初涉KMP算法
久仰字符串系列理论
KMP
讲解(引用自bzoj3670动物园)
某天,园长给动物们讲解KMP算法。
园长:“对于一个字符串S,它的长度为L。我们可以在O(L)的时间内,求出一个名为next的数组。有谁预习了next数组的含义吗?”
熊猫:“对于字符串S的前i个字符构成的子串,既是它的后缀又是它的前缀的字符串中(它本身除外),最长的长度记作next[i]。”
园长:“非常好!那你能举个例子吗?”
熊猫:“例S为abcababc,则next[5]=2。因为S的前5个字符为abcab,ab既是它的后缀又是它的前缀,并且找不到一个更长的字符串满足这个性质。同理,还可得出next[1] = next[2] = next[3] = 0,next[4] = next[6] = 1,next[7] = 2,next[8] = 3。”
作用
基础KMP算法是用来处理字符串匹配的问题的。最简单的应用便是纯粹的询问:A是否在B中出现过。
KMP最核心的内容莫过于fail[](也叫做next[])。对于这部分内容的理解可以考出比较多的花样(但似乎kmp的模型无非比较经典的那几个,我到现在为止见过最灵活的还是非主席树莫属)
KMP的例题
【kmp模板】P3375 【模板】KMP字符串匹配
题目描述
如题,给出两个字符串s1和s2,其中s2为s1的子串,求出s2在s1中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组next。
(如果你不知道这是什么意思也不要问,去百度搜[kmp算法]学习一下就知道了。)
输入输出格式
输入格式:
第一行为一个字符串,即为s1
第二行为一个字符串,即为s2
输出格式:
若干行,每行包含一个整数,表示s2在s1中出现的位置
接下来1行,包括length(s2)个整数,表示前缀数组next[i]的值。
说明
时空限制:1000ms,128M
数据规模:
设s1长度为N,s2长度为M
对于30%的数据:N<=15,M<=5
对于70%的数据:N<=10000,M<=100
对于100%的数据:N<=1000000,M<=1000000
样例说明:
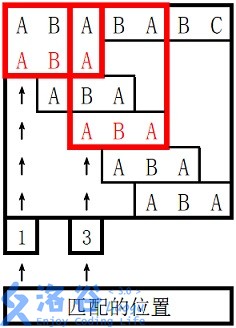
所以两个匹配位置为1和3,输出1、3
题目分析
基础KMP板子,先存着。
#include<bits/stdc++.h>
const int maxn = ; char A[maxn],B[maxn];
int fail[maxn],n,m; int main()
{
scanf("%s%s",A+,B+);
n = strlen(A+), m = strlen(B+);
fail[] = ;
for (int i=, j=; i<m; i++)
{
while (j&&B[j+]!=B[i+]) j = fail[j]; //不能继续匹配并且j没减到0,j回退
if (B[j+]==B[i+]) j++; //能继续匹配
fail[i+] = j;
}
for (int i=, j=; i<n; i++)
{
while (j&&B[j+]!=A[i+]) j = fail[j]; //不能继续匹配并且j没减到0,j回退
if (B[j+]==A[i+]) j++; //能匹配
if (j==m){ //匹配到了B串
printf("%d\n",i-m+);
j = fail[j]; //继续找匹配(因为有可能两处匹配重叠)
}
}
for (int i=; i<=m; i++) printf("%d ",fail[i]);
puts("");
return ;
}
【kmp略带理解】hdu2087剪花布条
Problem Description
Input
Output
题目分析
大意就是要在A中找出最多数量互不重叠的B串。于是每一次匹配完是将j清零就好了。
#include<bits/stdc++.h>
const int maxn = ; char A[maxn],B[maxn];
int fail[maxn],n,m,ans; int main()
{
while (scanf("%s",A+)!=EOF)
{
if (A[]=='#') break;
scanf("%s",B+);
n = strlen(A+), m = strlen(B+);
ans = fail[] = ;
for (int i=, j=; i<m; i++)
{
while (j&&B[i+]!=B[j+]) j = fail[j];
if (B[i+]==B[j+]) j++;
fail[i+] = j;
}
for (int i=, j=; i<n; i++)
{
while (j&&A[i+]!=B[j+]) j = fail[j];
if (A[i+]==B[j+]) j++;
if (j==m)
ans++, j = ;
}
printf("%d\n",ans);
}
return ;
}
【kmp理解】bzoj3670: [Noi2014]动物园
Description
近日,园长发现动物园中好吃懒做的动物越来越多了。例如企鹅,只会卖萌向游客要吃的。为了整治动物园的不良风气,让动物们凭自己的真才实学向游客要吃的,园长决定开设算法班,让动物们学习算法。
某天,园长给动物们讲解KMP算法。
园长:“对于一个字符串S,它的长度为L。我们可以在O(L)的时间内,求出一个名为next的数组。有谁预习了next数组的含义吗?”
