python cookbook第三版学习笔记七:python解析csv,json,xml文件
CSV文件读取:
Csv文件格式如下:分别有2行三列。

访问代码如下:
f=open(r'E:\py_prj\test.csv','rb')
f_csv=csv.reader(f)
for f in f_csv:
print f
在这里f是一个元组,为了访问某个字段,需要用索引来访问对应的值,如f[0]访问的是first,f[1]访问的是second,f[2]访问的是third. 用列索引的方式很难记住。一不留神就会搞错。可以考虑用对元组命名的方式
这里介绍namedtuple的方法。
下面的例子中实现用namedtuple创建一个对象赋值给user。其中对象实例是user,包含了3个属性值,分别是name,age,height。通过赋值后得到u
就可以利用属性访问的方法u.name来访问各个属性
user=namedtuple('user',['name','age','height'])
u=user(name='zhf',age=20,height=180)
print u.name
这种方法也可以用到csv文件的读取上。代码修改如下
f=open(r'E:\py_prj\test.csv','rb')
f_csv=csv.reader(f)
heading=next(f_csv)
Row=namedtuple('Row',heading)
for row in f_csv:
row=Row(*row)
print row.first,row.second,row.third
这样访问起来就直观多了。那么用对象的方式看起来太复杂了点。可以用字典的方式么。也是可以的而且方法更加简洁。方法如下。
f=open(r'E:\py_prj\test.csv','rb')
f_csv=csv.DictReader(f)
for row in f_csv:
print row['first']
同样的写入也可以用csv.DictWriter()
Json数据:
Json和xml是网络世界上用的最多的数据交换格式。Json主要有以下特点:
1 对象表示为键值对,也就是字典的形式
2 数据又逗号分隔
3 花括号保存对象
4 方括号保存数组
操作json文件的方法如下:
data={'name':'zhf','age':30,'location':'china'}
f=open('test.json','w')
json.dump(data,f)
f=open('test.json','r')
print json.load(f)
在生成的json文件中格式如下:

可以看到json的这种键值结构在感官上比XML的结构要简单得多,也更一目了然。
我们还可以对json进行扩展。如下面的数据。在record的键值里面是一个数组,数组里面有2个字典数据
data={'name':'zhf','age':30,'location':'china','record':[{'first':'china','during':10},{'second':'chengdu','during':20}]}
可以看到json可以存储复杂的数据结构。当我们打印出来的时候。可以看到结构的可视化结果不怎么好。

我们可以用pprint的方法将结果打印出结构化的样子:pprint(json.load(f))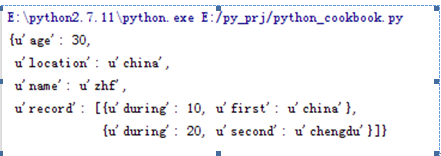
这样看起来就清晰直观多了
解析XML文件:
XML(eXtensible Markup Language)指可扩展标记语言,被设计用来传输和存储数据。XML和JSON两种文件格式是互联网上应用得最多的数据传输格式。Python解析XML有三种方法:一是xml.dom.*模块。二是xml.sax.*模块 三是xml.etree.ElementTree模块
首先介绍dom模块。一个DOM的解析器在解析一个XML文档的时候。一次性读取整个文档。把文档中的所有元素保存在内存中的一个树结构中。 可以看到这种方式比较适用于解析数据小的XML文档,否则会很耗内存。
比如下面的结构。<string-array>下面包括许多<item>。这个结构包含了北京市下面的地级市
解析代码如下:
def xml_try():
domtree=xml.dom.minidom.parse(r'D:\test_source\arrays.xml')
data=domtree.documentElement
city=data.getElementsByTagName('string-array')
for c in city:
print c.getAttribute('name')
cityname =c.getElementsByTagName('item')
for name in cityname:
print name.childNodes[0].data
首先用domtree.documentElement将XML文件所有内容录入。然后用getElementsByTagName读取所有tag名字为string-array的结构。然后在每个结构里面再进行具体的解析。遍历到子节点的时候用childNodes来访问最后的末端元素。getAttribute得到具体的属性。
同样的文件我们用ElementTree解析方法如下:首先查找所有的string-array节点。然后再其中查找所有的item节点。然后输出节点内容
from xml.etree.ElementTree import parse
def xml_try():
doc=parse(r'D:\test_source\arrays.xml')
for city in doc.findall('string-array'):
name=city.findall('item')
for n in name:
print n.text
如果我们想精准的查找某个节点结构。方法如下:
doc1=parse(r'D:\test_source\rss20.xml')
for item in doc1.iterfind('channel/item/title'):
print item.text
xml结构如下:

上面是定位了最后一级的子节点。如果要定位到上面的父节点,然后查找所有的子节点的方法如下:
doc1=parse(r'D:\test_source\rss20.xml')
for item in doc1.iterfind('channel/item'):
print item.findtext('title')
print item.findtext('link')
前面2种方法都是一次性的将XML文件所有数据读入,然后再来进行查找。这种方法优点是查找速度快,但是很耗内存。其实大多数的情况下我们只是查找特定的元素。一次性的全部读入。会导致很多不必要的数据被写入。如果可以边查找边判断的话,那么可以大大的节约内存,iterparse就是这样的方法:还是用之前的文档。
from xml.etree.ElementTree import iterparse
doc2=iterparse(r'D:\test_source\rss20.xml',('start','end'))
for event,elem in doc2:
print 'the event is %s' % event
print elem.tag,elem.text
我们截取了一小部分的结果。

对应的XML结构

发现什么规律么,当遇到<title>的字符的时候,event就是start,当遇到</title>的时候event就是end. Iterparse返回2个元素,一个是event。一个是elem.这个elem就是位于start和end之间的元素。从上面的打印可以看到elem.tag,elem.text被打印了两次。这是由于在event为start的时候,打印了一次。在event为end的时候又被打印了一次。
我们可以修改代码如下,当只有在event为end的时候才输出text
doc2=iterparse(r'D:\test_source\rss20.xml',('start','end'))
for event,elem in doc2:
print 'the event is %s' % event
if event == 'end':
print elem.tag,elem.text
既然iterparse能够扫描一个个的元素,并得到对应的text.那么我们就可以将这个函数转换为生成器。代码修改如下:
def xml_try(element):
tag_indicate=[]
doc2=iterparse(r'D:\test_source\rss20.xml',('start','end'))
for event,elem in doc2:
if event == 'start':
tag_indicate.append(elem.tag)
if event == 'end':
if tag_indicate.pop() == element:
yield elem.text
if __name__=='__main__':
for r in xml_try('title'):
print r
在上面的代码中。当event为start的时候,记录此时的tag。当event为end的时候,比较记录的tag值和传入的element值。如果相当,则返回此时的elem.text. 在代码中我们传入的是title。得到的结果如下。

