【python+beautifulsoup4】Beautifulsoup4
Beautiful soup将复杂HTML文档转换成一个复杂的属性结构,每个节点都是python对象,所有对象可归纳为4种Tag,NavigableString,BeautifulSoup,Comment
1.Tag 就是html中的一个个标签
tag有两个重要的属性,name和attrs
2.NavigableString 字符对象
#打印出标签p中的内容
print (soup.p.string)
3.BeautifulSoup 表示的是一个文档的内容
⼤部分时候,可以把它当作Tag 对象, 是⼀个特殊的 Tag
4.Comment 特殊的NavigableString对象
输出的内容不包括注释符号
一、遍历文档树:
1.直接子节点:.contents和.children属性
.conten
tag 的 .content 属性可以将tag的⼦节点以列表的⽅式输出
Print(soup.head.contents)
# [<head>the domouse’s story</head>]
.children 返回的是list对象
print (soup.head.children)
#<listiterator object at 0x7f71457f5710>
for child in soup.body.children:
print (child)
2.所有子孙节点:.descendants
contents 和 .children 属性仅包含tag的直接⼦节点, .descendants 属性可以对所有tag的⼦孙节点进⾏递归循环, 和 children类似, 我们也需要遍历获取其中的内容。
for child in soup.descendants:
print (child)
- 通过一个例子来更直观的看出三者之间的区别
获取的节点如下
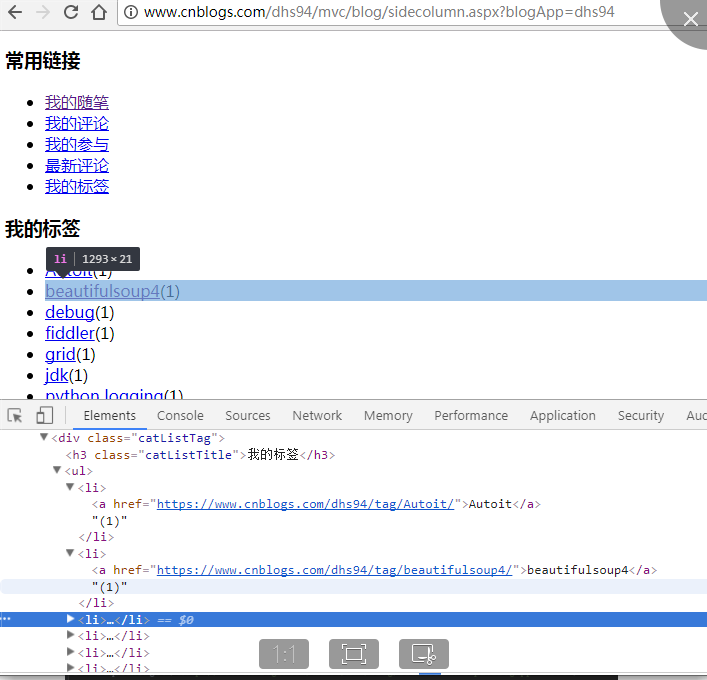
以下代码分别获取了class=‘catListTag’下直接子节点和子孙子节点的信息
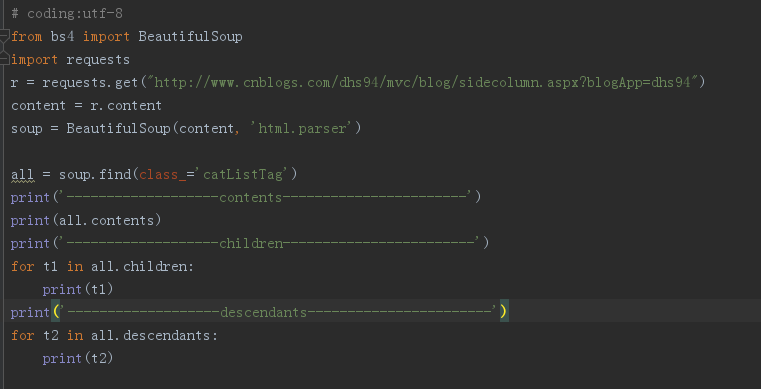
运行结果:
D:\PycharmProjects\ImoocInterface\venv\Scripts\python.exe D:/PycharmProjects/ImoocInterface/soup_test.py
-------------------contents-----------------------
['\n', <h3 class="catListTitle">我的标签</h3>, '\n', <ul>
<li><a href="https://www.cnblogs.com/dhs94/tag/Autoit/">Autoit</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/beautifulsoup4/">beautifulsoup4</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/debug/">debug</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/fiddler/">fiddler</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/grid/">grid</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/jdk/">jdk</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/python%20logging/">python logging</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/%E8%BF%9B%E7%A8%8B/">进程</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/%E6%A8%A1%E5%9D%97/">模块</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/%E7%BA%BF%E7%A8%8B/">线程</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/">更多</a></li>
