【项目实战】Kaggle泰坦尼克号的幸存者预测
前言
这是学习视频中留下来的一个作业,我决定根据大佬的步骤来一步一步完成整个项目,项目的下载地址如下:https://www.kaggle.com/c/titanic/data
大佬的传送门:https://zhuanlan.zhihu.com/p/338974416
查看数据
首先我们打开训练集,看到的数据如下

我们可以看到这个数据集里面的特征类别有,乘客序号,是否存活,船票等级,性别,年龄,在船上的亲属数量,票的号码,票价,座舱号,和登船地
所以我们需要判定哪些数据是有效的
读取数据
import re //正则表达式的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns //画图用的一个库
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
print('训练集:', train.shape, '测试集', test.shape)
total_data = train.append(test, sort=False, ignore_index=True) //需要添加的index不出现重复
可以看到我们的数据规模

然后我们查看我们数据的摘要信息
train.info()
print("-" * 40)//方便阅读输入的分隔符
test.info()
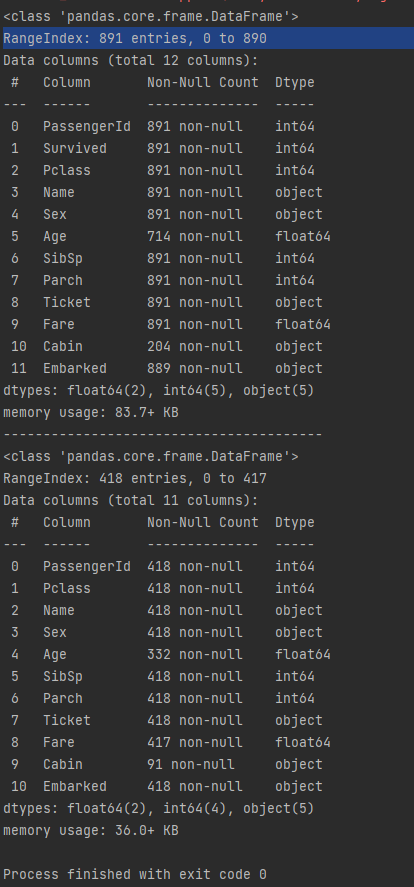
这里可以明显看出,在训练集中,年龄、座舱号、目的地有缺失值
而在测试集中,年龄、票价、座舱号有缺失值
特征工程
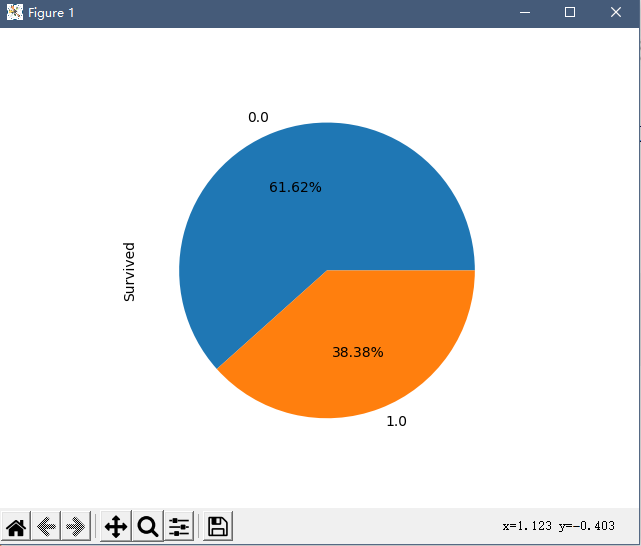
查看总体幸存比例
total_data['Survived'].value_counts().plot.pie(autopct='%1.2f%%') //这里的正则表达式表示小数点后保留两位
plt.show()
这里再查看性别与存活率的关系
print(total_data.groupby(['Sex'])['Survived'].agg(['count', 'mean'])) //groupby来挑选组别,agg定义输出列的名称
sns.countplot(x='Sex',hue= 'Survived', data=total_data)
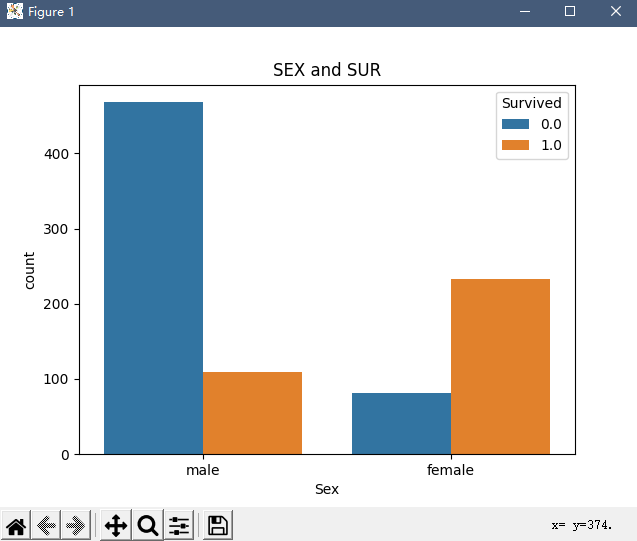
显然女性在登船率低于男性的情况下存活率远高于男性,所以性别是个很重要的特征
然后我们来看目的地对于存活率是否有影响,首先看看数据的概况
print(total_data['Embarked'].value_counts())
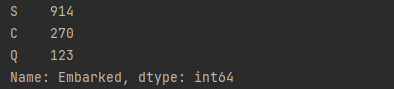
但是这里的embarked是有缺失值的,因此用众数填充Embarked空值(从哪来人最多,那就默认不知道哪里的人就从那里来里)
然后查看不同地区登船的人与存活率关系
total_data['Embarked'].fillna(
total_data.Embarked.mode().values[0], inplace=True) //TURE表示直接替换原来的值
print(total_data.groupby(['Embarked'])['Survived'].agg(['count', 'mean']))
plt.figure(figsize=(10, 5))
sns.countplot(x='Embarked', hue='Survived', data=total_data)
