Tars-Cpp 协程实现分析
作者:vivo 互联网服务器团队- Ye Feng
本文介绍了协程的概念,并讨论了 Tars Cpp 协程的实现原理和源码分析。
一、前言
Tars 是 Linux 基金会的开源项目(https://github.com/TarsCloud),它是基于名字服务使用 Tars 协议的高性能 RPC 开发框架,配套一体化的运营管理平台,并通过伸缩调度,实现运维半托管服务。Tars 集可扩展协议编解码、高性能 RPC 通信框架、名字路由与发现、发布监控、日志统计、配置管理等于一体,通过它可以快速用微服务的方式构建自己的稳定可靠的分布式应用,并实现完整有效的服务治理。
Tars 目前支持 C++,Java,PHP,Nodejs,Go 语言,其中 TarsCpp 3.x 全面启用对协程的支持,服务框架全面融合协程。本文基于TarsCpp-v3.0.0版本,讨论了协程在TarsCpp服务框架的实现。
二、协程的介绍
2.1 什么是协程
协程的概念最早出现在Melvin Conway在1963年的论文("Design of a separable transition-diagram compiler"),协程认为是“可以暂停和恢复执行”的函数。
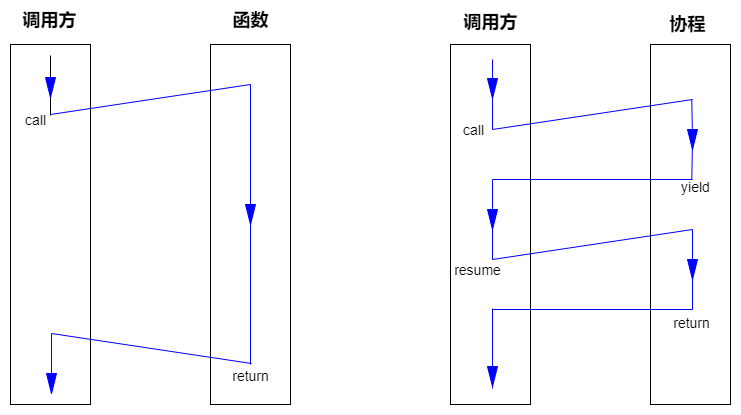
协程可以看成一种特殊的函数,相比于函数,协程最大的特点就是支持挂起(yield)和恢复(resume)的能力。如上图所示:函数不能主动中断执行流;而协程支持主动挂起,中断执行流,并在一定时机恢复执行。
协程的作用:
降低并发编码的复杂度,尤其是异步编程(callback hell)。
协程在用户态中实现调度,避免了陷入内核,上下文切换开销小。
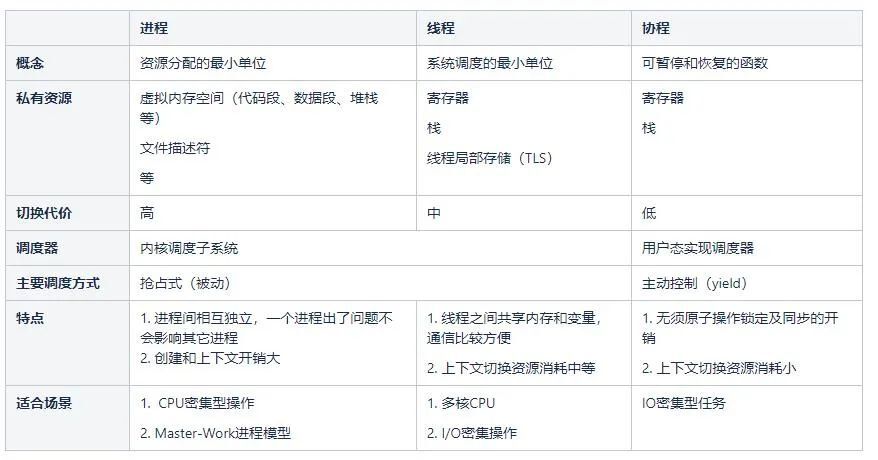
2.2 进程、线程和协程
我们可以简单的认为协程是用户态的线程。协程和线程主要异同:
相同点:都可以实现上下文切换(保存和恢复执行流)
不同点:线程的上下文切换在内核实现,切换的时机由内核调度器控制。协程的上下文切换在用户态实现,切换的时机由调用方自身控制。
进程、线程和协程的比较:
2.3 协程的分类
按控制传递(Control-transfer)机制分为:对称(Symmetric)协程和非对称(Asymmetric)协程。
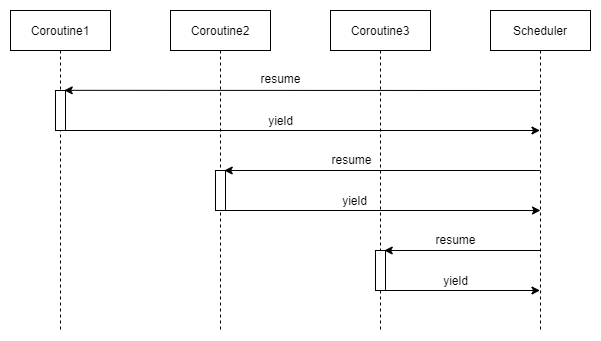
对称协程:协程之间相互独立,调度权(CPU)可以在任意协程之间转移。协程只有一种控制传递操作(yield)。对称协程一般需要调度器支持,通过调度算法选择下一个目标协程。
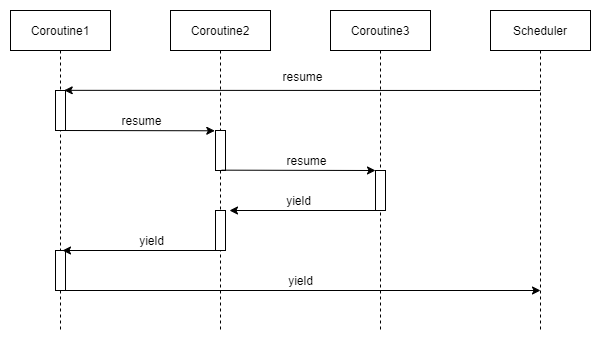
非对称协程:协程之间存在调用关系,协程让出的调度权只能返回给调用者。协程有两种控制操作:恢复(resume)和挂起(yield)。
下图演示了对称协程的调度权转移流程,协程只有一个操作yield,表示让出CPU,返回给调度器。
下图演示了非对称协程的调度权转移流程。协程可以有两个操作,即resume和yield。resume表示转移CPU给被调用者,yield表示被调用者返回CPU给调用者。
根据协程是否有独立的栈空间,协程分为有栈协程(stackful)和无栈协程(stackless)两种。