</ul>, '\n']
-------------------children------------------------
<h3 class="catListTitle">我的标签</h3>
<ul>
<li><a href="https://www.cnblogs.com/dhs94/tag/Autoit/">Autoit</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/beautifulsoup4/">beautifulsoup4</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/debug/">debug</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/fiddler/">fiddler</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/grid/">grid</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/jdk/">jdk</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/python%20logging/">python logging</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/%E8%BF%9B%E7%A8%8B/">进程</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/%E6%A8%A1%E5%9D%97/">模块</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/%E7%BA%BF%E7%A8%8B/">线程</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/">更多</a></li>
</ul>
-------------------descendants-----------------------
<h3 class="catListTitle">我的标签</h3>
我的标签
<ul>
<li><a href="https://www.cnblogs.com/dhs94/tag/Autoit/">Autoit</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/beautifulsoup4/">beautifulsoup4</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/debug/">debug</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/fiddler/">fiddler</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/grid/">grid</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/jdk/">jdk</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/python%20logging/">python logging</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/%E8%BF%9B%E7%A8%8B/">进程</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/%E6%A8%A1%E5%9D%97/">模块</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/%E7%BA%BF%E7%A8%8B/">线程</a>(1)</li><li><a href="https://www.cnblogs.com/dhs94/tag/">更多</a></li>
