ElasticSearch基础+文档CRUD操作
本篇博客是上一篇的延续,主要用来将年前学习ES的知识点做一个回顾,方便日后进行复习和汇总!因为近期项目中使用ES出现了点小问题,因此在这里做一个详细的汇总!
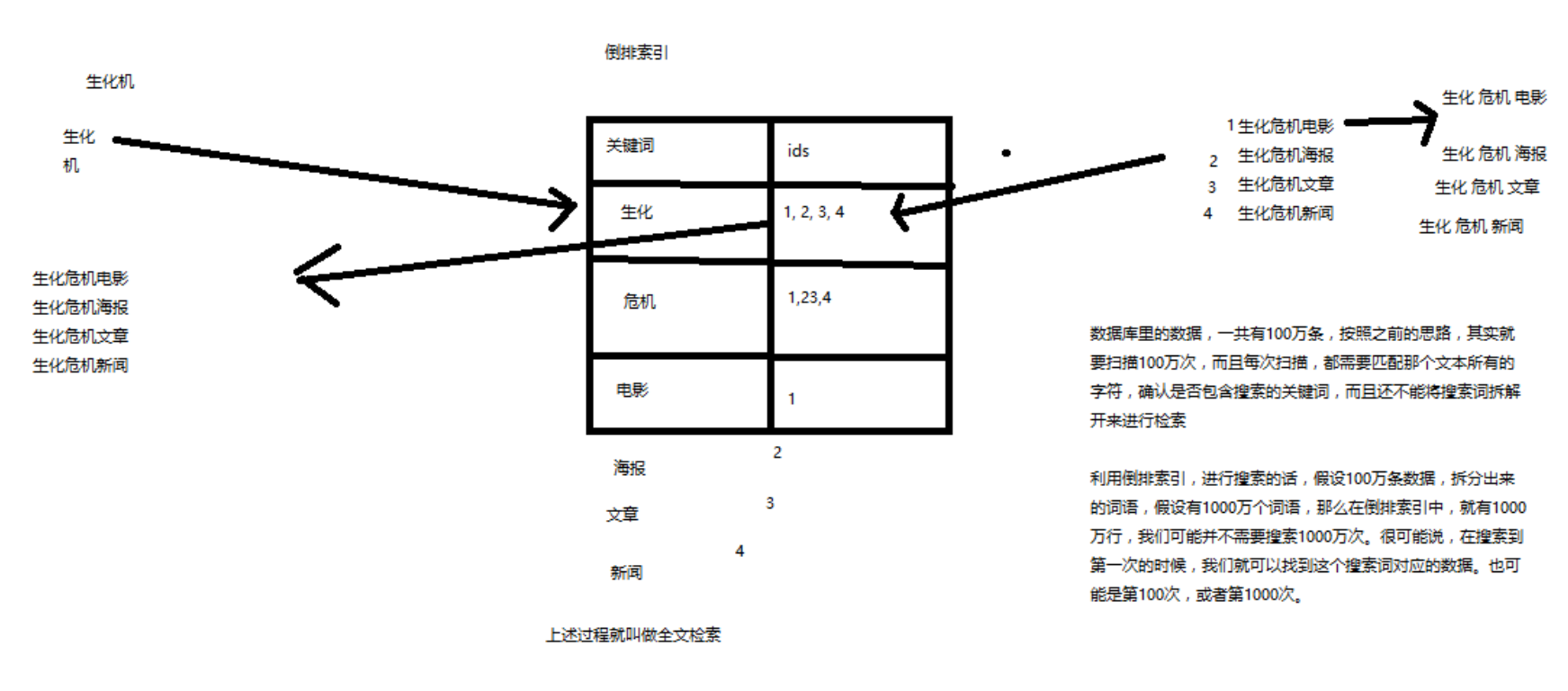
【01】全文检索和Lucene
【02】Elasticsearch的功能
【03】Elasticsearch的特点
【04】elasticsearch的核心概念
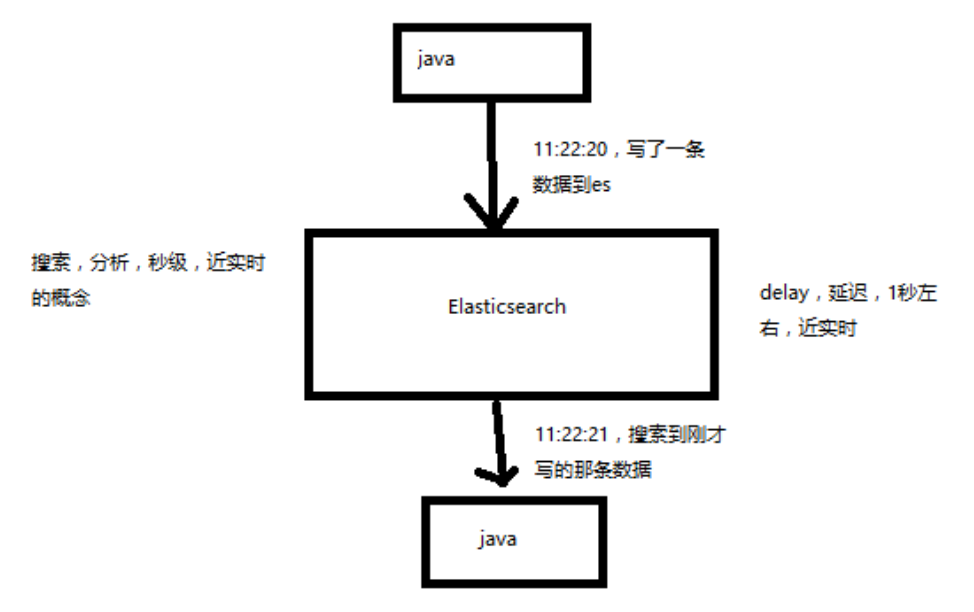
举个稍微形象点的例子:
举个例子:
商品index,里面存放了所有的商品数据,即商品document 但是商品分很多种类,每个种类的document的field可能不太一样,比如说电器商品,可能还包含一些诸如
售后时间范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field type,日化商品type,电器商品type,生鲜商品type 日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period 每一个type里面,都会包含一堆document
{
"product_id": "",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "",
"category_name": "电器",
"service_period": "1年"
}
{
"product_id": "",
"product_name": "基围虾",
"product_desc": "纯天然,冰岛产",
"category_id": "",
"category_name": "生鲜",
"eat_period": "7天"
}
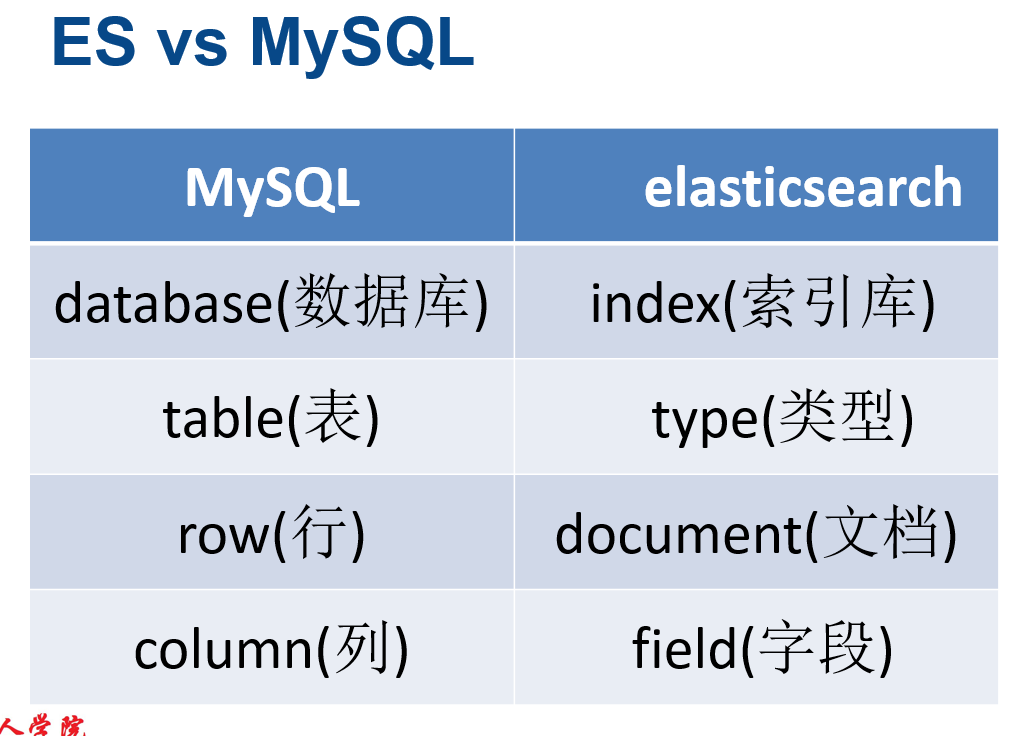
