实时降噪(Real-time Denoising):Spatio-Temporal Filtering
空间滤波(Spatial Filtering)
基于距离的高斯滤波
仅考虑距离因素,会让图像均匀变糊,损失了有用的高频信息。
双边滤波(Bilateral filtering)
额外考虑了颜色因素(基于认为颜色变化剧烈的地方是边界,不应该贡献太多权重)
\]
\(\sigma_d\) 和 \(\sigma_r\) 都是主观设置的常量,即自己来决定各因素的权重影响。
联合双边滤波(Joint Bilateral filtering)[2017]
SVGF(Spatio-Temporal Variance Guided Filter)[Schied 2017] = 联合双边滤波 + 时域滤波
联合双边滤波(Joint Bilateral filtering):充分利用 G-buffer 的各种属性作为参考,控制空间滤波的核和权重
问题关键实际就是在判断高频信息属于噪声还是图像信息,而 G-buffer 是光栅化过程生成的完全没有噪声,因此作为滤波的指导是非常有用的。
考虑的点有:
- 联合考虑深度差异和法线(不能简单的单纯考虑深度差异)
- 实际上就是考虑沿平面的深度差距
\]

- 法线的差异
- 求出来的值有可能是负值,因此使用了 max() 函数
- \(\sigma_n\) 是为了更突出法线变化
\]
注:如果使用法线贴图,使用法线贴图变换前的法线。

- 亮度的差异(两点颜色间的灰度差距):差异过大则认为两点位置靠近边界,贡献不应过大
- 由于噪声可能会出现干扰,因此需要 variance 指导
\]
方差 Var 的计算:
- 计算需要滤波的点 7×7 范围内的方差
- 按时域的方法,通过motion vector计算上一帧对应像素的方差,并计算平均(相当于按时域滤波了,将方差变得时域上平滑)
- 再在周围 3×3 的区域内做空间的平均滤波

最后综合权重就可以计算为 \(w=w_z*w_n*w_l\)
一些改进及优化
加速 filtering: 可分离的高斯滤波
如果滤波核采用高斯函数的形式,得益于 2D 高斯可分离成水平垂直两次 1D 高斯滤波的特性,可以对图像进行一个水平方向的 1D 高斯滤波 pass 和一个垂直方向的 1D 高斯滤波 pass,将时间复杂度从 \(O(mnk^2)\) 降到 \(O(2mnk)\)
\(m,n\) 代表图像长宽,\(k\) 代表方形滤波核边长
\]
\]

加速 filtering: a-trous wavelet
而对于非高斯函数形式或者说更复杂的滤波核(例如联合双边滤波核),就很难像单纯的高斯核那样可分离成两个 1D Pass。这时候就可能需要 a-trous wavelet 方法来优化较大滤波范围的原始2D滤波
a-trous wavelet:采用多 pass 的方式,每个 pass 使用 3×3 或 5×5 的小滤波范围但逐渐增加采样间隔。
具体来说,第 \(i\) 个 pass 的采样间隔将为 \(2^{i-1}-1\)(相邻两个 pass 的采样间隔相差 \(2^i\))
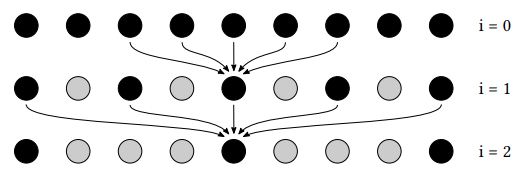
时间复杂度 \(O(mnk^2)\) 降到 \(O(mn\cdot 5^2\cdot log_2{k})\),只是需要额外的纹理用来写入前一个 pass 的输出(中间结果)。因此对于超大范围的滤波,使用 a-trous wavelet 方法增加的写入开销还是远远比节省的采样开销小。
例如:本来一个 64×64 的 2D 滤波,在该方法中就会变成使用 5 个 Pass,每个 Pass 做 5×5 的 2D 滤波。因为在使用第五个 pass 时,采样间隔为 15,也就是说采样总跨度为 15*4+5 = 65,即 65×65 的滤波范围,与 64×64 已经非常相似。
jittering
结合 jittering 来进行子采样,进一步减少采样数。
outliers removal
可以根据设置的阈值 max radiance 限制或者根据 variance 去 clamp 掉颜色差异较大的 pixel(例如一些亮点)
当然直接粗暴的剔除这些亮点可能会导致能量不守恒,但是最高效的减少 firefly 方法就是如此。

