【HashMap】浅析HashMap的构造方法及put方法(JDK1.7)
引言
数据结构中,Hash的核心是使用一个hash函数将值映射到一个地址上,在后续查找的时候再通过这个hash函数计算得到这个地址。所以理想情况下Hash查找的时间复杂度是O(1)。
但是hash映射有可能会有冲突,两个不同的值,通过hash函数算出来的地址相同。比如,hash函数是:x%5,则5和10通过这个函数计算得到的地址都是0。这种情况就被称为hash冲突。
常见的Hash冲突解决办法有开放地址法、再哈希法、链地址法。
Hash函数+Hash冲突解决方法 就构成了一套hash算法
JDK1.7的HashMap的Hash函数是一个位运算计算公式:h & (length-1)。(下文会解释这个公式)
JDK1.7的HashMap的Hash冲突解决办法是:链地址法。
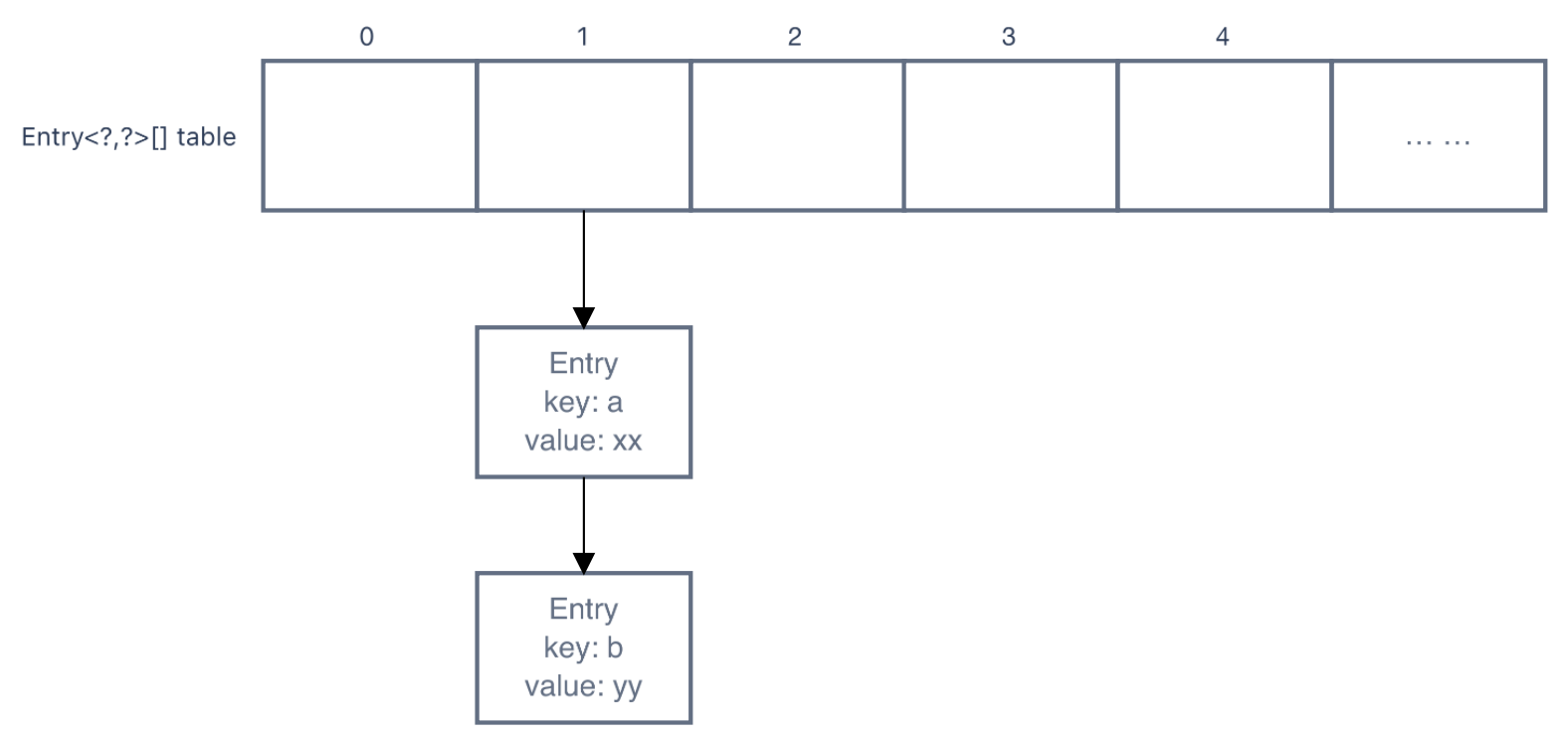
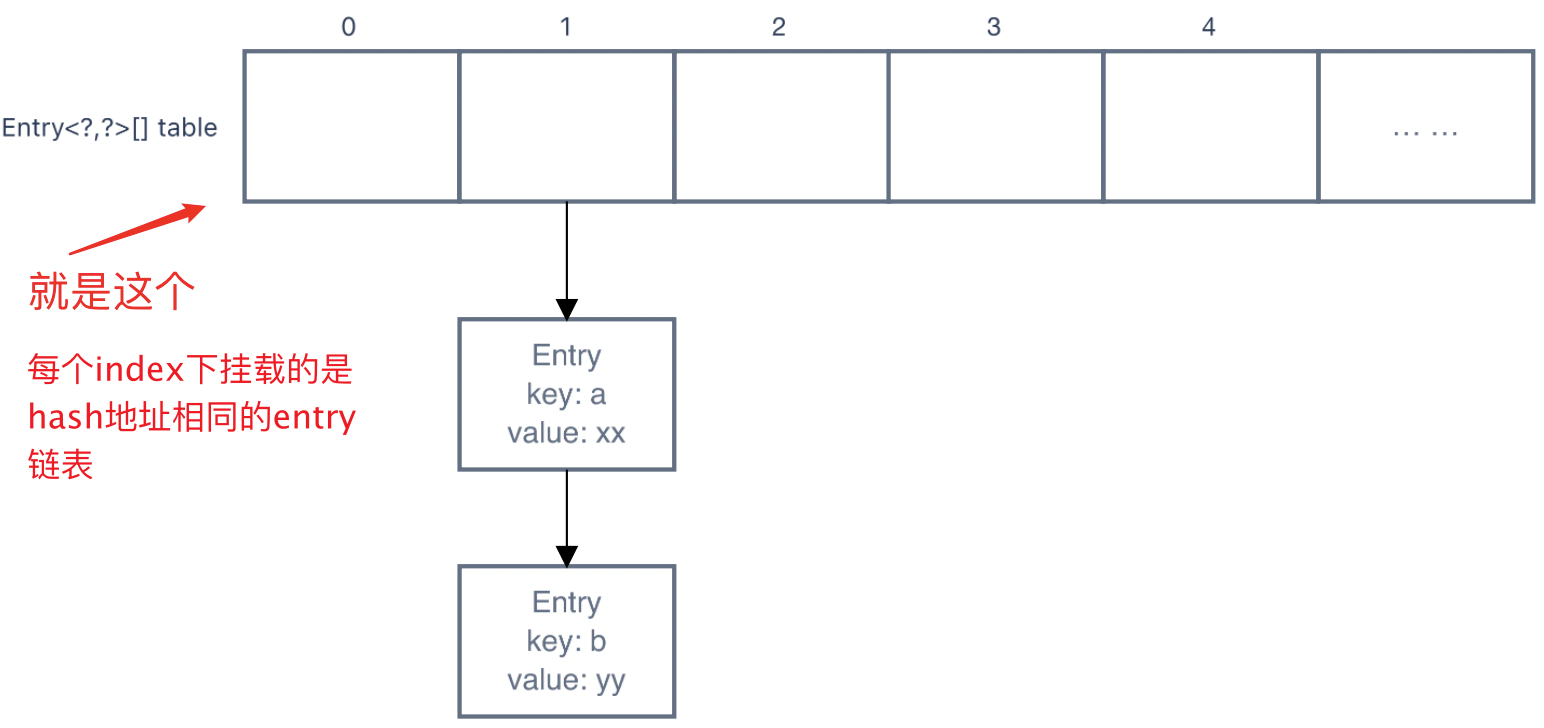
Ps.链地址法就是将所有hash地址相同的entry都挂在地址下,形如:
所以可以看出,查找hash地址相同的节点需要一个个遍历,时间复杂度为n,效率很低。
所以在1.8中该用了红黑树,红黑树是一个插入、查找时间复杂度都约为logn的数据结构,很大程度上提升了查找的性能。
代码讲解
属性
Entry<?,?>[] table
int size:map中键值对的数量int threshold:table进行扩容的一个阈值,定义map中有多少元素时,map快满了。map size大于这个阈值,则有可能会对table进行扩容float loadFactor:计算threshold的一个因子(threshold = table.length * loadFactor),默认值为0.75int modCount:map中节点数的变更次数,一种类似乐观锁的机制。每次会影响map中的size的操作,都会使
modCount++。然后遍历map时,会先拿到此时的modCount,然后在遍历每个节点的时候去对比map的modCount和之前拿到的是否一致,如果不一致则说明有线程在你遍历的时候修改了map,所以就会抛出
ConcurrentModificationException。int hashSeed:计算hash的一个参数key的hashcode会和hash seed做与运算,然后结果再进行一系列位运算,最终得到hash值。
然后再把hash值放进hash函数进行计算,得到hash地址
HashMap的空参构造方法
public HashMap() {
// DEFAULT_INITIAL_CAPACITY -> 1 << 4,即为16
// DEFAULT_LOAD_FACTOR -> 0.75
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor) {