因此归根结底就是index里面有很多个Type,而每个type又有很多document。即一个数据库(index)中有很多表(type),每张表中又有很多行数据(document)
下面再来看ES中的两个核心概念:
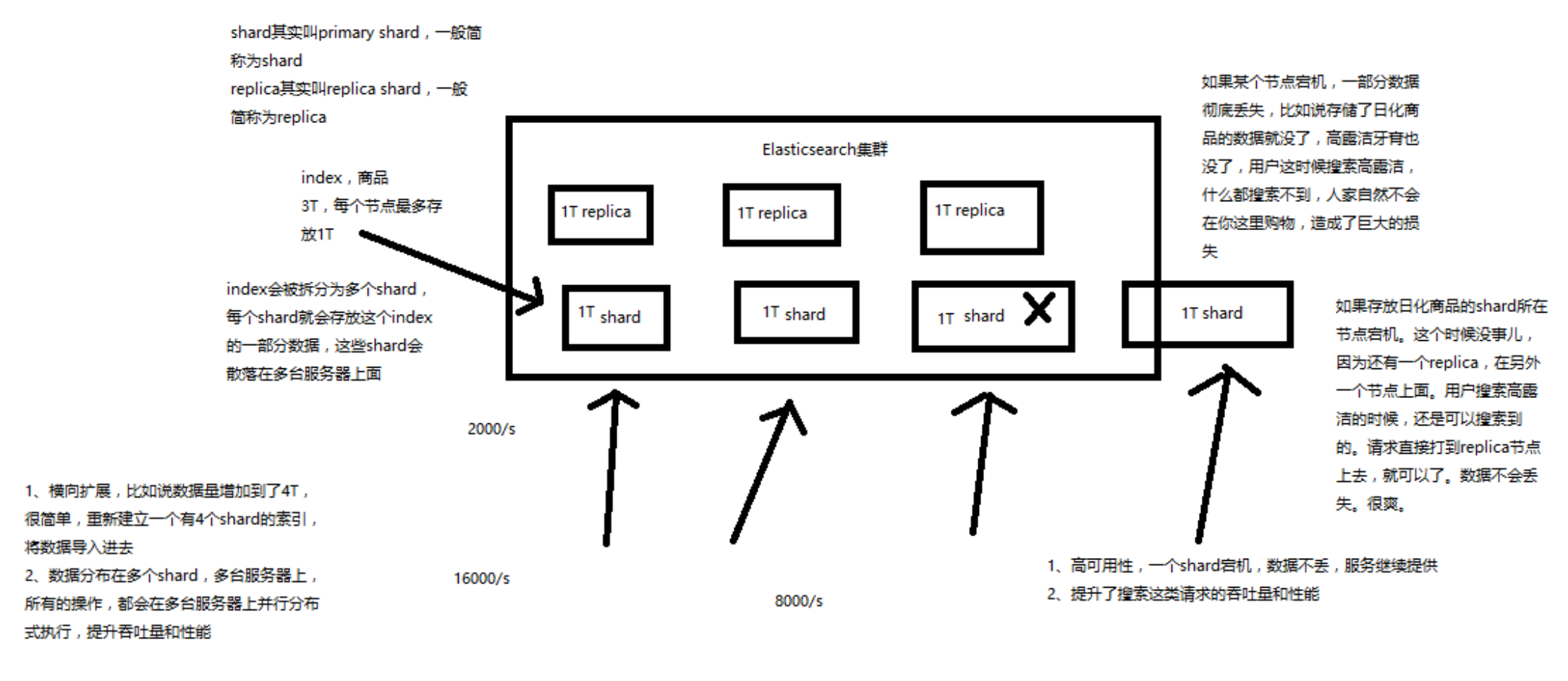
()shard:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
()replica:任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个
replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞
吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个
),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
ES规定primary shard和replica shard不能在同一个节点上。因此我们一般将ES搭建在两台服务器上。
通过如下的一张图就可以很清晰的明白上面的概念了:
【05】ES的基本操作
关于ES的安装网络上有很多博客,笔者在此不再赘述。
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
:: elasticsearch yellow - 50.0% epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
:: elasticsearch green - 100.0% epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
:: elasticsearch yellow - 50.0%
如何快速了解集群的健康状况?green、yellow、red?
