论文笔记 - An Explanation of In-context Learning as Implicit Bayesian Inference
这位更是重量级。这篇论文对于概率论学的一塌糊涂的我简直是灾难。
由于 prompt 的分布与预训练的分布不匹配(预训练的语料是自然语言,而 prompt 是由人为挑选的几个样本拼接而成,是不自然的自然语言),作者设预训练的分布为 $p$ 而 prompt 的分布设为 $p_{prompt}$,因此作者认为这两种分布的不符可能是造成 inference 效果不佳的重要原因($S_n$ 为 context):
$$argmax_{y}\;p(y|S_n,\;x_{test})\;\neq argmax_{y}\;p_{prompt}(y|x_{test})$$
但是这种不匹配造成可以通过设置更好的 prompt 减弱,进而提出了 $singal$ 的概念,$singal$ 可以认为是一种任务的明确程度,$singal$ 越大代表任务越明确,得到的结果也准确,例如:一般情况下,One-shot 的效果要比 Few-shot 和 Zero-shot 都要差,例如下面的prompt :
> Albert Einstein was a German. Marie Curie was <token to infer>
这个 context 根本没有明确任务是什么!按照 prompt 的分布这里应该生成的是 Polish,但是按照预训练的分布这里完全可以填 brilliant 什么的,也就是两种分布不匹配的程度被大大放大了。但是如果换成 Few-shot 呢:
> Albert Einstein was German. Mahatma Gandhi was Indian. Karl Heinrich Marx was German. Marie Curie was <token to infer>
这个 context 就很好的描述了任务的目的:判断这些人所属的国家。因此,作为 context 的样本数量增加可以有效增加 $singal$,缩小两种分布的不匹配程度,进而改善效果。
作者进一步总结了几个对 $singal$ 有影响的因素
样本数量
如上文所述,样本越多任务描述越清晰,$singal$ 越大。
输入空间
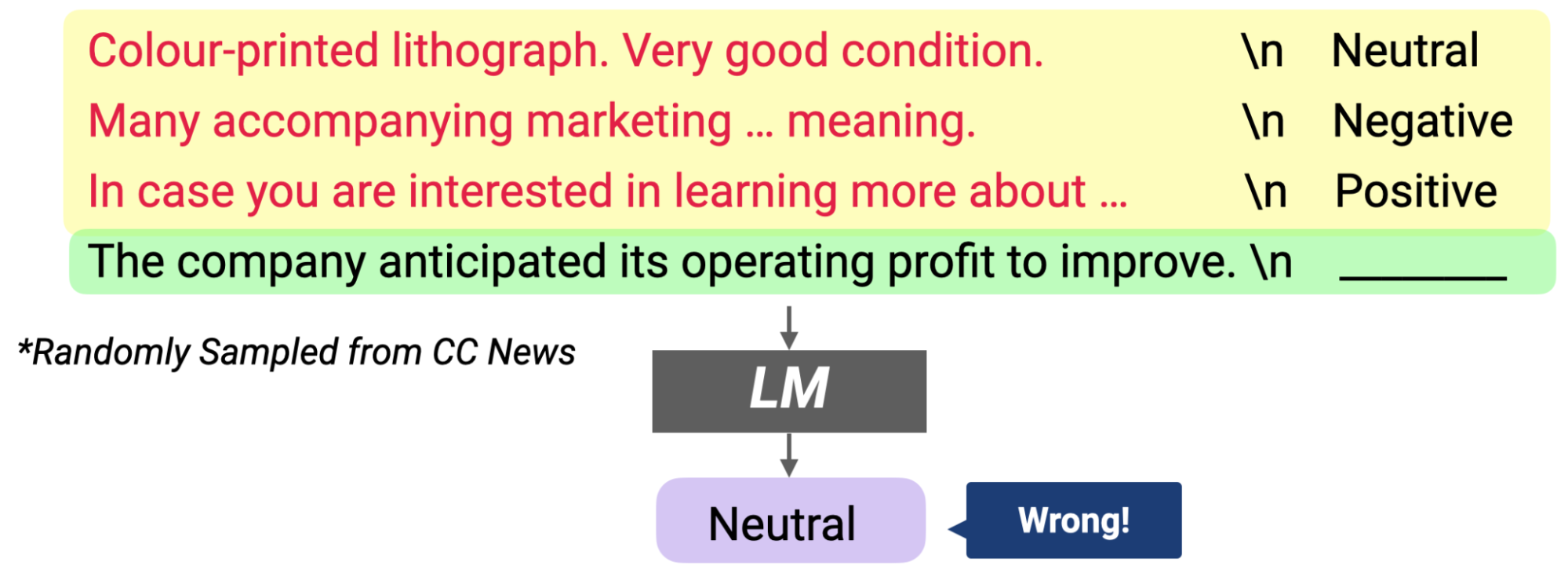
x 随便选的话会使准确率大幅度降低。
输出空间

y 随便选的话也会使准确率大幅度降低。
输入输出的对应关系
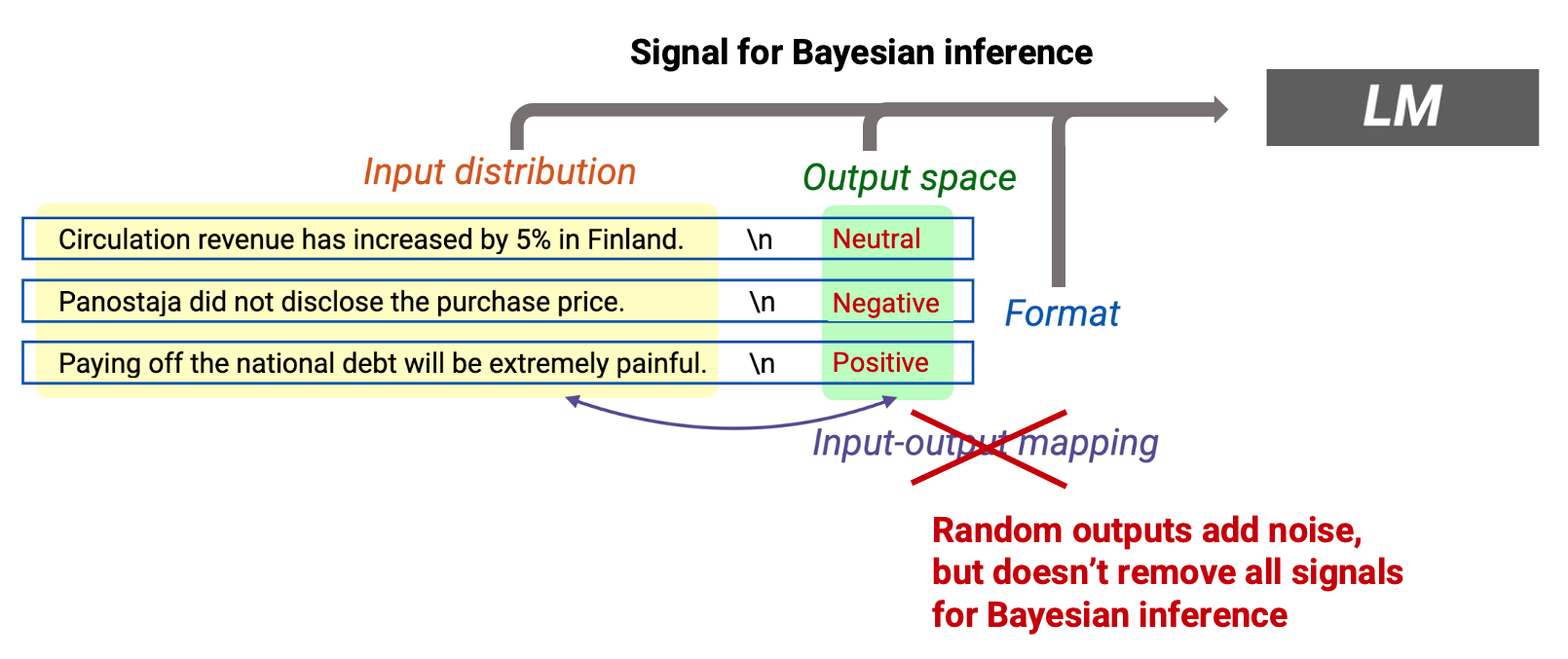
输出的标签在输出空间里面随机选取,对准确率有影响但是没有想象中那么大,进而证明了对 in-context learning 更重要的因素是任务描述,而不是提供的 prompt 是否正确(因为答案错误并没有影响这个任务的目的:情感分类)。
