Neo4J之Cypher 第三章
Cypher是一种声明式图形查询语言,可用于表达性和高效的图形查询和更新。它旨在同时适合开发人员和运营专业人员。Cypher的设计既简单又强大。可以轻松表达高度复杂的数据库查询,使您可以专注于自己的域,而不会迷失在数据库访问中。
Cypher的结构基于英文散文和简洁的图像,使查询既易于编写,也易于阅读。
子句链接在一起,并且它们相互之间提供中间结果集。例如,来自一个MATCH子句的匹配变量将是存在下一个子句的上下文。查询语言由几个不同的子句组成。
MATCH:要匹配的图形模式。这是从图形中获取数据的最常用方法。WHERE:在自己的权利不是一个条款,但相当一部分MATCH,OPTIONAL MATCH和WITH。向模式添加约束,或过滤通过的中间结果WITH。RETURN:返回什么。
制造数据
CREATE (john:Person {name: 'John'})
CREATE (joe:Person {name: 'Joe'})
CREATE (steve:Person {name: 'Steve'})
CREATE (sara:Person {name: 'Sara'})
CREATE (maria:Person {name: 'Maria'})
CREATE (john)-[:FRIEND]->(joe)-[:FRIEND]->(steve)
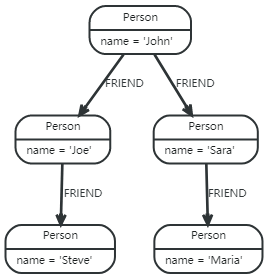
例如,这是一个查询,该查询在返回“约翰”和找到的任何朋友之前,先找到一个名为“约翰”和“约翰的”朋友(虽然不是他的直接朋友)的用户。
MATCH (john {name: 'John'})-[:FRIEND]->()-[:FRIEND]->(fof)
RETURN john.name, fof.name
示例二:添加过滤条件的查询
找到所有关注过朋友的用户,并返回他们关注的朋友中以S开头的人的名字
MATCH (user)-[:FRIEND]->(follwer)
WHERE user.name IN ['Joe', 'John', 'Sara'] AND
follwer.name =~ 'S.*'
RETURN user.name, follwer.name
3.1.1模式Patterns
Neo4j图由节点和关系构成。节点可能还有标签和属性,关系可能还有类型和属性。节点表达实体,关系连接一对节点。节点可以看做关系型数据库中的表,但有一些不一样。节点的标签可以理解为不同的表名,属性类似数据库中的列,一个节点的数据类型类似关系数据库中的一行数据,拥有相同标签的节点通常具有类似的属性,但不必完全一样,这点和关系数据库中一张表中的行数据拥有相同列的是不一样的。
节点和模式都是低层次的构建块,单个节点或关系都只能表示很少的信息,但是模型可以将很多节点和关系编码为任意复杂的想法
3.1.2.1节点语法
() 匿名节点 可以匹配所有节点,如果想在其余地方引用这个节点,可以添加一个变量,如(matrix)
-- :表示无方向关系
-->:有方向关系
-[rale]->:给关系赋予一个变量,方便对其操作
-[rale:friend]->:匹配关系类型为friend类型的关系,并赋予rale变量接收
-[rale:friend {long_time:2}]->:给关系加条件,匹配friend类型的关系且属性long_time为2
3.1.2.3 模式语法
将节点和关系的语法组合在一起可以表达模式
(keanu:Person:Actor {name: "Keanu Reeves"})-[role:ACTED_IN {roles: ["Neo"]}]->
(matrix:Movie {title: "The Matrix"})
3.1.2.4模式变量:
同时如果想要关系语法不想重复写,想要多个语句写的时候减少重复写,可以将关系语法赋予一个变量
acted_in = (people:Person)-[:acted_in]->(movie:Movie)
这样acted_in 就可以写到多个查询语句中,减少重复编写
3.1.3.1更新语句
一个Cypher查询部分不能同时匹配和更新图数据,每个部分要么读取和匹配图,要么更新它,如果需要读取并且更新图
它需要两部分:读取和更新.
