【Kafka入门】Kafka入门第一篇:基础概念篇
Kafka简介
Kafka是一个消息系统服务框架,它以提交日志的形式存储消息,并且消息的存储是分布式的,为了提供并行性和容错保障,消息的存储是分区冗余形式存在的。
Kafka的架构
Kafka中包含以下几种专业术语:
1. topic:Kafka中以topic的形式来保存不同类别的消息
2. producer:Kafka中发布消息的称为producer
3. consumer:Kafka中订阅topic的进程称为consumer
4. broker:Kafka运行在由一个或多个服务(器)组成的集群上,每一个服务(器)称为一个broker。
具体的架构如下:
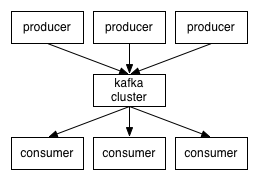
从架构图可以看出,producers通过网络将消息发布到Kafka上,然后消息以分区冗余的topic形式存储在分布式的Kafka服务集群上,最后consumers订阅不同的topic消息进行消费。其中客户端和服务器间是通过TCP协议进行通信。
topic(话题)
topic是已经发布的消息的一个分类名称,Kafka以分区(partition)日志的形式存储topic,也就是说,每个topic会被分成不同的partition,不同partition的关系如下:
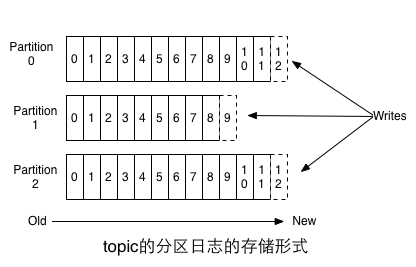
每个分区都是有序的不可变的消息序列,这些消息序列以追加形式写到提交日志上去。我们可以看到,在每个分区内,每条消息都被分配了一个下标号(offset),这些有序的下标号用以在不同partiton中唯一确定消息的位置。
消息在Kafka上的存储时间是可配置的,在配置时间范围内,消息是可以随时被消费,但是从消息发布时间开始计算,一旦配置的时间过了,为了腾出更多的空间,消息将会被丢弃。
topic的分布式存储和分布式的服务请求
producer(消息生产者)
consumer(消息消费者)
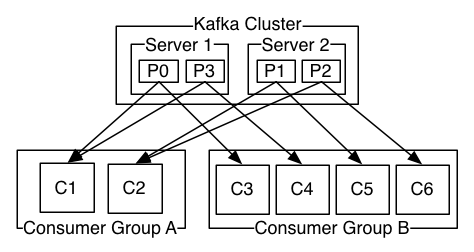
Kafka消息系统的几点保障
【Kafka入门】Kafka入门第一篇:基础概念篇的更多相关文章
- DNA拷贝数变异CNV检测——基础概念篇
DNA拷贝数变异CNV检测——基础概念篇 一.CNV 简介 拷贝数异常(copy number variations, CNVs)是属于基因组结构变异(structural variation), ...
- lua学习之基础概念篇
基础概念 程序块 (chunk) 定义 lua 中的每一个源代码文件或在交互模式(Cmd)中输入的一行代码都称之为程序块 一个程序块就是一连串语句或者命令 lua 中连续的语句不需要分隔符,但为了可读 ...
- (数据科学学习手札102)Python+Dash快速web应用开发——基础概念篇
本文示例代码与数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的新系列教程Python+Dash快 ...
- 函数响应式编程(FRP)从入门到”放弃”——基础概念篇
前言 研究ReactiveCocoa一段时间了,是时候总结一下学到的一些知识了. 一.函数响应式编程 说道函数响应式编程,就不得不提到函数式编程,它们俩到底有什么关系呢?今天我们就详细的解析一下他们的 ...
- 干货 | 自适应大邻域搜索(Adaptive Large Neighborhood Search)入门到精通超详细解析-概念篇
01 首先来区分几个概念 关于neighborhood serach,这里有好多种衍生和变种出来的胡里花俏的算法.大家在上网搜索的过程中可能看到什么Large Neighborhood Serach, ...
- 函数响应式编程(FRP)—基础概念篇
原文出处:http://ios.jobbole.com/86815/. 一函数响应式编程 说到函数响应式编程,就不得不提到函数式编程,他们俩有什么关系呢?今天我们就详细的解析一下他们的关系. 现在下面 ...
- Win32多线程编程(1) — 基础概念篇
内核对象的基本概念 Windows系统是非开源的,它提供给我们的接口是用户模式的,即User-Mode API.当我们调用某个API时,需要从用户模式切换到内核模式的I/O System Serv ...
- (一)github之基础概念篇
1.github: 一项为开发者提供git仓库的托管服务, 开发者间共享代码的场所.github上公开的软件源代码全都由git进行管理. 2.git: 开发者将源代码存入名为git仓库的资料库中,而g ...
- http协议之基础概念篇(1)
内容概述: 该篇主要内容概述 a.http相关术语解析 b.http的基本原理与工作流程 c.相关工具的使用(Wireshark) 作用介绍 绝大多数的web开发,都是构建在http协议之上的. HT ...
随机推荐
- codevs 1540 银河英雄传说
题目描述 Description 公元五八○一年,地球居民迁移至金牛座α第二行星,在那里发表银河联邦创立宣言,同年改元为宇宙历元年,并开始向银河系深处拓展. 宇宙历七九九年,银河系的两大军事集团在巴米 ...
- 告诉你KVC的一切-b
KVC(Key-value coding)键值编码,单看这个名字可能不太好理解.其实翻译一下就很简单了,就是指iOS的开发中,可以允许开发者通过Key名直接访问对象的属性,或者给对象的属性赋值.而不需 ...
- UIWebView 加载网页、文件、 html-b
UIWebView 是用来加载加载网页数据的一个框.UIWebView可以用来加载pdf word doc 等等文件 生成webview 有两种方法,1.通过storyboard 拖拽 2.通过al ...
- SQL2008附加数据库提示错误:5120
前几天在附加数据库时,出现了这个错误 在win7 x64系统上使用sql2008进行附加数据库(包括在x86系统正在使用的数据库文件,直接拷贝附加在X64系统中)时,提示无法打开文 ...
- hdu 1828 Picture(线段树 || 普通hash标记)
http://acm.hdu.edu.cn/showproblem.php?pid=1828 Picture Time Limit: 6000/2000 MS (Java/Others) Mem ...
- android apk 反编译
Apk文件结构 apk文件实际是一个zip压缩包,可以通过解压缩工具解开.以下是我们用zip解开helloworld.apk文件后看到的内容.可以看到其结构跟新建立的工程结构有些类似. java代码: ...
- Java之向左添加零(000001)第二种方法
//待测试数据 int i = 100; //得到一个NumberFormat的实例 NumberFormat nf = NumberFormat.getInstance(); //设置是否使用分组 ...
- javascript-代码复用模式
代码复用模式 1)使用原型继承 函数对象中自身声明的方法和属性与prototype声名的对象有什么不同: 自身声明的方法和属性是静态的, 也就是说你在声明后,试图再去增 ...
- 常用的python模块
http://tiankonghaikuo1000.blog.163.com/blog/static/18231597200812424255338/ adodb:我们领导推荐的数据库连接组件bsdd ...
- QT中的字符串处理函数
Fn 1 : arg 这个函数的具体声明不写了,它有20个重载,典型的示例代码如下: 1: #include <QtCore/QCoreApplication> 2: #include & ...