plt.title('Embarked and Survived')
可以看出,C地登船的存活率最高、其次为Q地登船、S地登船人数最多但存活率最低
这里Cabin缺失比较多,用Unknown替代缺失值
total_data['Cabin'].fillna('U', inplace=True)
total_data['Cabin'] = total_data['Cabin'].map(
lambda x: re.compile('([a-zA-Z]+)').search(x).group()) ///正则表达式把船票的第一个字母取出来
print(total_data.groupby(['Cabin'])['Survived'].agg(['count', 'mean']))
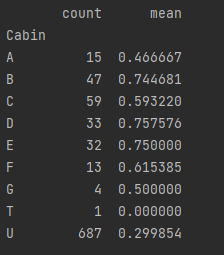
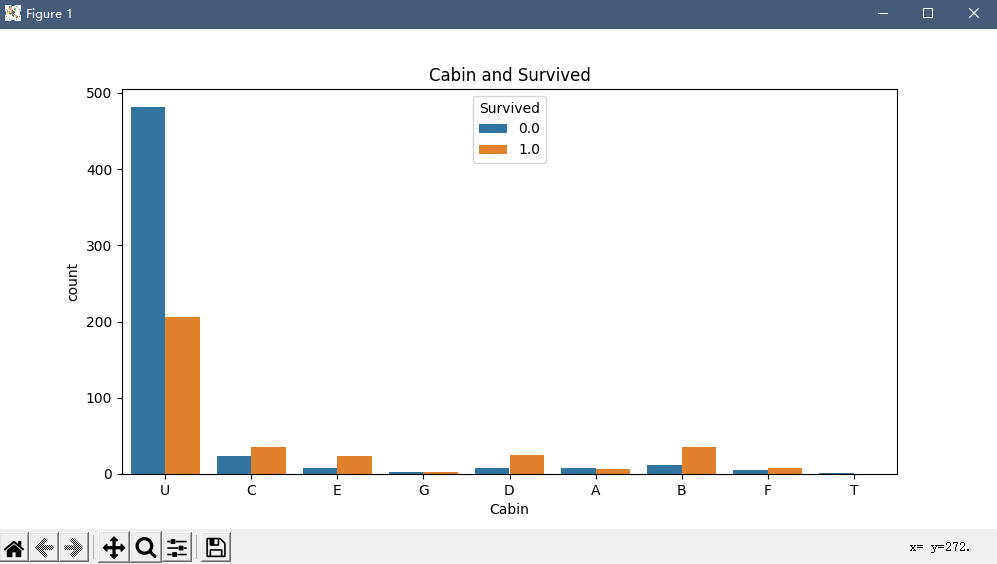
不难看出BDE的存活率比较高
再看看不同票等级生存的分布与不同票等级生存的几率
print(total_data.groupby(['Pclass'])['Survived'].agg(['count', 'mean']))
plt.figure(figsize=(10, 5))
sns.countplot(x='Pclass', hue='Survived', data=total_data)
plt.title('Pclass and Survived')
plt.show()
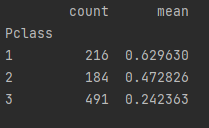
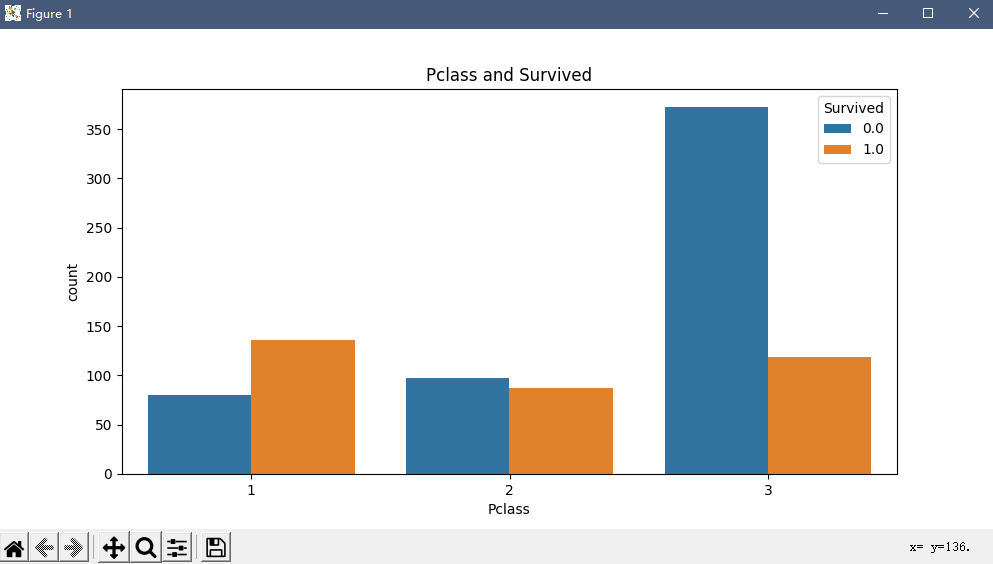
票等级越高存活率就越高
再来填充空白的票价
total_data['Fare'] = total_data[['Fare']].fillna(
total_data.groupby('Pclass').transform(np.mean)) //把票类别所在的所有票价求均值填充
来查看票价分布
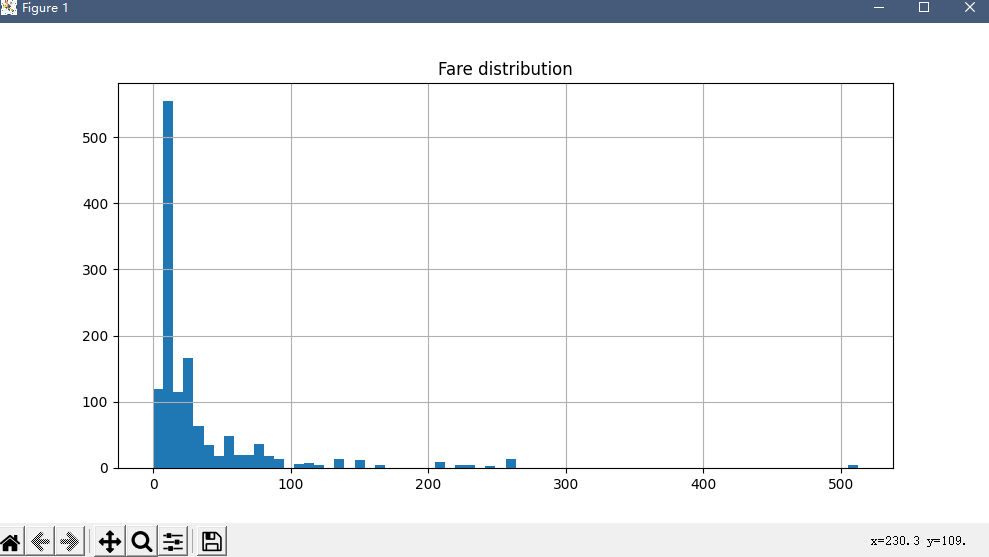
然后合并家庭人数
total_data['Family_Size'] = total_data['Parch'] + total_data['SibSp'] + 1
继续用众数填充年龄缺失值(方法不好,但是也勉强能用)
total_data['Age'].fillna(
total_data.Age.mode().values[0], inplace=True)
转变
其实做到这里发现已经做不下去了,文章给的一些处理数据方法远远超出了我的认知(巨大的打击),重新寻求一番后,发现了这个文章,适用于我来操作
https://blog.csdn.net/Learning_AI/article/details/122460458
首先我简述一下几个点,我独立在处理这些数据时有几个问题没有解决,但是文章代码给了很好的解决方案,记录一下
- 字段类型转换: 由于男女属于string类型,所以不能直接读取,我甚至想搞一个词典函数来分开读取,结果作者直接用get_dummies来转换成一个独热向量解决了,亏我还是nlp的,太尴尬了
- 选取需要的行和列: 我想了很久,在之前的代码上,把np.loadtxt改了又改加了又加,不断切片,数序号,结果根本不用这么麻烦,直接用xy全部读取,然后专门用一个feature元组存特征,再用np.array来读取,究其原因还是自己之前学numpy和pandas的时候太急了,导致自己现在菜的一,总之就是后悔,非常后悔
