有的方法将耦合度降至最低。
3、设计的核心思想:尽可能减少代码耦合,如果发现代码耦合,就要采取解耦技术。让数据模型,业务逻辑和视图显示三层之间彼此降低耦合,把关联依赖降到最低,而不至于牵一发而动全身。原则就是A功能的代码不要写在B的功能代码中,如果两者之间需要交互,可以通过接口,通过消息,甚至可以引入框架,但总之就是不要直接交叉写。
五、RabbitMQ中的概念名词
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字, exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
六、RabbitMQ工作原理
MQ 是消费 - 生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取或者订阅队列中的消息。 MQ 则是遵循了 AMQP协议的具体实现和产品。在项目中,将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。

( 1)客户端连接到消息队列服务器,打开一个channel。
( 2)客户端声明一个exchange,并设置相关属性。
( 3)客户端声明一个queue,并设置相关属性。
( 4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
( 5)客户端投递消息到exchange。
( 6) exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里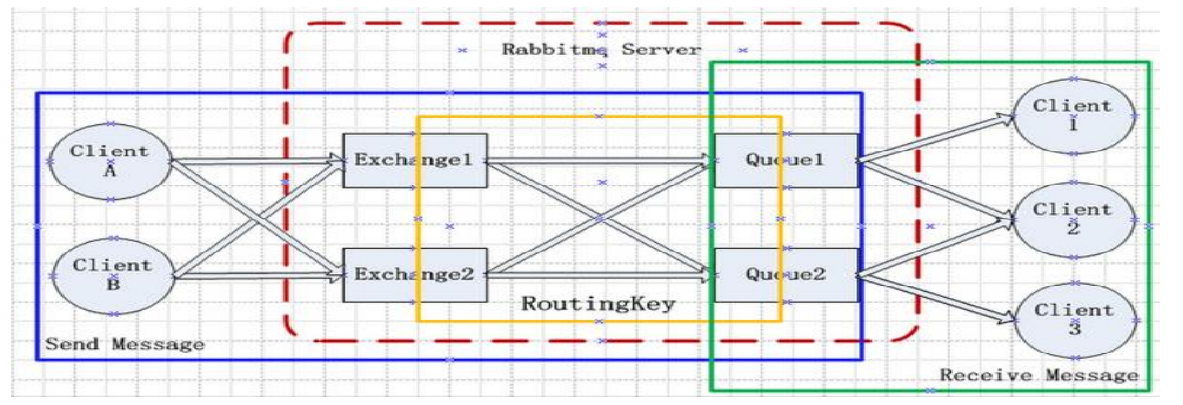
七、Rabbitmq 的 metadata(元数据)
元数据可以持久化在 RAM 或 Disc. 从这个角度可以把 RabbitMQ 集群中的节点分成两种 :RAM Node和 Disk Node.
RAM Node 只会将元数据存放在RAM
Disk node 会将元数据持久化到磁盘。
单节点系统就没有什么选择了 , 只允许 disk node, 否则由于没有数据冗余一旦重启就会丢掉所有的配置信息 . 但在集群环境中可以选择哪些节点是 RAM node.在集群中声明(declare) 创建 exchange queue binding, 这类操作要等到所有的节点都完成创建才会返回 :
如果是内存节点就要修改内存数据 ,
如果是 disk node 就要等待写磁盘 , 节点过多这里的速度就会被大大的拖慢 .
有些场景 exchang queue 相当固定 , 变动很少 ,那即使全都是 disc node, 也没有什么影响 . 如果使用
Rabbitmq 做 RPC( RPC :Remote Procedure Call—远程过程调用), RPC 或者类似 RPC
的场景这个问题就严重了 , 频繁创建销毁临时队列 , 磁盘读写能力就很快成为性能瓶颈了。所以 , 大多数情况下 , 我们尽量把 Node
创建为RAM Node. 这里就有一个问题了 , 要想集群重启后元数据可以恢复就需要把集群元数据持久化到磁盘 , 那需要规划 RabbitMQ
集群中的 RAM Node 和 Disc Node 。
只要有一个节点是 Disc Node
就能提供条件把集群元数据写到磁盘 ,RabbitMQ 的确也是这样要求的 : 集群中只要有一个 disk node 就可以 , 其它的都可以是
RAM node. 节点加入或退出集群一定至少要通知集群中的一个 disk node 。
如果集群中 disk node 都宕掉 , 就不要变动集群的元数据 . 声明 exchange queue 修改用户权限 , 添加用户等等这些变动在节点重启之后无法恢复 。
有一种情况要求所有的 disk node 都要在线情况在才能操作 , 那就是增加或者移除节点 .RAM node 启动的时候会连接到预设的
disk node 下载最新的集群元数据 . 如果你有两个 disk node(d1 d2), 一个 RAM node 加入的时候你只告诉
d1, 而恰好这个 RAM node 重启的时候 d1 并没有启动 , 重启就会失败 . 所以加入 RAM 节点的时候 , 把所有的disk
node 信息都告诉它 ,RAM node 会把 disk node 的信息持久化到磁盘以便后续启动可以按图索骥 .