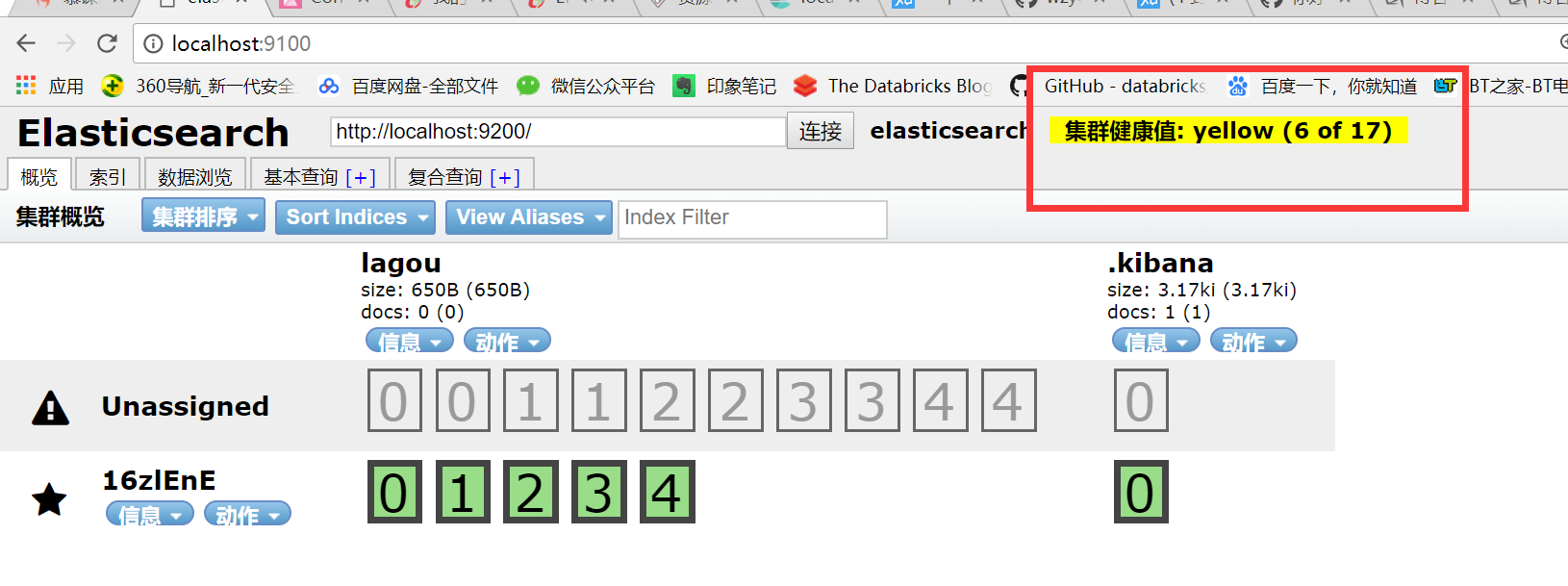
原因:
我们现在就一个笔记本电脑,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每个index分配5个
primary shard和5个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。现在kibana自己建立的index是1个primary shard和1个
replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动。
索引操作:
()快速查看集群中有哪些索引 GET /_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg .1kb .1kb ()简单的索引操作 创建索引:PUT /test_index?pretty health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open test_index XmS9DTAtSkSZSwWhhGEKkQ 650b 650b
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg .1kb .1kb 删除索引:DELETE /test_index?pretty health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg .1kb .1kb
基本的CRUD操作:

如下才是正确的:
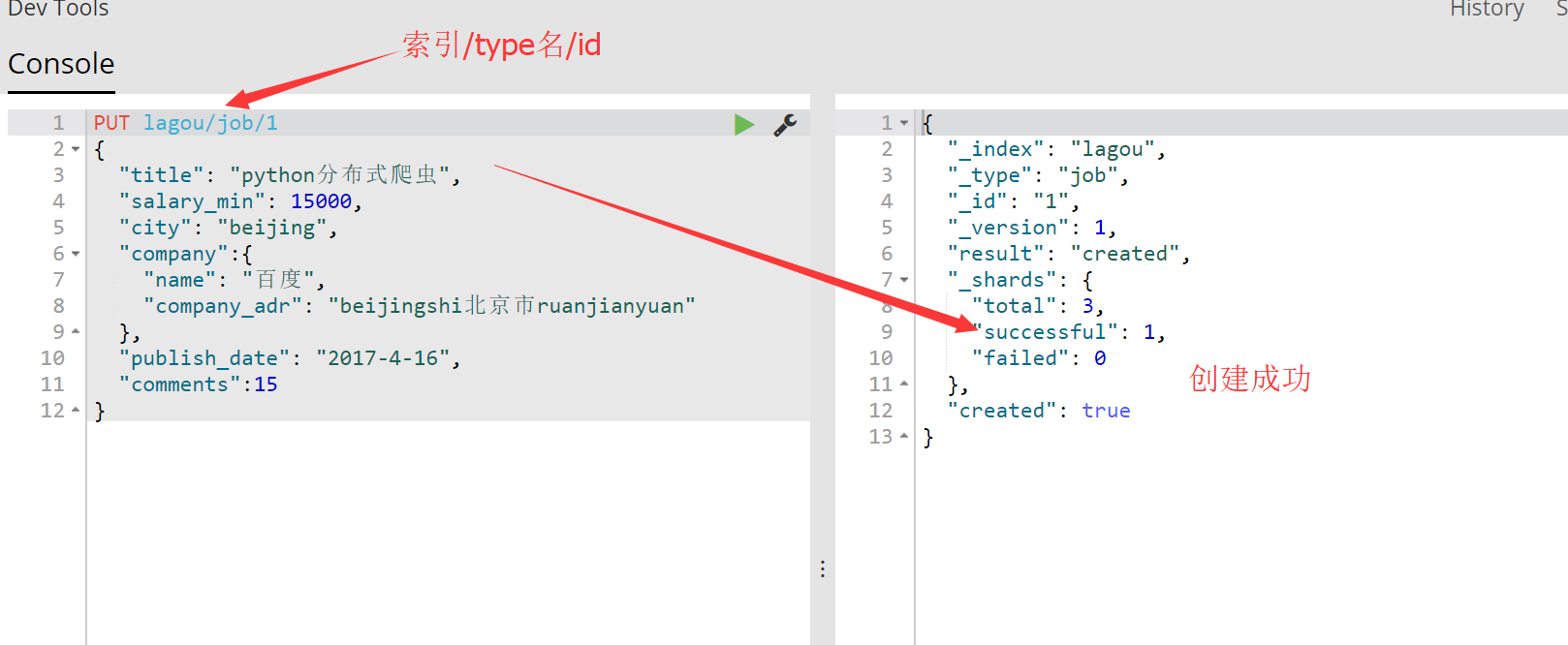
然后去head插件中查看:

我们来修改下地址和城市,结果如下:
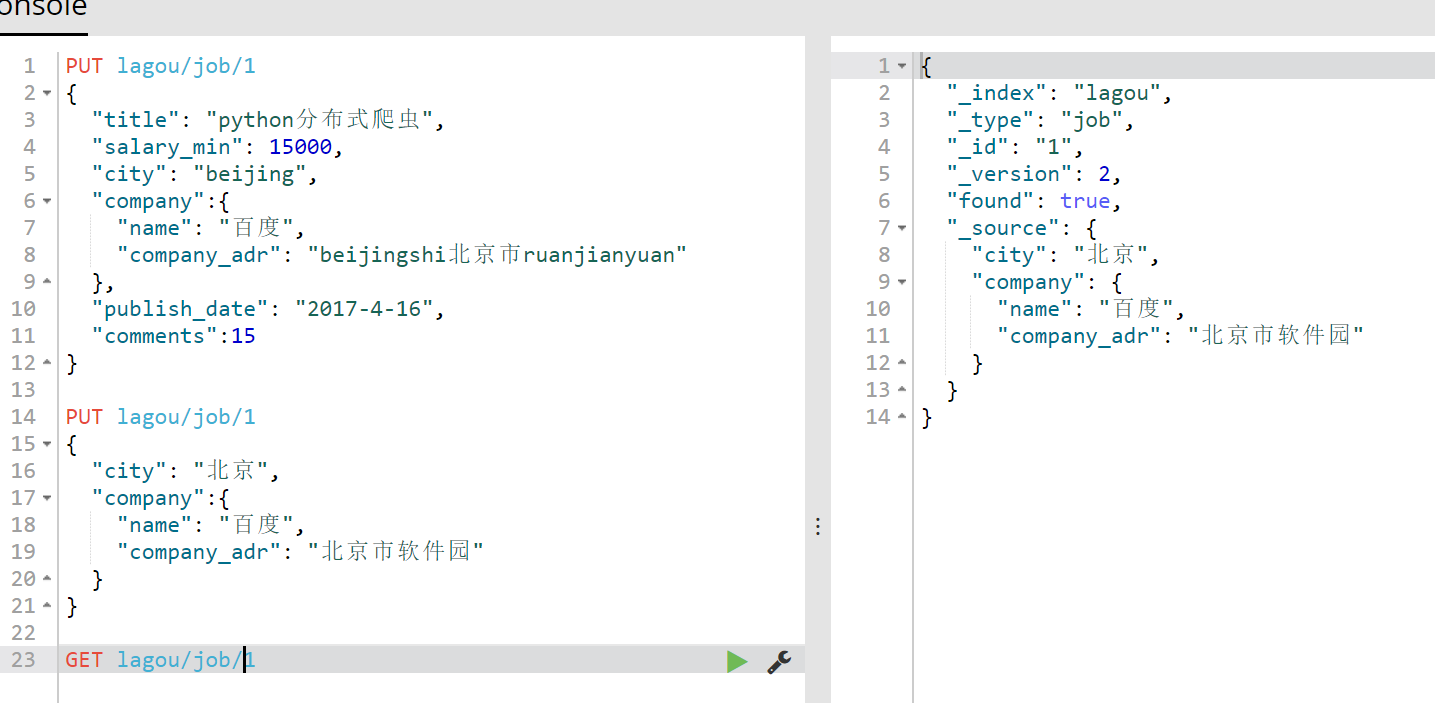
