1.4 Apache Hadoop完全分布式集群搭建-hadoop-最全最完整的保姆级的java大数据学习资料
1.4 Apache Hadoop 完全分布式集群搭建
- 软件和操作系统版本
Hadoop框架是采用Java语言编写,需要java环境(jvm)
JDK版本:JDK8版本
集群:
知识点学习:统一使用vmware虚拟机虚拟三台linux节点,linux操作系统:Centos7
生产阶段:建议最少5台服务器节点 - Hadoop搭建方式
单机模式:单节点模式,非集群,生产不会使用这种方式
单机伪分布式模式:单节点,多线程模拟集群的效果,生产不会使用这种方式
完全分布式模式:多台节点,真正的分布式Hadoop集群的搭建(生产环境建议使用这种方式)
1.4.1 虚拟机环境准备
- 三台虚拟机(静态IP,关闭防火墙,修改主机名,配置免密登录,集群时间同步)
- 在/opt目录下创建文件夹
#软件安装包存放目录
mkdir -p /opt/lagou/software
#软件安装目录
mkdir -p /opt/lagou/servers
- Hadoop下载地址:
https://archive.apache.org/dist/hadoop/common/hadoop-2.9.2/
Hadoop官网地址:
- 上传hadoop安装文件到/opt/lagou/software
1.4.2 集群规划
| 框架 | linux121 | linux122 | linux123 |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | NodeManager | NodeManager、ResourceManager |
1.4.3 安装Hadoop
- 登录linux121节点;进入/opt/lagou/software,解压安装文件到/opt/lagou/servers
tar -zxvf hadoop-2.9.2.tar.gz -C /opt/lagou/servers
- 查看是否解压成功
ll /opt/lagou/servers/hadoop-2.9.2
- 添加Hadoop到环境变量 vim /etc/profile
#HADOOP_HOME
export HADOOP_HOME=/opt/lagou/servers/hadoop-2.9.2 export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 使环境变量生效
source /etc/profile
- 验证hadoop
hadoop version
校验结果:

- hadoop目录
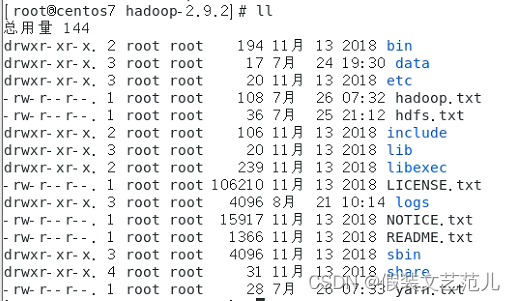
- bin目录:对Hadoop进行操作的相关命令,如hadoop,hdfs等
- etc目录:Hadoop的配置文件目录,如hdfs-site.xml,core-site.xml等
- lib目录:Hadoop本地库(解压缩的依赖)
- sbin目录:存放的是Hadoop集群启动停止相关脚本,命令
- share目录:Hadoop的一些jar,官方案例jar,文档等
1.4.3.1 集群配置
Hadoop集群配置 = HDFS集群配置 + MapReduce集群配置 + Yarn集群配置
- HDFS集群配置
- 将JDK路径明确配置给HDFS(修改hadoop-env.sh)
- 指定NameNode节点以及数据存储目录(修改core-site.xml)
- 指定SecondaryNameNode节点(修改hdfs-site.xml)
- 指定DataNode从节点(修改etc/hadoop/slaves文件,每个节点配置信息占一行)
- MapReduce集群配置
- 将JDK路径明确配置给MapReduce(修改mapred-env.sh)
- 指定MapReduce计算框架运行Yarn资源调度框架(修改mapred-site.xml)
- Yarn集群配置
- 将JDK路径明确配置给Yarn(修改yarn-env.sh)
- 指定ResourceManager老大节点所在计算机节点(修改yarn-site.xml)
- 指定NodeManager节点(会通过slaves文件内容确定)
集群配置具体步骤:
1.4.3.1.1 HDFS集群配置
cd /opt/lagou/servers/hadoop-2.9.2/etc/hadoop
配置:hadoop-env.sh
将JDK路径明确配置给HDFS
vim hadoop-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
指定NameNode节点以及数据存储目录(修改core-site.xml)
vim core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux121:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/lagou/servers/hadoop-2.9.2/data/tmp</value>
</property>
core-site.xml的默认配置:
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-common/core-default.xml
指定secondarynamenode节点(修改hdfs-site.xml)
vim hdfs-site.xml
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>linux123:50090</value>
</property>
<!-- 副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
官方默认配置
