表的操作管理和 MySQL 的约束控制
一、表的操作
1、表的基本概念
数据库与表之间的关系:数据库是由各种数据表组成的,数据表是数据库中最重要的对象,用来存储和操作数据的逻辑结构。
表由列和行组成,列是表数据的描述,行是表数据的实例。
表的操作:创建新表、修改表和删除表。
2、创建表
创建数据表可使用 CREATE TABLE 命令
语法格式:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] table_name [([column_definition], … | [index_definition])] [table_option] [select_statement];
注意:在同一个数据库中,表名不能有重名。
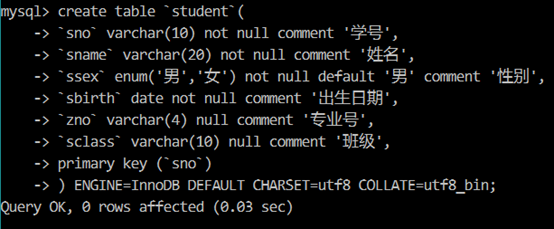
【例1】在 studentInfo 数据库中创建 Student 表,包括字段:学号(sno,非空,char(10)),姓名(sname,非空,varchar(20)),性别(ssex,char(2)),出生日期(sbirth,data,非空),专业号(zno,varchar(20)),班级(sclass,varchar(10))
3、查看表
1)显示表的名称
语法格式:
SHOW TABLES ;
【例2】显示数据库 studentInfo 中所有的表

2)显示表的结构
查看表结构有简单查询和详细查询,可使用 DESCRIBE / DESC 语句 和 SHOW CREATE TABLE 语句
语法格式: DESCRIBE 表名; 或者 DESC 表名; 或者 SHOW CREATE TABLE 表名;
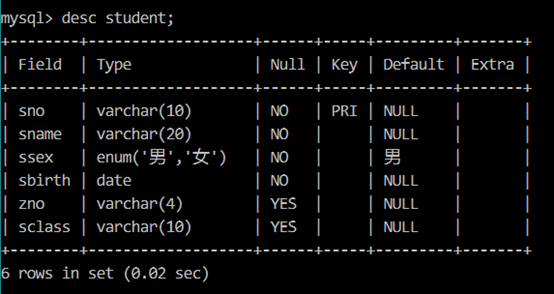
【例3】3 种命令显示数据库 studentInfo 中表 student 的结构