</ul>
<li><a href="https://www.cnblogs.com/dhs94/tag/Autoit/">Autoit</a>(1)</li>
<a href="https://www.cnblogs.com/dhs94/tag/Autoit/">Autoit</a>
Autoit
(1)
<li><a href="https://www.cnblogs.com/dhs94/tag/beautifulsoup4/">beautifulsoup4</a>(1)</li>
<a href="https://www.cnblogs.com/dhs94/tag/beautifulsoup4/">beautifulsoup4</a>
beautifulsoup4
(1)
<li><a href="https://www.cnblogs.com/dhs94/tag/debug/">debug</a>(1)</li>
<a href="https://www.cnblogs.com/dhs94/tag/debug/">debug</a>
debug
.....................
对比三者可发现,contens和children输出为直接子节点的内容即<h3>和<ul>标签所包含的内容,而descendant输出为子孙节点的内容不仅有<h3>和<ul>所包含的内容,还直接输出了<ul>标签下<li>标签的内容<a>
3.节点内容:.string属性
二、搜索
1. find_all(name, attrs, recursive, text,**kwargs)
1) name 参数
name 参数可以查找所有名字为 name 的tag,字符串对象会被⾃动忽略掉
A.传字符串
最简单的过滤器是字符串.在搜索⽅法中传⼊⼀个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容,下⾯的例⼦⽤于查找⽂档中所有的 <b> 标签:
soup.find_all('b')
# [<b>The Dormouse's story</b>]
B.传正则表达式
如果传⼊正则表达式作为参数,Beautiful Soup会通过正则表达式的 match()来匹配内容.下⾯例⼦中找出所有以b开头的标签,这表示 <body> 和 <b> 标签都应该被找到
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# b
C.传列表
如果传⼊列表参数,Beautiful Soup会将与列表中任⼀元素匹配的内容返回.下⾯代码找到⽂档中所有 <a> 标签和 <b> 标签:
soup.find_all(["a", "b"])
# [<b>The Dormouse's story</b>,
# <a class="sister" href="http://example.com/elsie"; id="link1">Els
ie</a>,
# <a class="sister" href="http://example.com/lacie"; id="link2">Lac
ie</a>,
# <a class="sister" href="http://example.com/tillie"; id="link3">Ti
llie</a>]
2) keyword 参数
soup.find_all(id_='link2')或soup.find_all(class_='link2')
注意关键字后的下划线,没有下划线会报错
# [<a class="sister" href="http://example.com/lacie"; id="link2">Lac
ie</a>]
3) text 参数
通过 text 参数可以搜搜⽂档中的字符串内容, 与 name 参数的可选值⼀样,text 参数接受 字符串 , 正则表达式 , 列表
soup.find_all(text="Elsie")
# [u'Elsie']
2.soup.find(name, attrs, recursive, text,**kwargs)
找到第一个符合的对象
三、css选择器
与soup.find_all()类似,查找所有符合的节点并返回list
