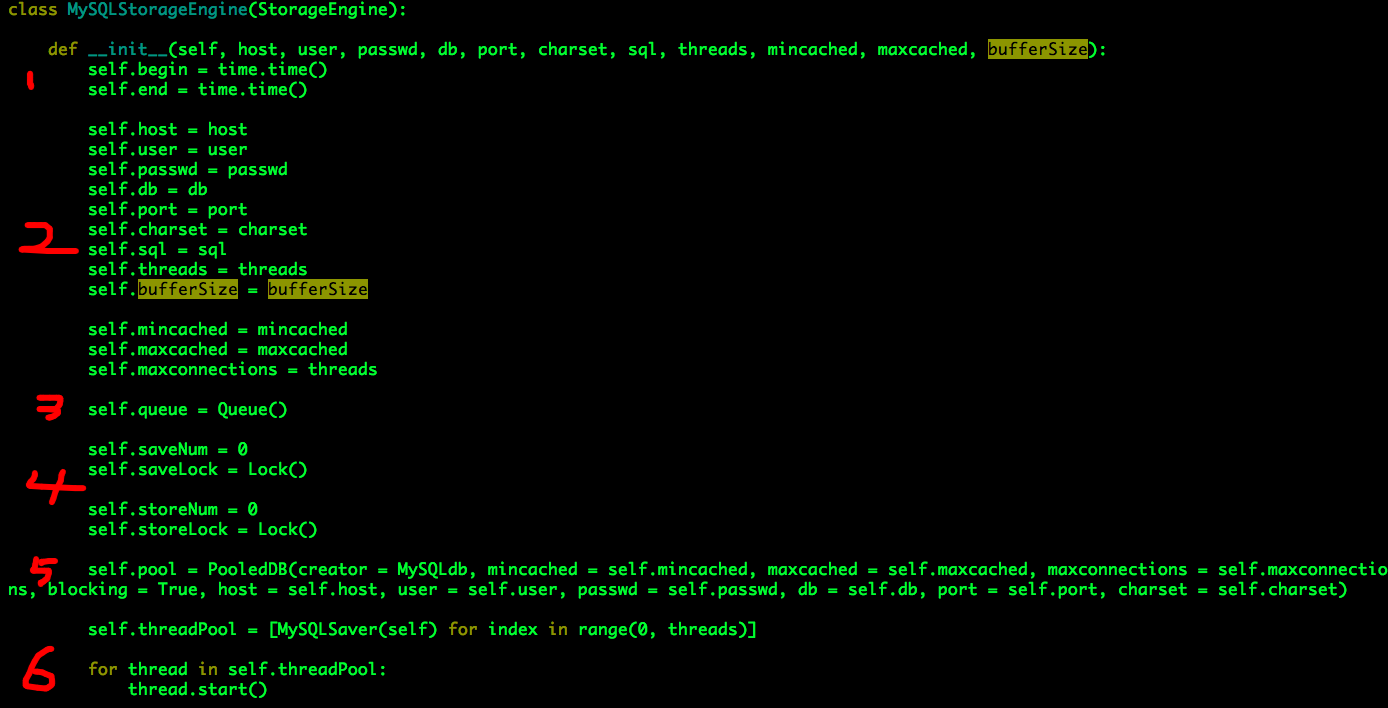
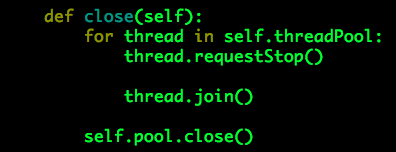
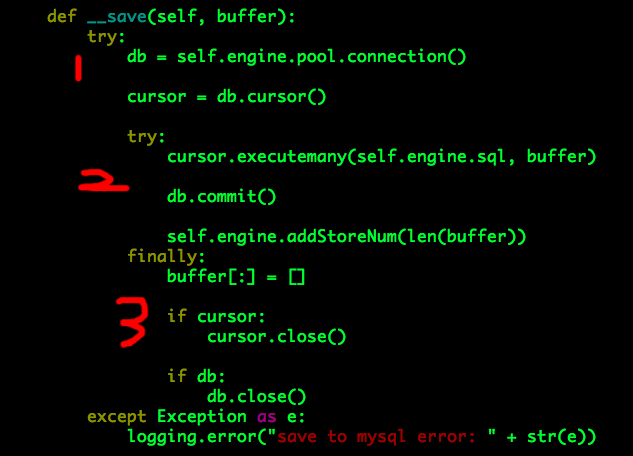
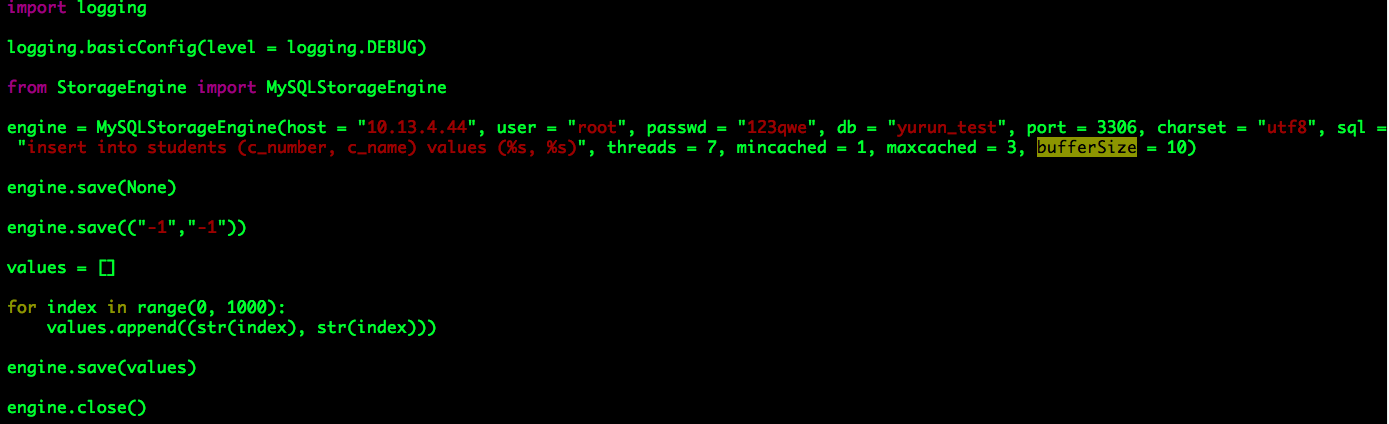
MySQL通用批量写入工具(Python)



MySQL通用批量写入工具(Python)的更多相关文章
- 【Python之旅】第六篇(七):开发简易主机批量管理工具
[Python之旅]第六篇(七):开发简易主机批量管理工具 python 软件开发 Paramiko模块 批量主机管理 摘要: 通过前面对Paramiko模块的学习与使用,以及Python中多线程与多 ...
- Sqlite表结构读取工具,word批量转html,在线云剪贴板,文件批量提取工具;
工欲善其事必先利其器,本周为您推荐工具排行 Sqlite表结构读取工具,word批量转html,在线云剪贴板,文件批量提取工具: 本周我们又要发干货了,准备好接受了吗? 为什么是干货,就是因为 ...
- Python开发程序:简单主机批量管理工具
题目:简单主机批量管理工具 需求: 主机分组 登录后显示主机分组,选择分组后查看主机列表 可批量执行命令.发送文件,结果实时返回 主机用户名密码可以不同 流程图: 说明: ### 作者介绍: * au ...
- mysql批量写入
MySQL批量写入语法是: INSERT INTO table (field1,field2,field3) VALUES (“a”,”b”,”c”), (“a1”,”b1”,”c1”),(“a2”, ...