4、修改表
ALTER TABLE 用于更改原有的结构。例如,可以增加或删除列、重命名列或表,还可以修改字符集。
语法格式:
alter [ ignore] table table_name
alter_specification [, alter_specification]
add [column] column_definition[ first | after col_name] // 添加字段
| alter [column] col_name {set default literal | drop default} // 修改字段
| change [column] old_col_name column_definition [first| after col_name] // 重命名字段
| modify [column] column_definition [first | after col_name] // 修改字段
| drop [column] col_name // 删除列
| rename [to] new_table_name // 对表重命名
| order by col_name // 按字段排序
| convert to character set character_name [collate collation_name] // 将字段集转化为二进制
| [default] character set charset_name [collate collation_name] // 修改字符集
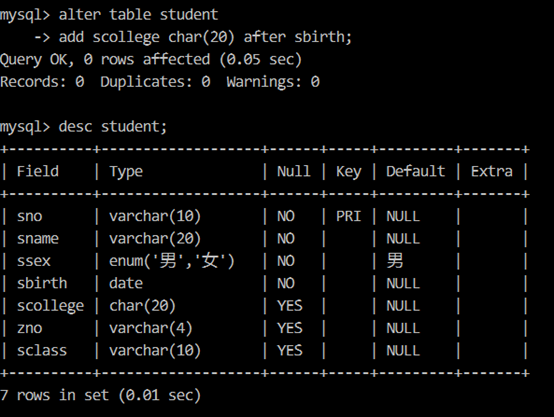
【例4】在 student 表的出生日期字段后添加一个数据类型为 char,长度为 20 的字段 scollege,允许为空,表示学生所在学院
【例5】还使用 alter table 命令把 scollege 字段删除
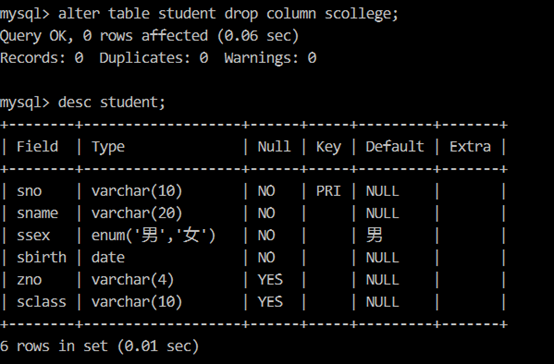
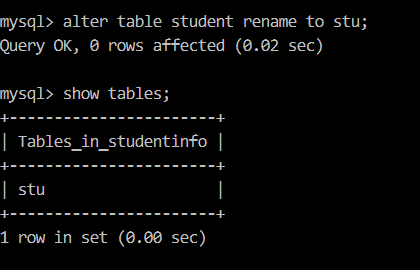
【例6】把 student 表名改为 stu
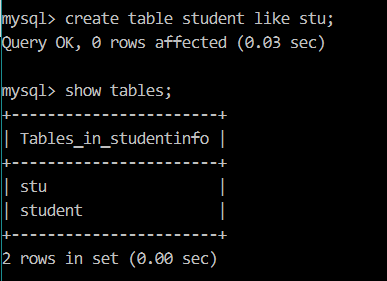
5、复制表
语法格式:
create [temporary] table [if not exists] table_name [ () like old_table_name [] ] | [AS (select_statement)];
【例7】复制 stu 表到 student 表中
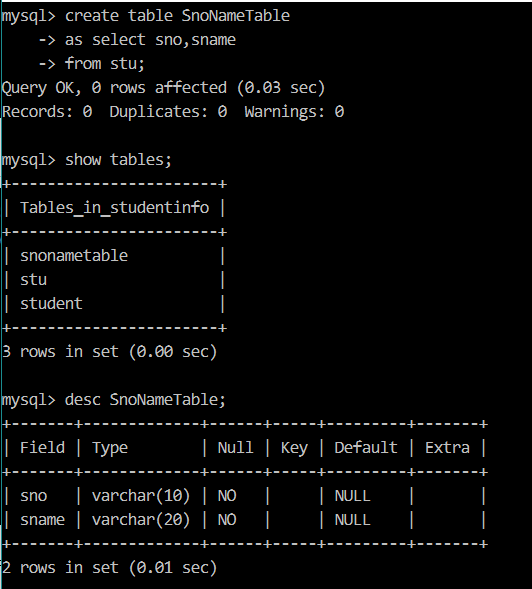
【例8】复制 stu 表中的学号(sno),姓名(sname)到新的表 SnoNameTable
6、删除表