下面是代码部分
class TitanicDataset(Dataset):
def __init__(self, filepath):
xy = pd.read_csv(filepath)
# xy.shape()可以得到xy的行列数
self.len = xy.shape[0]
# 选取相关的数据特征
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
# np.array()将数据转换成矩阵,方便进行接下来的计算
# 要先进行独热表示,然后转化成array,最后再转换成矩阵
self.x_data = torch.from_numpy(np.array(pd.get_dummies(xy[feature])))
self.y_data = torch.from_numpy(np.array(xy["Survived"]))
# getitem函数,可以使用索引拿到数据
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
# 返回数据的条数/长度
def __len__(self):
return self.len
然后
# 实例化自定义类,并传入数据地址
dataset = TitanicDataset('train.csv')
# num_workers是否要进行多线程服务,num_worker=2 就是2个进程并行运行
# 采用Mini-Batch的训练方法
train_loader = DataLoader(dataset=dataset, batch_size=16, shuffle=True, num_workers=0)
然后来定义模型
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
# 要先对选择的特征进行独热表示计算出维度,而后再选择神经网络开始的维度
self.linear1 = torch.nn.Linear(6, 3)
self.linear2 = torch.nn.Linear(3, 1)
self.sigmoid = torch.nn.Sigmoid()
# 前馈
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
由于有测试集,所以还需要写一个测试函数
def test(self, x):
with torch.no_grad():##在使用pytorch时,并不是所有的操作都需要进行计算图的生成(计算过程的构建,以便梯度反向传播等操作)。而对于tensor的计算操作,默认是要进行计算图的构建的,在这种情况下,可以使用 with torch.no_grad():,强制之后的内容不进行计算图构建
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
y = []
# 根据二分法原理,划分y的值
for i in x:
if i > 0.5:
y.append(1)
else:
y.append(0)
return y
然后实例化模型,定义损失函数,优化器
# 实例化模型
model = Model()
# 定义损失函数
criterion = torch.nn.BCELoss(reduction='mean')
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
开始训练
if __name__ == '__main__':