// Ray Tracing Gems Chapter 17
vec3 fireflyRejectionClamp(vec3 radiance, vec3 maxRadiance)
{
return min(radiance, maxRadiance);
}
// Ray Tracing Gems Chapter 25
vec3 fireflyRejectionVariance(vec3 radiance, vec3 variance, vec3 shortMean, vec3 dev)
{
vec3 dev = sqrt(max(1.0e-5, variance));
vec3 highThreshold = 0.1 + shortMean + dev * 8.0;
vec3 overflow = max(0.0, radiance - highThreshold);
return radiance - overflow;
}
时域滤波(Temporal Filtering)
Temporal Filtering
简单地说,就是想找到本帧某 pixel 对应上一帧哪个 pixel 然后进行线性混合,这样就可以通过时序来增加采样数,让当前图像噪声更加小些。
当然,也不能简单地按照相同的屏幕 uv 坐标来直接混合;因为物体和摄像机随时都会发生移动等变化,这时候就需要借助 motion vector 来找到上帧对应的准确屏幕位置。
具体步骤:
back projection(后向投影):用于计算出 pixel 在两帧之间的 motion vector(即要找到本帧某 pixel 对应上一帧哪个 pixel)
求出当前帧 pixel 的世界坐标(如果保存了G-buffer可以直接取值用;如果没有保存,通过逆视口变换、逆VP变换得到)
将当前帧的 pixel 世界坐标乘本帧的变换矩阵的逆矩阵 \(T^{-1}_i\),再乘上一帧的变换矩阵 \(T_{i-1}\),从而得到上一帧这个 pixel 对应的世界坐标。
将上一帧的世界坐标经上一帧 \(VP\) 和视口变换得到上一帧的 pixel 屏幕位置
本帧 pixel 的颜色与上一帧对应位置的 pixel 的颜色进行线性混合:
\]
\]
~ 为未空间滤波,- 为已空间滤波;\(\alpha\) 一般为 0.1~0.2
所需存储的主要历史信息:
- 上一帧的 color buffer(一般来说 temporal 混合的都是 color)
- 上一帧的所有物体的变换矩阵(transforms)
问题:
- 镜头的第一帧,或光源突变的情况无法处理
- 屏幕空间信息不足:比如屏幕外的点进入了屏幕内(由于时域滤波基于屏幕空间)
- 被遮挡的物体突然出现(本质还是屏幕空间问题)
- 由于世界空间几何位置没有变化(从而motion vector没有变化),导致 shadow 、reflection 等滞后的现象
一些改进及优化
clamping
使用 clamp 来避免 color 发生太大的变化,减轻鬼影现象。
- 对本帧 \(x_i\) 邻域计算均值 \(\mu\) 和方差 \(\sigma\) (可以在做空间滤波时顺便求出来,基本无开销)
- 对本帧 \(x_i\) 进行 reprojection 得到对应上帧的位置 \(x^o_{i-1}\)
- 对 \(x^o_{i-1}\) 的 color 进行 clamp,clamp 在 \([\mu-\sigma,\mu+\sigma]\)
- 混合本帧 \(x_i\) 的 color 和上帧的 clamp color
detection
可以通过检测某些条件来决定是否混合上一帧的结果,比如:
可以判断前后两帧 motion vector 对应的 pixel 对应的物体是否为一个物体:如果不是同一物体,混合系数 \(\alpha\) 设为 0
该方法需要额外存储历史帧的 id buffer
混合 irradiance 而非 color
前面提到的 temporal 基本都是在混合 color,但实际上混合 irradiance 的效果更好:因为 irradiance 与不同着色点的法线无关,它相比 color 更加平滑。
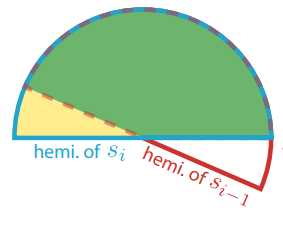
- 记录历史帧 normal + irradiance:
- 假设表面都是 diffuse ,因此只需存储半球中心对应法线,而无需存储方向相关的 irradiance 强度信息
- 屏幕空间本帧法线对应半球范围与历史帧法线对应半球范围的重合比例决定历史帧 irradiance 的 temporal 混合权重
- 仅可以支持 diffuse
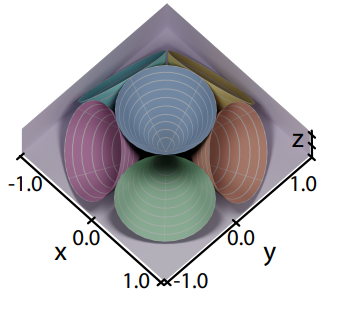