看到没有这里有个小坑,直接像上面那样修改会直接将原始数据的其他字段值全量覆盖,因此要想修改指定字段的值,我们需要在地址栏中指定_update关键字,同时在里面使用doc指定,需要修改哪个字段,相当于就是说需要修改文档中的哪个字段,如下所示:另外还要注意指定ID,表示我修改的是哪个document 。另外要注意修改字段的值使用的是post请求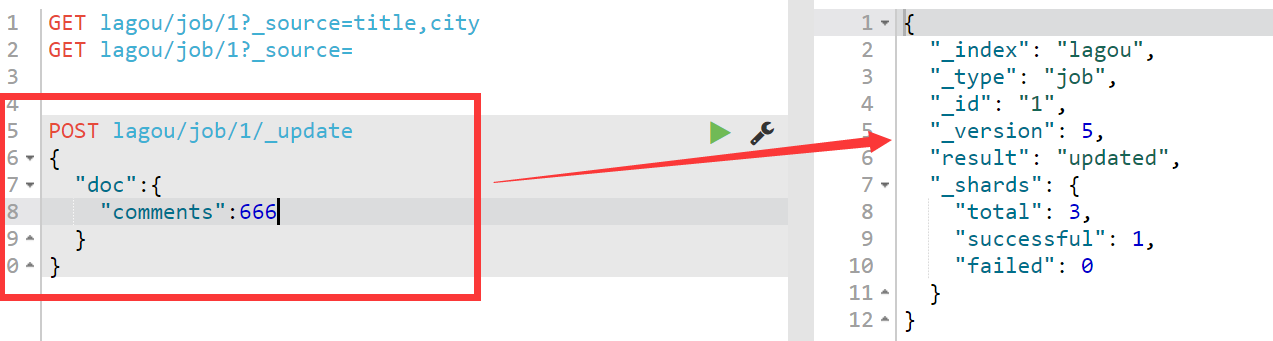
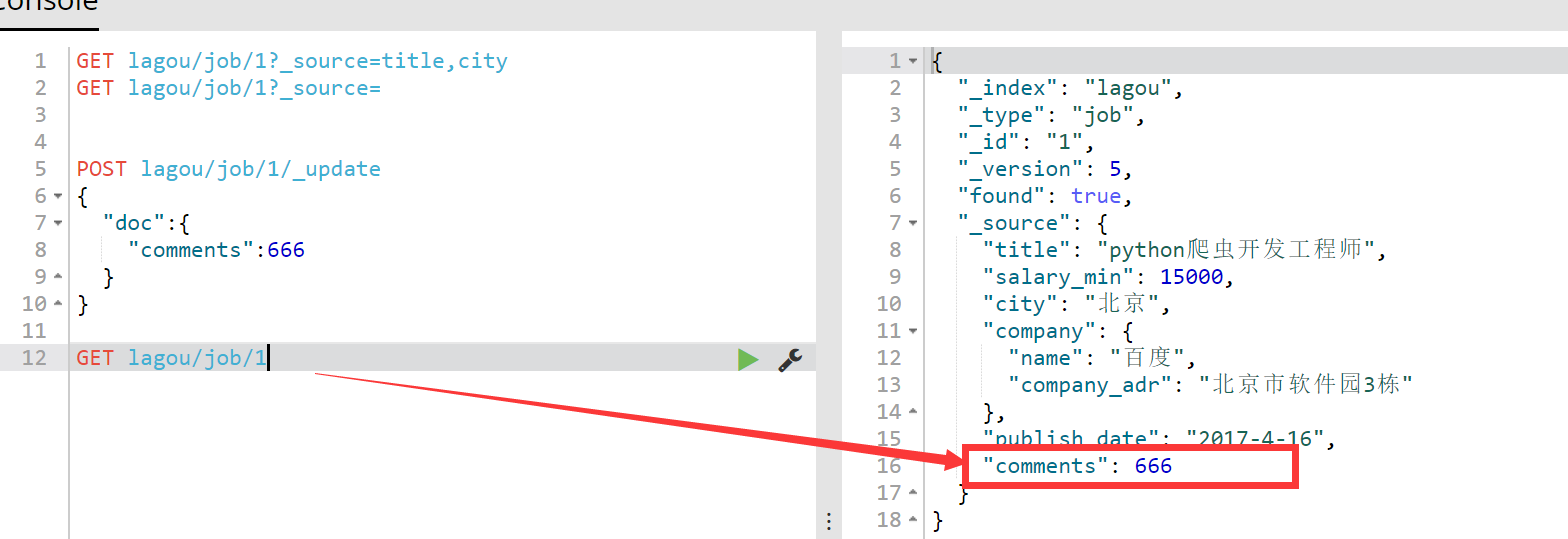
再来查看修改后的结果:
【06】在上面我们创建索引时,指定了doc的ID,但有时候我们需要ES来为我们生成ID,而不是我们自己指定ID,例如我们新增另外一条数据,记住这里使用的是post新增一条数据,而不是put:
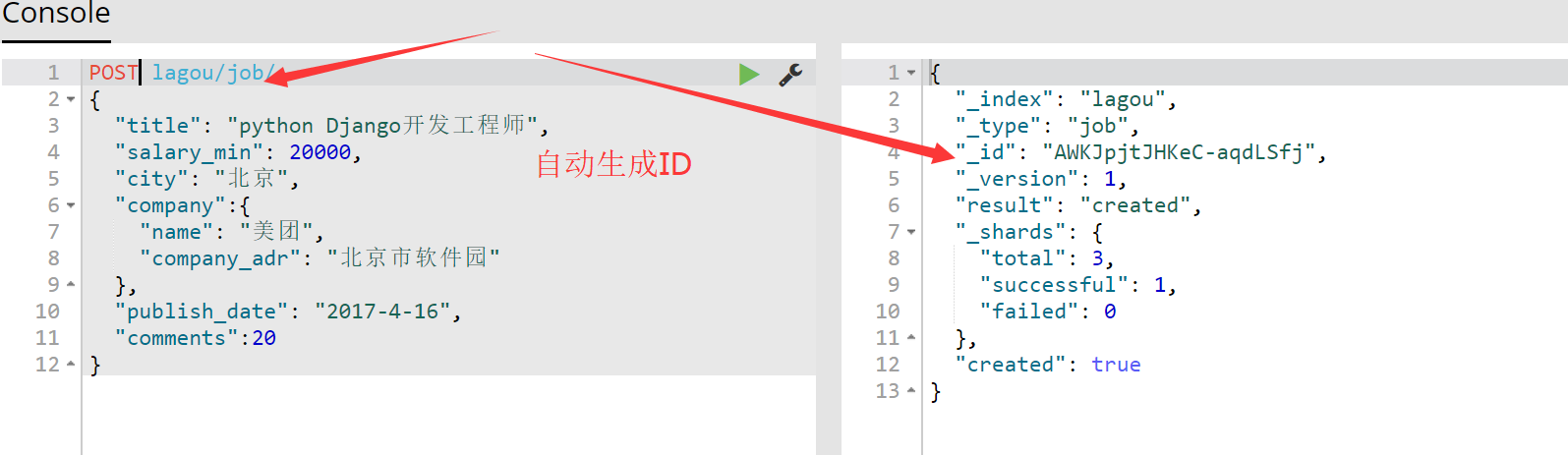
可以看到我们在上面使用了POST新增了一条数据到type中,而且没有指定ID,ES为我们自动生成了ID。再来查看head插件:

【07】获取指定的字段
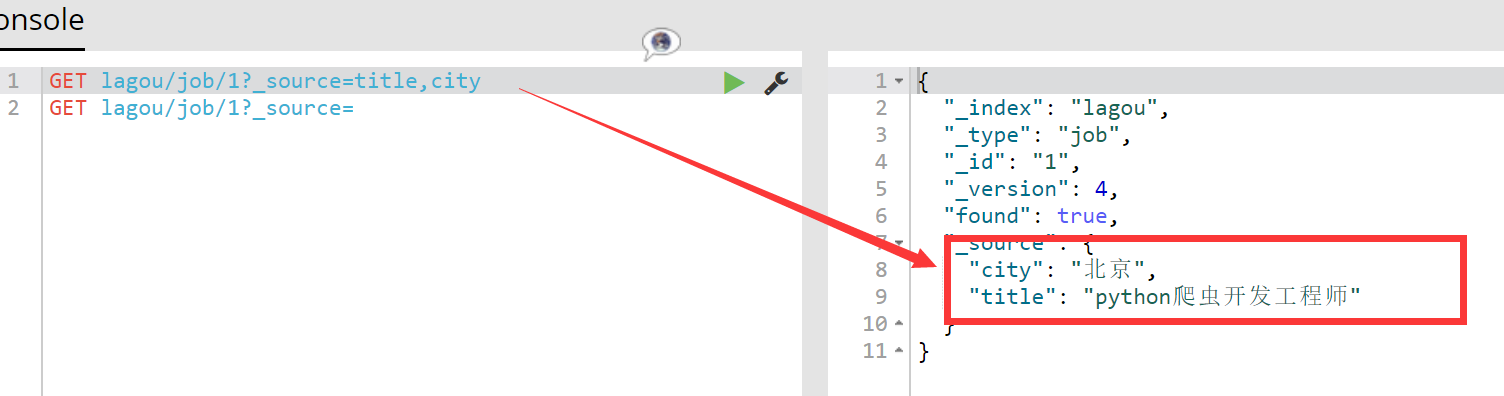
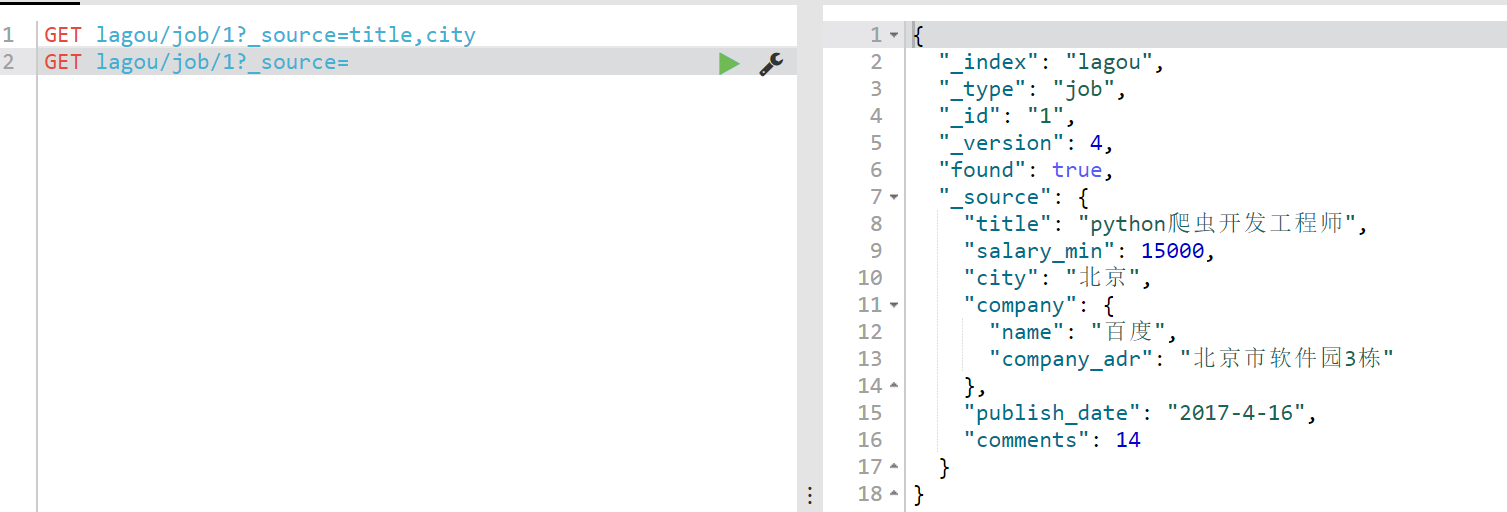
现在我想获取指定的字段,例如title和city:
GET lagou/job/1?_source=title,city
结果如下所示:
【08】删除操作
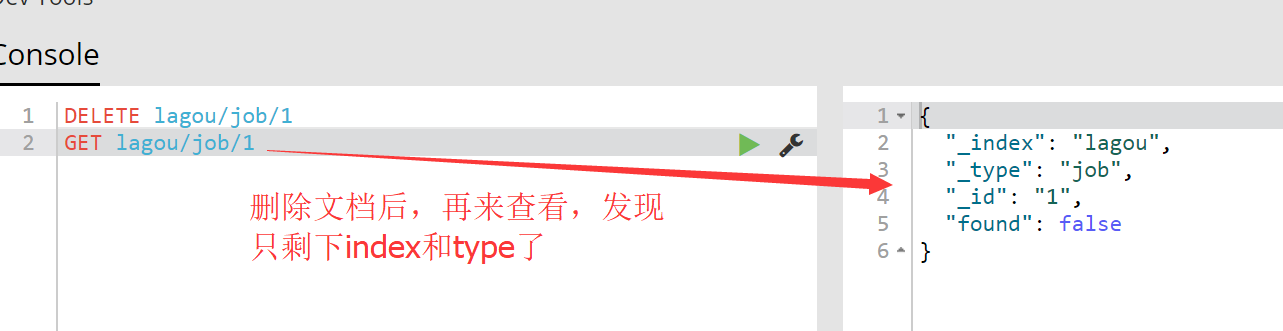
1.删除doc 使用DELETE lagou/job/1表示删除id为1的doc,此时索引index和type,相当于就是删除表中的一条数据
2.删除type ES5报错,说明它不能删除Type:

3.删除索引,可以删除索引:

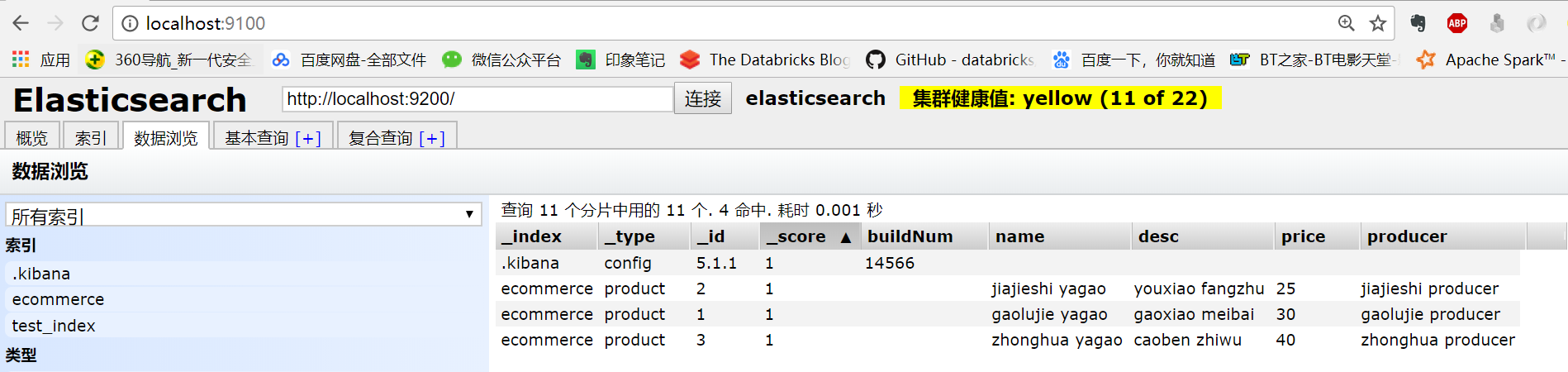
