python解析库之 XPath
1. XPath (XML Path Language) XML路径语言
2. XPath 常用规则:
nodename 选取此节点的所有子节点
/ 从当前结点选取直接子节点
// 从当前结点选取子孙节点
. 选取当前结点
.. 选取当前结点的父节点
@ 选取属性
3. 实例
from lxml import etree text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text) # 初始化,构造XPath对象
# 自动修正html代码,最后一个<li>没有闭合,tostring()方法补全html代码,返回结果是bytes类型
result = etree.tostring(html)
print(result.decode('utf-8'))
也可以读取文件来进行解析
from lxml import etree html = etree.parse(r'C:\Users\Administrator\Desktop\test.txt', etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('utf-8'))
4. 使用//开头的XPath规则来选取符合要求的节点
from lxml import etree text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">爱我中华</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
'''匹配节点'''
html = etree.HTML(text)
result1 = html.xpath('//*') # 使用*匹配所有节点
print(result1)
result2 = html.xpath('//li') # 获取所有的li节点
print(result2)
print(result2[0])
result3 = html.xpath('//li/a') # 获取所有li节点的直接a子节点
print(result3) # 首先选中href属性为link3.html的a节点,然后再获取其父亲节点,在获取其class属性的值
# result4 为['item-inactive'],这是个只有一个元素的列表
result4 = html.xpath('//a[@href="link3.html"]/../@class')
print(result4[0])
# 同时, 也可以通过parent::来获取父亲节点 如:
result5 = html.xpath('//a[@href="link3.html"]/parent::*/@class') '''属性匹配 (选取节点时,可以用@符号进行属性过滤)'''
# 匹配属性class="item-inactive"的li节点
result6 = html.xpath('//li[@class="item-inactive"]')
print(result6) '''文本获取 (使用XPath中的text()方法获取节点中的文本)'''
result7 = html.xpath('//li[@class="item-inactive"]/a[@href="link3.html"]/text()')
print(result7) # 打印出 ['爱我中华'] 列表 '''属性获取 使用@来获取属性'''
# 匹配属性href="link3.html"的a节点的父亲节点的class属性
result8 = html.xpath('//a[@href="link3.html"]/../@class')
print(result8) # 打印['item-inactive'] '''属性多值匹配'''
html_test = '''<li class="li item-inactive"><a href="link3.html">爱我中华</a></li>'''
# 这里li标签class属性有两个值, 如果按照上边的属性匹配 是匹配不到的,就要用到contains()函数
html_test = etree.HTML(html_test)
# 通过contains方法,第一个参数穿属性名,第二个传属性值中的任意一个,都可以匹配到
result9 = html_test.xpath('//li[contains(@class, "li")]/a/text()')
print(result9) '''多属性匹配 (根据多个属性来确定一个节点)'''
html_test2 = '''<li class="li item-inactive" name="item"><a href="link3.html">Hello World</a></li>'''
# 这里li标签class属性有两个值, 如果按照上边的属性匹配 是匹配不到的,就要用到contains()函数
html_test = etree.HTML(html_test2)
# 通过contains方法,第一个参数穿属性名,第二个传属性值中的任意一个,都可以匹配到
result10 = html_test.xpath('//li[contains(@class, li) and @name="item"]/a[@href="link3.html"]/text()')
print(result10) # 打印['Hello World']
5. XPath 运算符
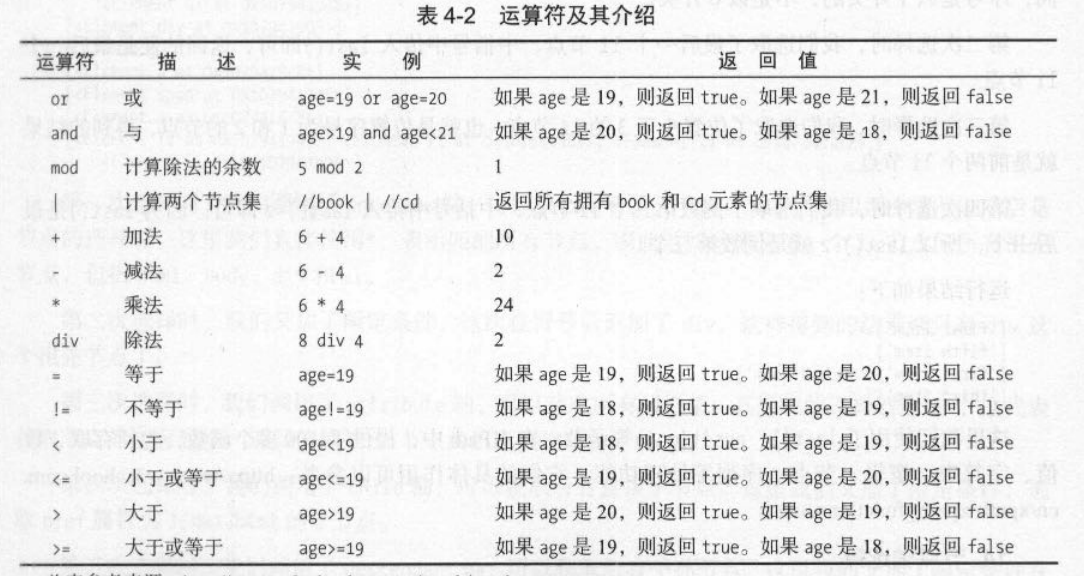
5. 按序选择 (同时匹配了多个节点时但又只想要其中一个节点时)
from lxml import etree text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">爱我中华</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
'''匹配节点后按序选择'''
html = etree.HTML(text)
result1 = html.xpath('//li[1]/a/text()') # 选取匹配到的li节点的第一个
print(result1)
result2 = html.xpath('//li[last()]/a/text()') # 选取匹配到的li节点的最后一个
print(result2)
result3 = html.xpath('//li[position()<3]/a/text()') # 选取匹配到的所有li节点中位置小于3,也就时第1,2个
print(result3)
result4 = html.xpath('//li[last()-2]/a/text()') # 选取匹配到的li节点的倒数第三个
print(result4) '''节点轴选择'''
html = etree.HTML(text)
result5 = html.xpath('//li[1]/ancestor::*') # 选取匹配到的li节点的第一个的所有祖先节点
print(result5)
result6 = html.xpath('//li[1]/attribute::*') # 选取匹配到的li节点的所有属性值
print(result6)
result7 = html.xpath('//li[1]/child::a') # 选取匹配到的li节点的所有子节点
print(result7)
result8 = html.xpath('//li[1]/descendant::a') # 选取匹配到的li节点的所有子孙节点
print(result8)
result9 = html.xpath('//li[1]/following::*') # 选取获取到的当前结点后的所有节点
print(result9)
result10 = html.xpath('//li[1]/following-sibling::*') # 选取获取到的当前结点之后的所有同级节点
print(result10)
python解析库之 XPath的更多相关文章
- python爬虫三大解析库之XPath解析库通俗易懂详讲
目录 使用XPath解析库 @(这里写自定义目录标题) 使用XPath解析库 1.简介 XPath(全称XML Path Languang),即XML路径语言,是一种在XML文档中查找信息的语言. ...