有栈协程:每个协程有独立的栈空间,保存独立的上下文(执行栈、寄存器等),协程的唤醒和挂起就是拷贝和切换上下文。优点:协程调度可以嵌套,在内存中的任意位置、任意时刻进行。局限:协程数目增大,内存开销增大。
无栈协程:单个线程内所有协程都共享同一个栈空间(共享栈),协程的切换就是简单的函数调用和返回,无栈协程通常是基于状态机或闭包来实现。优点:减小内存开销。局限:协程调度产生的局部变量都在共享栈上, 一旦新的协程运行后共享栈中的数据就会被覆盖, 先前协程的局部变量也就不再有效, 进而无法实现参数传递、嵌套调用等高级协程交互。
Golang 中的 goroutine、Lua 中的协程都是有栈协程;ES6的 await/async、Python 的 Generator、C++20 中的 cooroutine 都是无栈协程。
三、Tars 协程实现
实现协程的核心有两点:
实现用户态的上下文切换。
实现协程的调度。
Tars 协程的由下面几个类实现:
TC_CoroutineInfo 协程信息类:实现协程的上下文切换。每个协程对应一个 TC_CoroutineInfo 对象,上下文切换基于boost.context实现。
TC_CoroutineScheduler 协程调度器类:实现了协程的管理和调度。
TC_Coroutine 协程类:继承于线程类(TC_Thread),方便业务快速使用协程。
Tars 协程有几个特点:
有栈协程。每个协程都分配了独立的栈空间。
对称协程。协程之间相互独立,由调度器负责调度。
基于 epoll 实现协程调度,和网络IO无缝结合。
3.1 用户态上下文切换的实现方式
协程可以看成一种特殊的函数,和普通函数不同,协程函数有挂起(yield)和恢复(resume)的能力,即可以中断自己的执行流,并且在合适的时候恢复执行流,这也称为上下文切换的能力。
协程执行的过程,依赖两个关键要素:协程栈和寄存器,协程的上下文环境其实就是寄存器和栈的状态。实现上下文切换的核心就是实现保存并恢复当前执行环境的寄存器状态的能力。
实现用户态上下文切换一般有以下方式:

3.2 基于boost.context实现上下文切换
Tars 协程是基于 boost.context 实现,boost.context 提供了两个接口(make_fcontext, jump_fcontext)实现协程的上下文切换。
代码1:
/**
* @biref 执行环境上下文
*/
typedef void* fcontext_t;
/**
* @biref 事件参数包装
*/
struct transfer_t {
fcontext_t fctx; // 来源的执行上下文。来源的上下文指的是从什么位置跳转过来的
void* data; // 接口传入的自定义的指针
};
/**
* @biref 初始化执行环境上下文
* @param sp 栈空间地址
* @param size 栈空间的大小
* @param fn 入口函数
* @return 返回初始化完成后的执行环境上下文
*/
extern "C" fcontext_t make_fcontext(void * stack, std::size_t stack_size, void (* fn)( transfer_t));
/**
* @biref 跳转到目标上下文
* @param to 目标上下文
* @param vp 目标上下文的附加参数,会设置为transfer_t里的data成员