https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
- 指定datanode从节点(修改slaves文件,每个节点配置信息占一行)
vim slaves
linux121
linux122
linux123
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
1.4.3.1.2 MapReduce集群配置
指定MapReduce使用的jdk路径(修改mapred-env.sh)
vim mapred-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
- 指定MapReduce计算框架运行Yarn资源调度框架(修改mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
mapred-site.xml默认配置
1.4.3.1.3 Yarn集群配置
- 指定JDK路径
vim yarn-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
- 指定ResourceManager的master节点信息(修改yarn-site.xml)
vim yarn-site.xml
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>linux123</value>
</property>
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
yarn-site.xml的默认配置
https://hadoop.apache.org/docs/r2.9.2/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
- 指定NodeManager节点(slaves文件已修改)
注意:
Hadoop安装目录所属用户和所属用户组信息,默认是501 dialout,而我们操作Hadoop集群的用户使用的是虚拟机的root用户,所以为了避免出现信息混乱,修改Hadoop安装目录所属用户和用户组!!!
chown -R root:root /opt/lagou/servers/hadoop-2.9.2
1.4.3.2 分发配置
编写集群分发脚本rsync-script
- rsync 远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文 件都复制过去。
- 基本语法
rsync -rvl $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
- 选项参数说明
表2-2
| 选项 | 功能 |
|---|---|
| -r | 递归 |
| -v | 显示复制过程 |
| -l | 拷贝符号连接 |
rsync案例
- 三台虚拟机安装rsync (执行安装需要保证机器联网)
[root@linux121 ~]# yum install -y rsync
- 把linux121机器上的/opt/lagou/software目录同步到linux122服务器的root用户下的/opt/目录
[root@linux121 opt]$ rsync -rvl /opt/lagou/software/ root@linux122:/opt/lagou/software
集群分发脚本编写
需求:循环复制文件到集群所有节点的相同目录下
rsync命令原始拷贝:
rsync -rvl /opt/module root@linux123:/opt/
期望脚本
脚本+要同步的文件名称说明:在/usr/local/bin这个目录下存放的脚本,root用户可以在系统任何地方直接执行。
脚本实现
(1)在/usr/local/bin目录下创建文件rsync-script,文件内容如下:[root@linux121 bin]$ touch rsync-script
[root@linux121 bin]$ vim rsync-script
在文件中编写shell代码
#!/bin/bash #1 获取命令输入参数的个数,如果个数为0,直接退出命令 paramnum=$#
if((paramnum==0)); then
echo no params;
exit;
fi #2 根据传入参数获取文件名称
p1=$1
file_name=`basename $p1`
echo fname=$file_name #3 获取输入参数的绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir #4 获取用户名称
user=`whoami` #5 循环执行rsync
for((host=121; host<124; host++)); do
echo ------------------- linux$host --------------
rsync -rvl $pdir/$file_name $user@linux$host:$pdir
done
(2)修改脚本 rsync-script 具有执行权限
[root@linux121 bin]$ chmod 777 rsync-script
(3)调用脚本形式:rsync-script 文件名称
[root@linux121 bin]$ rsync-script /home/root/bin
(4)调用脚本分发Hadoop安装目录到其它节点
[root@linux121 bin]$ rsync-script /opt/lagou/servers/hadoop-2.9.2
1.4.4 启动集群
注意:如果集群是第一次启动,需要在Namenode所在节点格式化NameNode,非第一次不用执行格式化Namenode操作!!!
