scrapy爬取数据的基本流程及url地址拼接
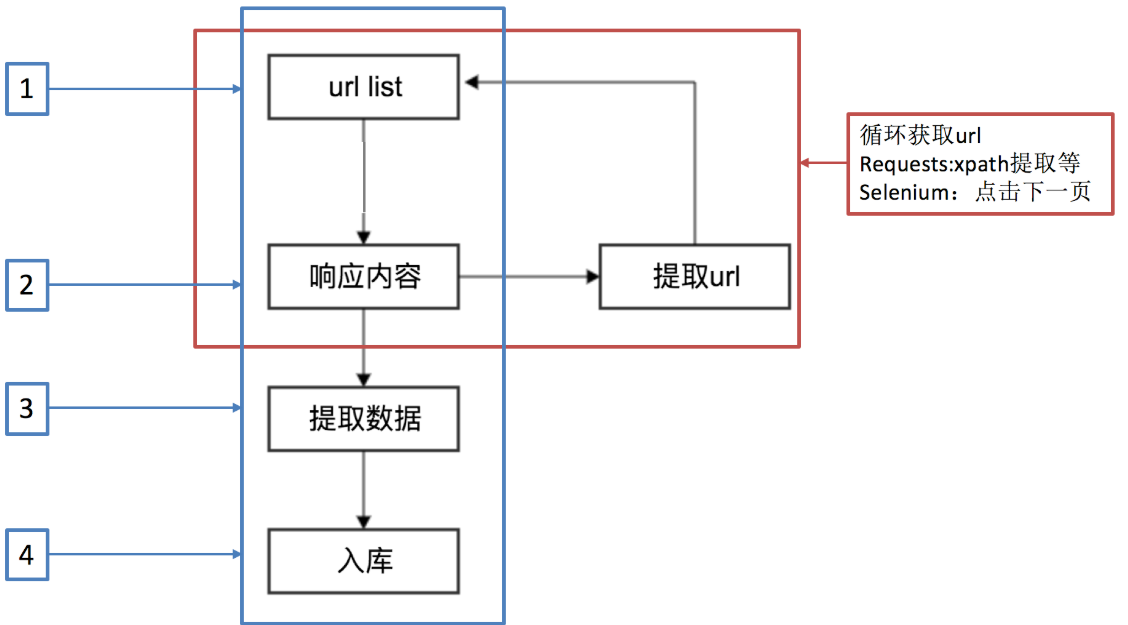
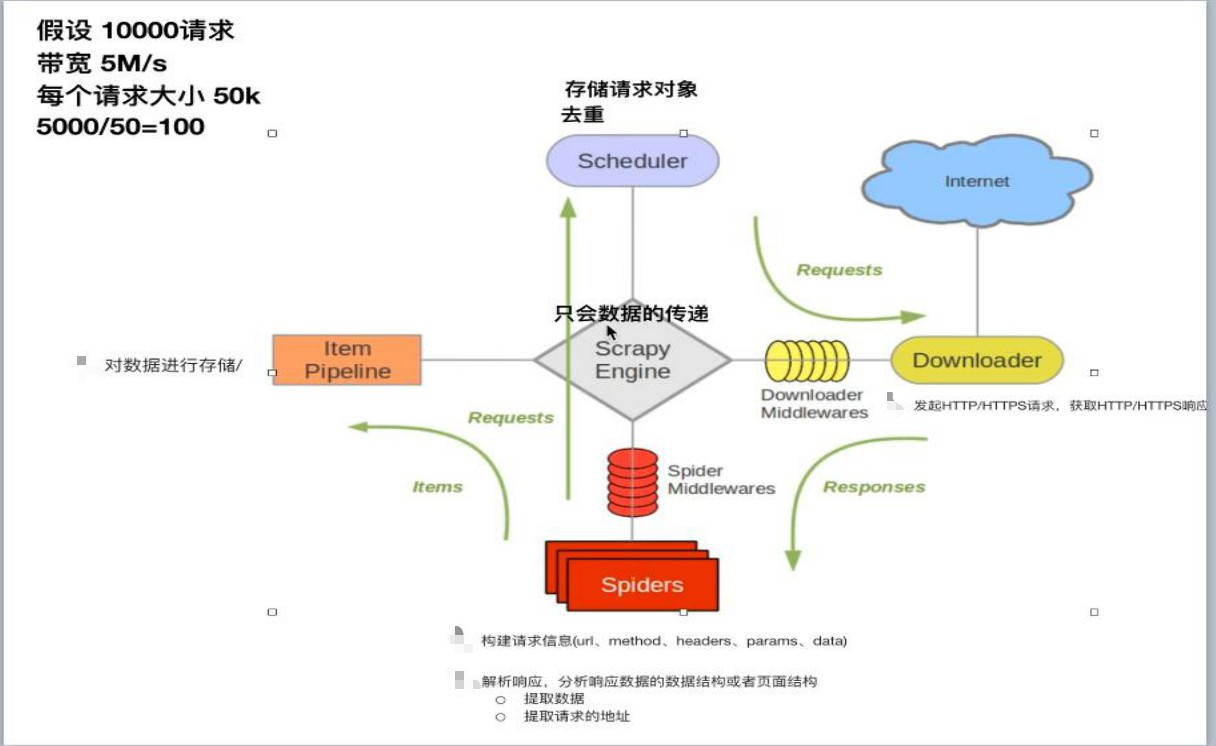
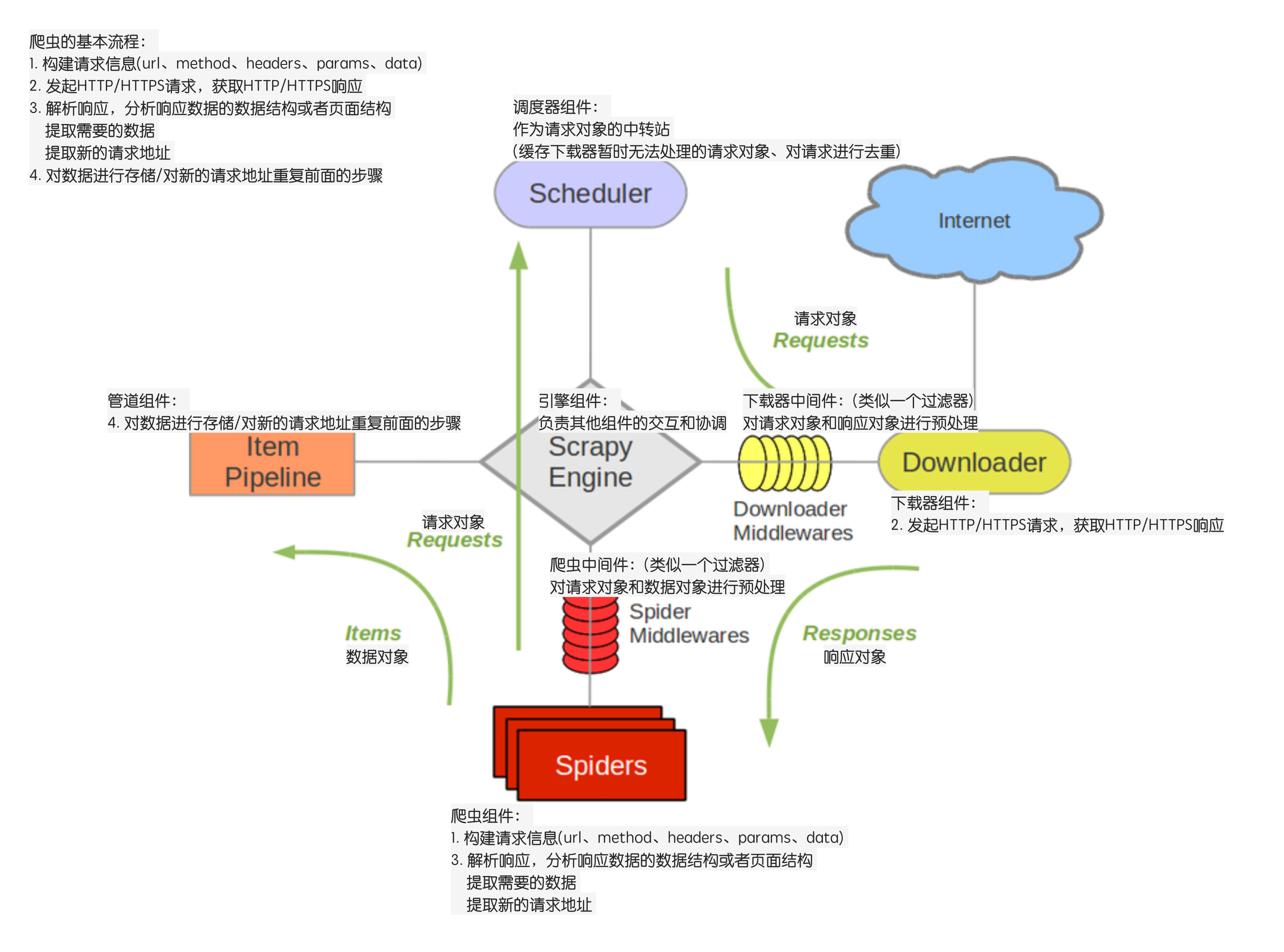


上面的代码应该改成:yield item
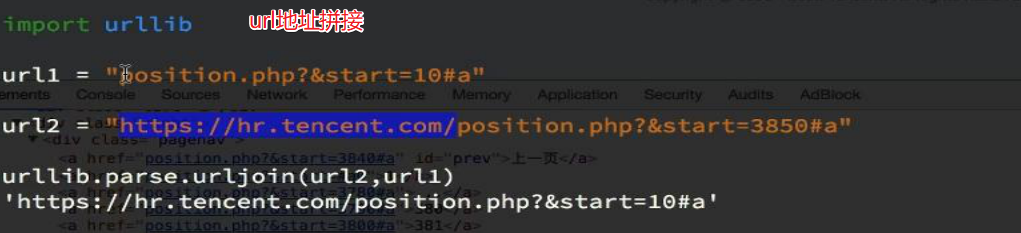
#主站链接 用来拼接
base_site = 'https://www.jpdd.com' def parse(self,response):
