(三)elasticsearch 源码之启动流程分析
1.前面我们在《(一)elasticsearch 编译和启动》和 《(二)elasticsearch 源码目录 》简单了解下es(elasticsearch,下同),现在我们来看下启动代码
下面是启动流程图,我们按照流程图的顺序依次描述
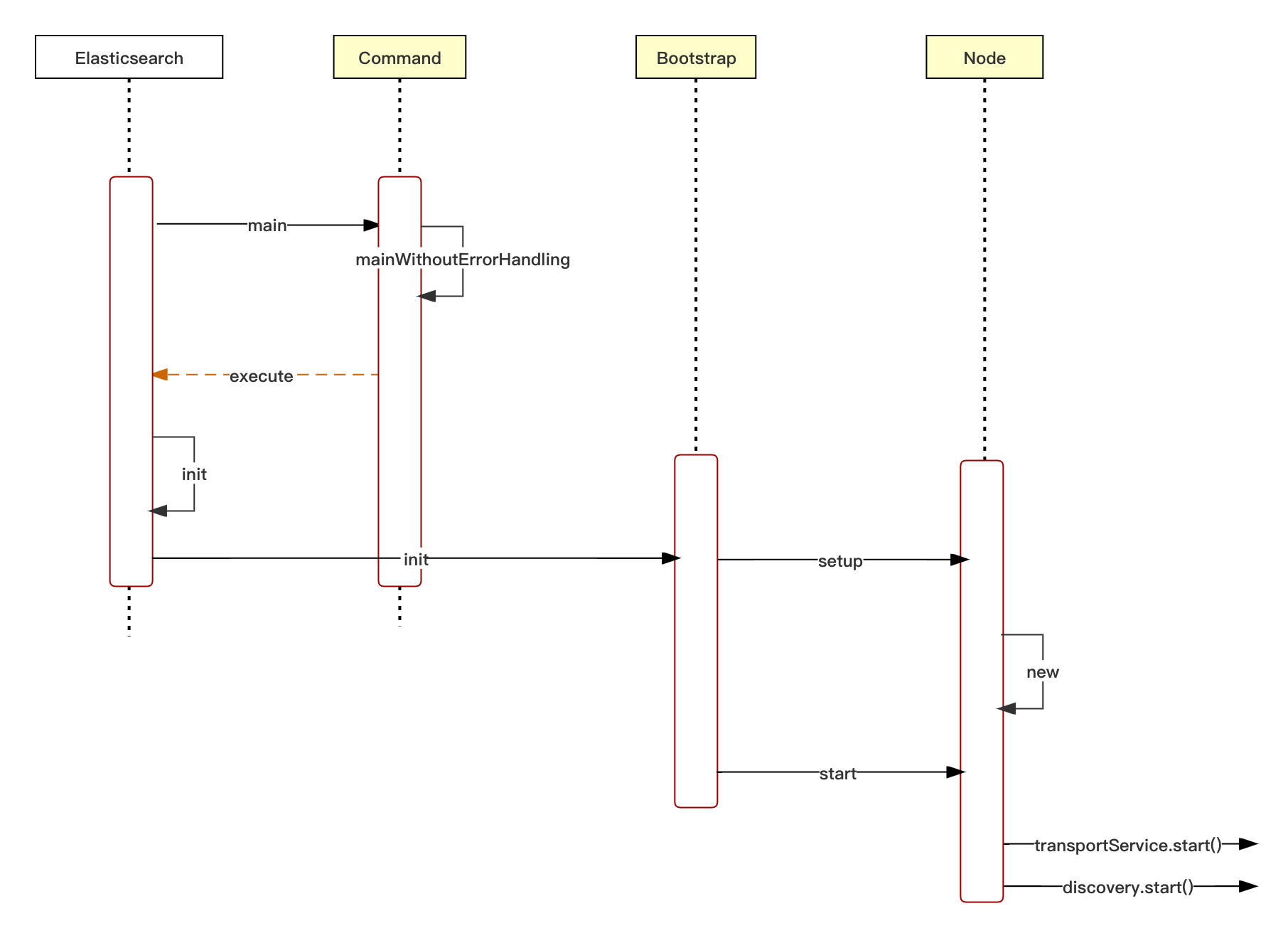
2.启动流程
org.elasticsearch.bootstrap.Elasticsearch
public static void main(final String[] args) throws Exception {
overrideDnsCachePolicyProperties();
/*
* We want the JVM to think there is a security manager installed so that if internal policy decisions that would be based on the
* presence of a security manager or lack thereof act as if there is a security manager present (e.g., DNS cache policy). This
* forces such policies to take effect immediately.
