机器学习中的L1、L2正则化
目录
有关机器学习中的L1、L2正则化,有很多的博文都在说这件事情,大致看了相关的几篇博客文章,做下总结供自己学习。当然了,也不敢想象自己能够把相关的知识都搞明白。如果可以的话,按照一个思路能够理解清晰就ok了。
主要通过三个问题来查阅文献,进行学习:
- 什么使正则化,以及有什么作用?
- 什么是L1、L2正则化?
- 机器学习中L1、L2正则化的作用?
1. 什么是正则化?正则化有什么作用?
1.1 什么是正则化?
正则化(regularization):是指在线性代数理论中,不适定问题通常是由一组线性方程定义的,而且这组方程通常来源于有着很大的条件数的不适定反问题;
上面是来自于百度百科-正则化中的解释,完全不懂啊;
那么,通俗地可以理解为:对某一问题加以先验的限制或约束以达到某种特定目的的一种手段或操作;
说白了,正则化是一种手段,那么某种特定的目的又是什么呢?例如:L1可以用于特征选择,L2可以用于防止过拟合。
1.2 正则化有什么作用?
上面已经说了使用正则化其中一个的目的是为了防止模型过拟合,那么就简单介绍以下过拟合。
1.2.1 过拟合
过拟合是指在模型参数拟合过程中的问题,由于训练数据中包含抽样误差,训练时,复杂的模型将抽样误差也考虑在内,对抽样误差也进行了很好的拟合;
直观的表现是:最终的模型在训练集上效果好;在测试集上效果差,即模型泛化能力弱;
常见解决过拟合的方法:
- Early Stopping
- 数据增强
- 正则化
- Dropout(Deep Learning)
1.2.2 正则化用于过拟合
监督学习的问题无非就是minimize your error while regularizing your parameters,也就是在正则化参数的同时最小化误差;最小化误差是为了让我们的模型拟合我们的训练数据,而正则化参数是防止我们的模型过分拟合我们的训练数据;
因为参数太多,会导致我们的模型复杂度上升,容易过拟合,也就是训练误差会很小。但训练误差小并不是我们的最终目标,我们的目标是希望模型的测试误差小,也就是能够准确的预测新的样本。所以,我们需要保证模型“简单“的基础上最小化训练误差,这样得到的模型参数也具有好的泛化能力。而使模型”简单“就是通过正则化来实现的。
2. L1,L2正则化?
2.1 L1、L2范数
范数使衡量某个向量空间中的每个向量的长度或大小;
\[
||x||_p := (\sum_{i=1}^{n}|x_i|^p)^{\dfrac{1}{p}}
\]
L1范数:
当\(p=1\)时,即向量中所有元素绝对值的和;
\[
||x||_1=\sum_{i=1}^{n}|x_i|
\]
L2范数:
当\(p=2\)时,即向量中所有元素平方和再开平方,即欧几里得距离;
\[
||x||_2 = (\sum_{i=1}^{n}x_i^2)^{\dfrac{1}{2}}
\]
2.2 监督学习中的L1、L2正则化
一般说,监督学习可以看做是最小化下面的目标函数,即:
\[
arg \ \mathop{min}\limits_{x} \sum_{i}L(y_i, f(x_i;w)) + \lambda \Omega(w)
\]
其中,第一项\(L(y_i, f(x_i;w))\)用于衡量第\(i\)个样本的预测值\(f(x_i;w)\)和真实标签\(y_i\)之间的误差;也就是要求在训练集上的误差最小,尽量拟合训练数据;同时,第二项\(\Omega(w)\)表示对参数正则化,用于约束模型,使其尽量的简单;
那么L1、L2怎么用到上面的目标函数中呢?即:
L1正则化:
\[
arg \ \mathop{min}\limits_{x} \sum_{i}L(y_i, f(x_i;w)) + \lambda ||w||_1
\]
L2正则化:
\[
arg \ \mathop{min}\limits_{x} \sum_{i}L(y_i, f(x_i;w)) + \lambda ||w||_2^2
\]
3. L1、L2正则化的作用
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择;
- L2正则化可以防止模型过拟合;一定程度上,L1也可以防止过拟合;
3.1 稀疏模型与特征选择——L1
上面提到L1有助于生成一个稀疏权值矩阵,进而用于特征选择,为什么要生成稀疏矩阵呢?