# 采用Mini-Batch的方法训练要采用多层嵌套循环
# 所有数据都跑100遍
for epoch in range(400):
# data从train_loader中取出数据(取出的是一个元组数据):(x,y)
# enumerate可以获得当前是第几次迭代,内部迭代每一次跑一个Mini-Batch
for i, data in enumerate(train_loader, 0):
# inputs获取到data中的x的值,labels获取到data中的y值
x, y = data
x = x.float() //需要转换类型,不然会报错
y = y.float()
y_pred = model(x)
y_pred = y_pred.squeeze(-1) //把y降维
loss = criterion(y_pred, y)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
最后把测试集传进去
test_data = pd.read_csv('test.csv')
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
test = torch.from_numpy(np.array(pd.get_dummies(test_data[feature])))
y = model.test(test.float())
输出结果为csv
# 输出预测结果
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': y})
output.to_csv('my_predict.csv', index=False)
最终kaggle得分
随机梯度下降,学习率0.01,训练100次
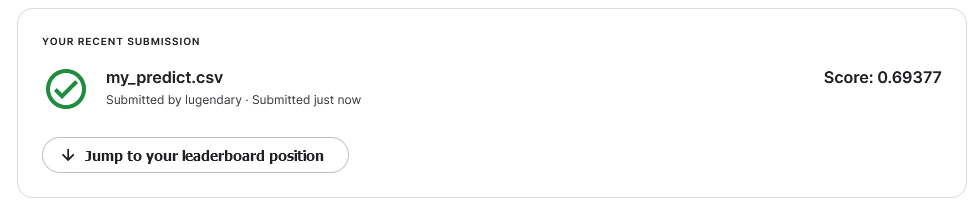
小批量梯度下降,学习率0.01,训练200次

后记
我又把代码改了改了,搞成了全梯度下降
具体代码如下
import numpy as np
import pandas as pd
import torch
xy = pd.read_csv('train.csv')
len = xy.shape[0]
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
x_data = torch.from_numpy(np.array(pd.get_dummies(xy[feature])))
y_data = torch.from_numpy(np.array(xy["Survived"]))
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
# 要先对选择的特征进行独热表示计算出维度,而后再选择神经网络开始的维度
self.linear1 = torch.nn.Linear(6, 3)
self.linear2 = torch.nn.Linear(3, 1)
self.sigmoid = torch.nn.Sigmoid()
# 前馈
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
return x
# 测试函数
def test(self, x):
with torch.no_grad():
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
y = []
# 根据二分法原理,划分y的值
for i in x:
if i > 0.5:
y.append(1)
else:
y.append(0)
return y
# 实例化模型
model = Model()
# 定义损失函数
criterion = torch.nn.BCELoss(reduction='mean')
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 防止windows系统报错
if __name__ == '__main__':
# 采用Mini-Batch的方法训练要采用多层嵌套循环
# 所有数据都跑100遍
# plt.show()
for epoch in range(200000):
x_data = x_data.float()
y_data = y_data.float()
y_pred = model(x_data)
y_pred = y_pred.squeeze(-1)
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 测试
test_data = pd.read_csv('test.csv')
feature = ["Pclass", "Sex", "SibSp", "Parch", "Fare"]
test = torch.from_numpy(np.array(pd.get_dummies(test_data[feature])))
y = model.test(test.float())
# 输出预测结果
output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': y})
output.to_csv('my_predict.csv', index=False)

帅的嘛还就不谈了!
但是这里还是有个问题
因为我学习的时候,明明随机梯度下降更加精确,因为随机梯度下降可以逃离局部最优点,但是为什么这里的得分反而是全梯度下降高呢?
我想了想我终于明白了,tmd因为我全梯度训练了20w次,搁谁谁不高
我换成了400次,果然,0.63分
好了,没问题了
【项目实战】Kaggle泰坦尼克号的幸存者预测的更多相关文章
- 小白学习之pytorch框架(7)之实战Kaggle比赛:房价预测(K折交叉验证、*args、**kwargs)
本篇博客代码来自于<动手学深度学习>pytorch版,也是代码较多,解释较少的一篇.不过好多方法在我以前的博客都有提,所以这次没提.还有一个原因是,这篇博客的代码,只要好好看看肯定能看懂( ...
- 数据分析-kaggle泰坦尼克号生存率分析
概述 1912年4月15日,泰坦尼克号在首次航行期间撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难.沉船导致大量伤亡的原因之一是没有足够的救生艇给乘客和船员.虽然幸存下来有一些运气因素,但 ...
- kaggle 泰坦尼克号问题总结
学习了机器学习这么久,第一次真正用机器学习中的方法解决一个实际问题,一步步探索,虽然最后结果不是很准确,仅仅达到了0.78647,但是真是收获很多,为了防止以后我的记忆虫上脑,我决定还是记录下来好了. ...
- 【腾讯Bugly干货分享】React Native项目实战总结
本文来自于腾讯bugly开发者社区,非经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/577e16a7640ad7b4682c64a7 “8小时内拼工作,8小时外拼成长 ...
