Jenkins搭建与数据迁移实践
概述
本文主要介绍内容如下:
1.使用Docker搭建Jenkins
2.迁移原Jenkins数据到新搭建的Jenkins中
3.在Jenkins容器内部配置Maven的私服配置
4.在Jenkins容器内部配置Nodejs
使用Docker搭建Jenkins
Jenkins的最新版本已经全面支持jdk11,由于项目原因我们还是jdk8的钉子户,所以本次安装的Jenkins版本我们选择支持jdk8的最新版本。
拉取镜像与运行容器的命令如下:
docker pull jenkins/jenkins:lts-centos7-jdk8 docker run -d --name jenkins -u root -p 8081:8080 -p 50000:50000 --restart=always -v /home/jenkins_home/:/var/jenkins_home -v /usr/bin/docker:/usr/bin/docker -v /var/run/docker.sock:/var/run/docker.sock -v /etc/localtime:/etc/localtime:ro jenkins/jenkins:lts-centos7-jdk8
目录映射中/home/jenkins_home/目录中的内容会在容器第一次启动时自动生成,它映射的是Jenkins的工作目录。
/usr/bin/docker与/var/run/docker.sock的映射可以让容器使用宿主机的docker命令,用来协助构建操作。
运行后,在浏览器中通过ip:8081即可访问Jenkins工作台,首次进入工作台需要输入管理员的初始密码,
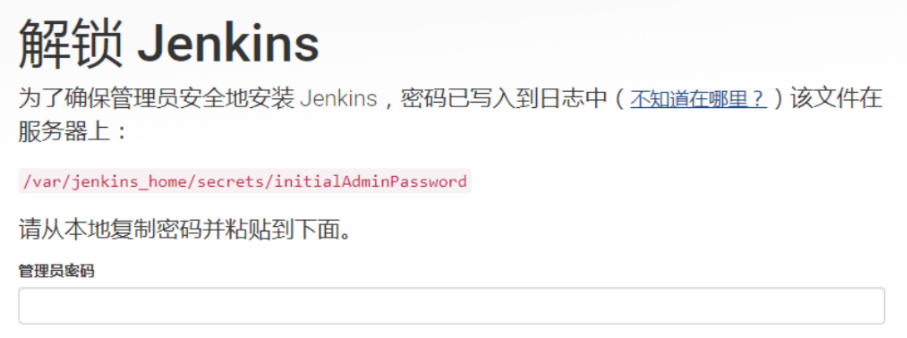
初始密码我们可以在宿主机的/home/jenkins_home/secrets/initialAdminPassword文件中获得。
输入密码后,如果顺利的话,会进入插件安装页面,我们选择安装推荐的插件等待安装完成即可。
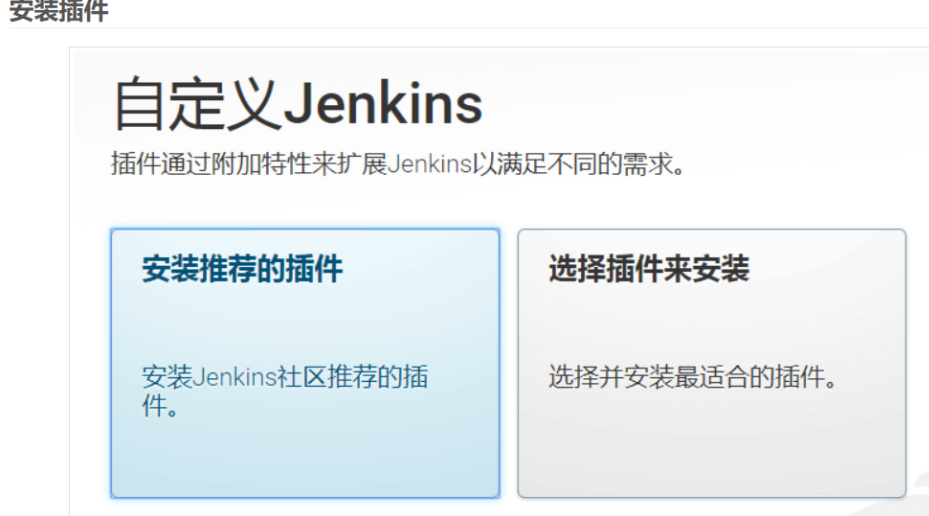
但是你有可能遇到下面的情况:
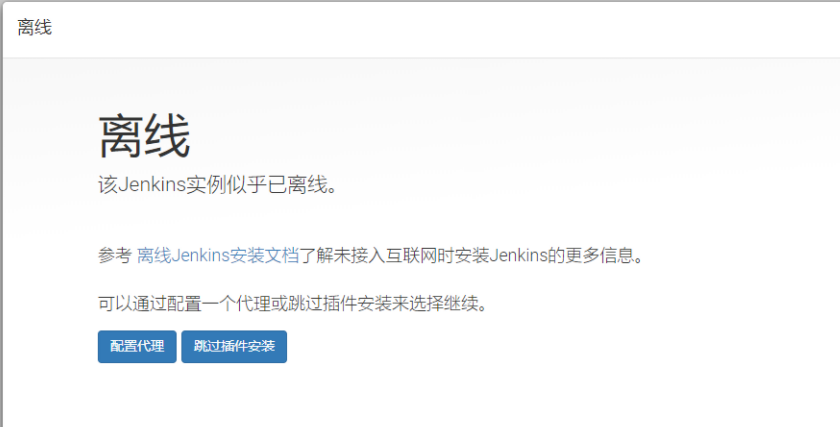
如何解决呢?