* @return 跳转来源
*/
extern "C" transfer_t jump_fcontext(fcontext_t const to, void * vp);(1)make_fcontext 创建协程
接受三个参数,stack 是为协程分配的栈底,stack_size 是栈的大小,fn 是协程的入口函数
返回初始化完成后的执行环境上下文
(2)jump_fcontext 切换协程
接受两个参数,目标上下文地址和参数指针
返回一个上下文,指向当前上下文从哪个上下文跳转过来
make_fcontext 和 jump_fcontext 通过汇编代码实现,具体的汇编代码可以参考:
https://github.com/TarsCloud/TarsCpp/blob/v3.0.0/util/src/asm/jump_x86_64_sysv_elf_gas.S
https://github.com/TarsCloud/TarsCpp/blob/v3.0.0/util/src/asm/make_x86_64_sysv_elf_gas.S
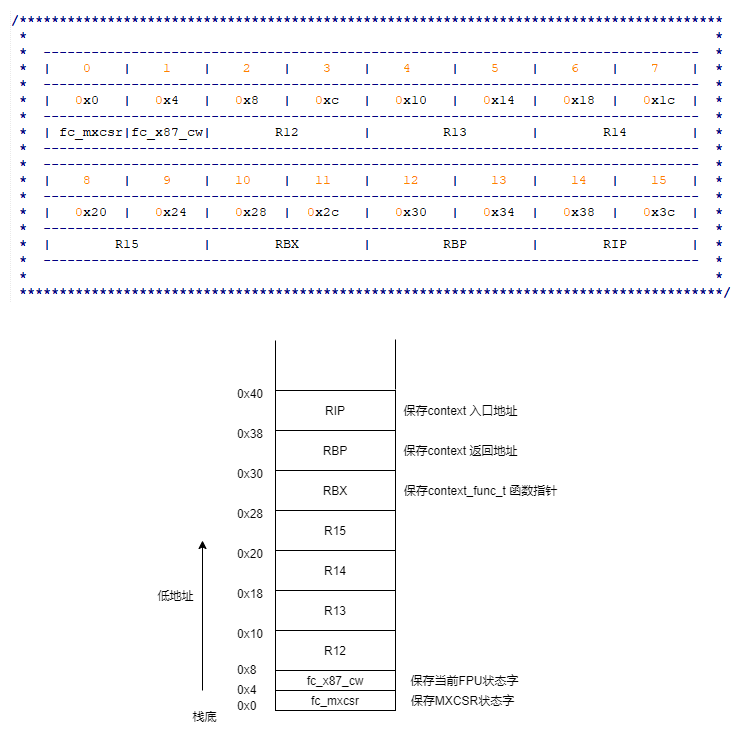
boost context 是通过 fcontext_t结构体来保存协程状态。相对于其它汇编实现的协程库,boost的context和stack是一起的,栈底指针就是context,切换context就是切换stack。
3.3 Tars协程信息类
TC_CoroutineInfo 协程信息类,包装了 boost.context 提供的接口,表示一个 TARS 协程。
其中,TC_CoroutineInfo::registerFunc 定义了协程的创建。
代码2:
void TC_CoroutineInfo::registerFunc(const std::function<void ()>& callback)
{
_callback = callback;
_init_func.coroFunc = TC_CoroutineInfo::corotineProc;
_init_func.args = this;
fcontext_t ctx = make_fcontext(_stack_ctx.sp, _stack_ctx.size,
TC_CoroutineInfo::corotineEntry); // 创建协程
transfer_t tf = jump_fcontext(ctx, this); // context 切换
//实际的ctx
this->setCtx(tf.fctx);
}
void TC_CoroutineInfo::corotineEntry(transfer_t tf)
{
TC_CoroutineInfo * coro = static_cast< TC_CoroutineInfo * >(tf.data); // this
auto func = coro->_init_func.coroFunc;
void* args = coro->_init_func.args;
transfer_t t = jump_fcontext(tf.fctx, NULL);
//拿到自己的协程堆栈, 当前协程结束以后, 好跳转到main
coro->_scheduler->setMainCtx(t.fctx);
//再跳转到具体函数