*/
System.setSecurityManager(new SecurityManager() {
@Override
public void checkPermission(Permission perm) {
// grant all permissions so that we can later set the security manager to the one that we want
}
});
LogConfigurator.registerErrorListener();
final Elasticsearch elasticsearch = new Elasticsearch();
int status = main(args, elasticsearch, Terminal.DEFAULT);
if (status != ExitCodes.OK) {
exit(status);
}
}后续执行 Elasticsearch.execute -> Elasticsearch.init -> Bootstrap.init
org.elasticsearch.bootstrap.Bootstrap
static void init(
final boolean foreground,
final Path pidFile,
final boolean quiet,
final Environment initialEnv) throws BootstrapException, NodeValidationException, UserException {
// force the class initializer for BootstrapInfo to run before
// the security manager is installed
BootstrapInfo.init();
INSTANCE = new Bootstrap();
// 安全配置文件
final SecureSettings keystore = loadSecureSettings(initialEnv);
final Environment environment = createEnvironment(pidFile, keystore, initialEnv.settings(), initialEnv.configFile());
LogConfigurator.setNodeName(Node.NODE_NAME_SETTING.get(environment.settings()));
try {
LogConfigurator.configure(environment);
} catch (IOException e) {
throw new BootstrapException(e);
}
if (JavaVersion.current().compareTo(JavaVersion.parse("11")) < 0) {
final String message = String.format(
Locale.ROOT,
"future versions of Elasticsearch will require Java 11; " +
"your Java version from [%s] does not meet this requirement",
System.getProperty("java.home"));
new DeprecationLogger(LogManager.getLogger(Bootstrap.class)).deprecated(message);
}
// 处理pidFile
if (environment.pidFile() != null) {
try {
PidFile.create(environment.pidFile(), true);
} catch (IOException e) {
throw new BootstrapException(e);
}
}
// 如果是后台启动,则不打印日志
final boolean closeStandardStreams = (foreground == false) || quiet;
try {
if (closeStandardStreams) {
final Logger rootLogger = LogManager.getRootLogger();
final Appender maybeConsoleAppender = Loggers.findAppender(rootLogger, ConsoleAppender.class);
if (maybeConsoleAppender != null) {
Loggers.removeAppender(rootLogger, maybeConsoleAppender);
}
closeSystOut();
}
// fail if somebody replaced the lucene jars
checkLucene();
// 通用异常捕获
// install the default uncaught exception handler; must be done before security is
// initialized as we do not want to grant the runtime permission
// setDefaultUncaughtExceptionHandler
Thread.setDefaultUncaughtExceptionHandler(new ElasticsearchUncaughtExceptionHandler());
INSTANCE.setup(true, environment);
try {
// any secure settings must be read during node construction
IOUtils.close(keystore);
} catch (IOException e) {
throw new BootstrapException(e);
}
INSTANCE.start();
if (closeStandardStreams) {
closeSysError();
}
}这里我们可以关注下 INSTANCE.setup(true, environment);
org.elasticsearch.bootstrap.Bootstrap
private void setup(boolean addShutdownHook, Environment environment) throws BootstrapException {
Settings settings = environment.settings();
try {
spawner.spawnNativeControllers(environment);
} catch (IOException e) {
throw new BootstrapException(e);
}
// 检查一些mlock设定
initializeNatives(
environment.tmpFile(),
BootstrapSettings.MEMORY_LOCK_SETTING.get(settings),
BootstrapSettings.SYSTEM_CALL_FILTER_SETTING.get(settings),
BootstrapSettings.CTRLHANDLER_SETTING.get(settings));
// 探针
// initialize probes before the security manager is installed
initializeProbes();
if (addShutdownHook) {
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
try {
IOUtils.close(node, spawner);
LoggerContext context = (LoggerContext) LogManager.getContext(false);
Configurator.shutdown(context);
if (node != null && node.awaitClose(10, TimeUnit.SECONDS) == false) {
throw new IllegalStateException("Node didn't stop within 10 seconds. " +
"Any outstanding requests or tasks might get killed.");
}
} catch (IOException ex) {
throw new ElasticsearchException("failed to stop node", ex);
} catch (InterruptedException e) {
LogManager.getLogger(Bootstrap.class).warn("Thread got interrupted while waiting for the node to shutdown.");
Thread.currentThread().interrupt();
}
}
});
}
try {
// 检查类加载的一些问题
// look for jar hell
final Logger logger = LogManager.getLogger(JarHell.class);
JarHell.checkJarHell(logger::debug);
} catch (IOException | URISyntaxException e) {
throw new BootstrapException(e);
}
// Log ifconfig output before SecurityManager is installed
IfConfig.logIfNecessary();
// 安全处理
// install SM after natives, shutdown hooks, etc.