再去head中查看,发现没有了拉钩这个索引:
以上就是关于ES的基本增删改查操作。相关的命令汇总如下:
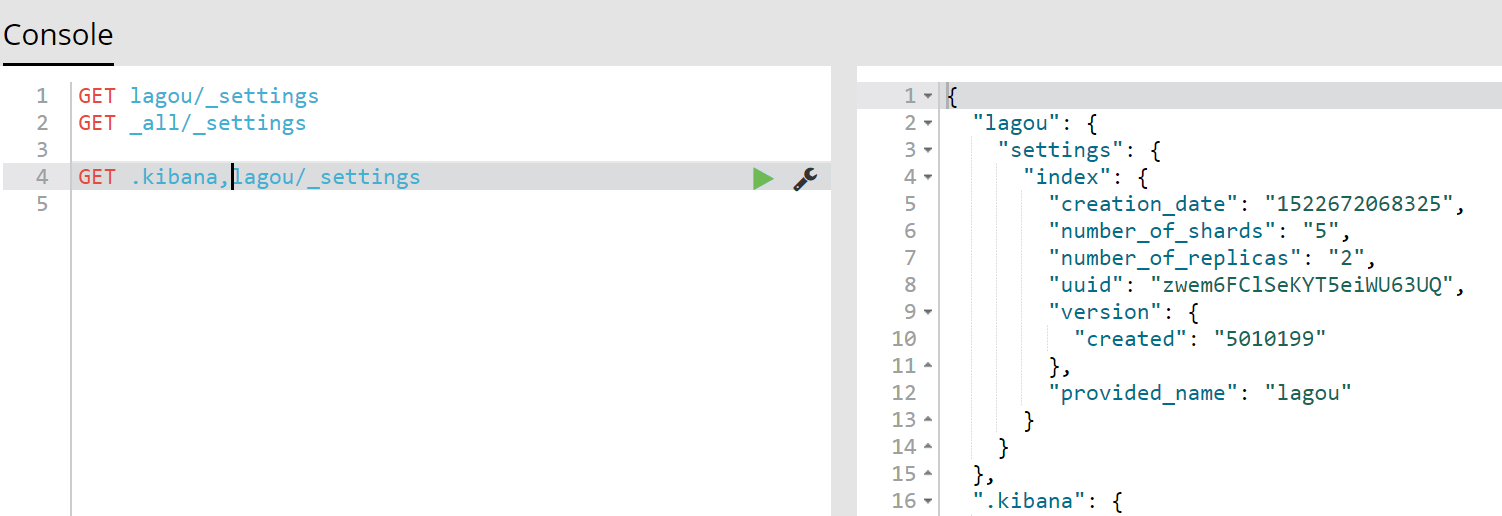
GET lagou/_settings
GET _all/_settings
GET .kibana,lagou/_settings
#
PUT lagou/_settings
{
"number_of_replicas":
}
GET _all
GET lagou POST lagou/job/
{
"title": "python爬虫开发工程师",
"salary_min": ,
"city": "北京",
"company":{
"name": "百度",
"company_adr": "北京市软件园3栋"
},
"publish_date": "2017-4-16",
"comments":
}
POST lagou/job/
{
"title": "python Django开发工程师",
"salary_min": ,
"city": "北京",
"company":{
"name": "美团",
"company_adr": "北京市软件园"
},
"publish_date": "2017-4-16",
"comments":
}
POST lagou/job/
{
"title": "python爬虫开发工程师",
"salary_min": ,
"city": "北京",
"company":{
"name": "百度",
"company_adr": "北京市软件园3栋"
},
"publish_date": "2017-4-16",
"comments":
}
DELETE lagou/job/
GET lagou/job/
ElasticSearch基础+文档CRUD操作的更多相关文章
