《数据结构与算法之美》 <02>复杂度分析(下):浅析最好、最坏、平均、均摊时间复杂度?
上一节,我们讲了复杂度的大 O 表示法和几个分析技巧,还举了一些常见复杂度分析的例子,比如 O(1)、O(logn)、O(n)、O(nlogn) 复杂度分析。掌握了这些内容,对于复杂度分析这个知识点,你已经可以到及格线了。但是,我想你肯定不会满足于此。
今天会继续给你讲四个复杂度分析方面的知识点,最好情况时间复杂度(best case time complexity)、最坏情况时间复杂度(worst case time complexity)、平均情况时间复杂度(average case time complexity)、均摊时间复杂度(amortized time complexity)。如果这几个概念你都能掌握,那对你来说,复杂度分析这部分内容就没什么大问题了。
最好、最坏情况时间复杂度
上一节我举的分析复杂度的例子都很简单,今天我们来看一个稍微复杂的。你可以用我上节教你的分析技巧,自己先试着分析一下这段代码的时间复杂度。
// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) pos = i;
}
return pos;
}
你应该可以看出来,这段代码要实现的功能是,在一个无序的数组(array)中,查找变量 x 出现的位置。如果没有找到,就返回 -1。按照上节课讲的分析方法,这段代码的复杂度是 O(n),其中,n 代表数组的长度。
我们在数组中查找一个数据,并不需要每次都把整个数组都遍历一遍,因为有可能中途找到就可以提前结束循环了。但是,这段代码写得不够高效。我们可以这样优化一下这段查找代码。
// n表示数组array的长度
int find(int[] array, int n, int x) {
int i = 0;
int pos = -1;
for (; i < n; ++i) {
if (array[i] == x) {
pos = i;
break;
}
}
return pos;
}
这个时候,问题就来了。我们优化完之后,这段代码的时间复杂度还是 O(n) 吗?很显然,咱们上一节讲的分析方法,解决不了这个问题。
因为,要查找的变量 x 可能出现在数组的任意位置。如果数组中第一个元素正好是要查找的变量 x,那就不需要继续遍历剩下的 n-1 个数据了,那时间复杂度就是 O(1)。但如果数组中不存在变量 x,那我们就需要把整个数组都遍历一遍,时间复杂度就成了 O(n)。所以,不同的情况下,这段代码的时间复杂度是不一样的。
为了表示代码在不同情况下的不同时间复杂度,我们需要引入三个概念:最好情况时间复杂度、最坏情况时间复杂度和平均情况时间复杂度。
顾名思义,最好情况时间复杂度就是,在最理想的情况下,执行这段代码的时间复杂度。就像我们刚刚讲到的,在最理想的情况下,要查找的变量 x 正好是数组的第一个元素,这个时候对应的时间复杂度就是最好情况时间复杂度。
同理,最坏情况时间复杂度就是,在最糟糕的情况下,执行这段代码的时间复杂度。就像刚举的那个例子,如果数组中没有要查找的变量 x,我们需要把整个数组都遍历一遍才行,所以这种最糟糕情况下对应的时间复杂度就是最坏情况时间复杂度。
平均情况时间复杂度
我们都知道,最好情况时间复杂度和最坏情况时间复杂度对应的都是极端情况下的代码复杂度,发生的概率其实并不大。为了更好地表示平均情况下的复杂度,我们需要引入另一个概念:平均情况时间复杂度,后面我简称为平均时间复杂度。
平均时间复杂度又该怎么分析呢?我还是借助刚才查找变量 x 的例子来给你解释。
要查找的变量 x 在数组中的位置,有 n+1 种情况:在数组的 0~n-1 位置中和不在数组中。我们把每种情况下,查找需要遍历的元素个数累加起来,然后再除以 n+1,就可以得到需要遍历的元素个数的平均值,即:

我们知道,时间复杂度的大 O 标记法中,可以省略掉系数、低阶、常量,所以,咱们把刚刚这个公式简化之后,得到的平均时间复杂度就是 O(n)。