熊猫:“对于字符串S的前i个字符构成的子串,既是它的后缀又是它的前缀的字符串中(它本身除外),最长的长度记作next[i]。”
园长:“非常好!那你能举个例子吗?”
熊猫:“例S为abcababc,则next[5]=2。因为S的前5个字符为abcab,ab既是它的后缀又是它的前缀,并且找不到一个更长的字符串满足这个性质。同理,还可得出next[1] = next[2] = next[3] = 0,next[4] = next[6] = 1,next[7] = 2,next[8] = 3。”
园长表扬了认真预习的熊猫同学。随后,他详细讲解了如何在O(L)的时间内求出next数组。
下课前,园长提出了一个问题:“KMP算法只能求出next数组。我现在希望求出一个更强大num数组一一对于字符串S的前i个字符构成的子串,既是它的后缀同时又是它的前缀,并且该后缀与该前缀不重叠,将这种字符串的数量记作num[i]。例如S为aaaaa,则num[4] = 2。这是因为S的前4个字符为aaaa,其中a和aa都满足性质‘既是后缀又是前缀’,同时保证这个后缀与这个前缀不重叠。而aaa虽然满足性质‘既是后缀又是前缀’,但遗憾的是这个后缀与这个前缀重叠了,所以不能计算在内。同理,num[1] = 0,num[2] = num[3] = 1,num[5] = 2。”
最后,园长给出了奖励条件,第一个做对的同学奖励巧克力一盒。听了这句话,睡了一节课的企鹅立刻就醒过来了!但企鹅并不会做这道题,于是向参观动物园的你寻求帮助。你能否帮助企鹅写一个程序求出num数组呢?
特别地,为了避免大量的输出,你不需要输出num[i]分别是多少,你只需要输出.jpg) 对1,000,000,007取模的结果即可。
对1,000,000,007取模的结果即可。
.jpg)
Input
第1行仅包含一个正整数n ,表示测试数据的组数。随后n行,每行描述一组测试数据。每组测试数据仅含有一个字符串S,S的定义详见题目描述。数据保证S 中仅含小写字母。输入文件中不会包含多余的空行,行末不会存在多余的空格。
Output
包含 n 行,每行描述一组测试数据的答案,答案的顺序应与输入数据的顺序保持一致。对于每组测试数据,仅需要输出一个整数,表示这组测试数据的答案对 1,000,000,007 取模的结果。输出文件中不应包含多余的空行。
Sample Input
aaaaa
ab
abcababc
Sample Output
1
32
HINT
n≤5,L≤1,000,000
题目大意
kmp算法中所求的$fail[i]$代表$i$位置最长「相同的前缀后缀」;相似地,这里的$num[i]$代表$i$位置所有不重叠「相同的前缀后缀」的数量和。
题目分析
嘛……算是一道考察对于kmp算法理解的思维题。
每一次求next[]时舍去有重叠的最长前后缀是不行的,因为会对后面的转移造成影响。
那么考虑最基础的暴力,就是枚举每一个i再做kmp(感觉这个暴力可以用exKMP优化的样子,不过我不会)。显然复杂度是爆炸的。
继而考虑优化,先求出允许重叠的「相同的前缀后缀」的答案$prenum[]$,再考虑与当前情况不矛盾的$prenum[]$之和。这句话或许有点奇怪,换而言之就是:在之前允许重叠的答案里,找出一些对于当前情况来说,不重叠的答案之和。
好吧之后的过程我讲得就不甚清楚了,挂一篇博客吧[NOI2014][bzoj3670] 动物园 [kmp+next数组应用]
#include<bits/stdc++.h>
const int maxn = ;
const int MO = 1e9+; int prenum[maxn],fail[maxn];
int tt,n,ans;
char str[maxn]; int main()
{
scanf("%d",&tt);
while (tt--)
{
memset(fail, , sizeof fail);
scanf("%s",str);
n = strlen(str);
prenum[] = , prenum[] = , ans = ;
for (int i=, j=; i<n; i++)
{
while (j&&str[i]!=str[j]) j = fail[j];
if (str[i]==str[j]) j++;
fail[i+] = j, prenum[i+] = prenum[j]+;
}
for (int i=, j=; i<n; i++)
{
while (j&&str[i]!=str[j]) j = fail[j];
if (str[i]==str[j]) j++;
while ((j<<)>i+) j = fail[j];
ans = 1ll*ans*(prenum[j]+)%MO;
}
printf("%d\n",ans);
}
return ;
}
【完全最短循环子串】poj2406Power Strings
Description
Input
Output
Sample Input
abcd
aaaa
ababab
.