八、Rabbitmq 集群部署
192.168.253.135 bb
192.168.253.171 aa
192.168.253.153 cc
yum install -y erlang rabbitmq-server.noarch
systemctl enable rabbitmq-server.service
systemctl start rabbitmq-server.service
systemctl status rabbitmq-server.service
rabbitmqctl change_password guest admin #更改密码为admin,用户名不能数字开头

RABBITMQ_NODE_PORT=5672
ulimit -S -n 4096
RABBITMQ_SERVER_ERL_ARGS="+K true +A30 +P 1048576 -kernel inet_default_connect_options [{nodelay,true},{raw,6,18,<<5000:64/native>>}] -kernel inet_default_listen_options [{raw,6,18,<<5000:64/native>>}]"
RABBITMQ_NODE_IP_ADDRESS=192.168.253.135 #修改为本地节点的ip
scp /etc/rabbitmq/rabbitmq-env.conf aa:/etc/rabbitmq/
scp /etc/rabbitmq/rabbitmq-env.conf cc:/etc/rabbitmq/
/usr/lib/rabbitmq/bin/rabbitmq-plugins list
rabbitmq-plugins enable rabbitmq_management
node1:
rabbitmqctl add_user mama admin
rabbitmqctl set_permissions mama ".*" ".*" ".*" #.*所有权限
rabbitmqctl set_user_tags mama administrator #设为管理员才可以登陆
scp /var/lib/rabbitmq/.erlang.cookie aa:/var/lib/rabbitmq/.erlang.cookie
scp /var/lib/rabbitmq/.erlang.cookie cc:/var/lib/rabbitmq/.erlang.cookie
systemctl restart rabbitmq-server.service
rabbitmqctl stop_app
rabbitmqctl join_cluster --ram rabbit@bb
rabbitmqctl start_app

rabbitmqctl stop_app
rabbitmqctl change_cluster_node_type disc (ram)
Turning rabbit@cc into a ram node ...
Error: Mnesia is still running on node rabbit@cc.
Please stop the node with rabbitmqctl stop_app first. #可以看到需要先停止应用
停止后再次执行
[root@cc rabbitmq]# rabbitmqctl change_cluster_node_type ram
Turning rabbit@cc into a ram node ...
rabbitmqctl start_app
rabbitmqctl stop_app
rabbitmqctl reset ----》 Resetting node rabbit@cc ...
[root@cc rabbitmq]# rabbitmqctl cluster_status #查看状态发现节点cc脱离了集群
Cluster status of node rabbit@cc ...
[{nodes,[{disc,[rabbit@cc]}]}, #脱离集群后的节点自动会变成disc的方式,原因在下方 1
{running_nodes,[rabbit@cc]},
{cluster_name,<<"rabbit@cc">>}, #并没有其他节点的名称说明不在集群内了
{partitions,[]},
{alarms,[{rabbit@cc,[]}]}]
rabbitmqctl forget_cluster_node rabbit@node3
rabbitmqctl reset
rabbitmqctl start_app
rabbitmqctl cluster_status
openstack共享组件--rabbitmq消息队列(1)的更多相关文章
- OpenStack共享组件-RabbitMQ消息队列
1. MQ 全称为 Message Queue, 消息队列( MQ ),是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们. 消息 ...
- OpenStack组件——RabbitMQ消息队列
1.MQ 全称为 Message Queue, 消息队列( MQ ) 是一种应用程序对应用程序的通信方法.应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们. 消息传 ...
- openstack (共享服务) 消息队列rabbitmq服务
云计算openstack共享组件——消息队列rabbitmq(3) 一.MQ 全称为 Message Queue, 消息队列( MQ ) 是一种应用程序对应用程序的通信方法.应用程序通过读写出入队 ...
