转: 多版本并发控制(MVCC)在分布式系统中的应用 (from coolshell)
from: http://coolshell.cn/articles/6790.html
问题
最近项目中遇到了一个分布式系统的并发控制问题。该问题可以抽象为:某分布式系统由一个数据中心D和若干业务处理中心L1,L2 … Ln组成;D本质上是一个key-value存储,它对外提供基于HTTP协议的CRUD操作接口。L的业务逻辑可以抽象为下面3个步骤:
- read: 根据keySet {k1, … kn}从D获取keyValueSet {k1:v1, … kn:vn}
- do: 根据keyValueSet进行业务处理,得到需要更新的数据集keyValueSet’ {k1′:v1′, … km’:vm’} (注:读取的keySet和更新的keySet’可能不同)
- update: 把keyValueSet’更新到D (注:D保证在一次调用更新多个key的原子性)
在没有事务支持的情况下,多个L进行并发处理可能会导致数据一致性问题。比如,考虑L1和L2的如下执行顺序:
- L1从D读取key:123对应的值100
- L2从D读取key:123对应的100
- L1将key:123更新为100 + 1
- L2将key:123更新为100 + 2
如果L1和L2串行执行,key:123对应的值将为103,但上面并发执行中L1的执行效果完全被L2所覆盖,实际key:123所对应的值变成了102。
解决方案1:基于锁的事务
为了让L的处理具有可串行化特性(Serializability),一种最直接的解决方案就是考虑为D加上基于锁的简单事务。让L在进行业务处理前先锁定D,完成以后释放锁。另外,为了防止持有锁的L由于某种原因长时间未提交事务,D还需要具有超时机制,当L尝试提交一个已超时的事务时会得到一个错误响应。

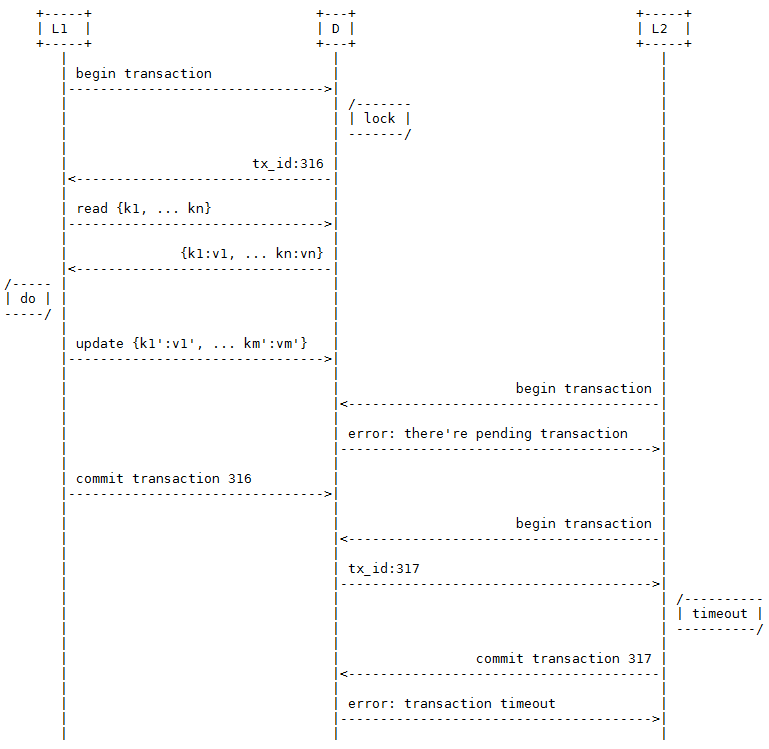
本方案的优点是实现简单,缺点是锁定了整个数据集,粒度太大;时间上包含了L的整个处理时间,跨度太长。虽然我们可以考虑把锁定粒度降低到数据项级别,按key进行锁定,但这又会带来其他的问题。由于更新的keySet’可能是事先不确定的,所以可能无法在开始事务时锁定所有的key;如果分阶段来锁定需要的key,又可能出现死锁(Deadlock)问题。另外,按key锁定在有锁争用的情况下并不能解决锁定时间太长的问题。所以,按key锁定仍然存在重要的不足之处。
解决方案2:多版本并发控制
为了实现可串行化,同时避免锁机制存在的各种问题,我们可以采用基于多版本并发控制(Multiversion concurrency control,MVCC)思想的无锁事务机制。人们一般把基于锁的并发控制机制称成为悲观机制,而把MVCC机制称为乐观机制。这是因为锁机制是一种预防性的,读会阻塞写,写也会阻塞读,当锁定粒度较大,时间较长时并发性能就不会太好;而MVCC是一种后验性的,读不阻塞写,写也不阻塞读,等到提交的时候才检验是否有冲突,由于没有锁,所以读写不会相互阻塞,从而大大提升了并发性能。我们可以借用源代码版本控制来理解MVCC,每个人都可以自由地阅读和修改本地的代码,相互之间不会阻塞,只在提交的时候版本控制器会检查冲突,并提示merge。目前,Oracle、PostgreSQL和MySQL都已支持基于MVCC的并发机制,但具体实现各有不同。