Sample Output
1
4
3
Hint
题目大意
多组数据,求一个字符串的最短循环子串
题目分析
注意到kmp中的$fail[i]$表示的是最大的前缀的后缀的长度,即$1...fail[n]$等同$n-fail[n]+1...n$。也就是说若原串是一个循环次数大于1的循环子串,那么$n-fail[n]$一段刚好是最短的循环子串。
当时我也想了一会儿才想清楚,这里放一张图。
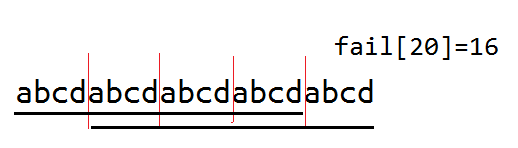
#include<cstring>
#include<cstdio>
const int maxn = ; char ch[maxn];
int fail[maxn],n; int main()
{
while (scanf("%s",ch+))
{
if (ch[]=='.') break;
memset(fail, , sizeof fail);
n = strlen(ch+);
for (int i=, j=; i<n; i++)
{
while (j&&ch[i+]!=ch[j+]) j = fail[j];
if (ch[i+]==ch[j+]) j++;
fail[i+] = j;
}
if (n%(n-fail[n])==) printf("%d\n",n/(n-fail[n]));
else puts("");
}
return ;
}
【不完全最短循环子串】bzoj1355: [Baltic2009]Radio Transmission
Description
Input
Output
Sample Input
cabcabca
Sample Output
HINT
对于样例,我们可以利用"abc"不断自我连接得到"abcabcabc",读入的cabcabca,是它的子串
题目分析
数据保证了给定串为不完整的循环子串,那么算几组手造数据的$fail[]$会发现:
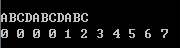
第二次循环节开始时,fail[]变为从一开始的递增序列。
要注意的是这并不意味着答案就是从首开始的零个数。
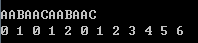
这是一个小细节。
#include<bits/stdc++.h>
const int maxn = ; char ch[maxn];
int n,fail[maxn]; int main()
{
scanf("%d%s",&n,ch+);
for (int i=, j=; i<n; i++)
{
while (j&&ch[i+]!=ch[j+]) j = fail[j];
if (ch[i+]==ch[j+]) j++;
fail[i+] = j;
}
printf("%d\n",n-fail[n]);
return ;
}
【fail[]巧妙运用】bzoj1511: [POI2006]OKR-Periods of Words
Description
Input
Output
Sample Input
babababa
Sample Output
题目分析
好困,大脑宕机。
先挂题解和代码:luoguP3435 [POI2006]OKR-Periods of Words
#include<bits/stdc++.h>
const int maxn = ; int n,fail[maxn];
char str[maxn];
long long ans; int main()
{
scanf("%d%s",&n,str+);
for (int i=, j=; i<n; i++)
{
while (j&&str[i+]!=str[j+]) j = fail[j];
if (str[i+]==str[j+]) j++;
fail[i+] = j;
}
for (int i=; i<=n; i++)
if (fail[fail[i]]) fail[i] = fail[fail[i]];
for (int i=; i<=n; i++)
if (fail[i]) ans += 1ll*i-fail[i];
printf("%lld\n",ans);
return ;
}
END
初涉KMP算法的更多相关文章
- 简单有效的kmp算法
以前看过kmp算法,当时接触后总感觉好深奥啊,抱着数据结构的数啃了一中午,最终才大致看懂,后来提起kmp也只剩下“奥,它是做模式匹配的”这点干货.最近有空,翻出来算法导论看看,原来就是这么简单(先不说 ...