- Elasticsearch从入门到放弃:文档CRUD要牢记
在Elasticsearch中,文档(document)是所有可搜索数据的最小单位.它被序列化成JSON存储在Elasticsearch中.每个文档都会有一个唯一ID,这个ID你可以自己指定或者交给E ...
- Elasticsearch中最重要的文档CRUD要牢记
Elasticsearch文档CRUD要牢记 转载参考:https://juejin.im/post/5ddbf298e51d4523053c42e7 在Elasticsearch中,文档(docum ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 四十一 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
elasticsearch(搜索引擎)基本的索引和文档CRUD操作 也就是基本的索引和文档.增.删.改.查.操作 注意:以下操作都是在kibana里操作的 elasticsearch(搜索引擎)都是基 ...
- Elasticsearch(5)--- 基本命令(集群相关命令、索引CRUD命令、文档CRUD命令)
Elasticsearch(5)--- 基本命令 这篇博客的命令分为ES集群相关命令,索引CRUD命令,文档CRUD命令.这里不包括Query查询命令,它单独写一篇博客. 一.ES集群相关命令 ES集 ...
- Elasticsearch (1) 文档操作
本文介绍如何在Elasticsearch中对文档进行操作. 1.检查Elasticsearch及Kibana运行是否正常 在浏览器输入192.168.6.16:9200,有如下输出则说明Elastic ...
- 007-elasticsearch5.4.3【一】概述、Elasticsearch 访问方式、Elasticsearch 面向文档、常用概念