func(args, t);
}TC_CoroutineInfo::switchCoro 定义了协程切换。
代码3:
void TC_CoroutineScheduler::switchCoro(TC_CoroutineInfo *to)
{
//跳转到to协程
_currentCoro = to;
transfer_t t = jump_fcontext(to->getCtx(), NULL);
//并保存协程堆栈
to->setCtx(t.fctx);
}四、 Tars 协程调度器
基于 boost.context 的 TC_CoroutineInfo 类实现了协程的上下文切换,协程的管理和调度,则是由 TC_CoroutineScheduler 协程调度器类来负责,分管理和调度两个方面来说明 TC_CoroutineScheduler 调度类。
协程管理:目的是需要合理的数据结构来组织协程(TC_CoroutineInfo),方便调度的实现。
协程调度:目的是控制协程的启动、休眠和唤醒,实现了 yield, sleep 等功能,本质就是实现协程的状态机,完成协程的状态切换。Tars 协程分为 5 个状态:FREE, ACTIVE, AVAIL, INACTIVE, TIMEOUT
代码4:
/**
* 协程的状态信息
*/
enum CORO_STATUS
{
CORO_FREE = 0,
CORO_ACTIVE = 1,
CORO_AVAIL = 2,
CORO_INACTIVE = 3,
CORO_TIMEOUT = 4
};4.1 Tars 协程的管理
TC_CoroutineScheduler 主要通过以下方法管理协程:
TC_CoroutineScheduler::create() 创建 TC_CoroutineScheduler 对象
TC_CoroutineScheduler::init() 初始化,分配协程栈内存
TC_CoroutineScheduler::run() 启动调度
TC_CoroutineScheduler::terminate() 停止调度
TC_CoroutineScheduler::destroy() 资源销毁,释放协程栈内存
我们可以通过 TC_CoroutineScheduler::init() 看到数据结构的初始化过程。
代码5:
void TC_CoroutineScheduler::init()
{
... ....
createCoroutineInfo(_poolSize); // _all_coro = new TC_CoroutineInfo*[_poolSize+1];
TC_CoroutineInfo::CoroutineHeadInit(&_active);
TC_CoroutineInfo::CoroutineHeadInit(&_avail);
TC_CoroutineInfo::CoroutineHeadInit(&_inactive);
TC_CoroutineInfo::CoroutineHeadInit(&_timeout);
TC_CoroutineInfo::CoroutineHeadInit(&_free);
int iSucc = 0;
for(size_t i = 0; i < _currentSize; ++i)
{
//iId=0不使用, 给mainCoro使用!!!!