这个结论虽然是正确的,但是计算过程稍微有点儿问题。究竟是什么问题呢?我们刚讲的这 n+1 种情况,出现的概率并不是一样的。我带你具体分析一下。(这里要稍微用到一点儿概率论的知识,不过非常简单,你不用担心。)
我们知道,要查找的变量 x,要么在数组里,要么就不在数组里。这两种情况对应的概率统计起来很麻烦,为了方便你理解,我们假设在数组中与不在数组中的概率都为 1/2。另外,要查找的数据出现在 0~n-1 这 n 个位置的概率也是一样的,为 1/n。所以,根据概率乘法法则,要查找的数据出现在 0~n-1 中任意位置的概率就是 1/(2n)。
因此,前面的推导过程中存在的最大问题就是,没有将各种情况发生的概率考虑进去。如果我们把每种情况发生的概率也考虑进去,那平均时间复杂度的计算过程就变成了这样:
这个值就是概率论中的加权平均值,也叫作期望值,所以平均时间复杂度的全称应该叫加权平均时间复杂度或者期望时间复杂度。
引入概率之后,前面那段代码的加权平均值为 (3n+1)/4。用大 O 表示法来表示,去掉系数和常量,这段代码的加权平均时间复杂度仍然是 O(n)。
你可能会说,平均时间复杂度分析好复杂啊,还要涉及概率论的知识。实际上,在大多数情况下,我们并不需要区分最好、最坏、平均情况时间复杂度三种情况。像我们上一节课举的那些例子那样,很多时候,我们使用一个复杂度就可以满足需求了。只有同一块代码在不同的情况下,时间复杂度有量级的差距,我们才会使用这三种复杂度表示法来区分。
均摊时间复杂度
到此为止,你应该已经掌握了算法复杂度分析的大部分内容了。下面我要给你讲一个更加高级的概念,均摊时间复杂度,以及它对应的分析方法,摊还分析(或者叫平摊分析)。
均摊时间复杂度,听起来跟平均时间复杂度有点儿像。对于初学者来说,这两个概念确实非常容易弄混。我前面说了,大部分情况下,我们并不需要区分最好、最坏、平均三种复杂度。平均复杂度只在某些特殊情况下才会用到,而均摊时间复杂度应用的场景比它更加特殊、更加有限。
老规矩,我还是借助一个具体的例子来帮助你理解。(当然,这个例子只是我为了方便讲解想出来的,实际上没人会这么写。)
// array表示一个长度为n的数组
// 代码中的array.length就等于n
int[] array = new int[n];
int count = 0; void insert(int val) {
if (count == array.length) {
int sum = 0;
for (int i = 0; i < array.length; ++i) {
sum = sum + array[i];
}
array[0] = sum;
count = 1;
} array[count] = val;
++count;
}
我先来解释一下这段代码。这段代码实现了一个往数组中插入数据的功能。当数组满了之后,也就是代码中的 count == array.length 时,我们用 for 循环遍历数组求和,并清空数组,将求和之后的 sum 值放到数组的第一个位置,然后再将新的数据插入。但如果数组一开始就有空闲空间,则直接将数据插入数组。
那这段代码的时间复杂度是多少呢?你可以先用我们刚讲到的三种时间复杂度的分析方法来分析一下。
最理想的情况下,数组中有空闲空间,我们只需要将数据插入到数组下标为 count 的位置就可以了,所以最好情况时间复杂度为 O(1)。最坏的情况下,数组中没有空闲空间了,我们需要先做一次数组的遍历求和,然后再将数据插入,所以最坏情况时间复杂度为 O(n)。
那平均时间复杂度是多少呢?答案是 O(1)。我们还是可以通过前面讲的概率论的方法来分析。假设数组的长度是 n,根据数据插入的位置的不同,我们可以分为 n 种情况,每种情况的时间复杂度是 O(1)。除此之外,还有一种“额外”的情况,就是在数组没有空闲空间时插入一个数据,这个时候的时间复杂度是 O(n)。而且,这 n+1 种情况发生的概率一样,都是 1/(n+1)。所以,根据加权平均的计算方法,我们求得的平均时间复杂度就是:
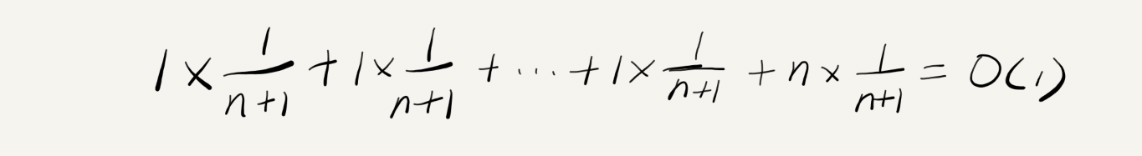