一.概述 Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上. Elasticsearch 也是使用 Java 编写的,它的内部使用 L ...
- .Net Api 之如何使用Elasticsearch存储文档
.Net Api 之如何使用Elasticsearch存储文档 什么是Elasticsearch? Elasticsearch 是一个分布式.高扩展.高实时的搜索与数据分析引擎.它能很方便的使大量数据 ...
- MongoDB .Net Driver(C#驱动) - 内嵌数组/嵌入文档的操作(增加、删除、修改、查询(Linq 分页))
目录 一.前言 1. 运行环境 二.前期准备工作 1. 创建 MongoDBContext MongoDb操作上下文类 2.创建测试类 3.创建测试代码 三.内嵌数组增加元素操作 1.Update.S ...
随机推荐
- Windows socket I/O模型 之 select(2)
在Windows socket I/O模型 之 select(1)中.我们仅仅是在console中简单的模拟了select的处理方法. 还有非常多特性不能改动.比方仅仅能写,不能读. 没使用线程.也 ...
- [转] git clone 远程分支
git clone只能clone远程库的master分支,无法clone所有分支,解决办法如下: 找一个干净目录,假设是git_work cd git_work git clone http://my ...
- vim调试
首先,想调试一个程序的话,输入以下命令: guest-djjtew@ubuntu:~$ python3 -m pdb 1.py 这时候就停止了,等待着你的输入,然后输入"l"的话, ...
- canvas 星空插件
(function(a){ a.fn.starBg=function(p){ var p=p||{}; var w_w=p&&p.window_width?p.window_width ...
- caffeModels--models-caffes-大全
caffe的伯克利主页:http://caffe.berkeleyvision.org/caffe的github主页:https://github.com/BVLC/caffe caffe的model ...
- caffe搭建--ubuntu标准平台的搭建
http://caffe.berkeleyvision.org/install_apt.html Ubuntu Installation General dependencies sudo apt-g ...
- centos 6 7 differences 区别
命令 centos6 centos7 ifconfig 有 有 yum install -y net-tools 服务管理 chkconfig /etc/init.d/服务 systemctl sys ...
- listview 下拉刷新
http://blog.csdn.net/lancees/article/details/7776853
- iOS8中提示框的使用UIAlertController(UIAlertView和UIActionSheet二合一)
本文转载至 http://blog.csdn.net/liuwuguigui/article/details/39494597 IOS8UIAlertViewUIActionSheet ...
- cocos2d-js 运行动画
1.添加动画缓存 //添加动画缓存 cc.spriteFrameCache.addSpriteFrames(res.bug_plist); this.spriteSheet = new cc.Spri ...