- KMP算法
KMP算法是字符串模式匹配当中最经典的算法,原来大二学数据结构的有讲,但是当时只是记住了原理,但不知道代码实现,今天终于是完成了KMP的代码实现.原理KMP的原理其实很简单,给定一个字符串和一个模式串 ...
- 萌新笔记——用KMP算法与Trie字典树实现屏蔽敏感词(UTF-8编码)
前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽. 基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成"* ...
- KMP算法实现
链接:http://blog.csdn.net/joylnwang/article/details/6778316 KMP算法是一种很经典的字符串匹配算法,链接中的讲解已经是很明确得了,自己按照其讲解 ...
- 数据结构与算法JavaScript (五) 串(经典KMP算法)
KMP算法和BM算法 KMP是前缀匹配和BM后缀匹配的经典算法,看得出来前缀匹配和后缀匹配的区别就仅仅在于比较的顺序不同 前缀匹配是指:模式串和母串的比较从左到右,模式串的移动也是从 左到右 后缀匹配 ...
- 扩展KMP算法
一 问题定义 给定母串S和子串T,定义n为母串S的长度,m为子串T的长度,suffix[i]为第i个字符开始的母串S的后缀子串,extend[i]为suffix[i]与字串T的最长公共前缀长度.求出所 ...
- 字符串模式匹配之KMP算法图解与 next 数组原理和实现方案
之前说到,朴素的匹配,每趟比较,都要回溯主串的指针,费事.则 KMP 就是对朴素匹配的一种改进.正好复习一下. KMP 算法其改进思想在于: 每当一趟匹配过程中出现字符比较不相等时,不需要回溯主串的 ...
- 算法:KMP算法
算法:KMP排序 算法分析 KMP算法是一种快速的模式匹配算法.KMP是三位大师:D.E.Knuth.J.H.Morris和V.R.Pratt同时发现的,所以取首字母组成KMP. 少部分图片来自孤~影 ...
- BF算法与KMP算法
BF(Brute Force)算法是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符:若不相等,则比较S的 ...
随机推荐
- PHP实现用户登录注册功能
初学php做了一些比较常见且有用的页面,放在上面记录一下咯 我是用了bootstrap框架里面的模态框做注册登陆页面,这样页面比较美观 页面效果: 注册成功条件/功能: 1)用户名不能冲突 2)两次密 ...
- 00 | QPS
每秒查询率 QPS Query Per Second 某个查询服务器 在 规定时间内 处理了多少流量 对应的fetches/sec,即每秒响应请求数,就是最大吞吐量 原理:每天80%的访问集中在20% ...
- html table导出到Excel中,走后台保存文件,js并调用另保存
tableToExcel工具类,此工具类指定格式的表格进行转Excel 格式:其中不能带有thead,tbody和th标签 <table> <tr> <td>表头1 ...
- 抛出异常-throws和throw
package com.mpp.test; import java.util.Scanner; public class TryDemoFour { public static void main(S ...
- 微信支付——基于laravel框架的php实现
现在经手的几乎每个项目都支持微信支付,简单记录下接入的大致流程. 1.首先商户等申请各种账号,微信支付商户号,APPID,API密钥,Appsecret 2.app端上传支付需要的各个字段 3.后台收 ...
- Python基础之collection
collection-系列 cellection是作为字典.元组(列表与元组可互相转换)的扩充,在此需要导入cellection 一.计数器(counter) counter是对字典类型的补充,用户获 ...
- object-position和object-fit
今天在用video标签时发现改变video的宽和高,它里面播放内容由于比例的限制无法充满我设置的宽高,这时要是有类似background-size属性该是多好.网上一查果然找到了css3中的objec ...
- 实战:mysql写存储过程并定时调用
有表:cap_meter_detail 字段:recordtime 情景:recordtime每半个小时记录一次,故一天会产生很很多数据,我们要做的是,每天00:00:00对cap_meter_det ...
- 解决Unsupported major.minor version 51.0报错问题
问题产生原因:计算机环境变量的jdk版本与eclipse使用的jdk版本不一致 解决方法: 1.查看计算机环境变量的jdk版本 2.查看eclipse项目java compiler的方法:在项目点右键 ...
- KVC/KVO 本质
KVO 的实现原理 KVO是关于runtime机制实现的 当某个类的对象属性第一次被观察时,系统就会在运行期动态地创建该类的一个派生类,在这个派生类中重写基类中任何被观察属性的setter方法.派生类 ...