(1)通过标签查找 soup.select(‘b’)
返回所有标签为<b>的节点
(2)通过类名或ID查找
Soup.select(‘.classname’)
Soup.select(‘#id’)
(3)组合查找
标签+类Soup.select(‘b .classname’)
返回b标签中类名为classname的节点
子标签查找Soup.select(‘head>title’)
返回父标签为head的title节点
(4)属性查找
Soup.select(“a[class=’link’]”)
标签为a且class为link的节点
Soup.select(“p a[class=’link’]”)
返回p标签中a[class=’link’]的节点
(5)获取内容
get_text()

四、爬网页图片
1、目标网站
1) 打开一个风景图的网站:https://www.enterdesk.com/
2) 用 firebug 定位
3)从下图可以看出,所有的图片都是 img 标签,父节点class属性为egeli_pic_dl
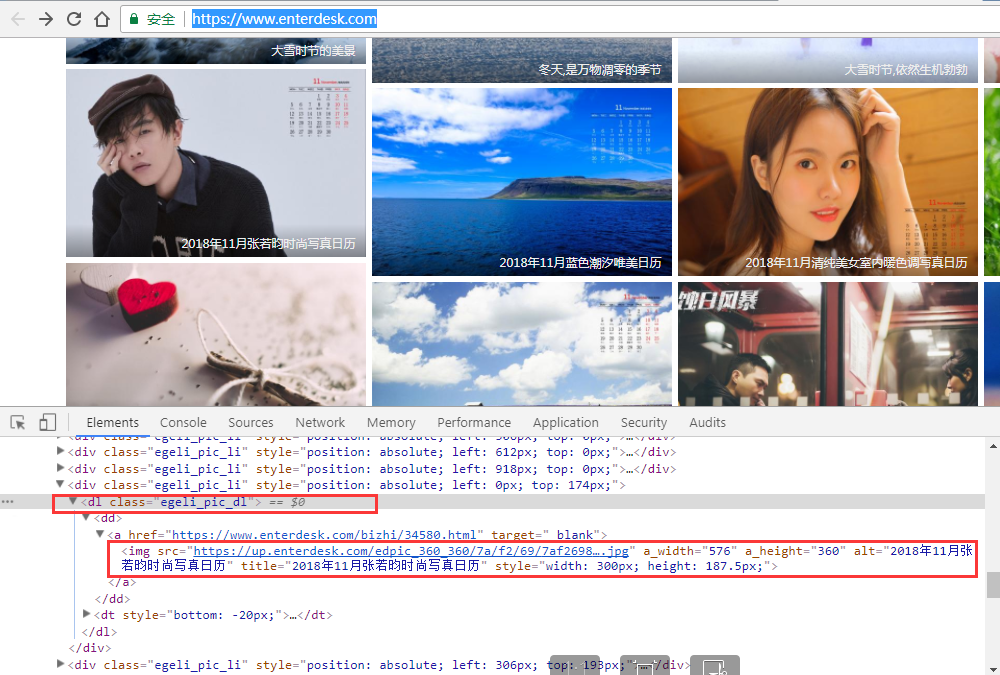
2、用 find_all 找出所有的标签
1).find_all(class_="legeli_pic_dl")获取所有的图片对象标签
2).从标签里面提出 jpg 的 url 地址和 title
from bs4 import BeautifulSoup
import requests
import os
r = requests.get("https://www.enterdesk.com/")
# 获取页面内容
content = r.content
# 用html.parser解析html
soup = BeautifulSoup(content, 'html.parser')
# 获取所有class为egene_pic_dl,返回tag类,为list
all = soup.find_all(class_='egeli_pic_dl')
for i in all:
# 获取图片路径和名称
img_url = i.img['src']
img_name = i.img['title']
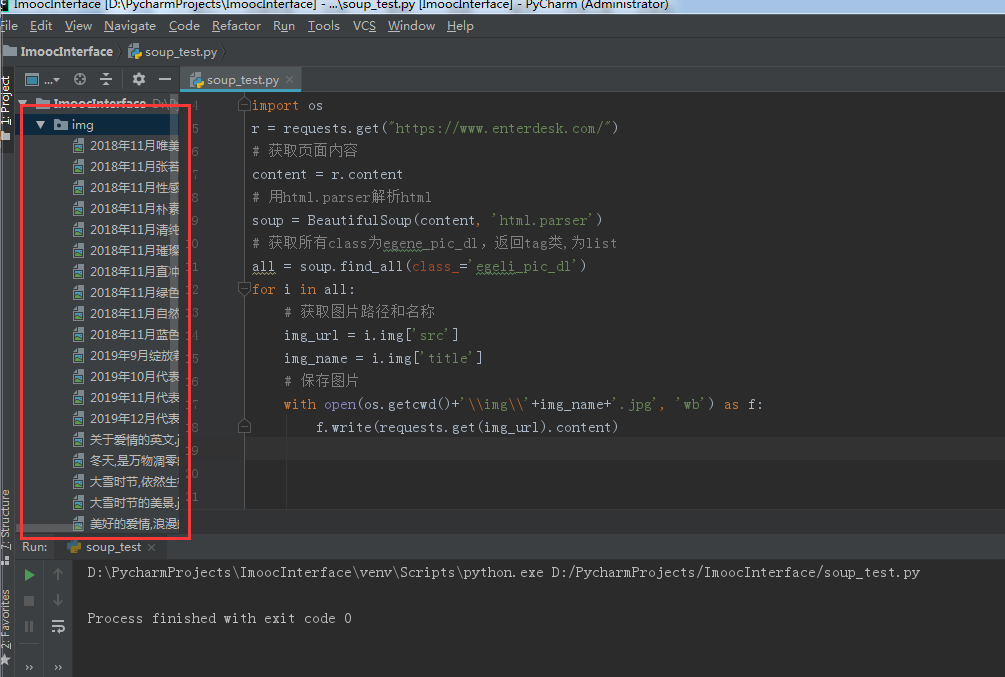
3.保存图片
1).在当前脚本文件夹下创建一个 img 的子文件夹
2).导入 os 模块,os.getcwd()这个方法可以获取当前脚本的路径
3).用 open 打开写入本地电脑的文件路径,命名为:os.getcwd()+"\\img\\"+img_name+'.jpg'(命名重复的话,会被覆盖掉)
4).requests 里 get 打开图片的 url 地址,content 方法返回的是二进制流文件,可以直接写到本地
for i in all:
# 获取图片路径和名称
img_url = i.img['src']
img_name = i.img['title']
# 保存图片
with open(os.getcwd()+'\\img\\'+img_name+'.jpg', 'wb') as f:
f.write(requests.get(img_url).content)
4.运行结果
【python+beautifulsoup4】Beautifulsoup4的更多相关文章
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
- 【Python数据分析】Python3操作Excel(二) 一些问题的解决与优化
继上一篇[Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 对豆瓣图书Top250进行爬取以后,鉴于还有一些问题没有解决,所以进行了进一步的交流讨论,这期间得到了一只尼玛 ...
- 利用Dnspod api批量更新添加DNS解析【python脚本】 - 推酷
利用Dnspod api批量更新添加DNS解析[python脚本] - 推酷 undefined
- 【python进阶】详解元类及其应用2
前言 在上一篇文章[python进阶]详解元类及其应用1中,我们提到了关于元类的一些前置知识,介绍了类对象,动态创建类,使用type创建类,这一节我们将继续接着上文来讲~~~ 5.使⽤type创建带有 ...