至此为止,前面的最好、最坏、平均时间复杂度的计算,理解起来应该都没有问题。但是这个例子里的平均复杂度分析其实并不需要这么复杂,不需要引入概率论的知识。这是为什么呢?我们先来对比一下这个 insert() 的例子和前面那个 find() 的例子,你就会发现这两者有很大差别。
首先,find() 函数在极端情况下,复杂度才为 O(1)。但 insert() 在大部分情况下,时间复杂度都为 O(1)。只有个别情况下,复杂度才比较高,为 O(n)。这是 insert()第一个区别于 find() 的地方。
我们再来看第二个不同的地方。对于 insert() 函数来说,O(1) 时间复杂度的插入和 O(n) 时间复杂度的插入,出现的频率是非常有规律的,而且有一定的前后时序关系,一般都是一个 O(n) 插入之后,紧跟着 n-1 个 O(1) 的插入操作,循环往复。
所以,针对这样一种特殊场景的复杂度分析,我们并不需要像之前讲平均复杂度分析方法那样,找出所有的输入情况及相应的发生概率,然后再计算加权平均值。
针对这种特殊的场景,我们引入了一种更加简单的分析方法:摊还分析法,通过摊还分析得到的时间复杂度我们起了一个名字,叫均摊时间复杂度。
那究竟如何使用摊还分析法来分析算法的均摊时间复杂度呢?
我们还是继续看在数组中插入数据的这个例子。每一次 O(n) 的插入操作,都会跟着 n-1 次 O(1) 的插入操作,所以把耗时多的那次操作均摊到接下来的 n-1 次耗时少的操作上,均摊下来,这一组连续的操作的均摊时间复杂度就是 O(1)。这就是均摊分析的大致思路。你都理解了吗?
均摊时间复杂度和摊还分析应用场景比较特殊,所以我们并不会经常用到。为了方便你理解、记忆,我这里简单总结一下它们的应用场景。如果你遇到了,知道是怎么回事儿就行了。
对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系,这个时候,我们就可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。而且,在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。
尽管很多数据结构和算法书籍都花了很大力气来区分平均时间复杂度和均摊时间复杂度,但其实我个人认为,均摊时间复杂度就是一种特殊的平均时间复杂度,我们没必要花太多精力去区分它们。你最应该掌握的是它的分析方法,摊还分析。至于分析出来的结果是叫平均还是叫均摊,这只是个说法,并不重要。
《数据结构与算法之美》 <02>复杂度分析(下):浅析最好、最坏、平均、均摊时间复杂度?的更多相关文章
- Chapter4 复杂度分析(下):浅析最好,最坏,平均,均摊时间复杂度
四个复杂度分析: 1:最好情况时间复杂度(best case time complexity) 2:最坏情况时间复杂度(worst case time complexity) 3:平均情况时间复杂度( ...
- 《数据结构与算法之美》 <05>链表(下):如何轻松写出正确的链表代码?
想要写好链表代码并不是容易的事儿,尤其是那些复杂的链表操作,比如链表反转.有序链表合并等,写的时候非常容易出错.从我上百场面试的经验来看,能把“链表反转”这几行代码写对的人不足 10%. 为什么链表代 ...
- 《数据结构与算法之美》 <01>复杂度分析(上):如何分析、统计算法的执行效率和资源消耗?
我们都知道,数据结构和算法本身解决的是“快”和“省”的问题,即如何让代码运行得更快,如何让代码更省存储空间.所以,执行效率是算法一个非常重要的考量指标. 那如何来衡量你编写的算法代码的执行效率呢?这里 ...
- JavaScript 数据结构与算法之美 - 十大经典排序算法汇总(图文并茂)
1. 前言 算法为王. 想学好前端,先练好内功,内功不行,就算招式练的再花哨,终究成不了高手:只有内功深厚者,前端之路才会走得更远. 笔者写的 JavaScript 数据结构与算法之美 系列用的语言是 ...