1.4.4.1 单节点启动
[root@linux121 hadoop-2.9.2]$ hadoop namenode -format
格式化命令执行效果:

格式化后创建的文件:/opt/lagou/servers/hadoop-2.9.2/data/tmp/dfs/name/current

在linux121上启动NameNode
[root@linux121 hadoop-2.9.2]$ hadoop-daemon.sh start namenode
[root@linux121 hadoop-2.9.2]$ jps
在linux121、linux122以及linux123上分别启动DataNode
[root@linux121 hadoop-2.9.2]$ hadoop-daemon.sh start datanode
[root@linux121 hadoop-2.9.2]$ jps
3461 NameNode
3608 Jps
3561 DataNode [root@linux122 hadoop-2.9.2]$ hadoop-daemon.sh start datanode
[root@linux122 hadoop-2.9.2]$ jps
3190 DataNode
3279 Jps [root@linux123 hadoop-2.9.2]$ hadoop-daemon.sh start datanode
[root@linux123 hadoop-2.9.2]$ jps
3237 Jps
3163 DataNode
web端查看hdfs界面
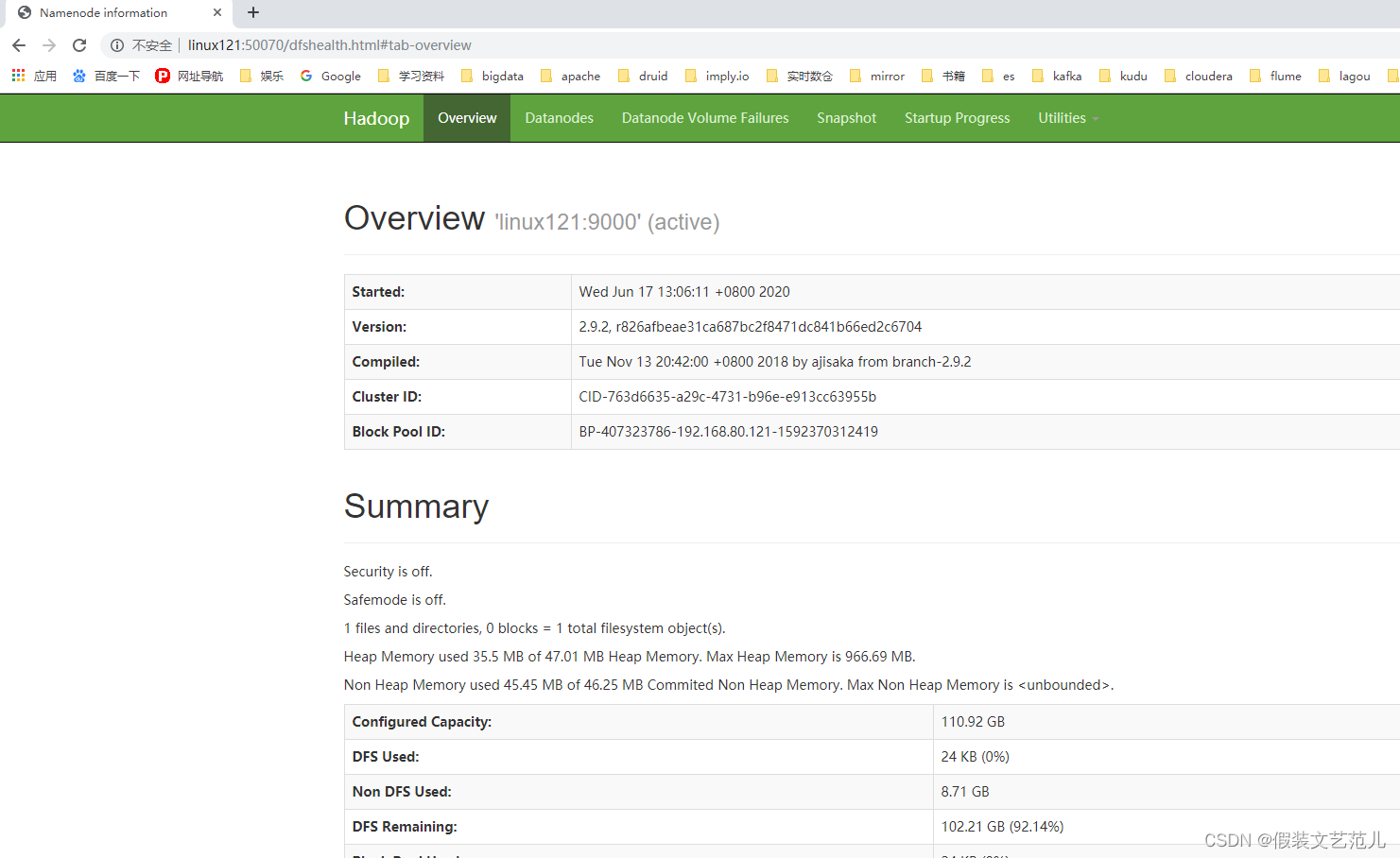
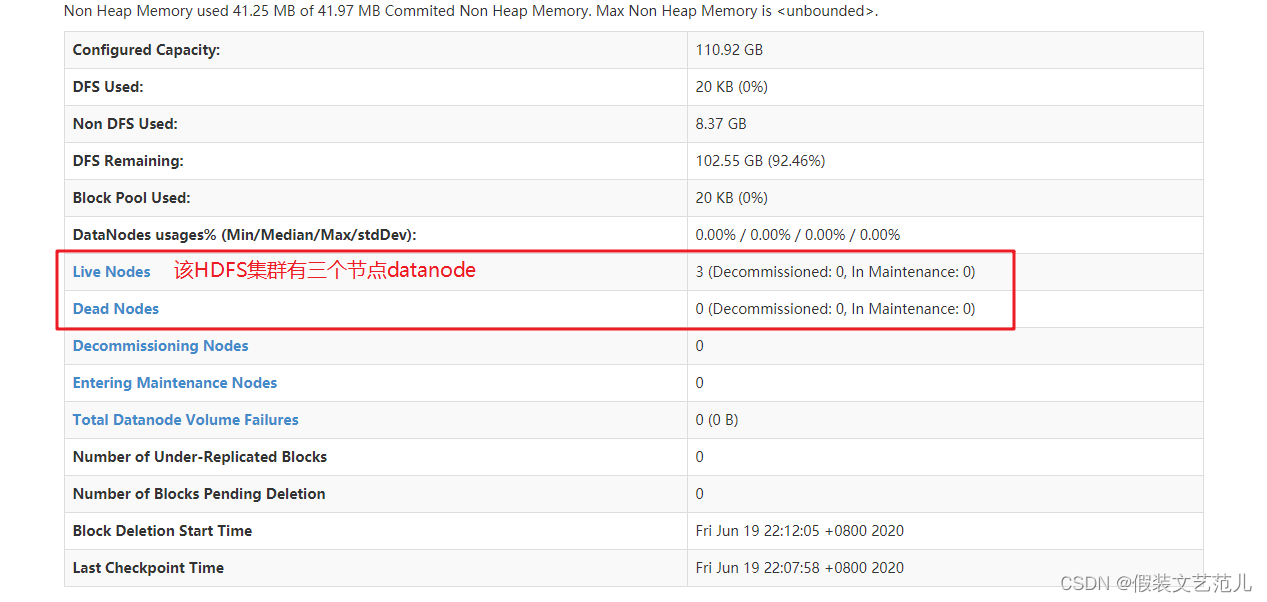
查看HDFS集群正常节点:
Yarn集群单节点启动
[root@linux123 servers]# yarn-daemon.sh start resourcemanager
[root@linux123 servers]# jps
7881 ResourceManager
8094 Jps [root@linux122 servers]# yarn-daemon.sh start nodemanager
[root@linux122 servers]# jps
8166 NodeManager
8223 Jps [root@linux121 servers]# yarn-daemon.sh start nodemanager
[root@linux121 servers]# jps
8166 NodeManager
8223 Jps
思考:Hadoop集群每次需要一个一个节点的启动,如果节点数增加到成千上万个怎么办?