删除表可以用 DROP TABLE 命令
语法格式:
drop table [if exists] table_name [,table_name] …
【例9】删除 stu 表和 SnoNameTable 表

可以用 show tables 命令查看 studentInfo 中现在剩余的表
7、表管理中的注意事项
1)关于空值(NULL)的说明
空值通常用于表示未知、不可用或将在以后添加的数据,切不可将它与数字 0 或字符类型的空字符混为一谈。
2)关于列的标志(IDENTITY)属性
任何表都可以创建一个包含系统所生成序号值的标志列。该序号值唯一标志表中的一列,且可以作为键值。
3)关于列类型的隐含改变
在 MySQL 中,系统会隐含地改变在 CREATE TABEL 语句或 ALTER TBALE 语句中所指定的列类型。
长度小于 4 的 VARCHAR 类型会被改变为 CHAR 类型。
二、MySQL 约束控制
1、数据完整性约束
数据的完整性总体来说可分为以下 4 类,即实体完整性、参照完整性、域完整性和用户自定义完整性
实体完整性:实体的完整性强制表的标识符列或主键的完整性(通过约束,唯一约束,主键约束或标识列属性)
参照完整性:在删除和输入记录时,引用完整性保持表之间已定义的关系,引用完整性确保键值在所有表中一致。
域完整性:限制类型(数据类型),格式(检查约束和规则),可能值范围(外键约束,检查约束,默认值定义,非空约束和规则)
用户自定义完整性:用户自己定义的业务规则。
2、字段的约束
设计数据库时,可以对数据库表中的一些字段设置约束条件,由数据库管理系统(如 MySQL)自动检测输入的数据是否满足约束条件,不满足约束条件的数据,数据库管理系统拒绝录入。MySQL 支持的常用约束条件有 6 种:主键(primary key)约束、外键(foreign key)约束、非空(not null)约束、唯一性(unique)约束、默认值(default)约束、自增约束(auto_increment)及检查(check)约束。其中,检查约束需要借助触发器或者 MySQL 复合数据类型实现。
1)主键(primary key)约束
设计数据库时,建议为所有的数据库表都定义一个主键,用于保证数据库表中记录的唯一性。一张表中只允许设置一个主键,这个主键可以是一个字段,也可以是一个字段组(不建议使用复合主键)。在录入数据的过程中,必须在所有主键字段中输入数据,即任何主键字段的值不允许为 NULL。
设置主键通常有两种方式:表级完整性约束和列级完整性约束。
假设一个表的主键是单个字段ID。如果用表级完整性约束,就是用 PRIMARY KEY 命令单独设置主键为 ID 列。
语法规则:
PRIMARY KEY(字段名)
【例10】创建学生 stu1 表,用表的完整性设置学号 sno 字段为主键