- 【Python】JBOSS-JMX-EJB-InvokerServlet批量检测工具
一.说明 在JBoss服务器上部署web应用程序,有很多不同的方式,诸如:JMX Console.Remote Method Invocation(RMI).JMXInvokerServlet.Htt ...
- php从memcache读取数据再批量写入mysql的方法
这篇文章主要介绍了php从memcache读取数据再批量写入mysql的方法,可利用memcache缓解服务器读写压力,并实现数据库数据的写入操作,非常具有实用价值,需要的朋友可以参考下. 用 Mem ...
- Python简单主机批量管理工具
一.程序介绍 需求: 简单主机批量管理工具 需求: 1.主机分组 2.主机信息使用配置文件 3.可批量执行命令.发送文件,结果实时返回 4.主机用户名密码.端口可以不同 5.执行远程命令使用param ...
- 批量插入数据, 将DataTable里的数据批量写入数据库的方法
大量数据导入操作, 也就是直接将DataTable里的内容写入到数据库 通用方法: 拼接Insert语句, 好土鳖 1. MS Sql Server: 使用SqlBulkCopy 2. MySql ...
- 部署MySQL自动化运维工具inception+archer
***************************************************************************部署MySQL自动化运维工具inception+a ...
随机推荐
- java 服务端解决ajax跨域问题
//过滤器方式 可以更改为拦截器方式public class SimpleCORSFilter implements Filter { public void doFilter(ServletRequ ...
- 初学 Canvas <第一篇-基础篇>
本文摘自:兴趣部落大神(为你一生画眉)-讲一讲canvas究竟是个啥? HTML5 的标准已经出来好久了,但是似乎其中的 Canvas 现在并没有在太多的地方用到.一个很重要的原因是,Canvas 的 ...
- Ubuntu常见问题
1. Ubuntu16.04安装完国际版QQ后发现用不了搜狗输入法 sudo mv /usr/bin/ibus-daemon /usr/bin/ibus-daemon.bak
- HDU5303
题意:给定一个环形道路长度为L,以及环形道路下标为0处为起始点,在环形道路上距离起始点Xi位置种植一颗苹果树,该树有a个苹果,篮子的最大容量为K,那么求摘完全部苹果所需的最短距离. 思路:之前没想出来 ...
- 未在本地计算机上注册“Microsoft.Jet.OLEDB.4.0”提供程序(Oledb)
转载:http://blog.csdn.net/lemontec/article/details/1754413 前几天用c#读 Excel 出现了如下问题未在本地计算机上注册“Microsoft.J ...
- (转)PHP的ereg()与eregi()的不同及相同点。对比
ereg() 字符串比对解析. 语法: int ereg(string pattern, string string, array [regs]); 返回值: 整数/数组 函数种类: 资料处理 内容说 ...
- win7+SQL2008无法打开物理文件 操作系统错误 5:拒绝访问 SQL Sever
今天在win7+SQL2008的环境下操作分离附加数据库,分离出去然后再附加,没有问题.但是一把.mdf文件拷到其它文件夹下就出错,错误如下:无法打开物理文件 "E:\db\MyDB.mdf ...
- sql plus 和 pl/sql无法连接远程oracle数据库
前言:安装完oracle客户端后,可能会出现sql plus 和 pl/sql无法连接远程oracle数据库的情况,可能是以下原因: 针对sql plus连接不上: 1 可能原因:之前安装过oracl ...
- 【windows开发实现记事本程序——界面篇】
前言 从毕业开始学习windows UI编程,工作中总是和一些API打交道,但是从没有做过一个完整的界面程序.因此打算自己利用空余时间做一个小的项目来总结自己所学的东西.在网上看到许多人建议自己动手写 ...
- 你好,C++(32) 类是对现实世界的抽象和描述 6.2.1 类的声明和定义
6.2 类:当C++爱上面向对象 类这个概念是面向对象思想在C++中的具体体现:它既是封装的结果,同时也是继承和多态的载体.因此,要想学习C++中的面向对象程序设计,也就必须从“类”开始. 6.2. ...