对于读取,Cypher采用惰性加载,直到需要返回结果的时候才实际的去匹配数据.
with用来连接这两部分
使用with语句进行聚合过滤查询,示例:
MATCH (n {name:"John"})-[:friend]-(friend)
WITH n, count(friend) as friendsCount
WHERE friendsCount>3
RETURN n, friendsCount
使用with语句进行聚合更新,示例:
MATCH (n {name:'John'})-[:friend]-(friend)
WITH n,count(friend) as friendsCount
SET n.friendsCount = friendsCount
RETURN n.friendsCount
3.1.3.2返回数据
任何查询都可以返回数据.RETURN语句有三个子句,分别为SKIP,LIMIT和ORDER BY
3.1.4事务
任何更新图的查询都运行在一个事务中,一个更新查询要么全部成功,要么全部失败
Cypher要么新创建一个事务,要么运行在一个已有的事务中:
如果上下文中没有事务,Cypher将会创建一个,一旦查询完成就提交该事务
如果运行上下文中已有事务,查询就会运行在该事务之中.直到事务成功提交之后,数据才会被存储
可以将多个查询作为单个事务去运行,保证数据正常
注意:事务中的查询结果是放在内存中的,一个事务如果查询量巨大会造成内存的大量使用
3.1.5唯一性
进行模式匹配时,默认不会多次匹配同一个图关系.比如匹配John朋友的朋友,不会将John自己也返回给John
示例:
1.先准备数据
在模式匹配时,neo4j确保不会在单个模式中多次找到相同图形关系的匹配。举例,在寻找朋友的朋友时,不会返回所述用户自身。
CREATE (adam:User { name: 'Adam' }),(pernilla:User { name: 'Pernilla' }),(david:User { name: 'David'}),(adam)-[:FRIEND]->(pernilla),(pernilla)-[:FRIEND]->(david)
寻找Adam朋友的朋友
MATCH (user:User { name: 'Adam' })-[r1:FRIEND]-()-[r2:FRIEND]-(friend_of_a_friend)
RETURN friend_of_a_friend.name AS fofName
因为r1和r2在同一个模式中,又是不同的变量名,所以不会返回同一条关系,即图形中的有向边。检验:在两个子句中用不同的变量名就不管用
MATCH (user:User { name: 'Adam' })-[r1:FRIEND]-(friend)
MATCH (friend)-[r2:FRIEND]-(friend_of_a_friend)
RETURN friend_of_a_friend.name AS fofName
但是只要在一个模式中,即使拆分了多个子模式也不会匹配到同一关系,如下所示。
MATCH (user:User { name: 'Adam' })-[r1:FRIEND]-(friend),(friend)-[r2:FRIEND]-(friend_of_a_friend)
RETURN friend_of_a_friend.name AS fofName
3.1.6兼容性
设置Cypher查询的版本
Neo4j数据库的Cypher也是会进行版本变化的.
可以在neo4j.conf配置中cypher.default_language_version 参数来设置Neo4j数据库使用哪个版本的Cypher语言
如果只是想在一个查询中指定版本,可以在查询语句的开头地方写上版本
比如:
Cypher 2.3
match(n) return(n)
目前的版本有3.1 3.0 2.3
Neo4J之Cypher 第三章的更多相关文章
- Neo4j使用Cypher查询图形数据
Neo4j使用Cypher查询图形数据,Cypher是描述性的图形查询语言,语法简单,功能强大,由于Neo4j在图形数据库家族中处于绝对领先的地位,拥有众多的用户基数,使得Cypher成为图形查询语言 ...
- 《Django By Example》第三章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:第三章滚烫出炉,大家请不要吐槽文中 ...
- 《Linux内核设计与实现》读书笔记 第三章 进程管理
第三章进程管理 进程是Unix操作系统抽象概念中最基本的一种.我们拥有操作系统就是为了运行用户程序,因此,进程管理就是所有操作系统的心脏所在. 3.1进程 概念: 进程:处于执行期的程序.但不仅局限于 ...
- Python黑帽编程3.0 第三章 网络接口层攻击基础知识
3.0 第三章 网络接口层攻击基础知识 首先还是要提醒各位同学,在学习本章之前,请认真的学习TCP/IP体系结构的相关知识,本系列教程在这方面只会浅尝辄止. 本节简单概述下OSI七层模型和TCP/IP ...
- 《Entity Framework 6 Recipes》中文翻译系列 (11) -----第三章 查询之异步查询
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 第三章 查询 前一章,我们展示了常见数据库场景的建模方式,本章将向你展示如何查询实体 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (19) -----第三章 查询之使用位操作和多属性连接(join)
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 3-16 过滤中使用位操作 问题 你想在查询的过滤条件中使用位操作. 解决方案 假 ...