为了使用数学工具进行分析,作者将前文中提到的任务描述定义为 $\theta$,一篇自然语言预料可能包含多个不同的 $\theta \in \Theta$,而一个 prompt 只包含一个 $\theta^*$(例如你考虑你正在写一篇任务传记,你的任务顺序可能是:名字 $\to$ 国籍 $\to$ 职业 $\to$ 成就等包含多个任务,但是在 prompt 中任务顺序是:名字 $\to$ 国籍 $\to$ 名字 $\to$ 国籍 $\to$ 名字 $\to$ 国籍...,只在重复进行一个任务)(国籍 $\to$ 名字这个就是前文提到的分布不匹配,因为自然语言不会出现这样的分布,这种不匹配可以被有利因素补偿),同时我们认为 $\theta^* \in \Theta$(我们认为 icl 要做的任务一定在预训练的语料中出现过了)。
$$p(y|S_n,x_{test})=\int_{\theta} p(y|S_n,\;x_{test},\;\theta)p(\theta | S_n,\;x_{test})\, \mathrm{d}x$$
$$\propto\;\int_{\theta} p(y|S_n,\;x_{test},\;\theta)p(S_n,\;x_{test} | \theta)p(\theta)\, \mathrm{d}x \;\;\;\;(Bayes'\;rule,\;drop\;the\;constant\;\frac{1}{p(S_n,\;x_{test})})$$
$$\propto\; \int_{\theta} p(y|S_n,\;x_{test},\;\theta) \frac{p(S_n,\;x_{test} | \theta)}{p(S_n,\;x_{test} | \theta^*)} p(\theta)\, \mathrm{d}x\;\;\;\;(divided\;by\;a\;constant)$$
待补充。。。
论文笔记 - An Explanation of In-context Learning as Implicit Bayesian Inference的更多相关文章
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- 论文笔记《Spatial Memory for Context Reasoning in Object Detection》
好久不写论文笔记了,不是没看,而是很少看到好的或者说值得记的了,今天被xinlei这篇paper炸了出来,这篇被据老大说xinlei自称idea of the year,所以看的时候还是很认真的,然后 ...