首先确认一下你的服务器本身是肯定有网的,而且服务器的防火墙是开启的状态。
防火墙是否开启可以用以下命令观察:
firewall-cmd --state
如果以上条件成立,我们可以执行一下下边的命令
#开启 NAT 转发
firewall-cmd --permanent --zone=public --add-masquerade
#检查是否允许 NAT 转发
firewall-cmd --query-masquerade
firewall-cmd --reload
之后再重新启动你的Jenkins容器,再次观察是否已经解决了问题。
如果还没有解决问题,就需要你自己来寻找原因了。
那为什么执行这样的命令后,就可以让容器可以连接网络了呢?这就要说到docker的网络模式了。
我们运行jenkins容器时没有指定容器的网络,所以容器会以默认的bridge模式启动,bridge模式我们可以把它类比成Vmvare虚拟的nat网络模式,到这里你应该就明白了,firewall防火墙在开启的时候,如果不开启nat转发,容器内部当然就无法借助nat的手段连接网络了。
当然,如果你的服务器不需要防火墙,完全可以关闭防火墙来解决问题,不过关闭防火墙之后,需要重新启动docker服务后,docker才可以正常运行,命令如下:
systemctl stop firewalld.service #停止firewall
systemctl restart docker #重启docker
或者还有一种解决方式,就是在docker run命令的后边加上--net=host参数,来指定docker的网络模式为host模式,使用host网络模式后,不再需要端口映射,且无法实现端口映射,所以容器出现端口冲突的情况。
至此,我们的Jenkins就搭建完成了。
迁移原Jenkins数据到新搭建的Jenkins中
现在我们假设你原理就已经拥有了一个Jenkins,并且已经运行了很久,想要把运行的数据备份和恢复到我们新部署的Jenkins中,如何操作呢?
Jenkins本身其实是提供了备份插件的,我们在Jenkins中安装ThinBackup插件即可实现。
安装成功后,可以在系统管理中找到插件的入口:
进入后页面如下:

首先进入settings修改配置中的备份目录为/var/jenkins_home/bak

我们可以在宿主机的/home/jenkins_home目录下创建bak目录,用来存放备份文件。
其他配置建议如下,可自行调整:
配置保存后,回到插件页面,点击backup now,即可在宿主机的/home/jenkins_home/bak目录中发现备份文件,
我们将此备份文件拷贝到另一个jenkins的备份目录下,即可通过点击restore进行恢复的操作。
恢复完成后,需要重新启动jenkins容器。
在Jenkins容器内部配置Maven的私服配置
如果我们的项目中使用了maven私服,需要修改maven的setting.xml文件。
maven的安装方式有以下两种:
1.使用yum install maven一键安装
2.去官网下载maven手动安装,具体过程本文不介绍
无论选择了哪种安装方式,我们都可以通过mvn -v命令查找到maven的安装目录,在其中可以找到setting.xml文件,在其中配置私服即可。
在Jenkins容器内部配置Nodejs
nodejs的安装其实在容器内部和外部是没有区别的
到官网https://nodejs.org/en/download/releases/下载指定的版本即可,这里由于项目原因,我们选择了Node.js 14.21.2版本
下载node-v14.21.2-linux-x64.tar.gz,复制到宿主机的/home/jenkins_home/node/中。
进入容器内部,解压后,执行如下命令,创建软连接
ln -s /var/jenkins_home/node/node-v14.21.2-linux-x64/bin/node /usr/bin
ln -s /var/jenkins_home/node/node-v14.21.2-linux-x64/bin/npm /usr/bin
ln -s /var/jenkins_home/node/node-v14.21.2-linux-x64/bin/npx /usr/bin
ln -s /var/jenkins_home/node/node-v14.21.2-linux-x64/bin/corepack /usr/bin
即可完成node的安装,
如果需要使用yarn命令和pnpm命令,可以执行corepack enable命令来开启。
至此,nodejs安装完成。
Jenkins搭建与数据迁移实践的更多相关文章
- 利用Kettle进行SQLServer与Oracle之间的数据迁移实践
Kettle简介 Kettle(网地址为http://kettle.pentaho.org/)是一款国外开源的ETL工具,纯java编写,可以在Windows.Linux.Unix上运行,数据抽取高效 ...
- ubuntu 下 mysql数据库的搭建 及 数据迁移
1.mysql的安装 我是使用apt-get直接安装的 :sudo apt-get install mysql-server sudo apt-get install mysql-client 2.配 ...
