Django_model基础
Django-model基础
ORM
映射关系:
表名 <-------> 类名
字段 <-------> 属性
表记录 <------->类实例对象
创建表(建立模型)
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
模型建立如下:
class Author(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
age=models.IntegerField() # 与AuthorDetail建立一对一的关系
authorDetail=models.OneToOneField(to="AuthorDetail") class AuthorDetail(models.Model): nid = models.AutoField(primary_key=True)
birthday=models.DateField()
telephone=models.BigIntegerField()
addr=models.CharField( max_length=64) class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
city=models.CharField( max_length=32)
email=models.EmailField() class Book(models.Model): nid = models.AutoField(primary_key=True)
title = models.CharField( max_length=32)
publishDate=models.DateField()
price=models.DecimalField(max_digits=5,decimal_places=2)
keepNum=models.IntegerField()
commentNum=models.IntegerField() # 与Publish建立一对多的关系,外键字段建立在多的一方
publish=models.ForeignKey(to="Publish",to_field="nid") # 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表
authors=models.ManyToManyField(to='Author')
通过logging可以查看翻译成的sql语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
注意事项:
1、 表的名称myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称
2、id 字段是自动添加的
3、对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
4、这个例子中的CREATE TABLE SQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。
5、定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加models.py所在应用的名称。
6、外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
字段选项
每个字段有一些特有的参数,例如,CharField需要max_length参数来指定VARCHAR数据库字段的大小。还有一些适用于所有字段的通用参数。 这些参数在文档中有详细定义,这里我们只简单介绍一些最常用的:
(1)null 如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False. (1)blank 如果为True,该字段允许不填。默认为False。
要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。
如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。 (2)default 字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。 (3)primary_key 如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,
Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,
否则没必要设置任何一个字段的primary_key=True。 (4)unique 如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的 (5)choices
由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,而且这个选择框的选项就是choices 中的选项。 这是一个关于 choices 列表的例子: YEAR_IN_SCHOOL_CHOICES = (
('FR', 'Freshman'),
('SO', 'Sophomore'),
('JR', 'Junior'),
('SR', 'Senior'),
('GR', 'Graduate'),
)
每个元组中的第一个元素,是存储在数据库中的值;第二个元素是在管理界面或 ModelChoiceField 中用作显示的内容。 在一个给定的 model 类的实例中,想得到某个 choices 字段的显示值,就调用 get_FOO_display 方法(这里的 FOO 就是 choices 字段的名称 )。例如: from django.db import models class Person(models.Model):
SHIRT_SIZES = (
('S', 'Small'),
('M', 'Medium'),
('L', 'Large'),
)
name = models.CharField(max_length=60)
shirt_size = models.CharField(max_length=1, choices=SHIRT_SIZES) >>> p = Person(name="Fred Flintstone", shirt_size="L")
>>> p.save()
>>> p.shirt_size
'L'
>>> p.get_shirt_size_display()
'Large'
更多详见模型字段参考
一旦你建立好数据模型之后,django会自动生成一套数据库抽象的API,可以让你执行关于表记录的增删改查的操作。
添加表记录
普通字段
方式1
publish_obj=Publish(name="人民出版社",city="北京",email="renMin@163.com")
publish_obj.save() # 将数据保存到数据库
方式2
返回值publish_obj是添加的记录对象
publish_obj=Publish.objects.create(name="人民出版社",city="北京",email="renMin@163.com") 方式3
表.objects.create(**request.POST.dict())
外键字段
方式1:
publish_obj=Publish.objects.get(nid=1)
Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=665,pageNum=334,publish=publish_obj) 方式2:
Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=665,pageNum=334,publish_id=1)
关键点:book_obj.publish是什么?
多对多字段
book_obj=Book.objects.create(title="追风筝的人",publishDate="2012-11-12",price=69,pageNum=314,publish_id=1) author_yuan=Author.objects.create(name="yuan",age=23,authorDetail_id=1)
author_egon=Author.objects.create(name="egon",age=32,authorDetail_id=2) book_obj.authors.add(author_egon,author_yuan) # 将某个特定的 model 对象添加到被关联对象集合中。 ======= book_obj.authors.add(*[]) book_obj.authors.create() #创建并保存一个新对象,然后将这个对象加被关联对象的集合中,然后返回这个新对象。
关键点:book_obj.authors是什么?