- JavaScript 数据结构与算法之美 - 冒泡排序、插入排序、选择排序
1. 前言 算法为王. 想学好前端,先练好内功,只有内功深厚者,前端之路才会走得更远. 笔者写的 JavaScript 数据结构与算法之美 系列用的语言是 JavaScript ,旨在入门数据结构与算 ...
- JavaScript 数据结构与算法之美 - 非线性表中的树、堆是干嘛用的 ?其数据结构是怎样的 ?
1. 前言 想学好前端,先练好内功,内功不行,就算招式练的再花哨,终究成不了高手. 非线性表(树.堆),可以说是前端程序员的内功,要知其然,知其所以然. 笔者写的 JavaScript 数据结构与算法 ...
- 《数据结构与算法之美》 <06>栈:如何实现浏览器的前进和后退功能?
浏览器的前进.后退功能,我想你肯定很熟悉吧? 当你依次访问完一串页面 a-b-c 之后,点击浏览器的后退按钮,就可以查看之前浏览过的页面 b 和 a.当你后退到页面 a,点击前进按钮,就可以重新查看页 ...
- 《数据结构与算法之美》 <04>链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是 LRU 缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- JavaScript 数据结构与算法之美 - 线性表(数组、栈、队列、链表)
前言 基础知识就像是一座大楼的地基,它决定了我们的技术高度. 我们应该多掌握一些可移值的技术或者再过十几年应该都不会过时的技术,数据结构与算法就是其中之一. 栈.队列.链表.堆 是数据结构与算法中的基 ...
随机推荐
- 使用xhprof进行线上PHP性能追踪及分析
转自: http://avnpc.com/pages/profiler-php-performance-online-by-xhprof
- 【Python】机器学习之单变量线性回归 利用正规方程找到合适的参数值
[Python]机器学习之单变量线性回归 利用正规方程找到合适的参数值 本次作业来自吴恩达机器学习. 你是一个餐厅的老板,你想在其他城市开分店,所以你得到了一些数据(数据在本文最下方),数据中包括不同 ...
- ETH&EOS开发资源及工具集合(完整汇总版)
ETH&EOS开发资源及工具集合(完整汇总版) 3113 ETH开发资源篇 一.开发语言 · Solidity - 官方推荐以太坊智能合约开发语言,也是目前最为主流的智能合约语 ...
- Android开发环境搭建(eclipse版)
1.下载安装JDK 网址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
- 【ARM-Linux开发】"libxml/parser.h: 没有那个文件或目录"解决方案
这是因为在ubuntu上没有安装libxml2-dev,这个包应该是开发用的,而已安装的libxml2应该只是像jre一样的部件. 解决方案:sudo apt-get install libxml2- ...
- 监听input框变化,即时搜索 compositionstart, compositionend
前话: 如果直接通过input监听, 它是键盘输入按键按下了就触发时间,这样可能导致一些问题,比如在谷歌浏览器想输入中文输入不了: 解决方案: 用 compositionstart 和 composi ...
- poj 2362:square
题目大意:给你T组数据,每组数据有n个棍子,问你能不能用这些棍子拼成一个正方形(所有都要用上,而且不能截断棍子). Sample Input 34 1 1 1 15 10 20 30 40 508 1 ...
- gdb调试工具学习
GDB 是GNU开源组织发布的一个强大的UNIX下的程序调试工具.或许,各位比较喜欢那种图形界面方式的,像VC.BCB等IDE的调试,但如果你是在 UNIX平台下做软件,你会发现GDB这个调试工具有比 ...
- 学习笔记:CentOS7学习之十九:Linux网络管理技术
目录 学习笔记:CentOS7学习之十九:Linux网络管理技术 本文用于记录学习体会.心得,兼做笔记使用,方便以后复习总结.内容基本完全参考学神教育教材,图片大多取材自学神教育资料,在此非常感谢MK ...
- yum源 epel源 替换及安装
#!/bin/sh # 备份yum源 zip -r /etc/yum.repos.d/yum_resource_back_up.zip /etc/yum.repos.d/* # 替换yum源 wget ...