// initial capcity 不能小于0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// initial capacity 最大为:1 << 30,即2的30次方
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 校验loadFactor
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// 此时会让threshhold暂存initial capacity
// 在第一次put时,会扩充table,扩充的值为:>=threshold的最小2次幂数,threshold值会变为 table.length*loadFactor
// 所以虽然最初threshold是存的table的init capacity,但是在第一次put时就会让threshold回归其本来的作用(设置一个扩张table的阈值)
threshold = initialCapacity;
// 空的方法
init();
}
HashMap的put方法
put
public V put(K key, V value) {
// 如果table为空,则扩充table
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 放null值
if (key == null)
return putForNullKey(value);
// 根据key计算得到hash值
int hash = hash(key);
// 哈希函数:根据hash值计算得到在table中的下标(使用位运算)
int i = indexFor(hash, table.length);
// 得到下标所在的链表的表头
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)table[i];
// 遍历链表
for(; e != null; e = e.next) {
Object k;
// 如果链表中的当前项和要插入的值相同,则使用新的值替换旧的值
// hash值同 && key同(引用的是同一个对象 或 equals)
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// -------到此处说明table中原本没有节点的key和当前节点的key一样-------
// 将map节点的修改次数++
modCount++;
// 使用头插法添加一个节点
addEntry(hash, key, value, i);
return null;
}
inflateTable
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
// 找到最小的,大于2次幂的数。toSize为17,则capacity为32
int capacity = roundUpToPowerOf2(toSize);
// 为threshhold、table赋值
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry<?,?>[capacity];