uint32_t iId = generateId();
stack_context s_ctx = stack_traits::allocate(_stackSize); // 分配协程栈内存
TC_CoroutineInfo *coro = new TC_CoroutineInfo(this, iId, s_ctx);
_all_coro[iId] = coro;
TC_CoroutineInfo::CoroutineAddTail(coro, &_free);
++iSucc;
}
_currentSize = iSucc;
_mainCoro.setUid(0);
_mainCoro.setStatus(TC_CoroutineInfo::CORO_FREE);
_currentCoro = &_mainCoro;
}通过下面的 TC_CoroutineScheduler 调度类数据结构图,可以更清楚的看到协程的组织方式:
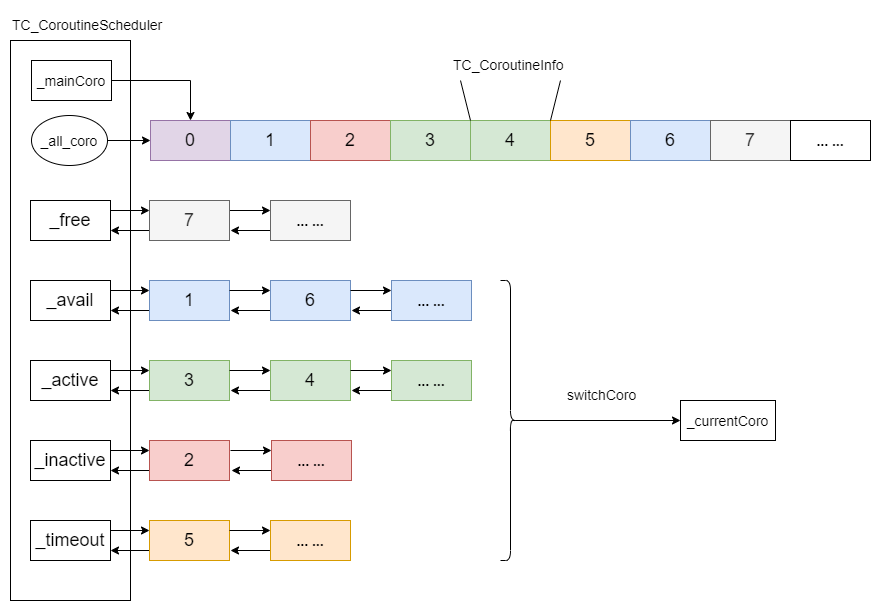
Tars调度类数据结构
使用协程之前,需要在协程数组(_all_coro),创建指定数量的协程对象,并为每个协程分配协程栈内存。
通过链表的方式管理协程,每个状态都有一个链表。协程状态切换,对应协程在不同状态链表的转移。
4.2 Tars 协程的调度
Tars 调度是基于epoll实现,在 epoll 循环里检查是否有需要执行的协程, 有则执行之, 没有则等待在epoll对象上, 直到有唤醒或者超时。使用 epoll 实现的好处是可以和网络IO无缝粘合, 当有数据发送/接收时, 唤醒epoll对象, 从而完成协程的切换。
Tars 协程调度的核心逻辑是:TC_CoroutineScheduler::run()
代码6:
void TC_CoroutineScheduler::run()
{
... ...
while(!_epoller->isTerminate())
{
if(_activeCoroQueue.empty() && TC_CoroutineInfo::CoroutineHeadEmpty(&_avail) && TC_CoroutineInfo::CoroutineHeadEmpty(&_active))
{
_epoller->done(1000); // epoll_wait(..., 1000ms) 先处理epoll的网络事件
}
//唤醒需要激活的协程
wakeup();
//唤醒sleep的协程
wakeupbytimeout();
//唤醒yield的协程
wakeupbyself();
int iLoop = 100;
//执行active协程, 每次执行100个, 避免占满cpu
while(iLoop > 0 && !TC_CoroutineInfo::CoroutineHeadEmpty(&_active))
{
TC_CoroutineInfo *coro = _active._next;
switchCoro(coro);
--iLoop;
}
//执行available协程, 每次执行1个
if(!TC_CoroutineInfo::CoroutineHeadEmpty(&_avail))
{
TC_CoroutineInfo *coro = _avail._next;
switchCoro(coro);
}
}
... ...