- 项目实战10.1—企业级自动化运维工具应用实战-ansible
实战环境: 公司计划在年底做一次大型市场促销活动,全面冲刺下交易额,为明年的上市做准备.公司要求各业务组对年底大促做准备,运维部要求所有业务容量进行三倍的扩容,并搭建出多套环境可以共开发和测试人员做测 ...
- Kafka项目实战-用户日志上报实时统计之应用概述
1.概述 本课程的视频教程地址:<Kafka实战项目之应用概述> 本课程是通过一个用户实时上报日志来展开的,通过介绍 Kafka 的业务和应用场景,并带着大家搭建本 Kafka 项目的实战 ...
- H2O中的随机森林算法介绍及其项目实战(python实现)
H2O中的随机森林算法介绍及其项目实战(python实现) 包的引入:from h2o.estimators.random_forest import H2ORandomForestEstimator ...
- 机器学习_线性回归和逻辑回归_案例实战:Python实现逻辑回归与梯度下降策略_项目实战:使用逻辑回归判断信用卡欺诈检测
线性回归: 注:为偏置项,这一项的x的值假设为[1,1,1,1,1....] 注:为使似然函数越大,则需要最小二乘法函数越小越好 线性回归中为什么选用平方和作为误差函数?假设模型结果与测量值 误差满足 ...
- KNN算法项目实战——改进约会网站的配对效果
KNN项目实战——改进约会网站的配对效果 1.项目背景: 海伦女士一直使用在线约会网站寻找适合自己的约会对象.尽管约会网站会推荐不同的人选,但她并不是喜欢每一个人.经过一番总结,她发现自己交往过的人可 ...
随机推荐
- 聊聊 Netty 那些事儿之 Reactor 在 Netty 中的实现(创建篇)
本系列Netty源码解析文章基于 4.1.56.Final版本 在上篇文章<聊聊Netty那些事儿之从内核角度看IO模型>中我们花了大量的篇幅来从内核角度详细讲述了五种IO模型的演进过程以 ...
- Java 常用Set集合和常用Map集合
目录 常用Set集合 Set集合的特点 HashSet 创建对象 常用方法 遍历 常用Map集合 Map集合的概述 HashMap 创建对象 常用方法 遍历 HashMap的key去重原理 常用Set ...
- Windows版pytorch,torch简明安装
好消息!!目前pytorch已经提供windows官方支持,可以直接安装了,请移步这里. pytorch是facebook开发的深度学习库,其目标是想成为深度学习领域整合gpu加速的numpy.笔者研 ...
- mysql实现两个字段合并成一个字段查询
[需求]实现国际化I18N语言切换功能,例如菜单列表.字典等. 主要是个辅助表进行管理语言的配置: 单个字段很简单,直接通过字典配置的数据标签(key)- 表名, 数据键值(value)-表字段名[默 ...
- 2、MYSQL介绍
一.mysql优点 1.成本低:开放源代码,一般可以免费试用,采用的是gpl协议 2.性能高:执行很快 3.简单:很容易安装和使用 二.DBMS分为两类: 1.基于共享文件系统的DBMS(Acce ...
- Vue中关于this指向的问题
由Vue管理的函数 例如: computed 计算属性 watch 监视属性 filters (Vue3中已弃用且不再支持) 过滤器 .... 上述属性里配置的函数不要采用箭头函数写法,因为箭头函数没 ...
- Oracle,SAP等暂停俄所有业务,国产化刻不容缓,无代码又该如何发力
国产化刻不容缓 "如果不是自主可控的产品,我们这个行业可能有一天就瘫痪了."这句话最早是中国工程院院士倪先生预言的.然而,2022年的今天,由于俄乌战争,包括Oracle.SAP等 ...
- JavaScript进阶内容——BOM详解
JavaScript进阶内容--BOM详解 在上一篇文章中我们学习了DOM,接下来让我们先通过和DOM的对比来简单了解一下BOM 首先我们先来复习一下DOM: 文档对象模型 DOM把文档当作一个对象来 ...
- Vue3系列2--项目目录介绍及运行项目
1 Vite项目目录 用Vscode打开创建的项目,看到下面的目录结构: 通过运行 npm install 初始化项目后生成两个初始化文件:node_modules和 package-lock.js ...
- Vue mixin(混入) && 插件
1 # mixin(混入) 2 # 功能:可以把多个组件公用的配置提取成一个混入对象 3 # 使用方法: 4 # 第一步:{data(){return {...}}, methods:{...},.. ...