book_urls = response.xpath('//table[@class="p-list"]//a/@href').extract() for book_url in book_urls:
url = self.base_site + book_url
yield scrapy.Request(url, callback=self.getInfo) #获取下一页
next_page_url = self.base_site + response.xpath(
'//table[@class="p-name"]//a[contains(text(),"下一页")]/@href'
).extract()[0] yield scrapy.Request(next_page_url, callback=self.parse)
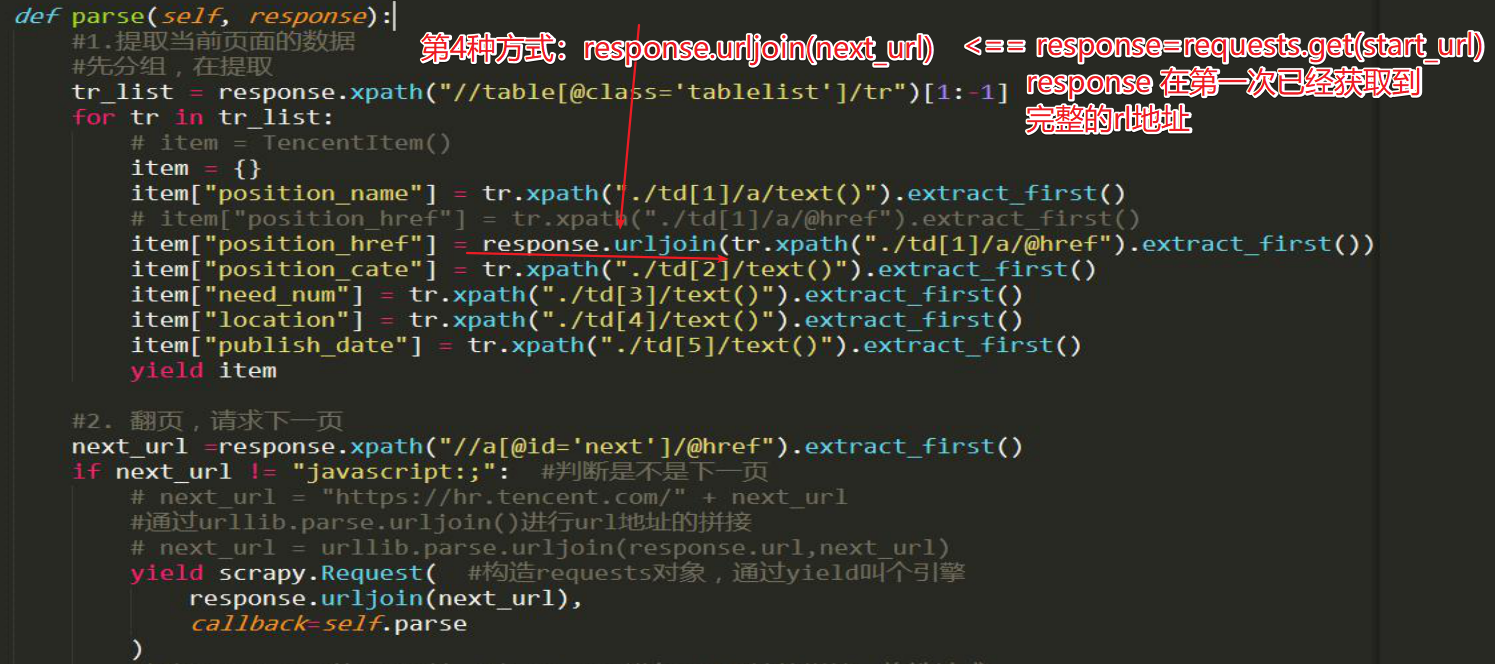
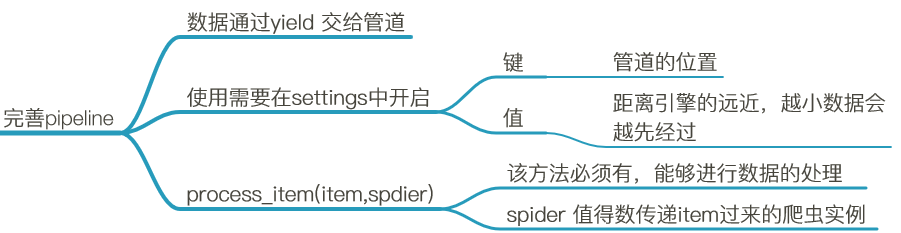


------数字越小,表示离引擎越近,数据越先经过处理,反之 。
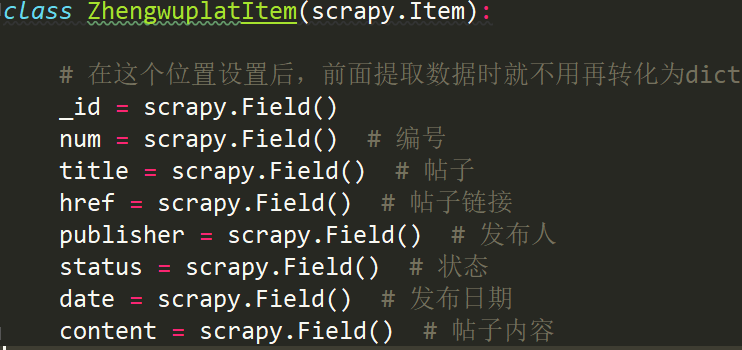
from yanguan.items import YanguanItem
item = YanguanItem() #实例化
参数说明:
括号中的参数为可选参数
callback:表示当前的url的响应交给哪个函数去处理
meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
dont_filter:默认会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
scrapy爬取数据的基本流程及url地址拼接的更多相关文章
- 如何提升scrapy爬取数据的效率
在配置文件中修改相关参数: 增加并发 默认的scrapy开启的并发线程为32个,可以适当的进行增加,再配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100. ...