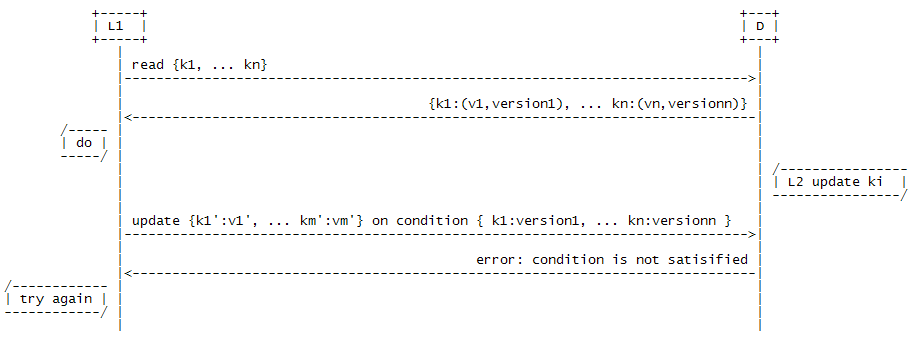
MVCC的一种简单实现是基于CAS(Compare-and-swap)思想的有条件更新(Conditional Update)。普通的update参数只包含了一个keyValueSet’,Conditional Update在此基础上加上了一组更新条件conditionSet { … data[keyx]=valuex, … },即只有在D满足更新条件的情况下才将数据更新为keyValueSet’;否则,返回错误信息。这样,L就形成了如下图所示的Try/Conditional Update/(Try again)的处理模式:


虽然对单个L来讲不能保证每次都成功更新,但从整个系统来看,总是有任务能够顺利进行。这种方案利用Conditional Update避免了大粒度和长时间的锁定,当各个业务之间资源争用不大的情况下,并发性能很好。不过,由于Conditional Update需要更多的参数,如果condition中value的长度很长,那么每次网络传送的数据量就会比较大,从而导致性能下降。特别是当需要更新的keyValueSet’很小,而condition很大时,就显得非常不经济。
为了避免condition太大所带来的性能问题,可以为每条数据项增加一个int型的版本号字段,由D维护该版本号,每次数据有更新就增加版本号;L在进行Conditional Update时,通过版本号取代具体的值。

另一个问题是上面的解决方案假设了D是可以支持Conditional Update的;那么,如果D是一个不支持Conditional Update的第三方的key-value存储怎么办呢?这时,我们可以在L和D之间增加一个P作为代理,所有的CRUD操作都必须经过P,让P来进行条件检查,而实际的数据操作放在D。这种方式实现了条件检查和数据操作的分离,但同时降低了性能,需要在P中增加cache,提升性能。由于P是D的唯一客户端;所以,P的cache管理是非常简单的,不必像多客户端情形担心缓存的失效。不过,实际上,据我所知redis和Amazon SimpleDB都已经有了Conditional Update的支持。
悲观锁和MVCC对比
上面介绍了悲观锁和MVCC的基本原理,但是对于它们分别适用于什么场合,不同的场合下两种机制优劣具体表现在什么地方还不是很清楚。这里我就对一些典型的应用场景进行简单的分析。需要注意的是下面的分析不针对分布式,悲观锁和MVCC两种机制在分布式系统、单数据库系统、甚至到内存变量各个层次都存在。
### 场景1:对读的响应速度要求高
有一类系统更新特别频繁,并且对读的响应速度要求很高,如股票交易系统。在悲观锁机制下,写会阻塞读,那么当有写操作时,读操作的响应速度就会受到影响;而MVCC不存在读写锁,读操作是不受任何阻塞的,所以读的响应速度会更快更稳定。