稀疏矩阵指的使很多元素为0,只有少数元素是非零值的矩阵;
通常机器学习中特征数量有很多;那么在预测或分类时,太多的特征显然难以选择,但是如果将这些特征输入到模型中,得到的模型是一个稀疏模型,即表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献或贡献很小,此时就可以只关注系数是非零值的特征;这就是稀疏模型与特征选择;
3.2 L1的直观理解
上一小节中提到稀疏模型与特征选择的关系,以及提到L1正则化有助于得到稀疏模型,下面就来说说L1正则化与它们之间的关系;
假设带有L1正则化的目标函数:
\[
J = J_0 + \lambda \sum_{w}|w|
\]
其中,第一项\(J_0\)表示为原目标,第二项\(\sum_{w}|w|\)表示L1正则化项,\(\lambda\)表示正则化系数;
机器学习的任务就是通过一些方法(如梯度下降)求出目标函数的最小值;当在原目标函数\(J_0\)后添加L1正则化项时,就相当于对\(J_0\)做了一个约束;
令\(L=\lambda\sum_{w}|w|\),则\(J=J_0+L\);此时任务变成在L约束条件下求出\(J_0\)的最小值的解;
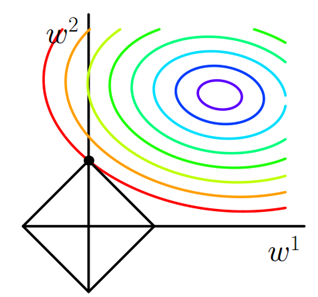
其中,在\(w_1, w_2\)的二维平面上作图,彩色等值线表示\(J_0\)的取值,中心代表\(J_0\)的最小值,黑色方框表示L的图形;
图中\(J_0\)等值线与L首次相交的地方就是最优解。即图像的\((w_1, w_2)=(0,w)\);
可以想象,因为L函数有很多『突出的角』(二维情况下四个,多维情况下更多),\(J_0\)与这些角接触的几率远大于与L其他部位接触的几率,而在这些角上,会有很多的权值等于0,这就是为什么正则化可以产生稀疏模型,进而用于特征选择;因为含有L1正则化项的目标函数的最优解中,有很多参数的值都为0,即得到稀疏模型;
同理,假设带有L2正则化项的目标函数为:
\[
J = J_0 + \lambda \sum_{w}w^2
\]
\(w_1, w_2\)二维平面下L2正则化项函数图形是一个圆,与方形相比,被磨去了棱角。在取得最优解的时候,模型中参数为0的几率小了很多,即得到的模型不容易是稀疏模型;
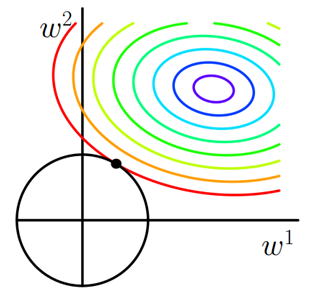
有关为什么要以图中彩色椭圆表示原目标函数的等值线?
图中只是无数种情况中的一种,这是因为原目标函数\(J_0\)是关于参数\(w_0, w_1,\cdots, w_n\)的函数,因此关于\(J_0\)的最优解可能位于坐标空间中的任意位置,不管在哪里,其等值线都是以最小值点发散开;
其他有关L1、L2的直观理解的博文,可以参考:【通俗易懂】机器学习中 L1 和 L2 正则化的直观解释
3.3 L2正则化
机器学习中模型的拟合过程都倾向于让权重尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型简单,具有良好的泛化能力。可以设想一下,如果权值较大时,当数据偏移一点点,就会对结果造成很大的影响;
3.3.1 L2正则化如何获得较小的参数?
以线性回归来举例,假设我们有目标函数:
\[
J(\theta) = \dfrac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^i)-y^i)^2
\]
使用梯度下降算法,对\(\theta\)求导,得到梯度;而梯度本身是上升最快的方向,为了使损失尽可能小,沿着梯度负方向更新参数;
以参数\(\theta_j\)举例,对其更新,得到:
\[
\theta_j := \theta_j-\alpha\dfrac{1}{m}[\sum_{i=1}^{m}(h_{\theta}(x^i)-y^i)x_j^i]
\]
其中,\(\alpha\)为学习率;
加入L2正则化项后,目标函数为:
\[
J(\theta) = \dfrac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^i)-y^i)^2 + \lambda\dfrac{1}{2m}\sum_{i=1}^{m}\theta_j^2
\]
以参数\(\theta_j\)举例,对其更新,得到:
\[
\theta_j := \theta_j(1-\alpha\dfrac{\lambda}{m})-\alpha\dfrac{1}{m}[\sum_{i=1}^{m}(h_{\theta}(x^i)-y^i)x_j^i]
\]
对比公式(10)、(12),可以发现,添加L2正则化项后,每一次更新\(\theta_j\)都需要先乘\((1-\alpha\dfrac{\lambda}{m}) < 1\)的因子,从而使得每次更新后,\(\theta_j\)减小的幅度更大;最终得到的\(\theta\)更小;
有关线性回归的梯度下降见:Machine Learning-线性回归
4. 如何选择正则化参数?