解除关系:
book_obj.authors.remove() # 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[])
book_obj.authors.clear() #清空被关联对象集合。
class RelatedManager
"关联管理器"是在一对多或者多对多的关联上下文中使用的管理器。它存在于下面两种情况:
ForeignKey关系的“另一边”。像这样:
from django.db import models class Reporter(models.Model):
# ...
pass class Article(models.Model):
reporter = models.ForeignKey(Reporter)
在上面的例子中,管理器reporter.article_set拥有下面的方法。
ManyToManyField关系的两边:
class Topping(models.Model):
# ...
pass class Pizza(models.Model):
toppings = models.ManyToManyField(Topping)
这个例子中,topping.pizza_set 和pizza.toppings都拥有下面的方法。
add(obj1[, obj2, ...])
把指定的模型对象添加到关联对象集中。 例如: >>> b = Blog.objects.get(id=1)
>>> e = Entry.objects.get(id=234)
>>> b.entry_set.add(e) # Associates Entry e with Blog b.
在上面的例子中,对于ForeignKey关系,e.save()由关联管理器调用,执行更新操作。然而,在多对多关系中使用add()并不会调用任何 save()方法,而是由QuerySet.bulk_create()创建关系。 延伸: # 1 *[]的使用
>>> book_obj = Book.objects.get(id=1)
>>> author_list = Author.objects.filter(id__gt=2)
>>> book_obj.authors.add(*author_list) # 2 直接绑定主键
book_obj.authors.add(*[1,3]) # 将id=1和id=3的作者对象添加到这本书的作者集合中
# 应用: 添加或者编辑时,提交作者信息时可以用到.
create(**kwargs)
创建一个新的对象,保存对象,并将它添加到关联对象集之中。返回新创建的对象: >>> b = Blog.objects.get(id=1)
>>> e = b.entry_set.create(
... headline='Hello',
... body_text='Hi',
... pub_date=datetime.date(2005, 1, 1)
... ) # No need to call e.save() at this point -- it's already been saved.
这完全等价于(不过更加简洁于): >>> b = Blog.objects.get(id=1)
>>> e = Entry(
... blog=b,
... headline='Hello',
... body_text='Hi',
... pub_date=datetime.date(2005, 1, 1)
... )
>>> e.save(force_insert=True)
要注意我们并不需要指定模型中用于定义关系的关键词参数。在上面的例子中,我们并没有传入blog参数给create()。Django会明白新的 Entry对象blog 应该添加到b中。
remove(obj1[, obj2, ...])
从关联对象集中移除执行的模型对象: >>> b = Blog.objects.get(id=1)
>>> e = Entry.objects.get(id=234)
>>> b.entry_set.remove(e) # Disassociates Entry e from Blog b.
对于ForeignKey对象,这个方法仅在null=True时存在。
clear()
从关联对象集中移除一切对象。 >>> b = Blog.objects.get(id=1)
>>> b.entry_set.clear()
注意这样不会删除对象 —— 只会删除他们之间的关联。 就像 remove() 方法一样,clear()只能在 null=True的ForeignKey上被调用。
set()方法
先清空,在设置,编辑书籍时即可用到
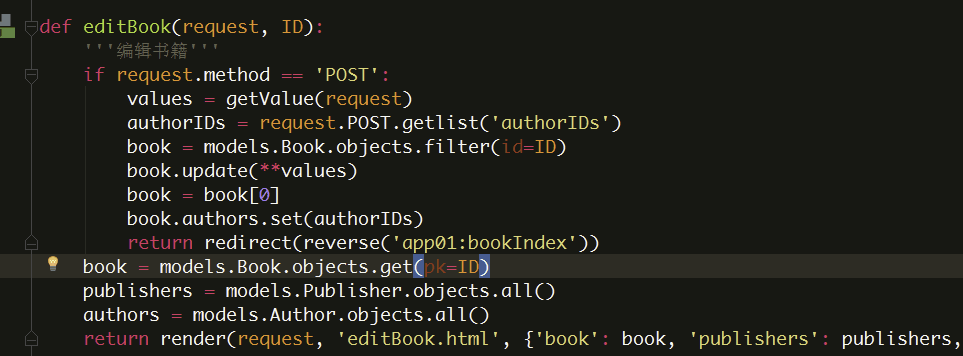
注意
对于所有类型的关联字段,add()、create()、remove()和clear(),set()都会马上更新数据库。换句话说,在关联的任何一端,都不需要再调用save()方法。
直接赋值:
通过赋值一个新的可迭代的对象,关联对象集可以被整体替换掉。
>>> new_list = [obj1, obj2, obj3]
>>> e.related_set = new_list
如果外键关系满足null=True,关联管理器会在添加new_list中的内容之前,首先调用clear()方法来解除关联集中一切已存在对象的关联。否则, new_list中的对象会在已存在的关联的基础上被添加。
查询表记录
查询相关API
<1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误。 <5> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 <4> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列
