3.redis.3.2 下载,安装、配置、使用、集群主从创建 - 3




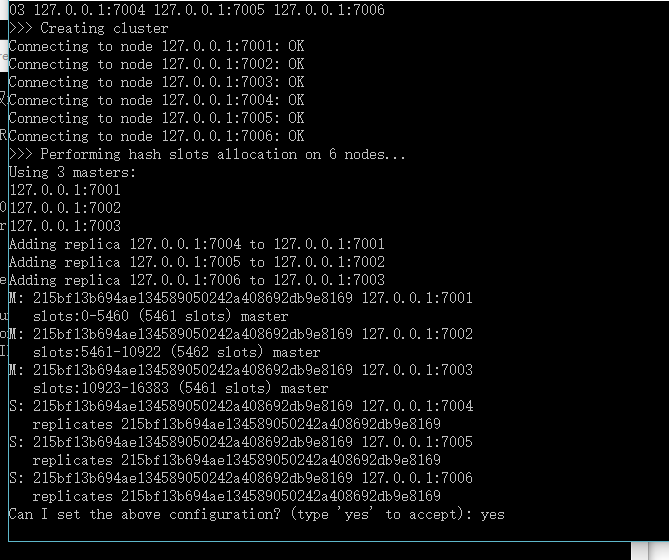



3.redis.3.2 下载,安装、配置、使用、集群主从创建 - 3的更多相关文章
- Linux中安装配置spark集群
一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoop MapReduce所 ...
- CentOS7安装配置redis5集群
一.服务器准备 本文准备了3台服务器 , 分别是 172.18.0.231 172.18.0.232 172.18.0.233 每台运行2个redis实例, 端口分别为7000 7001 ,即总共6个 ...
- Linux中安装配置hadoop集群
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择 ...
- Redis单台的安装部署及集群部署
Redis是一种高级key-value数据库.它跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富.有字符串,链表,集 合和有序集合.支持在服务器端计算集合的并,交和补集(diff ...
- 架构(三)MongoDB安装配置以及集群搭建
一 安装 1.1 下载MongoDB 我个人不太喜欢用wget url, 之前出现过wget下载的包有问题的情况 https://fastdl.mongodb.org/linux/mongodb-li ...
- 安装配置Spark集群
首先准备3台电脑或虚拟机,分别是Master,Worker1,Worker2,安装操作系统(本文中使用CentOS7). 1.配置集群,以下步骤在Master机器上执行 1.1.关闭防火墙:syste ...
- 离线环境下使用二进制方式安装配置Kubernetes集群
本文环境 Redhat Linux 7.3,操作系统采用的最小安装方式. Kubernetes的版本为 V1.10. Docker版本为18.03.1-ce. etcd 版本为 V3.3.8. 1. ...
- linux(centos8):安装配置consul集群(consul 1.8.4 | centos 8.2.2004)
一,什么是consul? 1,Consul 是 HashiCorp 公司推出的开源软件,用于实现分布式系统的服务发现与配置. Consul 是分布式的.高可用的. 可横向扩展的 2,官方网站: h ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
随机推荐
- java基础之运算符
运算符是用于表示数据的赋值,运算和比较的一种特殊符号.1.赋值运算符:=,+=,-=,*=,/=,%= x=1;x+=2;(相当于x=x+2,等于3),其他运算符同理 2.算术运算符:+,-,*,/, ...
- spoj 8222 Substrings(后缀自动机+DP)
[题目链接] http://acm.hust.edu.cn/vjudge/problem/viewProblem.action?id=28005 [题意] 给一个字符串S,令F(x)表示S的所有长度为 ...
- 使用CPU探查器优化XAML程序
如果您正在开发一个使用 XAML (是否是 c + +. C# 或 VB) 的 Windows 商店应用程序,还有一个好的机会来提高应用程序的性能.为了帮助完成这一点,我们所有在售的能够应用开发 Wi ...
- ARM Linux字符设备驱动程序
1.主设备号和次设备号(二者一起为设备号): 一个字符设备或块设备都有一个主设备号和一个次设备号.主设备号用来标识与设备文件相连的驱动程序,用来反 映设备类型.次设备号被驱动程序用来辨别操作的是哪个 ...
- C++ 类T T t;构造时分配的内存在静态数据区 T t=new T()分配的内存在堆 这样说对吗
C++ 类T T t;构造时分配的内存在静态数据区 T t=new T()分配的内存在堆
- 【原创】MapReduce计数器
MapReduce框架内置了一些计数器的支持,当然,我们也可以设置自己的计数器用来满足一些特殊的要求. 其实计数器可以用来完成很多事,关键要看你如何用,例如你想知道map输入数据的指定记录特定的信息有 ...
- HW5.9
public class Solution { public static void main(String[] args) { System.out.printf("%s\t%s\t%s\ ...
- smarty对网页性能的影响--开启opcache
在上一篇<smarty对网页性能的影响>中,默认没有开启opcache,于是我安装了一下zend opcache扩展,重新实验了一下,结果如下: 有smarty 用apache的ab命令进 ...
- 单位内部DNS架设及域名解析服务
越来越多的企业将企业内部局域网通过光缆.交换机等高速互连设备连接起来,形成较大规模的中型网络,网络上的主机和用户也随之日渐增多.作为 Internet的缩影,企业内部网上的各类服务器(如WWW服务器. ...
- python中的对象拷贝
python中.进行函数參数传递或者返回值时,假设是一般的变量,会拷贝传递.假设是列表或字典则是引用传递.那python怎样对列表和字典进行拷贝传递呢:标准库的copy模块提供了两个方法:copy和d ...