// 修改hashSeed
initHashSeedAsNeeded(capacity);
}
initHashSeedAsNeeded
final boolean initHashSeedAsNeeded(int capacity) {
// hashSeed初始为0,所以初始currentAltHashing为false
boolean currentAltHashing = hashSeed != 0;
// vm是否启动?
// 如无特殊设置,Holder.ALTERNATIVE_HASHING_THRESHOLD值为Integer.MAX_VALUE。一般capacity不会这么大
// 所以useAltHashing一般为false
boolean useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
// 如上面分析的,switching一般都为false,不会修改hashSeed
boolean switching = currentAltHashing ^ useAltHashing;
if (switching) {
hashSeed = useAltHashing
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}
putForNullKey
private V putForNullKey(V value) {
// 把null key放到table的第一个item下
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)table[0];
for(; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// -------到此处说明table中原本没有null key-------
modCount++;
// 把null key的hash值直接定义为0
// 所以它是放在table的第一个item下
addEntry(0, null, value, 0);
return null;
}
hash
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
// key的hashcode会和hash seed做与运算
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
indexFor
static int indexFor(int h, int length) {
// hash()计算得到的hash值,和table的length做并运算
// 若table length为16,则:
//
// Case1.
// h = 20 0001 0100
// length-1 = 15 0000 1111
// ---------
// index = 8 0000 0100
//
// Case2.