### 场景2:读远多于写
对于许多系统来讲,读操作的比例往往远大于写操作,特别是某些海量并发读的系统。在悲观锁机制下,当有写操作占用锁,就会有大量的读操作被阻塞,影响并发性能;而MVCC可以保持比较高且稳定的读并发能力。
### 场景3:写操作冲突频繁
如果系统中写操作的比例很高,且冲突频繁,这时就需要仔细评估。假设两个有冲突的业务L1和L2,它们在单独执行是分别耗时t1,t2。在悲观锁机制下,它们的总时间大约等于串行执行的时间:
T = t1 + t2
而在MVCC下,假设L1在L2之前更新,L2需要retry一次,它们的总时间大约等于L2执行两次的时间(这里假设L2的两次执行耗时相等,更好的情况是,如果第1次能缓存下部分有效结果,第二次执行L2耗时是可能减小的):
T’ = 2 * t2
这时关键是要评估retry的代价,如果retry的代价很低,比如,对某个计数器递增,又或者第二次执行可以比第一次快很多,这时采用MVCC机制就比较适合。反之,如果retry的代价很大,比如,报表统计运算需要算几小时甚至一天那就应该采用锁机制避免retry。
从上面的分析,我们可以简单的得出这样的结论:对读的响应速度和并发性要求比较高的场景适合MVCC;而retry代价越大的场景越适合悲观锁机制。
总结
本文介绍了一种基于多版本并发控制(MVCC)思想的Conditional Update解决分布式系统并发控制问题的方法。和基于悲观锁的方法相比,该方法避免了大粒度和长时间的锁定,能更好地适应对读的响应速度和并发性要求高的场景。
转: 多版本并发控制(MVCC)在分布式系统中的应用 (from coolshell)的更多相关文章
- 多版本号并发控制(MVCC)在分布式系统中的应用
QQ群:289150599 问题 近期项目中遇到了一个分布式系统的并发控制问题.该问题能够抽象为:某分布式系统由一个数据中心D和若干业务处理中心L1,L2 ... Ln组成:D本质上是一个key-va ...
- 数据库原理-事务隔离与多版本并发控制(MVCC)
刚来美团实习,正好是星期天,不得不说,其内部的资料很丰富,看了部分文档后,对数据库事务这块更理解了.数据库事务的ACID,大家都知道,为了维护这些性质,主要是隔离性和一致性,一般使用加锁这种方式.同时 ...
- MySQL多版本并发控制——MVCC机制分析
MVCC,即多版本并发控制(Multi-Version Concurrency Control)指的是,通过版本链维护一个数据的多个版本,使得读写操作没有冲突,可保证不同事务读写.写读操作并发执行,提 ...
- 多版本并发控制 MVCC
介绍多版本并发控制 多版本并发控制技术(Multiversion Concurrency Control,MVCC) 技术是为了解决问题而生的,通过 MVCC 我们可以解决以下几个问题: 读写之间阻塞 ...
- Mysql InnoDB多版本并发控制MVCC
参考书籍<mysql是怎样运行的> 系列文章目录和关于我 一丶为什么需要事务隔离级别 mysql是一个客户端/服务断软件,对于同一个服务器来说,可以有多个客户端进行连接,每一个客户端进行连 ...