try {
Security.configure(environment, BootstrapSettings.SECURITY_FILTER_BAD_DEFAULTS_SETTING.get(settings));
} catch (IOException | NoSuchAlgorithmException e) {
throw new BootstrapException(e);
}
node = new Node(environment) {
@Override
protected void validateNodeBeforeAcceptingRequests(
final BootstrapContext context,
final BoundTransportAddress boundTransportAddress, List<BootstrapCheck> checks) throws NodeValidationException {
BootstrapChecks.check(context, boundTransportAddress, checks);
}
};
}最后一句 node = new Node(environment) 初始化了节点,里面做了许多工作
org.elasticsearch.node.Node
protected Node(
final Environment environment, Collection<Class<? extends Plugin>> classpathPlugins, boolean forbidPrivateIndexSettings) {
...
// 打印jvm信息
final JvmInfo jvmInfo = JvmInfo.jvmInfo();
logger.info(
"version[{}], pid[{}], build[{}/{}/{}/{}], OS[{}/{}/{}], JVM[{}/{}/{}/{}]",
Build.CURRENT.getQualifiedVersion(),
jvmInfo.pid(),
Build.CURRENT.flavor().displayName(),
Build.CURRENT.type().displayName(),
Build.CURRENT.hash(),
Build.CURRENT.date(),
Constants.OS_NAME,
Constants.OS_VERSION,
Constants.OS_ARCH,
Constants.JVM_VENDOR,
Constants.JVM_NAME,
Constants.JAVA_VERSION,
Constants.JVM_VERSION);
...
// 初始化各类服务,以及他们相关的依赖
this.pluginsService = new PluginsService(tmpSettings, environment.configFile(), environment.modulesFile(),
environment.pluginsFile(), classpathPlugins);
final Settings settings = pluginsService.updatedSettings();
final Set<DiscoveryNodeRole> possibleRoles = Stream.concat(
DiscoveryNodeRole.BUILT_IN_ROLES.stream(),
pluginsService.filterPlugins(Plugin.class)
.stream()
.map(Plugin::getRoles)
.flatMap(Set::stream))
.collect(Collectors.toSet());
DiscoveryNode.setPossibleRoles(possibleRoles);
localNodeFactory = new LocalNodeFactory(settings, nodeEnvironment.nodeId());
...