model的实例化对象,而是一个可迭代的字典序列 <9> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <6> order_by(*field): 对查询结果排序 <7> reverse(): 对查询结果反向排序 <8> distinct(): 从返回结果中剔除重复纪录 <10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <11> first(): 返回第一条记录 <12> last(): 返回最后一条记录 <13> exists(): 如果QuerySet包含数据,就返回True,否则返回False
注意:一定区分object与querySet的区别 !!!
双下划线之单表查询
models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值 models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven")
models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and startswith,istartswith, endswith, iendswith
基于对象的跨表查询
一对多查询(Publish 与 Book)
正向查询(按字段:publish):
# 查询nid=1的书籍的出版社所在的城市
book_obj=Book.objects.get(nid=1)
print(book_obj.publish.city) # book_obj.publish 是nid=1的书籍对象关联的出版社对象
反向查询(按表名:book_set):
# 查询 人民出版社出版过的所有书籍
publish=Publish.objects.get(name="人民出版社")
book_list=publish.book_set.all() # 与人民出版社关联的所有书籍对象集合
for book_obj in book_list:
print(book_obj.title)
一对一查询(Author 与 AuthorDetail)
正向查询(按字段:authorDetail):
# 查询egon作者的手机号
author_egon=Author.objects.get(name="egon")
print(author_egon.authorDetail.telephone)
反向查询(按表名:author):
# 查询所有住址在北京的作者的姓名
authorDetail_list=AuthorDetail.objects.filter(addr="beijing")
for obj in authorDetail_list:
print(obj.author.name)
多对多查询 (Author 与 Book)
正向查询(按字段:authors):
# 金瓶眉所有作者的名字以及手机号
book_obj=Book.objects.filter(title="金瓶眉").first()
authors=book_obj.authors.all()
for author_obj in authors:
print(author_obj.name,author_obj.authorDetail.telephone)
反向查询(按表名:book_set):
# 查询egon出过的所有书籍的名字
author_obj=Author.objects.get(name="egon")
book_list=author_obj.book_set.all() #与egon作者相关的所有书籍
for book_obj in book_list:
print(book_obj.title)
注意:
你可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 FOO_set 的名称。例如,如果 Article model 中做一下更改: publish = ForeignKey(Blog, related_name='bookList'),那么接下来就会如我们看到这般:
# 查询 人民出版社出版过的所有书籍
publish=Publish.objects.get(name="人民出版社")
book_list=publish.bookList.all() # 与人民出版社关联的所有书籍对象集合
基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的 model 为止。
关键点:正向查询按字段,反向查询按表明。
# 练习1: 查询人民出版社出版过的所有书籍的名字与价格(一对多)
# 正向查询 按字段:publish
queryResult=Book.objects
.filter(publish__name="人民出版社")
.values_list("title","price")
# 反向查询 按表名:book
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("book__title","book__price")
# 练习2: 查询egon出过的所有书籍的名字(多对多)
# 正向查询 按字段:authors:
queryResult=Book.objects
.filter(authors__name="yuan")
.values_list("title")
# 反向查询 按表名:book
queryResult=Author.objects
.filter(name="yuan")
.values_list("book__title","book__price")
# 练习3: 查询人民出版社出版过的所有书籍的名字以及作者的姓名
# 正向查询
queryResult=Book.objects