- 【python进阶】Garbage collection垃圾回收2
前言 在上一篇文章[python进阶]Garbage collection垃圾回收1,我们讲述了Garbage collection(GC垃圾回收),画说Ruby与Python垃圾回收,Python中 ...
- 【python进阶】深入理解系统进程2
前言 在上一篇[python进阶]深入理解系统进程1中,我们讲述了多任务的一些概念,多进程的创建,fork等一些问题,这一节我们继续接着讲述系统进程的一些方法及注意点 multiprocessing ...
- 【python图像处理】图像的缩放、旋转与翻转
[python图像处理]图像的缩放.旋转与翻转 图像的几何变换,如缩放.旋转和翻转等,在图像处理中扮演着重要的角色,python中的Image类分别提供了这些操作的接口函数,下面进行逐一介绍. 1.图 ...
- 【Python 开发】Python目录
目录: [Python开发]第一篇:计算机基础 [Python 开发]第二篇 :Python安装 [Python 开发]第三篇:python 实用小工具
- 【Python教程】《零基础入门学习Python》(小甲鱼)
[Python教程]<零基础入门学习Python>(小甲鱼) 讲解通俗易懂,诙谐. 哈哈哈. https://www.bilibili.com/video/av27789609
- 【python系列】python画报表(Chartkick、Flask)(附中文乱码解决方式)
chartkick 能够画 javascript 报表, 并且比較美观.可是网上搜了下.非常难找到 python 版本号的,于是查了些资料,摸索了下. 对 Flask 也不非常熟悉,这里就仅仅抛砖引玉 ...
随机推荐
- cv2.bitwise_and的应用,
import cv2 import numpy as np Load two images img1 = cv2.imread('messi.png') img2 = cv2.imread('logo ...
- postman使用当前时间戳
//设置当前时间戳postman.setGlobalVariable(“time”,Math.round(new Date().getTime()));time = postman.getGlobal ...
- nginx rewrite正则子组最多匹配到$9
nginx rewrite正则匹配()匹配子组最多匹配到$9,就是从$0到$9 当需要匹配更多子组时,可通过变量来实现 if ($uri ~ ^/forum-15/sortid-74/(.*?)(la ...
- Django学习参考资料
0. HTTP协议简介http://www.cnblogs.com/maple-shaw/articles/9060408.html 1. 路由系统https://www.cnblogs.com/ma ...
- vue项目中使用v-for的方法莫名提示错误
错误示例: 解决方法一: 在v-for后面绑定key,示例如下→ 解决方法二: 点击左下角“设置”>“用户设置”内添加一下代码片段: { "vetur.validation.templ ...
- ABC技术落地_成功带动lot物联网行业、金融科技行业、智能人才教育。
ABC技术:AI:Python神经网络和自然语言处理(NLP):C ++ 机器学习和神经网络:Java自然语言处理.搜索算法.神经网络:Lisp归纳逻辑项目和机器学习.Big Date:R.Pytho ...
- Go语言注意事项
必须恰当导入需要的包,缺少了必要的包或者导入了不需要的包,程序都无法编译通过.这项严格要求避免了程序开发过程中引入未使用的包(译注:Go语言编译过程没有警告信息,争议特性之一 import 声明必须跟 ...
- Python面向对象中的继承、多态和封装
Python面向对象中的继承.多态和封装 一.面向对象的三大特性 封装:把很多数据封装到⼀个对象中,把固定功能的代码封装到⼀个代码块, 函数,对象, 打包成模块. 这都属于封装思想. 继承:⼦类可以⾃ ...
- 【AC自动机】单词
[题目链接] https://loj.ac/problem/10060 [题意] 某人读论文,一篇论文是由许多单词组成.但他发现一个单词会在论文中出现很多次,现在想知道每个单词分别在论文中出现多少次. ...
- kubernetes 水平伸缩及yaml格式编写
Replication Controller:用来部署.升级PodReplica Set:下一代的Replication ControllerDeployment:可以更加方便的管理Pod和Repli ...