如果用列级完整性约束,就是直接在该字段的数据类型或者其他约束条件后加上 “primary key” 关键字,即可将该字段设置为主键约束。
语法规则:
字段名 数据类型[其他约束条件] primary key
【例11】创建学生 stu2 表,用列的完整性设置学号 sno 字段为主键

如果一个表的主键是多个字段的组合,定义完所有的字段后,设置复合主键。
语法规则:
primary key (字段名1, 字段名2)
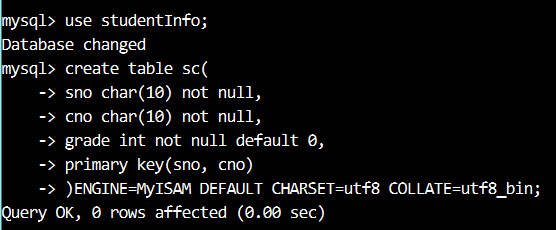
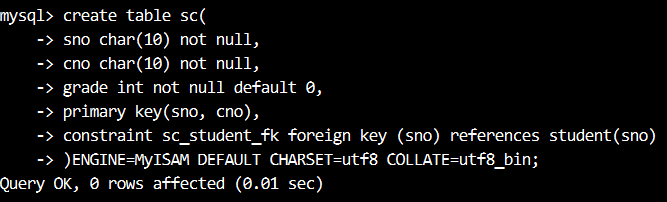
【例12】使用下面的 SQL 语句在 studentInfo 数据库中创建 SC 表,并将 (sno,cno) 的字段组合设置为 SC 表的主键
2)外键(foreign key)约束
外键约束主要用于定义表与表之间的某种关系。表 A 外键字段的取值,要么是 null,要么是来自于表 B 主键字段的取值(此时将表 A 称之为表 B 的子表,表 B 称之为表 A 的父表)
由于子表和父表之间的外键约束关系:
(1)如果子表的记录 “参照” 了父表的某条记录,那么父表这一条记录的删除(delete)或修改(update)操作可能以失败告终。
(2)如果试图直接插入(insert)或者修改(update)子表的 “外键值” ,子表中的 “外键值” 必须是父表中的 “主键值”,要么是 NULL,否则插入(insert)或者修改(update)操作失败。
例如,学生 student 表的班级号 class_no 字段的值要么是 null,要么是来自于班级 classes 表的 class_no 字段的取值。也可以这样说,学生 student 表的 class_no 字段的取值必须参照(reference)班级 classes 表的 class_no 字段的取值
在表 A 中外键的设置也有两种方式,一种是在表级完整性下定义外键约束,一种是在列级完整性下定义外键约束
表级完整性语法规则如下:
foregin key (表A的字段名列表) references (表B的字段名列表)
[ on delete {cascade| restrict |set null | no action} ]
[on update {cascade| restrict |set null | no action} ]
级联的选项有四种取值,其意义如下:
cascade:父表记录的删除(delete)或修改(update)操作会自动删除或修改子表中与之对应的记录。
set null:父表记录的删除(delete)或修改(update)操作会将子表中与之对应记录的外键值自动设置为 null 值。
no action:父表记录的删除(delete)或修改(update)操作如果子表存在与之对应的记录,那么删除或修改操作将失败。
restrict:与 no action 功能相同,且为级联选项的默认值。
如果表已经建好,那么可以通过 alter table 命令添加,语法如下:
alter table table_name
add [ constraint 外键名] foregin key [id](index_col_name, ……)
references table_name(index_col_name, ……)
[ on delete {cascade| restrict |set null | no action} ]
[ on update {cascade| restrict |set null | no action} ]
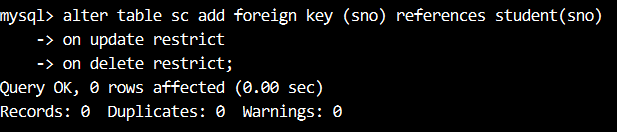
【例13】将 sc 表的 sno 字段设置为外键,该字段的值参照(reference)班级 student 表的 sno 字段的取值
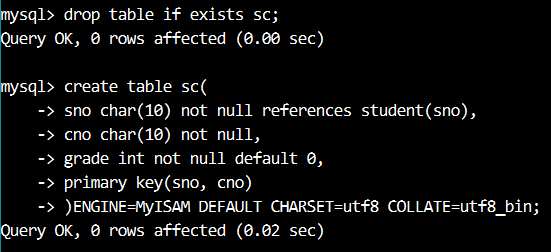
在列级完整性下定义外键约束,就是直接在列的后面添加 references 命令,例如:
表级完整性约束和列级完整性约束都是在 CREATE TABLE 语句中定义。还有另外一种方式,就是使用完整性约束命名字句 CONSTRAINT,用来对完整性约束条件命名,从而可以灵活的增加、删除一个完整性约束条件。
完整性约束命名字句格式:
constraint <完整性约束条件名> [PRIMARY KEY 短语| FOREIGN KEY 短语 | CHECK 短语]
【例14】创建 sc 表,将 sno 字段设置为外键
3)非空(not NULL)约束
如果某个字段满足非空约束的要求,则可以向该字段添加非空约束。非空约束限制该字段的内容不能为空,但可以是空白。
语法规则:
字段名 数据类型 not null
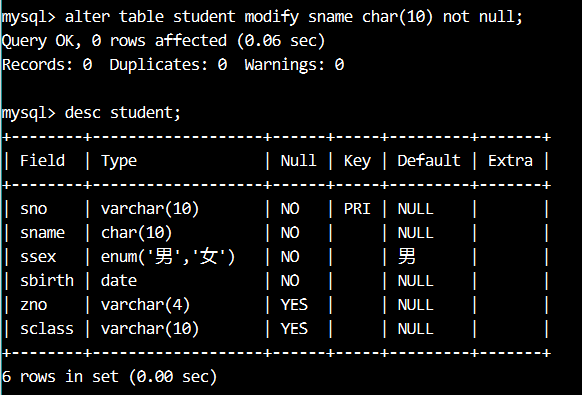
【例15】将学生 student 表的姓名 sname 字段设置为非空约束
4)唯一性(unique)约束
如果某个字段满足唯一性约束要求,则可以向该字段添加唯一性约束。与主键约束不同,一张表中可以存在多个唯一性约束,并且满足唯一性约束的字段可以取 NULL 值。
语法规则:
字段名 数据类型 unique
【例16】创建班级 classes 表,班级名 class_name 字段设置为非空约束以及唯一性约束