- 论文笔记:A Review on Deep Learning Techniques Applied to Semantic Segmentation
A Review on Deep Learning Techniques Applied to Semantic Segmentation 2018-02-22 10:38:12 1. Intr ...
- 论文笔记 — MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching
论文:https://github.com/ei1994/my_reference_library/tree/master/papers 本文的贡献点如下: 1. 提出了一个新的利用深度网络架构基于p ...
- (论文笔记Arxiv2021)Walk in the Cloud: Learning Curves for Point Clouds Shape Analysis
目录 摘要 1.引言 2.相关工作 3.方法 3.1局部特征聚合的再思考 3.2 曲线分组 3.3 曲线聚合和CurveNet 4.实验 4.1 应用细节 4.2 基准 4.3 消融研究 5.总结 W ...
- 论文笔记 Spatial contrasting for deep unsupervised learning
在我们设计无监督学习模型时,应尽量做到 网络结构与有监督模型兼容 有效利用有监督模型的基本模块,如dropout.relu等 无监督学习的目标是为有监督模型提供初始化的参数,理想情况是"这些 ...
- 论文笔记之:DualGAN: Unsupervised Dual Learning for Image-to-Image Translation
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation 2017-06-12 21:29:06 引言部分: 本文提出 ...
- 【论文笔记】多任务学习(Multi-Task Learning)
1. 前言 多任务学习(Multi-task learning)是和单任务学习(single-task learning)相对的一种机器学习方法.在机器学习领域,标准的算法理论是一次学习一个任务,也就 ...
- 论文笔记——NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING
论文地址:https://arxiv.org/abs/1611.01578 1. 论文思想 强化学习,用一个RNN学一个网络参数的序列,然后将其转换成网络,然后训练,得到一个反馈,这个反馈作用于RNN ...
随机推荐
- linux下用docker安装redis
docker安装redis方法: 1.用命令来查看可用版本: docker search redis 2.拉取官方的最新版本的镜像:docker pull redis:latest 3.查看镜像:do ...
- Prometheus+Grafana监控-基于docker-compose搭建
前言 Prometheus Prometheus 是有 SoundCloud 开发的开源监控系统和时序数据库,基于 Go 语言开发.通过基于 HTTP 的 pull 方式采集时序数据,通过服务发现或静 ...
- 【小白必看】Redis手把手教你从零开始下载到安装,再到配置允许图形化工具远程连接(一)
一.Redis安装 本文暂时仅介绍Windows环境下Redis的安装. 由于Windows环境下没有.exe安装文件,这里我们使用"曲线救国"的.msi安装包帮助我们一站式解决安 ...
- [HNOI2011]卡农 (数论计数,DP)
题面 原题面 众所周知卡农是一种复调音乐的写作技法,小余在听卡农音乐时灵感大发,发明了一种新的音乐谱写规则. 他将声音分成 n n n 个音阶,并将音乐分成若干个片段.音乐的每个片段都是由 1 1 1 ...
- HDU2065 “红色病毒”问题 (指数型母函数经典板题)
题面 医学界发现的新病毒因其蔓延速度和Internet上传播的"红色病毒"不相上下,被称为"红色病毒",经研究发现,该病毒及其变种的DNA的一条单链中,胞嘧啶, ...
- Linux的NFS的配置
快速代码 # nfs的Server配置文件和配置方法 echo '/newnfs 192.168.3.*rw,sync,no_root_squash)' >> /etc/exports # ...
- 实践分享!GitLab CI/CD 快速入门
用过 GitLab 的同学肯定也对 GitLab CI/CD 不陌生,GitLab CI/CD 是一个内置在 GitLab 中的工具,它可以帮助我们在每次代码推送时运行一系列脚本来构建.测试和验证代码 ...
- 新增 Oracle 兼容函数-V8R6C4B0021
KingbaseES V8R6C4B0021新增加以下Oracle 兼容函数. 一.bin_to_num Oracle bin_to_num 函数用于将二进制位转换成十进制的数. 1.传入参数 tes ...
- B树-删除
B树系列文章 1. B树-介绍 2. B树-查找 3. B树-插入 4. B树-删除 删除 根据B树的以下两个特性 每一个非叶子结点(除根结点)最少有 ⌈m/2⌉ 个子结点 有k个子结点的非叶子结点拥 ...
- [Python]-pydicom模块处理DICOM数据
在处理医疗数据时,经常要跟DICOM文件打交道.在使用Python处理时,不得不提常用的pydicom模块. import pydicom DICOM文件读取 pydicom.read_file()读 ...