- 《python核心编》程课后习题——第三章
核心编程课后习题——第三章 3-1 由于Python是动态的,解释性的语言,对象的类型和内存都是运行时确定的,所以无需再使用之前对变量名和变量类型进行申明 3-2原因同上,Python的类型检查是在运 ...
- 精通Web Analytics 2.0 (5) 第三章:点击流分析的奇妙世界:指标
精通Web Analytics 2.0 : 用户中心科学与在线统计艺术 第三章:点击流分析的奇妙世界:指标 新的Web Analytics 2.0心态:搞定它.新的闪亮系列工具:是的.准备好了吗?当然 ...
- 数据结构与算法分析——C语言描述 第三章的单链表
数据结构与算法分析--C语言描述 第三章的单链表 很基础的东西.走一遍流程.有人说学编程最简单最笨的方法就是把书上的代码敲一遍.这个我是头文件是照抄的..c源文件自己实现. list.h typede ...
- Java语言程序设计(基础篇) 第三章 选择
第三章 选择 3.8 计算身体质量指数 package com.chapter3; import java.util.Scanner; public class ComputeAndInterpret ...
随机推荐
- 前端如何实现将多页数据合并导出到Excel单Sheet页解决方案|内附代码
前端与数据展示 前后端分离是当前比较盛行的开发模式,它使项目的分工更加明确,后端负责处理.存储数据;前端负责显示数据.前端和后端开发人员通过接口进行数据的交换.因此前端最重要的能力是需要将数据呈现给用 ...
- http八股 跨域的本质 请求行 请求头 请求体 xss
1小八股 介绍 http 请求分为三个部分,请求行,请求头,请求体 还有状态码的含义 https://juejin.cn/post/7096317903200321544 2tips Content- ...
- Class path contains multiple SLF4J bindings解决
1.根据控制台查看冲突的日志依赖 本工程Maven依赖 <dependencies> <dependency> <groupId>org.slf4j</gro ...
- 乌卡时代的云成本管理:从0到1了解FinOps
在上一篇文章中,我们介绍了企业云业务的成本构成以及目前面临的成本困境,以及当前企业逐步转向 FinOps 的行业趋势,这篇文章我们将详细聊聊 FinOps,包括概念.重要性以及成熟度评价指标. 随着对 ...
- JZOJ 3479. 工作安排
\(\text{solution}\) 比较显然的 \(dp\) 顺序既然无所谓,那为了方便处理贡献,就先排个序 然后设 \(f_i\) 表示分到前 \(i\) 个的最小工资 则 \(f_i=C+f_ ...
- 抗TNF治疗改变JIA患者PBMC基因表达谱,可预测疗效
抗TNF治疗改变JIA患者PBMC基因表达谱,可预测疗效 Moorthy LN, et al. ACR 2007. Presentation No:1713. 背景:我们假设儿童期发生的特发性关节炎( ...
- 《爆肝整理》保姆级系列教程-玩转Charles抓包神器教程(8)-Charles如何进行断点调试
1.简介 Charles和Fiddler一样也有个强大的功能,可以修改发送到服务器的数据包,但是修改前需要拦截,即设置断点.设置断点后,开始拦截接下来所有网页,直到取消断点.这个功能可以在数据包发送之 ...
- 从NLP视角看电视剧《狂飙》,会有什么发现?
目录 1.背景 2.数据获取 3.文本分析与可视化 3.1 短评数据预处理 3.2 词云图可视化 3.3 top关键词共现矩阵网络 3.4 <狂飙>演职员图谱构建 4.短评相关数据分析与可 ...
- 百度脑图kityminder
KityMinder Editor 是一款强大.简洁.体验优秀的脑图编辑工具,适合用于编辑树/图/网等结构的数据. 编辑器由百度 FEX 基于 kityminder-core 搭建,并且在百度脑图中使 ...
- 信息学奥赛介绍-CSP
什么是信息学奥赛 信息学奥赛,全称为信息学奥林匹克竞赛,是教育部和中国科协委托中国计算机 学会举办的一项全国青少年计算机程序设计竞赛.主要分为NOIP(全国联赛),夏令营 NOI比赛的扩展赛,也称全国 ...