1.4.4.2 集群群起
如果已经单节点方式启动了Hadoop,可以先停止之前的启动的Namenode与Datanode进程,如果之前Namenode没有执行格式化,这里需要执行格式化!!!!
hadoop namenode -format
启动HDFS
[root@linux121 hadoop-2.9.2]$ sbin/start-dfs.sh
[root@linux121 hadoop-2.9.2]$ jps
4166 NameNode
4482 Jps
4263 DataNode [root@linux122 hadoop-2.9.2]$ jps
3218 DataNode
3288 Jps [root@linux123 hadoop-2.9.2]$ jps
3221 DataNode
3283 SecondaryNameNode
3364 Jps
启动YARN
[root@linux123 hadoop-2.9.2]$ sbin/start-yarn.sh
注意:NameNode和ResourceManger不是在同一台机器,不能在NameNode上启动 YARN,应该 在ResouceManager所在的机器上启动YARN。
1.4.4.3 Hadoop集群启动停止命令汇总
各个服务组件逐一启动/停止
分别启动/停止HDFS组件
hadoop-daemon.sh start / stop namenode / datanode / secondarynamenode
启动/停止YARN
yarn-daemon.sh start / stop resourcemanager / nodemanager
各个模块分开启动/停止(配置ssh是前提)常用
整体启动/停止HDFS
start-dfs.sh / stop-dfs.sh
整体启动/停止YARN
start-yarn.sh / stop-yarn.sh
1.4.5 集群测试
HDFS 分布式存储初体验
从linux本地文件系统上传下载文件验证HDFS集群工作正常
hdfs dfs -mkdir -p /test/input
#本地hoome目录创建一个文件
cd /root vim test.txt hello hdfs #上传linxu文件到Hdfs
hdfs dfs -put /root/test.txt /test/input #从Hdfs下载文件到linux本地
hdfs dfs -get /test/input/test.txt
MapReduce 分布式计算初体验
在HDFS文件系统根目录下面创建一个wcinput文件夹
[root@linux121 hadoop-2.9.2]$ hdfs dfs -mkdir /wcinput
在/root/目录下创建一个wc.txt文件(本地文件系统)
[root@linux121 hadoop-2.9.2]$ cd /root/
[root@linux121 wcinput]$ touch wc.txt
编辑wc.txt文件
[root@linux121 wcinput]$ vi wc.txt
在文件中输入如下内容
hadoop mapreduce yarn
hdfs hadoop mapreduce
mapreduce yarn lagou
lagou
lagou
保存退出
: wq!
上传wc.txt到Hdfs目录/wcinput下
hdfs dfs -put wc.txt /wcinput
回到Hadoop目录/opt/lagou/servers/hadoop-2.9.2
执行程序
[root@linux121 hadoop-2.9.2]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput
查看结果
[root@linux121 hadoop-2.9.2]$ hdfs dfs -cat /wcoutput/part-r-00000 hadoop 2
hdfs 1
lagou 3
mapreduce 3
yarn 2
1.4.6 配置历史服务器
在Yarn中运行的任务产生的日志数据不能查看,为了查看程序的历史运行情况,需要配置一下历史日志服务器。具体配置步骤如下:
配置mapred-site.xml