}下图可以更清楚得看到协程调度和状态转移的过程。
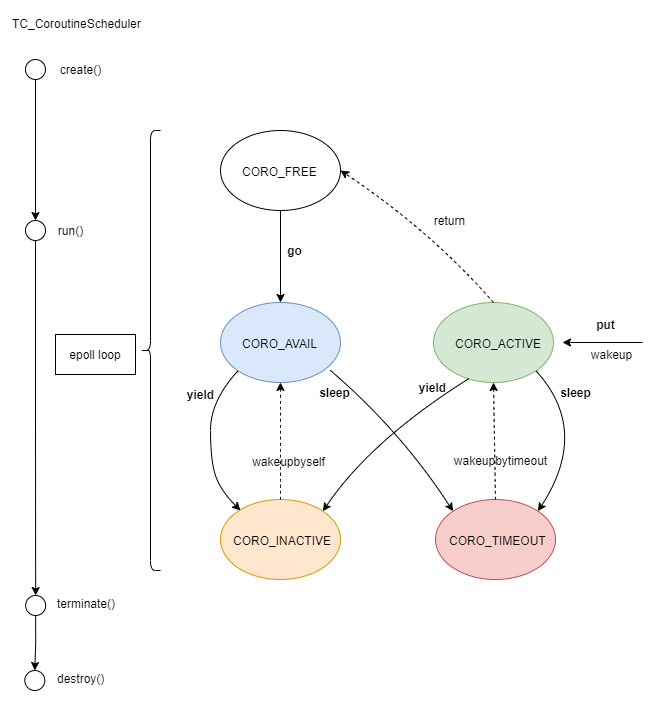
TC_CoroutineScheduler 提供了下面四种方法实现协程的调度:
(1) TC_CoroutineScheduler::go(): 启动协程。
(2)TC_CoroutineScheduler::yield(): 当前协程放弃继续执行。并提供了两种方式,支持不同的唤醒策略。
yield(true): 会自动唤醒(等到下次协程调度, 都会再激活当前线程)
yield(false): 不再自动唤醒, 除非自己调度该协程(比如put到调度器中)
(3)TC_CoroutineScheduler::sleep(): 当前协程休眠iSleepTime时间(单位:毫秒),然后会被唤醒继续执行。
(4)TC_CoroutineScheduler::put(): 放入需要唤醒的协程, 将协程放入到调度器中, 马上会被调度器调度。
五、总结
本文介绍了协程的概念,并讨论了 Tars Cpp 协程的实现原理和源码分析。
TarsCpp 3.x全面启用对协程的支持,本文的源码分析是基于TarsCpp-v3.0.0版本
https://github.com/TarsCloud/TarsCpp/tree/release/3.0
Tars-Cpp 协程实现分析的更多相关文章
- 分析Tornado的协程实现
转自:http://www.binss.me/blog/analyse-the-implement-of-coroutine-in-tornado/ 什么是协程 以下是Wiki的定义: Corouti ...
- Golang源码探索(二) 协程的实现原理
Golang最大的特色可以说是协程(goroutine)了, 协程让本来很复杂的异步编程变得简单, 让程序员不再需要面对回调地狱, 虽然现在引入了协程的语言越来越多, 但go中的协程仍然是实现的是最彻 ...
- Golang源码探索(二) 协程的实现原理(转)
Golang最大的特色可以说是协程(goroutine)了, 协程让本来很复杂的异步编程变得简单, 让程序员不再需要面对回调地狱,虽然现在引入了协程的语言越来越多, 但go中的协程仍然是实现的是最彻底 ...
- libco协程原理简要分析
此文简要分析一下libco协程的关键原理. 在分析前,先简单过一些协程的概念,以免有新手误读了此篇文章. 协程是用户态执行单元,它的创建,执行,上下文切换,挂起,销毁都是在用户态中完成,对linux系 ...
- qemu核心机制分析-协程coroutine
关于协程coroutine前面的文章已经介绍过了,本文总结对qemu中coroutine机制的分析,qemu 协程coroutine基于:setcontext函数族以及函数间跳转函数siglongjm ...