从上面几段代码可以看到,iterparse主要应用于比较大的xml文件。这种情况下如果一次性的读入所有数据形成树状结构,很耗内存。
python cookbook第三版学习笔记七:python解析csv,json,xml文件的更多相关文章
- python cookbook第三版学习笔记八:解析码流
Binascii模块 通过名字很容易知道这个模块的作用,binary, ascii.两个字母的合成,也就是二进制和ascii的转换模块 下面先介绍下字母的ascii码 a-z的ascii是从97-12 ...
- python cookbook第三版学习笔记十:类和对象(一)
类和对象: 我们经常会对打印一个对象来得到对象的某些信息. class pair: def __init__(self,x,y): self.x=x self. ...
- python cookbook第三版学习笔记四:文本以及字符串令牌解析
文本处理: 假设你存在一个目录,下面存在各种形式的文件,有txt,csv等等.如果你只想找到其中一种或多种格式的文件并打开该如何办呢.首先肯定是要找到满足条件的文件,然后进行路径合并在一一打开. pa ...
- python cookbook第三版学习笔记六:迭代器与生成器
假如我们有一个列表 items=[1,2,3].我们要遍历这个列表我们会用下面的方式 For i in items: Print i 首先介绍几个概念:容器,可迭代对象,迭代器 容器是一种存储数据 ...
- python cookbook第三版学习笔记 一
数据结构 假设有M个元素的列表,需要从中分解出N个对象,N<M,这会导致分解的值过多的异常.如下: record=['zhf','zhf@163.com','775-555-1212','847 ...
- python cookbook第三版学习笔记十三:类和对象(三)描述器
__get__以及__set__:假设T是一个类,t是他的实例,d是它的一个描述器属性.读取属性的时候T.d返回的是d.__get__(None,T),t.d返回的是d.__get__(t,T).说法 ...
- python cookbook第三版学习笔记二十:可自定义属性的装饰器
在开始本节之前,首先介绍下偏函数partial.首先借助help来看下partial的定义 首先来说下第一行解释的意思: partial 一共有三个部分: (1)第一部分也就是第一个参数,是一个函数, ...
- python cookbook第三版学习笔记十六:抽象基类
假设一个工程中有多个类,每个类都通过__init__来初始化参数.但是可能有很多高度重复且样式相同的__init__.为了减少代码.我们可以将初始化数据结构的步骤归纳到一个单独的__init__函数中 ...
- python cookbook第三版学习笔记十五:property和描述
8.5 私有属性: 在python中,如果想将私有数据封装到类的实例上,有两种方法:1 单下划线.2 双下划线 1 单下划线一般认为是内部实现,但是如果想从外部访问的话也是可以的 2 双下划线是则无法 ...
随机推荐
- New Ubuntu 16.04 Server Checklist
新的云服务器需要进行一些配置和安装一些软件,推荐Digitalocean社区的一些教程 服务器配置(包括SSH,安全设置):https://www.digitalocean.com/community ...
- 2016.10.18kubernetes 的8080和6443端口的区别与联系
由看过的资料知道,可以使用kubectl,client libraries和REST请求来访问api. 来自官方资料: By default the Kubernetes APIserver se ...
- centos 7 安装五笔输入法
centos 7 安装五笔输入法 [a@endv ~]$ yum search wubi 已加载插件:fastestmirror, langpacks Loading mirror speeds fr ...
- Android开发之布局文件里实现OnClick事件关联处理方法
一般监听OnClickListener事件,我们都是通过Button button = (Button)findViewById(....); button.setOClickLisener....这 ...
- C++必知必会(1)
条款1数据抽象 抽象数据类型的用途在于将变成语言扩展到一个特定的问题领域.一般对抽象数据类型的定义须要准训下面步骤: 1. 为类型取一个描写叙述性的名字 2. 列出类型所能运行的操作 ...
- zerglurker的C语言教程007——代码运行的顺序
软件开发中.代码有三种基本运行顺序: 顺序运行 代码从入口開始一条一条运行.直到返回或者结束 循环运行 在设定条件后,代码反复运行某一个或多个部分,直到达到某些条件后终止 条件运行 代码会先推断某些条 ...
- 将VS2010里的红色波浪线去掉
有时候,程序编译没错,却出现了一堆的红色波浪形,看着就烦. 解决方案:在VAssistX菜单栏->Visual Assist X Options->展开Advanced->Under ...
- 设计模式之Protocol实现代理模式
使用场合 使用步骤 不使用protocol实现代理 使用protocol实现代理 一.使用场合 A想让B帮忙,就让B代理 A想通知B发生了一些事情,或者传一些数据给B 观察者模式 二.使用步骤 定义一 ...
- SVN 服务端、客户端安装及配置、导入导出项目
http://blog.csdn.net/xcy13638760/article/details/12994923 http://www.cnblogs.com/armyfai/p/3985660.h ...
- Oracle 使用TRUNCATE TABLE删除所有行
若要删除表中的所有行,则 TRUNCATE TABLE 语句是一种快速.有效的方法.TRUNCATE TABLE 与不含 WHERE 子句的 DELETE 语句类似.但是,TRUNCATE TABLE ...