[root@linux121 hadoop]$ vi mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>linux121:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>linux121:19888</value>
</property>
分发mapred-site.xml到其它节点
rsync-script mapred-site.xml
启动历史服务器
[root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
查看历史服务器是否启动
[root@linux121 hadoop-2.9.2]$ jps
查看JobHistory
http://linux121:19888/jobhistory
1.4.6.1 配置日志的聚集
日志聚集:应用(Job)运行完成以后,将应用运行日志信息从各个task汇总上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和 HistoryManager。
开启日志聚集功能具体步骤如下:
配置yarn-site.xml
[root@linux121 hadoop]$ vi yarn-site.xml
在该文件里面增加如下配置。
<!-- 日志聚集功能开启 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://linux121:19888/jobhistory/logs</value>
</property>
分发yarn-site.xml到集群其它节点
rsync-script yarn-site.xml
关闭NodeManager 、ResourceManager和HistoryManager
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh stop resourcemanager [root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh stop nodemanager [root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh stop historyserver
启动NodeManager 、ResourceManager和HistoryManager
[root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh start resourcemanager [root@linux121 hadoop-2.9.2]$ sbin/yarn-daemon.sh start nodemanager [root@linux121 hadoop-2.9.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
删除HDFS上已经存在的输出文件
[root@linux121 hadoop-2.9.2]$ bin/hdfs dfs -rm -R /wcoutput
执行WordCount程序
[root@linux121 hadoop-2.9.2]$ hadoop jar share/hadoop/mapreduce/hadoop- mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput
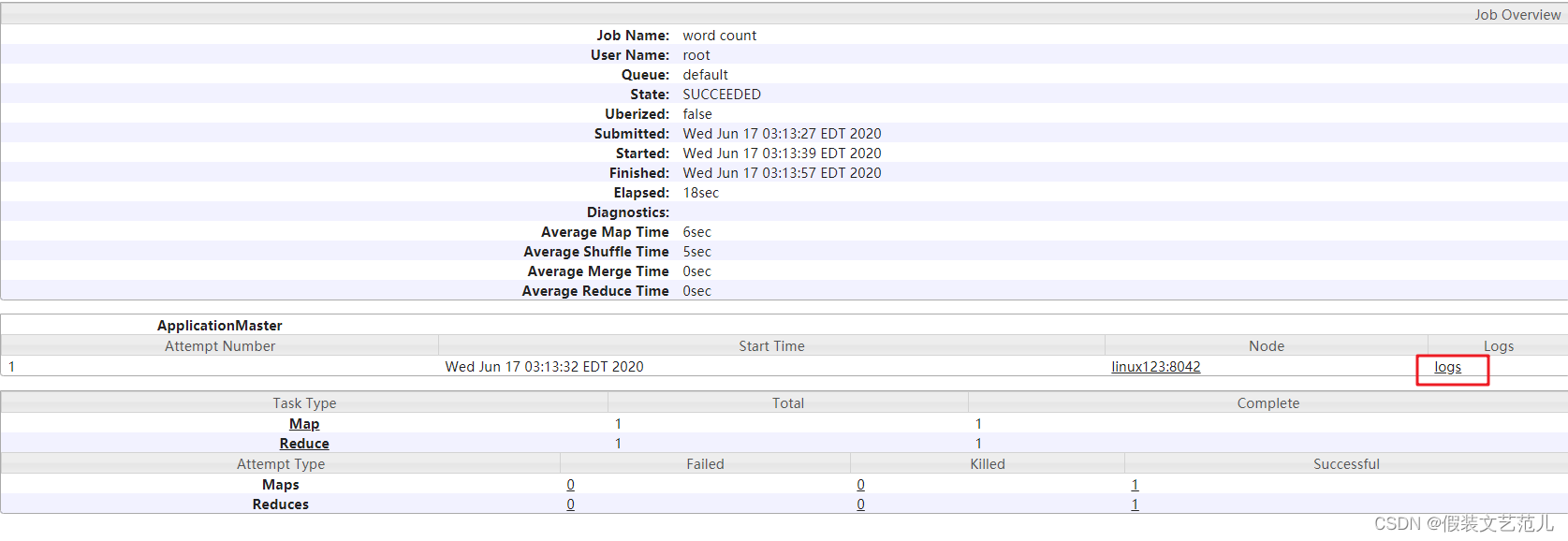
查看日志,如图所示


1.4 Apache Hadoop完全分布式集群搭建-hadoop-最全最完整的保姆级的java大数据学习资料的更多相关文章
- Hadoop完全分布式集群搭建
Hadoop的运行模式 Hadoop一般有三种运行模式,分别是: 单机模式(Standalone Mode),默认情况下,Hadoop即处于该模式,使用本地文件系统,而不是分布式文件系统.,用于开发和 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- 大数据之Hadoop完全分布式集群搭建
1.准备阶段 1.1.新建三台虚拟机 Hadoop完全分市式集群是典型的主从架构(master-slave),一般需要使用多台服务器来组建.我们准备3台服务器(关闭防火墙.静态IP.主机名称).如果没 ...