- 爬虫解析库:XPath
XPath XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言.最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的 ...
- python解析库
BeautifulSoup示例: #!/usr/bin/env python # -*- coding: utf-8 -*- # author: imcati html_doc = "&qu ...
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- xpath beautiful pyquery三种解析库
这两天看了一下python常用的三种解析库,写篇随笔,整理一下思路.太菜了,若有错误的地方,欢迎大家随时指正.......(conme on.......) 爬取网页数据一般会经过 获取信息-> ...
- Python3编写网络爬虫05-基本解析库XPath的使用
一.XPath 全称 XML Path Language 是一门在XML文档中 查找信息的语言 最初是用来搜寻XML文档的 但是它同样适用于HTML文档的搜索 XPath 的选择功能十分强大,它提供了 ...
- python爬虫的页面数据解析和提取/xpath/bs4/jsonpath/正则(1)
一.数据类型及解析方式 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为两部分,非结构化的数据 和 结构化的数据. 非结构化数据:先有数据,再有结构, 结构化数 ...
- (最全)Xpath、Beautiful Soup、Pyquery三种解析库解析html 功能概括
一.Xpath 解析 xpath:是一种在XMl.html文档中查找信息的语言,利用了lxml库对HTML解析获取数据. Xpath常用规则: nodename :选取此节点的所有子节点 // : ...
- python爬虫之html解析Beautifulsoup和Xpath
Beautiifulsoup Beautiful Soup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup 用来解析 HTML 比较简 ...
随机推荐
- Java VisualVM添加Visual GC插件
1.访问地址:https://visualvm.github.io/pluginscenters.html,找到自己JDK版本对应的插件下载地址(我的JDK版本为1.7.0_67): 2.点击该链接进 ...
- dtexec命令执行SSIS包
默认情况下,同时安装了 64 位和 32 位版本的 Integration Services 命令提示实用工具的 64 位计算机将在命令提示符处运行 32 位版本.运行 32 位版本的原因是:在 PA ...
- dynomite:高可用多数据中心同步
https://github.com/Netflix/dynomite Dynomite, inspired by Dynamo whitepaper, is a thin, distributed ...
- Angular2中实现基于TypeScript的对象合并方法:extend()
TypeScript里面没有现成的合并对象的方法,这里借鉴jQuery里的$.extend()方法.写了一个TypeScript的对象合并方法,使用方法和jQuery一样. 部分代码和jQuery代码 ...
- 2017年3月14日-----------乱码新手自学.net 之Authorize特性与Forms身份验证(登陆验证、授权小实例)
有段时间没写博客了,最近工作比较忙,能敲代码的时间也不多. 我一直有一个想法,想给单位免费做点小软件,一切思路都想好了,但是卡在一个非常基础的问题上:登陆与授权. 为此,我看了很多关于微软提供的Ide ...
- String、String Buffer、String Builder
对于String.String Buffer.String Builder:我一直都只知道String是字符串常量,后两者是字符串变量: String和String Buffer是线程安全的,Stri ...
- jar包生成exe可执行程序
1.生成工具EXE4J下载链接:https://www.ej-technologies.com/download/exe4j/files 2.安装.使用:https://blog.csdn.net/h ...
- C# 初始学习心情
当听说需要转做.net的时候.内心是忐忑不安的.因为突然从前端转向后端,几乎完全颠倒了...一个注重界面实现功能.一个注重逻辑的开发,然并卵,服从需求吧. 虽说公司需要你转.但是时间是不允许的,所以只 ...
- JFinal视频教程-JFnal学院分享课
最近JFinal学院出了JFinal视频教程分享课,请笑纳~ 课程列表: 1.[JFinal版]微信小程序富文本渲染解决方案-html2wxml4J分享课 这个课程主要讲的是使用基于JFinal开发的 ...
- 【TensorFlow入门完全指南】模型篇·最近邻模型
最近邻模型,更为常见的是k-最近邻模型,是一种常见的机器学习模型,原理如下: KNN算法的前提是存在一个样本的数据集,每一个样本都有自己的标签,表明自己的类型.现在有一个新的未知的数据,需要判断它的类 ...