在目标函数中:
\[
arg \ \mathop{min}\limits_{x} \sum_{i}L(y_i, f(x_i;w)) + \lambda \Omega(w)
\]
发现除了loss和正则化项两部分外,还有一个正则化参数\(\lambda\);它的作用使为了平衡loss和正则化项,它的取值影响着模型的性能;\(\lambda\)越大,则表示越重视正则化项,\(\lambda\)越小,则表示越重视loss项;
那么该如何选择正则化参数\(\lambda\)的大小呢?
借鉴zouxy09-机器学习中的范数规则化之(二)核范数与规则项参数选择
- 尝试很多的经验值;
- 使用交叉验证;即使用不同\(\lambda\)训练多个模型,并验证不同模型在测试集上的效果;
结束!!!
博主个人网站:https://chenzhen.online
Reference
机器学习中的L1、L2正则化的更多相关文章
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- 防止过拟合:L1/L2正则化
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- L0,L1,L2正则化浅析
在机器学习的概念中,我们经常听到L0,L1,L2正则化,本文对这几种正则化做简单总结. 1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数 ...
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- L1,L2正则化代码
# L1正则 import numpy as np from sklearn.linear_model import Lasso from sklearn.linear_model import SG ...
- 机器学习中模型泛化能力和过拟合现象(overfitting)的矛盾、以及其主要缓解方法正则化技术原理初探
1. 偏差与方差 - 机器学习算法泛化性能分析 在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去 ...
- L1和L2正则化(转载)
[深度学习]L1正则化和L2正则化 在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况 ...
- Kaldi中的L2正则化
steps/nnet3/train_dnn.py --l2-regularize-factor 影响模型参数的l2正则化强度的因子.要进行l2正则化,主要方法是在配置文件中使用'l2-regulari ...
- 阅读ARM Memory(L1/L2/MMU)笔记
<ARM Architecture Reference Manual ARMv8-A>里面有Memory层级框架图,从中可以看出L1.L2.DRAM.Disk.MMU之间的关系,以及他们在 ...
随机推荐
- Java集合(一):Java集合概述
注:本文基于JDK 1.7 1 概述 Java提供了一个丰富的集合框架,这个集合框架包括了很多接口.虚拟类和实现类. 这些接口和类提供了丰富的功能.可以满足主要的聚合需求. 下图就是这个框架的总体结构 ...
- Hadoop基础学习(一)分析、编写并执行WordCount词频统计程序
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/jiq408694711/article/details/34181439 前面已经在我的Ubuntu ...
- iOS Dev (53) 修复UIImagePickerController偷换StatusBar颜色的问题
版权声明:本文为 CSDN 博主 大锐哥(ID 为 prevention)原创文章,未经博主同意不得转载. https://blog.csdn.net/prevention/article/detai ...
- Halcon下载、安装
下载地址: 官网:http://www.halcon.com/halcon/download/ Halcon学习网:http://www.ihalcon.com/read.php?tid=56 { 最 ...
- 【Leetcode-easy】Longest Common Prefix
思路:每次从字符数组中读取两个字符串比较.需要注意输入字符串为空,等细节. public String longestCommonPrefix(String[] strs) { if(strs==nu ...
- Matlab图像处理(02)-图像基础
数据类 Matlab中和IPT中支持的基本数据类型如下: 名称 描述 double 双精度浮点数,范围-10308~10308 8字节 uint8 无符号1字节整数,范围[0, 255] uint1 ...
- 获取HDC的几种方法
当需要在显示器上(当然包括打印机等设备上)绘图时,或者写文字的时候,需要取得设备的上下文句柄,即HDC,本文以下都称为HDC.那么,有哪些办法取得HDC呢? 1 BeginPain()和EndPain ...
- BZOJ 1726 [Usaco2006 Nov]Roadblocks第二短路:双向spfa【次短路】
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=1726 题意: 给你一个无向图,求次短路. 题解: 两种方法. 方法一: 一遍spfa,在s ...
- db2move 数据导出整理
db2move <database-name> <action> [<option> <value>] 命令解释:1).database-name, ...
- JavaMail API的应用
JavaMail API 是一个用于阅读.编写和发送电子消息的可选包(标准扩展),用来创建邮件用户代理(Mail User Agent,MUA)类型程序. JavaMail API 需要 JavaBe ...