.filter(publish__name="人民出版社")
.values_list("title","authors__name")
# 反向查询
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("book__title","book__authors__age","book__authors__name")
# 练习4: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称
queryResult=Book.objects
.filter(authors__authorDetail__telephone__regex="")
.values_list("title","publish__name")
注意:
反向查询时,如果定义了related_name ,则用related_name替换表名,例如: publish = ForeignKey(Blog, related_name='bookList'):
# 练习1: 查询人民出版社出版过的所有书籍的名字与价格(一对多)
# 反向查询 不再按表名:book,而是related_name:bookList
queryResult=Publish.objects
.filter(name="人民出版社")
.values_list("bookList__title","bookList__price")
聚合查询与分组查询
先了解sql中的聚合与分组概念
聚合:aggregate(*args, **kwargs)
# 计算所有图书的平均价格
>>> from django.db.models import Avg
>>> Book.objects.all().aggregate(Avg('price'))
{'price__avg': 34.35}
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
>>> Book.objects.aggregate(average_price=Avg('price'))
{'average_price': 34.35}
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
>>> from django.db.models import Avg, Max, Min
>>> Book.objects.aggregate(Avg('price'), Max('price'), Min('price'))
{'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}
分组:annotate()
为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。
(1) 练习:统计每一本书的作者个数
bookList=Book.objects.annotate(authorsNum=Count('authors'))
for book_obj in bookList:
print(book_obj.title,book_obj.authorsNum)
SELECT
"app01_book"."nid",
"app01_book"."title",
"app01_book"."publishDate",
"app01_book"."price",
"app01_book"."pageNum",
"app01_book"."publish_id",
COUNT("app01_book_authors"."author_id") AS "authorsNum"
FROM "app01_book" LEFT OUTER JOIN "app01_book_authors"
ON ("app01_book"."nid" = "app01_book_authors"."book_id")
GROUP BY
"app01_book"."nid",
"app01_book"."title",
"app01_book"."publishDate",
"app01_book"."price",
"app01_book"."pageNum",
"app01_book"."publish_id"
sql
解析:
'''
Book.objects.annotate(authorsNum=Count('authors'))
拆分解析:
Book.objects等同于Book.objects.all(),翻译成的sql类似于: select id,name,.. from Book
这样得到的对象一定是每一本书对象,有n本书籍记录,就分n个组,不会有重复对象,每一组再由annotate分组统计。'''
(2) 如果想对所查询对象的关联对象进行聚合:
练习:统计每一个出版社的最便宜的书
publishList=Publish.objects.annotate(MinPrice=Min("book__price"))
for publish_obj in publishList:
print(publish_obj.name,publish_obj.MinPrice)
annotate的返回值是querySet,如果不想遍历对象,可以用上valuelist:
queryResult= Publish.objects
.annotate(MinPrice=Min("book__price"))
.values_list("name","MinPrice")
print(queryResult)
解析同上。
方式2:
queryResult=Book.objects.values("publish__name").annotate(MinPrice=Min('price')) # 思考: if 有一个出版社没有出版过书会怎样?