5)默认值(default)约束
如果某个字段满足默认值约束要求,可以向该字段添加默认值约束。
语法规则:
字段名 数据类型 [其他约束条件] default 默认值
【例17】创建课程 course 表,其 up_limit 字段设置默认值约束,且默认值为整数 60

6)自增(auto_increment)约束
AUTO_INCREMENT 是 MySQL 唯一扩展的完整性约束,当为数据库表中插入新记录时,字段上的值会自动生成唯一的 ID 。
语法格式:
CREATE TABLE table_name(
属性名 数据类型 AUTO_INCREMENT,
……
);
【例18】创建表 t_dept 时,设置 deptno 字段为 AUTO_INCREMENT 和 PK 约束

7)删除(delete)约束
一个字段的所有约束都可以用 alter table 命令删除
【例19】删除表 sc 中名称为 sc_studen_fk 的约束

表的操作管理和 MySQL 的约束控制的更多相关文章
- Learning-MySQL【4】:表的操作管理和 MySQL 的约束控制
一.表的操作 1.表的基本概念 数据库与表之间的关系:数据库是由各种数据表组成的,数据表是数据库中最重要的对象,用来存储和操作数据的逻辑结构. 表由列和行组成,列是表数据的描述,行是表数据的实例. 表 ...
- MYSQL数据库学习五 表的操作和约束
5.1 表的基本概念 表示包含数据库中所有数据的数据库对象.一行代表唯一的记录,一列代表记录的一个字段. 列(Columns):属性列,创建表时必须指定列名和数据类型. 索引(Indexes):根据指 ...
- MYSQL中约束及修改数据表
MYSQL中约束及修改数据表 28:约束约束保证数据的完整性和一致性约束分为表级约束和列级约束约束类型包括: NOT NULL(非空约束) PRIMARY KEY(主键约束) UNI ...
- Mysql数据表的操作
表的操作 前提:选择数据库 语法: use 数据库名; 1.创建数据表 语法: create table 表名( 字段1 字段类型 [附加属性], 字段2 字段类型 [附加属性], 字段3 字段类型 ...
- MySQL的外键,修改表,基本数据类型,表级别操作,其他(条件,通配符,分页,排序,分组,联合,连表操作)
MySQL的外键,修改表,基本数据类型,表级别操作,其他(条件,通配符,分页,排序,分组,联合,连表操作): a.创建2张表 create table userinfo(nid int not nul ...
- Mysql之表的操作与索引操作
表的操作: 1.表的创建: create table if not exists table_name(字段定义); 例子: create table if not exists user(id in ...
- 存储引擎和表的操作(mysql中的数据类型、完整性约束)
一.存储引擎 .概念 MySQL中的数据用各种不同的技术存储在文件(或者内存)中.这些技术中的每一种技术都使用不同的存储机制.索引技巧.锁定水平并且最终提供广泛的不同的功能和能力. 通过选择不同的技术 ...
- MySQL之库表详细操作
一 库操作 1.创建数据库 1.1 语法 CREATE DATABASE 数据库名 charset utf8; 1.2 数据库命名规则 可以由字母.数字.下划线.@.#.$ 区分大小写 唯一性 不能使 ...
- Mysql数据库 的库表简易操作
一. 库的操作 1.创建数据库 创建数据库: create database 库名 charset utf8; charset uft8 可选项 1.2 数据库命名规范: 可以由字母.数字.下划 ...
随机推荐
- Windows下同时安装两个版本Jdk
在项目开发中遇到了jdk版本切换的问题,于是尝试在电脑中安装jdk1.6和jdk1.7,话不多说马上开始 1 准备好两个版本的jdk路径 2 设置两个JAVA_HOME 3 设置总的动态切换的JAVA ...
- Vue介绍:vue导读3
一.全局组件 二.父组件传递信息给子组件 三.子组件传递信息给父组件 四.vue项目开发 一.全局组件 <body> <!-- 两个全局vue实例可以不用注册全局组件,就可以使用 - ...
- 设计模式之Template Method
1.设计模式的使用场景 模板方法模式(Template Method) 解释一下模板方法模式,就是指:一个抽象类中,有一个主方法,再定义1…n个方法,可以是抽象的,也可以是实际的方法,定义一个类,继承 ...
- bat 读取 ini 文件
bat 读取 ini 文件 参考链接:https://stackoverflow.com/questions/2866117/windows-batch-script-to-read-an-ini-f ...
- JAVA遇见HTML——JSP篇(案例项目)
- 在Myeclipse中没有部署jeesite项目,但是每次运行其他项目时,还是会加载jeesite项目
解决办法: 一.在以下路径中找到jeesite文件,并删除 1.Tomcat 7.0\conf\Catalina\localhost 2.Tomcat 7.0\webapps 3.Tomcat 7.0 ...
- 从Excel中读取数据并批量写入MySQL数据库(基于MySQLdb)
一.Excel内容如下,现在需要将Excel中的数据全部写入的MySQL数据库中: 二.连接MySQL的第三方库使用的是“MySQLdb”,代码如下: # -*- coding:utf-8 -*-im ...
- dockerfile-maven plugin自动镜像制作并发布
环境准备:win10+docker 1.打开hyper-v 2.下载最新版本docker:https://store.docker.com/editions/community/docker-ce-d ...
- flutter 项目中打印原生安卓的log信息
因为项目的需要 在flutter 中调用安卓的方法 再用安卓的方法去调用c写的so包 方法 如果当前项目下面没有android stduio 自带的logcat 那就利用下面的方法 在安卓代码中引入 ...
- RabbitMQ与Spring集成配置
1.引入相关jar包 //RabbitMQ compile group: 'org.springframework.amqp', name: 'spring-rabbit', version: '1. ...