// guice注入
modules.add(b -> {
b.bind(Node.class).toInstance(this);
b.bind(NodeService.class).toInstance(nodeService);
b.bind(NamedXContentRegistry.class).toInstance(xContentRegistry);
b.bind(PluginsService.class).toInstance(pluginsService);
b.bind(Client.class).toInstance(client);
b.bind(NodeClient.class).toInstance(client);
b.bind(Environment.class).toInstance(this.environment);
b.bind(ThreadPool.class).toInstance(threadPool);es 使用 guice注入框架,guice是个非常轻量级的依赖注入框架,既然各个组件都已经注入好了,我们现在可以启动了。
INSTANCE.start -> Bootstrap.start
org.elasticsearch.bootstrap.Bootstrap
private void start() throws NodeValidationException {
node.start();
keepAliveThread.start();
}node.start中启动各个组件。es中的各个组件继承了 AbstractLifecycleComponent。start方法会调用组件的doStart方法。
org.elasticsearch.node.Node
public Node start() throws NodeValidationException {
if (!lifecycle.moveToStarted()) {
return this;
}
logger.info("starting ...");
pluginLifecycleComponents.forEach(LifecycleComponent::start);
injector.getInstance(MappingUpdatedAction.class).setClient(client);
injector.getInstance(IndicesService.class).start();
injector.getInstance(IndicesClusterStateService.class).start();
injector.getInstance(SnapshotsService.class).start();
injector.getInstance(SnapshotShardsService.class).start();
injector.getInstance(SearchService.class).start();
nodeService.getMonitorService().start();
final ClusterService clusterService = injector.getInstance(ClusterService.class);
final NodeConnectionsService nodeConnectionsService = injector.getInstance(NodeConnectionsService.class);
nodeConnectionsService.start();
clusterService.setNodeConnectionsService(nodeConnectionsService);
...具体的我们看两个比较重要的服务 transportService.start();
org.elasticsearch.transport.TransportService
@Override
protected void doStart() {
transport.setMessageListener(this);
connectionManager.addListener(this);
// 建立网络连接
transport.start();
if (transport.boundAddress() != null && logger.isInfoEnabled()) {
logger.info("{}", transport.boundAddress());
for (Map.Entry<String, BoundTransportAddress> entry : transport.profileBoundAddresses().entrySet()) {
logger.info("profile [{}]: {}", entry.getKey(), entry.getValue());
}
}
localNode = localNodeFactory.apply(transport.boundAddress());
if (connectToRemoteCluster) {
// here we start to connect to the remote clusters
remoteClusterService.initializeRemoteClusters();
}
}启动transport的实现类是 SecurityNetty4HttpServerTransport
另一个比较重要的服务,discovery.start(),具体实现类是 Coordinator
org.elasticsearch.cluster.coordination.Coordinator
@Override
protected void doStart() {
synchronized (mutex) {
CoordinationState.PersistedState persistedState = persistedStateSupplier.get();
coordinationState.set(new CoordinationState(getLocalNode(), persistedState, electionStrategy));
peerFinder.setCurrentTerm(getCurrentTerm());
configuredHostsResolver.start();
final ClusterState lastAcceptedState = coordinationState.get().getLastAcceptedState();
if (lastAcceptedState.metaData().clusterUUIDCommitted()) {
logger.info("cluster UUID [{}]", lastAcceptedState.metaData().clusterUUID());
}
final VotingConfiguration votingConfiguration = lastAcceptedState.getLastCommittedConfiguration();
if (singleNodeDiscovery &&
votingConfiguration.isEmpty() == false &&
votingConfiguration.hasQuorum(Collections.singleton(getLocalNode().getId())) == false) {
throw new IllegalStateException("cannot start with [" + DiscoveryModule.DISCOVERY_TYPE_SETTING.getKey() + "] set to [" +
DiscoveryModule.SINGLE_NODE_DISCOVERY_TYPE + "] when local node " + getLocalNode() +
" does not have quorum in voting configuration " + votingConfiguration);
}
...(三)elasticsearch 源码之启动流程分析的更多相关文章
- 渣渣菜鸡的 ElasticSearch 源码解析 —— 启动流程(下)
关注我 转载请务必注明原创地址为:http://www.54tianzhisheng.cn/2018/08/12/es-code03/ 前提 上篇文章写完了 ES 流程启动的一部分,main 方法都入 ...
- 渣渣菜鸡的 ElasticSearch 源码解析 —— 启动流程(上)
关注我 转载请务必注明原创地址为:http://www.54tianzhisheng.cn/2018/08/11/es-code02/ 前提 上篇文章写了 ElasticSearch 源码解析 -- ...
- Android4.0源码Launcher启动流程分析【android源码Launcher系列一】
最近研究ICS4.0的Launcher,发现4.0和2.3有稍微点区别,但是区别不是特别大,所以我就先整理一下Launcher启动的大致流程. Launcher其实是贯彻于手机的整个系统的,时时刻刻都 ...
- Netty 源码学习——客户端流程分析
Netty 源码学习--客户端流程分析 友情提醒: 需要观看者具备一些 NIO 的知识,否则看起来有的地方可能会不明白. 使用版本依赖 <dependency> <groupId&g ...