- Python协程的引入与原理分析
相关概念 并发:指一个时间段内,有几个程序在同一个cpu上运行,但是任意时刻只有一个程序在cpu上运行.比如说在一秒内cpu切换了100个进程,就可以认为cpu的并发是100. 并行:值任意时刻点上, ...
- 分析easyswoole3.0源码,协程连接池(五)
连接池的含义,很多都知道,比如mysql的数据库连接是有限的,一开始连接mysql创建N个连接,放到一个容器里,每次有请求去容器中取出,取出用完再放回去. es3demo里,有mysql的连接池. E ...
- 深入浅出!从语义角度分析隐藏在Unity协程背后的原理
Unity的协程使用起来比较方便,但是由于其封装和隐藏了太多细节,使其看起来比较神秘.比如协程是否是真正的异步执行?协程与线程到底是什么关系?本文将从语义角度来分析隐藏在协程背后的原理,并使用C++来 ...
- flask之分析线程和协程
flask之分析线程和协程 01 思考:每个请求之间的关系 我们每一个请求进来的时候都开一个进程肯定不合理,那么如果每一个请求进来都是串行的,那么根本实现不了并发,所以我们假定每一个请求进来使用的是线 ...
- 协程分析之context上下文切换
协程现在已经不是个新东西了,很多语言都提供了原生支持,也有很多开源的库也提供了协程支持. 最近为了要给tbox增加协程,特地研究了下各大开源协程库的实现,例如:libtask, libmill, bo ...
随机推荐
- scanf()函数的详解以及使用时需要注意的一些细节-C语言基础
这篇文章要探讨的是"scanf()函数的详解以及使用时需要注意的一些细节".涉及scanf()函数的应用和需要注意的问题.属于C语言基础篇(持续更新). scanf()(函数原型: ...
- DBeaver通过phoenix连接云主机的hbase
准备 1.云主机上已经安装好jdk.hadoop.hbase.zookeeper.phoenix,并且在主机上测试连接成功.可参考 https://blog.csdn.net/shangxindeku ...
- idea修改背景颜色|护眼色|项目栏背景修改
https://blog.csdn.net/heytyrell/article/details/89743068
- vs调试导入功能时莫名自动结束调试
新装了vs2022,默认下图所示的地方打勾,导致调试文件导入功能时触发了自动结束调试,真是坑爹~~
- ESP32开发环境搭建 IDF3.3.5+VScode
1. 软件准备: ① ESP-IDF:包含ESP32 API和用于操作工具链的脚本. ②工具链msys32:用于编译ESP32应用程序. ③编辑工具Visual Studio Code 注意:工具链 ...
- 如何通过C++ 将数据写入 Excel 工作表
直观的界面.出色的计算功能和图表工具,使Excel成为最流行的个人计算机数据处理软件.在独立的数据包含的信息量太少,而过多的数据又难以理清头绪时,制作成表格是数据管理的最有效手段之一.这样不仅可以方便 ...
- 14.AQS的前世,从1990年的论文说起
大家好,我是王有志.关注王有志,一起聊技术,聊游戏,聊在外漂泊的生活. 鸽了这么久怪不好意思的,因此送一本<多处理器编程的艺术>,快点击此处参加吧.另外欢迎大家加入"共同富裕的J ...
- 依图在实时音视频中语音处理的挑战丨RTC Dev Meetup
前言 「语音处理」是实时互动领域中非常重要的一个场景,在声网发起的「RTC Dev Meetup丨语音处理在实时互动领域的技术实践和应用」 活动中,来自百度.寰宇科技和依图的技术专家,围绕该话题进行了 ...
- 【读书笔记】格子路径计数LatticePathEnumeration 学一半的笔记
流水账流水账这篇什么都不是 目录 方法 10.2 Lattice paths without restrictions 无限制格子路径 2维的例子,从(a,b)到(c,d),允许(0,1)和(1,0) ...
- Lua基础语法学习笔记
Lua是一门语言,我们可以使用一个库,可以在运行时去编译执行Lua中的代码,从而实现自己的内存中的数据和逻辑: 准备学习环境: 新建一个Lua项目目录,用来写我们的Lua代码: 进入目录,右键使用vs ...