// h = 78 0100 1110
// length-1 = 15 0000 1111
// ---------
// index = 14 0000 1110
//
// 这就是为什么table的capacity必须是2次幂的原因,因为hash函数需要用capacity-1的值做位运算
return h & (length-1);
}
addEntry
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果当前table的length超过阈值,并且table[bucketIndex]上已有节点,则扩充table
if ((size >= threshold) && (null != table[bucketIndex])) {
// 生成一个capacity是原来两倍的table,然后将原来的table拷贝过去(重新计算hash)
resize(2 * table.length);
// 重新计算hash(resize中可能会改变hashSeed的值)
hash = (null != key) ? hash(key) : 0;
// 重新计算在hash在table中index
bucketIndex = indexFor(hash, table.length);
}
// 创建节点(使用头插法)
createEntry(hash, key, value, bucketIndex);
}
resize
void resize(int newCapacity) {
Entry<?,?>[] oldTable = table;
int oldCapacity = oldTable.length;
// 原来的table已经达到了最大值(2的30次方),不扩容了
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 生成一个capacity为原来2倍的table
Entry<?,?>[] newTable = new Entry<?,?>[newCapacity];
// 把原来table中的entry挪到新table中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 替换table
table = newTable;
// 更新threshhold
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
transfer
void transfer(Entry<?,?>[] newTable, boolean rehash) {
Entry<?,?>[] src = table;
int newCapacity = newTable.length;
// 遍历原来table的每个节点
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = (Entry<K,V>)src[j];
// 遍历table下链表的每个entry
while(null != e) {
Entry<K,V> next = e.next;
// 是否重新计算hash值(如果hashSeed改变了,就需要重新计算hash值)
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 计算在新table中的的下标
// 根据indexFor()中计算下标的公式"h & (length-1)"可知
// 新下标要么和原来一样,要么是原来的下标+原来table的size
// 如:
// Case1.
// 原来table中的下标:
// h = 20 0001 0100
// length-1 = 15 0000 1111
// ---------
// index = 4 0000 0100
//
// 新table中的下标.
// h = 20 0001 0100
// length-1 = 31 0001 1111
// ---------
// index = 20 0001 0100
//
// Case2.
// 原来table中的下标:
// h = 78 0100 1110
// length-1 = 15 0000 1111
// ---------
// index = 14 0000 1110
//
// 新table中的下标:
// h = 78 0100 1110
// length-1 = 31 0001 1111
// ---------
// index = 14 0000 1110
//
int i = indexFor(e.hash, newCapacity);
e.next = (Entry<K,V>)newTable[i];
newTable[i] = e;
e = next;
}
}
}
复制的过程:

createEntry
void createEntry(int hash, K key, V value, int bucketIndex) {
// 头插法,过程和resize类似(差别就在于,没有循环e)
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
总结
JDK1.7中HashMap的hash算法:
- Hash函数:位运算计算公式:
h & (length-1) - Hash冲突解决办法:链地址法(插入方法:头插法)
JDK1.7中HashMap中的数据结构和算法还是很标准的基础数据结构,包括链表的头插法,也是链表的基础插入方法。将table的构建过程,和链表的插入方法模拟过一遍后,就能够理解这个对象的底层计算逻辑了。
HashMap为了增加运算的速度,用了很多位运算,主要用于hash值的计算,和hash地址的计算。
HashMap性能上的痛点在于:
- 链表的查找是简单的顺序查找,时间复杂度是n。这点在JDK1.8中改为了查找更快的树形数据结构——红黑树
- 扩容很耗费时间(需要遍历一遍将原来table中的所有entry,然后挪到另一个table中),所以开发时定义合适的初始大小能够提升性能
【HashMap】浅析HashMap的构造方法及put方法(JDK1.7)的更多相关文章
- 【ConcurrentHashMap】浅析ConcurrentHashMap的构造方法及put方法(JDK1.7)
目录 引言 代码讲解 构造方法 put方法 ensureSegment Segment.put 引言 ConcurrentHashMap的数据结构如下. 和HashMap的最大区别在于多了一层Segm ...