- hadoop源码_hdfs启动流程_3_心跳机制
hadoop在启动namenode和datanode之后,两者之间是如何联动了?datanode如何向namenode注册?如何汇报数据?namenode又如何向datanode发送命令? 心跳机制基 ...
- vue2源码框架和流程分析
vue整体框架和主要流程分析 之前对看过比较多关于vue源码的文章,但是对于整体框架和流程还是有些模糊,最后用chrome debug对vue的源码进行查看整理出这篇文章.... 本文对vue的整体框 ...
- Chromium源码--网络请求流程分析
转载请注明出处:http://www.cnblogs.com/fangkm/p/3784660.html 本文探讨一下chromium中加载URL的流程,具体来说是从地址栏输入URL地址到通过URLR ...
- hadoop源码_hdfs启动流程_2_DataNode
执行start-dfs.sh脚本后,集群是如何启动的? 本文阅读并注释了start-dfs脚本,以及datanode的启动主要流程流程源码. DataNode 启动流程 脚本代码分析 start-df ...
- Spring源码解析02:Spring IOC容器之XmlBeanFactory启动流程分析和源码解析
一. 前言 Spring容器主要分为两类BeanFactory和ApplicationContext,后者是基于前者的功能扩展,也就是一个基础容器和一个高级容器的区别.本篇就以BeanFactory基 ...
- Spring源码解析 | 第二篇:Spring IOC容器之XmlBeanFactory启动流程分析和源码解析
一. 前言 Spring容器主要分为两类BeanFactory和ApplicationContext,后者是基于前者的功能扩展,也就是一个基础容器和一个高级容器的区别.本篇就以BeanFactory基 ...
随机推荐
- Java一次返回中国所有省市区三级树形级联+前端vue展示【200ms内】
一.前言 中国省市区还是不少的,省有34个,市有391个,区有1101个,这是以小编的库里的,可能不是最新的,但是个数也差不了多少. 当一次返回所有的数据,并且还要组装成一个三级树,一般的for,会循 ...
- 华为路由器RIP路由协议配置命令
RIP路由协议配置 rip 创建开启协议进程 network + ip 对指定网段接口使能RIP功能IP地址是与路由器直连的网段 debugging rip 1 查看RIP定期更新情况 termina ...
- vue路由守卫用于登录验证权限拦截
vue路由守卫用于登录验证权限拦截 vue路由守卫 - 全局(router.beforeEach((to, from, next) =>来判断登录和路由跳转状态) 主要方法: to:进入到哪个路 ...
- 11.pygame飞机大战游戏整体代码
主程序 # -*- coding: utf-8 -*- # @Time: 2022/5/20 22:26 # @Author: LiQi # @Describe: 主程序 import pygame ...
- golang中的锁竞争问题
索引:https://www.waterflow.link/articles/1666884810643 当我们打印错误的时候使用锁可能会带来意想不到的结果. 我们看下面的例子: package ma ...
- JSP Webshell免杀设计
JSP Webshell免杀设计 @author:drag0nf1y 介绍 什么是Webshell? 被服务端解析执行的php.jsp文件 什么是RCE? remote command execute ...
- Vue 实现小小记事本
1.实现效果 用户输入后按回车,输入的内容自动保存,下方会显示记录的条数,鼠标移动到文字所在div上,会显示删除按钮,点击按钮,相应记录会被删除,下方的记录条数会相应变化,点击clear,所有记录会被 ...
- ISCTF2022WP
ISCTF2022改名叫套CTF吧(bushi),博主菜鸡一个,套题太多,挑一些题写下wp,勿喷. MISC 可爱的emoji 下载下来是个加密压缩包,根据hint掩码爆破密码 得到密码:KEYI ...
- 16.python中的回收机制
python中的垃圾回收机制是以引用计数器为主,标记清除和分代回收为辅的 + 缓存机制 1.引用计数器 在python内部维护了一个名为refchain的环状双向链表,在python中创建的任何对象都 ...
- Bugku 字符?正则?
打开是一段中规中矩的php代码 先读一下代码 高亮文件2.php 定义变量key 定义变量IM其值是一个正则表达式匹配的结果 如果IM是真就输出key 所以这道题的关键也就是IM正则匹配的结果了,我们 ...