- kafka数据迁移实践
欢迎大家前往云+社区,获取更多腾讯海量技术实践干货哦~ 作者:mikealzhou 本文重点介绍kafka的两类常见数据迁移方式:1.broker内部不同数据盘之间的分区数据迁移:2.不同broker ...
- mysql搭建及数据迁移教程
1.如果jumbo不存在,先安装jumbo 参考 http://hetu.baidu.com/api/tool/show?toolId=174: bash -c "$( curl htt ...
- confluence6.3.1部署+数据迁移
目录: 环境准备 搭建方法 数据迁移 搭建过程中的bug 1,confluence部署 1.1,环境准备 Java:jdk1.8 mysql: 数据库编码规则选择utf8 -- UTF-8 Unico ...
- SQL SERVER几种数据迁移/导出导入的实践
SQLServer提供了多种数据导出导入的工具和方法,在此,分享我实践的经验(只涉及数据库与Excel.数据库与文本文件.数据库与数据库之间的导出导入). (一)数据库与Excel 方法1: 使用数据 ...
- Jenkins修改默认主目录及数据迁移
前言 在使用Jenkins做持续集成的初期,未能预估项目量的大小.于是乎,配置都是使用的默认配置,而Jenkins的默认主目录放在了服务器的根目录下. 随着时间的推移,项目量的持续增加,在运维过程中就 ...
- Kafka数据迁移MaxCompute最佳实践
摘要: 本文向您详细介绍如何使用DataWorks数据同步功能,将Kafka集群上的数据迁移到阿里云MaxCompute大数据计算服务. 前提条件 搭建Kafka集群 进行数据迁移前,您需要保证自己的 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 巨杉数据库数据高性能数据导入迁移实践
SequoiaDB 一款自研金融级分布式数据库产品,支持标准SQL和分布式事务功能.支持复杂索引查询,兼容 MySQL.PGSQL.SparkSQL等SQL访问方式.SequoiaDB 在分布式存储功 ...
- 大数据平台迁移实践 | Apache DolphinScheduler 在当贝大数据环境中的应用
大家下午好,我是来自当贝网络科技大数据平台的基础开发工程师 王昱翔,感谢社区的邀请来参与这次分享,关于 Apache DolphinScheduler 在当贝网络科技大数据环境中的应用. 本次演讲主要 ...
随机推荐
- 源码级深度理解 Java SPI
作者:vivo 互联网服务器团队- Zhang Peng SPI 是一种用于动态加载服务的机制.它的核心思想就是解耦,属于典型的微内核架构模式.SPI 在 Java 世界应用非常广泛,如:Dubbo. ...
- Linux环境下执行脚本重启Weblogic控制台中部署的应用程序
之前有写过一篇博文介绍切换登录方式的脚本,脚本中存在一个缺点:仍需手动去Weblogic控制台重启应用程序:本文即介绍如何在脚本中更新Weblogic控制台中部署的应用程序. 一.配置Weblogic ...
- 记一次HTTPClient模拟登录获取Cookie的开发历程
记一次HTTPClient模拟登录获取Cookie的开发历程 环境: springboot : 2.7 jdk: 1.8 httpClient : 4.5.13 设计方案 通过新建一个 ...
- [排序算法] 堆排序 (C++)
堆排序解释 什么是堆 堆 heap 是一种近似完全二叉树的数据结构,其满足一下两个性质 1. 堆中某个结点的值总是不大于(或不小于)其父结点的值: 2. 堆总是一棵完全二叉树 将根结点最大的堆叫做大根 ...
- C温故补缺(十三):可变参数
可变参数 stdarg.h 头文件提供了实现可变参数功能的函数和宏.具体步骤如下: 定义一个函数,最后一个参数为省略号,省略号前面可以设置自定义参数,一般传入参数的个数. int func(int n ...
- ElasticSearch7.6.1学习笔记-狂神
ElasticSearch:7.6.1 https://gitee.com/yujie.louis/elastic-search 笔记,代码,安装包等 什么是ElasticSearch? Elasti ...
- 关于CSDN发布博客接口的研究
前言 其实我之前就有一个想法,实现用 python 代码来发布博客, 因为我个人做了一个发布到 github 博客软件(其实就是实现 git 命令集成,还有markdown的渲染的软件), 如果我弄明 ...
- Idea中Git的常用操作及可能存在的问题
一.使用 1.从git上下载项目 (1)默认branch下载(pull) (2)指定branch下载 (3)克隆远程仓库到本地(git clone) git clone https://github. ...
- java 如何正确使用接口返回对象Result
1. Result的使用 Result的使用,是java项目中开发接口的必备,它经常被我们用作接口的返回对象,方便前端或者其他程序的远程调用后处理业务.它一般包括以下几个属性: code:一般根据系统 ...
- 重学c#系列——linq(3) [二十九]
前言 继续介绍一些复杂的linq. 正文 groupjoin 这个函数: 有department public class Deployment { public string Id { get; s ...