- 使用EasyNetQ组件操作RabbitMQ消息队列服务
RabbitMQ是一个由erlang开发的AMQP(Advanved Message Queue)的开源实现,是实现消息队列应用的一个中间件,消息队列中间件是分布式系统中重要的组件,主要解决应用耦合, ...
- OpenStack共享组件
一.云计算的前世今生 1.物理机架构,应用部署和运行在物理机上 2.虚拟化架构,物理机上运行若干虚拟机,应用系统直接部署到虚拟机上 3.云计算架构,虚拟化提高了单台物理机的资源使用率 二.Open ...
- RabbitMQ消息队列(一): Detailed Introduction 详细介绍
http://blog.csdn.net/anzhsoft/article/details/19563091 RabbitMQ消息队列(一): Detailed Introduction 详细介绍 ...
- RabbitMQ消息队列1: Detailed Introduction 详细介绍
1. 历史 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有 ...
- (转)RabbitMQ消息队列(四):分发到多Consumer(Publish/Subscribe)
上篇文章中,我们把每个Message都是deliver到某个Consumer.在这篇文章中,我们将会将同一个Message deliver到多个Consumer中.这个模式也被成为 "pub ...
- RabbitMQ消息队列应用
RabbitMQ消息队列应用 消息通信组件Net分布式系统的核心中间件之一,应用与系统高并发,各个组件之间解耦的依赖的场景.本框架采用消息队列中间件主要应用于两方面:一是解决部分高并发的业务处理:二是 ...
随机推荐
- Tomcat基础知识
介绍Tomcat之前先介绍下Java相关的知识. 各常见组件: 1.服务器(server):Tomcat的一个实例,通常一个JVM只能包含一个Tomcat实例:因此,一台物理服务器上可以在启动多个JV ...
- Python学习笔记:序列构成的数组
列表推导是一种构建列表(list)的快捷方式 #列表推导 symbols = '!@#$%' codes = [ord(symbol) for symbol in symbols] #ord()Pyt ...
- 【构造 meet in middle 随机 矩阵树定理】#75. 【UR #6】智商锁
没智商了 变式可见:[构造 思维题]7.12道路建设 当你自信满满地把你认为的正确密码输入后,时光机滴滴报警 —— 密码错误.你摊坐在了地上. 黑衣人满意地拍了拍你的肩膀:“小伙子,不错嘛.虽然没解开 ...
- BZOJ4777 [Usaco2017 Open]Switch Grass[最小生成树+权值线段树套平衡树]
标题解法是吓人的. 图上修改询问,不好用数据结构操作.尝试转化为树来维护.发现(不要问怎么发现的)最小生成树在这里比较行得通,因为最近异色点对一定是相邻的(很好想),所以只要看最短的一条两端连着异色点 ...
- 201871010105-曹玉中《面向对象程序设计(java)》第十七周学习总结
201871010105-曹玉中<面向对象程序设计(java)>第十七周学习总结 项目 内容 这个作业属于哪个过程 https://www.cnblogs.com/nwnu-daizh/ ...
- Mybatis问题-Type interface com.zzu.ssm.dao.UserMapper is not known to the MapperRegistry
1. mapper.xml中namespace名称是否与dao接口包名一致 2. 在mybatis配置文件中注册mapper
- hdu 6052 To my boyfriend
题目 OvO click here http://acm.hdu.edu.cn/showproblem.php?pid=6052 (2017 Multi-University Training Con ...
- Remote API(RAPI)之 系统信息
RAPI提供了一些取系统信息的函数 CeGetSystemInfo:返回当前系统信息 CeGetSystemMetrics:获取Windows元素的尺寸和系统设置 CeGetVersionEx:获取当 ...
- [CCTF] pwn350
0x00: 之前打了CCTF,在CCTF的过程中遇到一个比较有意思的思路,记录一下. 0x01: 可以看到,这是一个 fmt 的漏洞,不过很简单,接收的输入都在stack中,可以确定输入在栈中的位置, ...
- pdf缩略图上传组件
之前仿造uploadify写了一个HTML5版的文件上传插件,没看过的朋友可以点此先看一下~得到了不少朋友的好评,我自己也用在了项目中,不论是用户头像上传,还是各种媒体文件的上传,以及各种个性的业务需 ...