- 基于Hadoop伪分布式集群搭建Spark
一.前置安装 1)JDK 2)Hadoop伪分布式集群 二.Scala安装 1)解压Scala安装包 2)环境变量 SCALA_HOME = C:\ProgramData\scala-2.10.6 P ...
- Hadoop伪分布式集群搭建
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 1.下载Hadoop压缩包 wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop- ...
- centos7+hadoop完全分布式集群搭建
Hadoop集群部署,就是以Cluster mode方式进行部署.本文是基于JDK1.7.0_79,hadoop2.7.5. 1.Hadoop的节点构成如下: HDFS daemon: NameN ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
- linux运维、架构之路-Hadoop完全分布式集群搭建
一.介绍 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS.HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件 ...
- hadoop HA分布式集群搭建
概述 hadoop2中NameNode可以有多个(目前只支持2个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正 ...
- 1、hadoop HA分布式集群搭建
概述 hadoop2中NameNode可以有多个(目前只支持2个).每一个都有相同的职能.一个是active状态的,一个是standby状态的.当集群运行时,只有active状态的NameNode是正 ...
随机推荐
- Elasticsearch:Pinyin 分词器
Elastic的Medcl提供了一种搜索Pinyin搜索的方法.拼音搜索在很多的应用场景中都有被用到.比如在百度搜索中,我们使用拼音就可以出现汉字: 对于我们中国人来说,拼音搜索也是非常直接的.那么在 ...
- krew插件安装
概念 Krew是kubectl插件的包管理工具.借助Krew,可以轻松地使用kubectl plugin:发现插件.安装和管理插件.使用类似apt.dnf或者brew. 对于kubectl用户:kre ...
- 3.使用nexus3配置maven私有仓库
配置之前,我们先来看看系统默认创建的都有哪些 其中圈起来的都是系统原有的,用不到,就全删掉,重新创建. 1,创建blob存储 2,创建hosted类型的maven 点击 Repository下面的 R ...
- Visual Studio 2022 开发 STM32 单片机 - 环境搭建点亮LED灯
安装VS2022社区版软件 选择基础的功能就好 安装VisualGDB软件(CSDN资源) 按照提示一步一步安装就好 VisualGDB激活软件(CSDN资源) 将如下软件放在VisualGDB的安装 ...
- 通用 HTTP 签名组件的另类实现
1.初衷 开发中经常需要做一些接口的签名生成和校验工作,最开始的时候都是每个接口去按照约定单独实现,久而久之就变的非常难维护,因此就琢磨怎么能够写了一个比较通用的签名生成工具. 2.思路 采用链式调用 ...
- 制造业数字化转型,本土云ERP系统如何卡位?
去标准化,主打个性化,方可在制造业数字化转型中大放异彩,本土云ERP要想获得青睐成功卡位必须坚持这个原则.为什么这么说?就连某头部ERP厂商都倡导一个观念"Rise With.......& ...
- NSIS使用API创建工具提示条和超级链接
不再借助专用插件创建超级链接和工具提示条 !includensDialogs.nsh #编写:水晶石 Name "link_tooltips" OutFile "link ...
- POJ2763 Housewife Wind (树链剖分)
差不多是模板题,不过要注意将边权转化为点权,将边的权值赋给它所连的深度较大的点. 这样操作过后,注意查询ask()的代码有所改变(见代码注释) 1 #include<cstdio> 2 # ...
- KMP模式匹配 学习笔记
功能 能在线性时间内判断字符串\(A[1~N]\)是否为字符串\(B[1~M]\)的子串,并求出字符串\(A\)在字符串\(B\)中各次出现的位置. 实现 1.对字符串\(A\)进行自我"匹 ...
- Docker | redis集群部署实战
前面已经简单熟悉过redis的下载安装使用,今天接着部署redis集群(cluster),简单体会一下redis集群的高可用特性. 环境准备 Redis是C语言开发,安装Redis需要先将Redis的 ...