解析:
'''
查看 Book.objects.values("publish__name")的结果和对应的sql语句
可以理解为values内的字段即group by的字段'''
(3) 统计每一本以py开头的书籍的作者个数:
queryResult=Book.objects
.filter(title__startswith="Py")
.annotate(num_authors=Count('authors'))
(4) 统计不止一个作者的图书:
queryResult=Book.objects
.annotate(num_authors=Count('authors'))
.filter(num_authors__gt=1)
(5) 根据一本图书作者数量的多少对查询集 QuerySet进行排序:
Book.objects.annotate(num_authors=Count('authors')).order_by('num_authors')
(6) 查询各个作者出的书的总价格:
# 按author表的所有字段 group by
queryResult=Author.objects
.annotate(SumPrice=Sum("book__price"))
.values_list("name","SumPrice")
print(queryResult) # 按authors__name group by
queryResult2=Book.objects.values("authors__name")
.annotate(SumPrice=Sum("price"))
.values_list("authors__name","SumPrice")
print(queryResult2)
F查询与Q查询
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
# 查询评论数大于收藏数的书籍
from django.db.models import F
Book.objects.filter(commnetNum__lt=F('keepNum'))
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
# 查询评论数大于收藏数2倍的书籍
Book.objects.filter(commnetNum__lt=F('keepNum')*2)
修改操作也可以使用F函数,比如将每一本书的价格提高30元:
Book.objects.all().update(price=F("price")+30)
Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
from django.db.models import Q
Q(title__startswith='Py')
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
bookList=Book.objects.filter(Q(authors__name="yuan")|Q(authors__name="egon"))
等同于下面的SQL WHERE 子句:
WHERE name ="yuan" OR name ="egon"
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
bookList=Book.objects.filter(Q(authors__name="yuan") & ~Q(publishDate__year=2017)).values_list("title")
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017),
title__icontains="python"
)
修改表记录
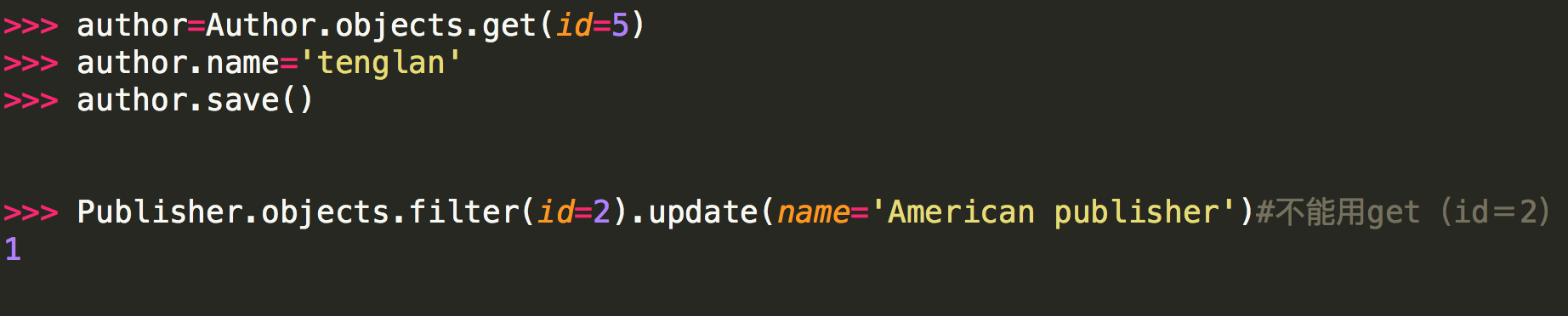
注意:
<1> 第二种方式修改不能用get的原因是:update是QuerySet对象的方法,get返回的是一个model对象,它没有update方法,而filter返回的是一个QuerySet对象(filter里面的条件可能有多个条件符合,比如name='alvin',可能有两个name='alvin'的行数据)。
<2>在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列。
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
注意,这里因为update返回的是一个整形,所以没法用query属性;对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分
删除表记录
删除方法就是 delete()。它运行时立即删除对象而不返回任何值。例如:
e.delete()
你也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。
例如,下面的代码将删除 pub_date 是2005年的 Entry 对象:
Entry.objects.filter(pub_date__year=2005).delete()
要牢记这一点:无论在什么情况下,QuerySet 中的 delete() 方法都只使用一条 SQL 语句一次性删除所有对象,而并不是分别删除每个对象。如果你想使用在 model 中自定义的 delete() 方法,就要自行调用每个对象的delete 方法。(例如,遍历 QuerySet,在每个对象上调用 delete()方法),而不是使用 QuerySet 中的 delete()方法。
在 Django 删除对象时,会模仿 SQL 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如:
b = Blog.objects.get(pk=1)
# This will delete the Blog and all of its Entry objects.
b.delete()
要注意的是: delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用:
Entry.objects.all().delete()
如果不想级联删除,可以设置为:
pubHouse = models.ForeignKey(to='Publisher', on_delete=models.SET_NULL, blank=True, null=True)
Django_model基础的更多相关文章
- python开发之路目录
Python 目录 基础 python入门 python数据类型.字符编码.文件处理 python函数基础 python函数进阶 python装饰器函数 python装饰器函数 python递归函数 ...
- Django Model基础操作
关于设计django model django为我们集成了ORM对数据库进行操作,我们只需要进行定义model,django就会自动为我们创建表,以及表之间的关联关系 创建好一个django项目-首先 ...