- Java集合框架之HashMap浅析
Java集合框架之HashMap浅析 一.HashMap综述: 1.1.HashMap概述 位于java.util包下的HashMap是Java集合框架的重要成员,它在jdk1.8中定义如下: pub ...
- == 和 equals,equals 与 hashcode,HashSet 和 HashMap,HashMap 和 Hashtable
一:== 和 equals == 比较引用的地址equals 比较引用的内容 (Object 类本身除外) String obj1 = new String("xyz"); Str ...
- [Java] 遍历HashMap和HashMap转换成List的两种方式
遍历HashMap和HashMap转换成List /** * convert the map to the list(1) */ public static void main(String[] ...
- Java基础知识强化之集合框架笔记62:Map集合之HashMap嵌套HashMap
1. HashMap嵌套HashMap 传智播客 jc 基础班 陈玉楼 20 高跃 ...
- PHP面向对象的构造方法与析构方法
构造方法与析构方法是对象中的两个特殊方法,它们都与对象的生命周期有关.构造方法时对象创建完成后第一个被对象自动调用的方法,这是我们在对象中使用构造方法的原因.而析构方法时对象在销毁之前最后一个被对象自 ...
- Java中构造方法跟普通方法的区别?
构造方法与普通方法的调用时机不同. 首先在一个类中可以定义构造方法与普通方法两种类型的方法,但是这两种方法在调用时有明显的区别. 1.构造方法是在实例化新对象(new)的时候只调用一次 2.普通方法是 ...
- 2、转载一篇,浅析人脸检测之Haar分类器方法
转载地址http://www.cnblogs.com/ello/archive/2012/04/28/2475419.html 浅析人脸检测之Haar分类器方法 [补充] 这是我时隔差不多两年后, ...
- 怎样理解JAVA的“构造方法”和“主方法”
在类中除了成员方法之外,还存在一种特殊类型的方法,那就是构造方法.主方法是类的入口点,它定义了程序从何处开始: 主方法提供对程序流向的控制,Java编译器通过主方法来执行程序.那么,下面一起来看一下关 ...
随机推荐
- Error running 'App': Command line is too long. Shorten command line for App or also for Spring Boot default configuration.
找到标签 <component name="PropertiesComponent">.在标签里加一行 : <property name="dynam ...
- js的json序列化和反序列化
(1)序列化 即js中的Object转化为字符串 1.使用toJSONString var last=obj.toJSONString(); //将JSON对象转化为JSON字符 2.使用string ...
- Spring 由哪些模块组成?
以下是 Spring 框架的基本模块:第 393 页 共 485 页 Core module Bean module Context module Expression Language module ...
- memcached 能够更有效地使用内存吗?
Memcache 客户端仅根据哈希算法来决定将某个 key 存储在哪个节点上,而不考 虑节点的内存大小.因此,您可以在不同的节点上使用大小不等的缓存.但是一 般都是这样做的:拥有较多内存的节点上可以运 ...
- Python - dict类型
- 集合学习之"将集合对象List<Product>转换为Map"
将集合对象List<Product>转换为Map key = Product对象的sku value =Product对象 1 List<Product> products = ...
- 罗振宇2022"时间的朋友"跨年演讲
罗振宇2022"时间的朋友"跨年演讲 行就行,不行我再想想办法. 原来,还能这么干! 堆资源不是解决问题的唯一道路,还是那句话:"处于困境中的人往往只关注自己的问题.而解 ...
- html5系列:form 2.0 新结构
以往的一个form表单,结构比较死板,所有的form元素都必须处在<form>和</form>之间才有效,这会造成一些麻烦,比如说:像bootstrap这种使用<div& ...
- 打造专属自己的html5拼图小游戏
最近公司刚好有个活动是要做一版 html5的拼图小游戏,于是自己心血来潮,自己先实现了一把,也算是尝尝鲜了.下面就把大体的思路介绍一下,希望大家都可以做出一款属于自己的拼图小游戏,必须是更炫酷,更好玩 ...
- web页面性能优化之接口前置
上个Q做了一波web性能优化,积累了一点点经验 记录分享一下. 先分享一个比较常用的接口前置 的优化方案吧 优化前首屏秒开大约在40%左右 首屏秒开大约提高了25% 先发一张优化成果图 前置原因 对于 ...