- MySQL多版本并发控制(MVCC)
MVCC是行级锁的一个变种,但是它在很多的情况下避免了加锁操作,因此开销更低.MySQL,包括Oracle.PostgreSQL都实现了MVCC,虽然每个关系数据库实现不一样,但大都是实现了非阻塞的读 ...
- mysql-innoDB-多版本并发控制(MVCC)
InnoDB的MVCC,是通过在每行记录后面保存三个隐藏的列来实现的其中的两个列一个保存了行的创建时间,一个保存行的过期时间(或删除时间).当然存储的并不是实际的时间值,而是系统版本号(system ...
- InnoDB学习(五)之MVCC多版本并发控制
MVCC多版本并发控制,是一种数据库管理系统并发控制的方法.MVCC多版本并发控制下,数据库中的数据会有多个版本,分别对应不同的事务,从而达到事务之间并发数据的隔离.MVCC最大的优势是读不加锁,读写 ...
- MVCC多版本并发控制
MVCC多版本并发控制 爱情小傻蛋关注 82019.09.28 23:23:37字数 4,740阅读 91,421 前提概要 什么是MVCC 什么是当前读和快照读? 当前读,快照读和MVCC的关系 M ...
随机推荐
- [解读REST] 0.REST 相关参考资料
Web之父 Tim Berners Lee :https://en.wikipedia.org/wiki/Tim_Berners-Lee 世界上诞生的第一个网站:http://info.cern.ch ...
- dict的特性和基本语法——python3.6
特性 key:value结构,字典中的每一个元素,都是键值对 key必须可被hash,且必须为不可变数据类型,必须唯一 可存放任意多个值,可修改,可以不唯一 无序 查找速度快,因为hash可以把key ...
- CentOS 6.3下安装腾达USB无线网卡遇到的问题及解决方法
前言:centos 6.3 下,安装腾达W311M型号Usb无线网卡的步骤.究竟折腾及同事的先前帮助,后来搞定. centos6.3 为64位.安装步骤及顺序: 1.在当前版本下安装W311M usb ...
- 【bzoj4269】再见Xor 高斯消元求线性基
题目描述 给定N个数,你可以在这些数中任意选一些数出来,每个数可以选任意多次,试求出你能选出的数的异或和的最大值和严格次大值. 输入 第一行一个正整数N. 接下来一行N个非负整数. 输出 一行,包含两 ...
- gcd-模板+最小公倍数
#include<iostream> #include<cstdio> #include<algorithm> using namespace std; int G ...
- NOJ——1669xor的难题(详细的树状数组扩展—异或求和)
[1669] xor的难题 时间限制: 1000 ms 内存限制: 65535 K 问题描述 最近Alex学长有个问题被困扰了很久,就是有同学给他n个数,然后给你m个查询,然后每个查询给你l和r(左下 ...
- LibreOJ2045 - 「CQOI2016」密钥破解
Portal Description 给出三个正整数\(e,N,c(\leq2^{62})\).已知\(N\)能表示成\(p\cdot q\)的形式,其中\(p,q\)为质数.计算\(r=(p-1)( ...
- Github管理 第一步:在Eclipse中导入既存Github Java Project
1.前提 从官网下载的最新版本的Eclipse已经集成了Github插件,所以忽略了配置说明. 如果在下面的步骤中你找不到Git的设定目录,可能你的Eclipse中还没有Github,请自行解决. 2 ...
- 洛谷 P 1514 引水入城==Codevs 1066
题目描述 在一个遥远的国度,一侧是风景秀美的湖泊,另一侧则是漫无边际的沙漠.该国的行政区划十分特殊,刚好构成一个N 行M 列的矩形,如上图所示,其中每个格子都代表一座城市,每座城市都有一个海拔高度. ...
- ajax操作提交整个表单内容
1 2 3 4 5 6 7 8 9 10 11 12 13 $.ajax({ cache: true, type: "POST ...