- 将scrapy爬取数据通过django入到SQLite数据库
1. 在django项目根目录位置创建scrapy项目,django_12是django项目,ABCkg是scrapy爬虫项目,app1是django的子应用 2.在Scrapy的settings.p ...
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
- 42.scrapy爬取数据入库mongodb
scrapy爬虫采集数据存入mongodb采集效果如图: 1.首先开启服务切换到mongodb的bin目录下 命令:mongod --dbpath e:\data\db 另开黑窗口 命令:mongo. ...
- scrapy爬取数据进行数据库存储和本地存储
今天记录下scrapy将数据存储到本地和数据库中,不是不会写,因为小编每次都写觉得都一样,所以记录下,以后直接用就可以了-^o^- 1.本地存储 设置pipel ines.py class Ak17P ...
- scrapy爬取数据保存csv、mysql、mongodb、json
目录 前言 Items Pipelines 前言 用Scrapy进行数据的保存进行一个常用的方法进行解析 Items item 是我们保存数据的容器,其类似于 python 中的字典.使用 item ...
- Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架 Scrapy是python下实现爬虫功能的框架,能够将数据解析.数据处理.数据存储合为一体功能的爬虫框架. 2. Scrapy安装 1. 安装依赖包 yum install g ...
- 爬虫必知必会(6)_提升scrapy框架爬取数据的效率之配置篇
如何提升scrapy爬取数据的效率:只需要将如下五个步骤配置在配置文件中即可 增加并发:默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_ ...
- 提高Scrapy爬取效率
1.增加并发: 默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100. 2.降低 ...
随机推荐
- PAT 甲级 1104. Sum of Number Segments (20) 【数学】
题目链接 https://www.patest.cn/contests/pat-a-practise/1104 思路 最容易想到的一个思路就是 遍历一下所有组合 加一遍 但 时间复杂度 太大 会超时 ...
- css浏览器兼容问题集锦
表单按钮用input type=submit和a链接两者表现不一致的问题 表单的输入框.文本.验证码图片没有对齐 IE6/7中margin失效 IE6中margin双边距 1.问题: 表单按钮用inp ...
- SQLSERVER安装记录
很多人都喜欢重装编程环境,VS,SQL是最常见的 尤其是SQL,在删除所有的SQL相关的组件之后(360),记得再次打开控制面板,查看是否有漏掉的,本人就有一个SQLXML没有删除掉 在删除之后,清理 ...
- 通道(Channel)的原理获取
通道表示打开到 IO 设备(例如:文件.套接字)的连接.若需要使用 NIO 系统,需要获取用于连接 IO 设备的通道以及用于容纳数据的缓冲区.然后操作缓冲区,对数据进行处理.Channel 负责传输, ...
- RQNOJ 311 [NOIP2000]乘积最大:划分型dp
题目链接:https://www.rqnoj.cn/problem/311 题意: 给你一个长度为n的数字,用t个乘号分开,问你分开后乘积最大为多少.(6<=n<=40,1<=k&l ...
- 修改ubuntu14.04命令行启动
方法1: 原来要想默认不进入xwindows,只需编辑文件”/etc/default/grub”, 把 GRUB_CMDLINE_LINUX_DEFAULT=”quiet splash” 改成GRUB ...
- CI框架上传csv文件
今天遇到在用CI框架上传csv文件时报错问题: The filetype you are attempting to upload is not allowed. 是类型不允许,想到CI框架的conf ...
- swoole_table
Memory Swoole提供了7个内存操作的模块,在多进程编程中可以帮助开发者实现一些特殊的需求. swoole_table 是基于共享内存和锁实现的超高性能,并发数据结构
- 通过在classpath自动扫描方式把组件纳入spring容器中管理。
前面的例子我们都是使用xml的bean定义来配置组件,如果组件过多很臃肿.spring2.5引入了组件自动扫描机制,在指定目录下查找标注了@Component.@Service.@Controller ...
- java面试题09
A卷 1.选择题 public class Test01 { public static void changeStr(String str) { str = "welcome"; ...