- java基础集合经典训练题
第一题:要求产生10个随机的字符串,每一个字符串互相不重复,每一个字符串中组成的字符(a-zA-Z0-9)也不相同,每个字符串长度为10; 分析:*1.看到这个题目,或许你脑海中会想到很多方法,比如判 ...
- node-webkit 环境搭建与基础demo
首先去github上面下载(地址),具体更具自己的系统,我的是windows,这里只给出windows的做法 下载windows x64版本 下载之后解压,得到以下东西 为了方便,我们直接在这个目录中 ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- Golang, 以17个简短代码片段,切底弄懂 channel 基础
(原创出处为本博客:http://www.cnblogs.com/linguanh/) 前序: 因为打算自己搞个基于Golang的IM服务器,所以复习了下之前一直没怎么使用的协程.管道等高并发编程知识 ...
- [C#] C# 基础回顾 - 匿名方法
C# 基础回顾 - 匿名方法 目录 简介 匿名方法的参数使用范围 委托示例 简介 在 C# 2.0 之前的版本中,我们创建委托的唯一形式 -- 命名方法. 而 C# 2.0 -- 引进了匿名方法,在 ...
- HTTPS 互联网世界的安全基础
近一年公司在努力推进全站的 HTTPS 化,作为负责应用系统的我们,在配合这个趋势的过程中,顺便也就想去搞清楚 HTTP 后面的这个 S 到底是个什么含义?有什么作用?带来了哪些影响?毕竟以前也就只是 ...
- Swift与C#的基础语法比较
背景: 这两天不小心看了一下Swift的基础语法,感觉既然看了,还是写一下笔记,留个痕迹~ 总体而言,感觉Swift是一种前后端多种语言混合的产物~~~ 做为一名.NET阵营人士,少少多多总喜欢通过对 ...
随机推荐
- ie下li标签中span加float:right不换行问题解决方案
在IE6,IE7下使用标签时,在加入右浮动样式(float:right)后,会换行的bug解决方案:bug案例:新闻列表中,为使时间右对齐,加右浮动产生换行 <ul> <li> ...
- git 使用及常用命令
git在团队项目中的使用流程 1.首先从一个git远程仓库中clone项目到本地 ? 1 git clone 仓库地址 2.创建开发分支 一般我们写代码不会在master分支上面写,而是新建一个分支 ...
- iOS开发UI篇—懒载入
iOS开发UI篇-懒载入 1.懒载入基本 懒载入--也称为延迟载入,即在须要的时候才载入(效率低,占用内存小).所谓懒载入,写的是其get方法. 注意:假设是懒载入的话则一定要注意先推断是否已经有了. ...
- Android加壳native实现
本例仅在Android2.3模拟器跑通过,假设要适配其它机型.请自行研究,这里不过抛砖引玉. 0x00 在Android中的Apk的加固(加壳)原理解析和实现,一文中脱壳代码都写在了java层非常ea ...
- Sencha touch 初体验
一.什么是Sencha Touch? Sencha Touch是一个应用手持移动设备的前端js框架,与extjs是同一个门派的,它继承了extjs的优点和缺点.功能很强大,效果很炫丽,效率不高. 二. ...
- DataSource是什么
public interface DataSource 该工厂用于提供到此 DataSource 对象表示的物理数据源的连接.作为 DriverManager(二者区别:http://tobylxy. ...
- java多个文件压缩下载
public static void zipFiles(File[] srcfile,ServletOutputStream sos){ byte[] buf=new byte[1024]; try ...
- Qt5的插件机制(6)--开发Qt插件时几个重要的宏
怎样开发Qt插件,能够在Qt Assistant 中搜索"Qt Plugins"或"How to Create Qt Plugins",看看那篇manual中的 ...
- Python生成器定义
通过列表生成式,我们可以直接创建一个列表.但是,受到内存限制,列表容量肯定是有限的.而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素 ...
- 小贝_redis hash类型学习
Redis Hash类型 一.查看hash类型的命令 二.操作hash命令具体解释 一.查看hash类型的命令 1.输入 help@hash 127.0.0.1:6379>help @hash ...