- 记录历史帧 normal + 6 个 irradiance:
- 使用 6 个圆锥立体角来粗略表示在不同方向上的 irradiance 强度信息(代表了 shading point 在这个立体角范围接受的 radiance 的总和)
- 可以支持 diffuse + specular
A-SVGF [2018]
改进了 SVGF 的 temporal filtering 操作,先计算出 temporal gradient(时域梯度,可以理解成表示 shading point 在两帧之间着色变化的程度),再根据此计算出每 pixel 做 temporal filtering 时的混合系数,而不非使用一个固定的混合系数,增强了结果的时序稳定性。
估计 temporal gradient
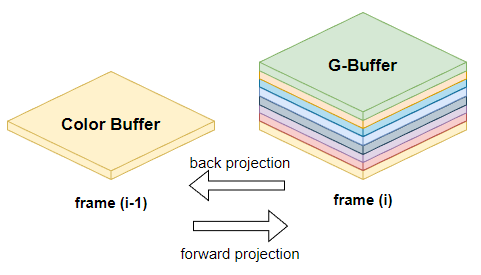
temporal 样本的复用需要进行 reprojection,而 reprojection 有两种方法:
- back projection(反向投影)就是把本帧的 sample 投影到先前帧的位置:\(\overleftarrow{G}_{i, j}\)
- forward projection(前向投影)先前帧的样本投影到本帧:\(\vec{G}_{i-1, j}\)
定义第 i 帧的第 j 个像素的表面采样表示为 \(G_{i,j}\)
以前计算 motion vector 时,我们往往是使用 back projection,而在计算 temporal gradient 时我们使用了 forward projection。
原因是本帧拥有的信息(G-Buffer)往往比上帧拥有的信息(几乎只有个 Color Buffer)多,使用 forward projection 的时候就可以有更多参考信息。
介绍完上面前置的知识后,这里定义 \(f\) 为着色函数,那么 temporal gradient 则可以表示为:
\]
在上一帧渲染的收尾阶段时,我们可以将屏幕分成若干个 tile,每个 tile 抽取一个 pixel \(G_{i-1}\) 作为历史样本,并将历史样本列表传递给本帧(也就是它的下一帧)。
在本帧,我们对历史样本列表的所有样本进行 forward projection,找到它们对应在本帧的位置 \(\vec{G}_{i-1, j}\)
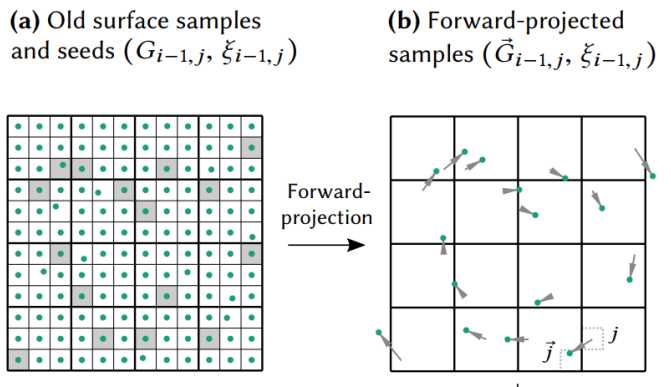
也就是说上一帧保留的信息有:Color Buffer + 物体 transforms + 历史样本列表(每个样本只需要带 position 属性)
虽然对历史所有 pixels 作 forward projection 能获得质量更好的 temporal gradient,但这样需要保留的历史信息就又多了个 position buffer,开销增大太多不值得;而稀疏的历史 pixels 样本足以在低开销的情况下估计并重建出够用的 temporal gradient(无需太精确)。
然后,对应本帧的位置 \(\vec{G}_{i-1, j}\) + 利用本帧的 G-Buffer 信息并重新着色得到着色结果 \(f_{i}\left(\vec{G}_{i-1, j}\right)\)
同时,历史样本 \(G_{i-1}\) + 直接利用上一帧 color buffer 不做任何插值就能直接索引找到着色结果 \(f_{i-1}\left(G_{i-1, j}\right)\)
稳定的随机采样:我们还希望 temporal gradient 的方差不要过大(更少的噪声),即对上一帧 \(G_{i-1}\) 的着色与 forward projection 后重新的着色之间的变化尽可能少受些噪声干扰。
\[\begin{array}{r}
\operatorname{Var}\left(\delta_{i, \vec{j}}\right)=\operatorname{Var}\left(f_{i}\left(\vec{G}_{i-1, j}, \xi_{i, j}\right)\right)+\operatorname{Var}\left(f_{i-1}\left(G_{i-1, j}, \xi_{i-1, j}\right)\right) \\
-2 \cdot \operatorname{Cov}\left(f_{i}\left(\vec{G}_{i-1, j}, \xi_{i, \vec{j}}\right), f_{i-1}\left(G_{i-1, j}, \xi_{i-1, j}\right)\right)
\end{array}
\]而这其中着色函数可能依赖于随机数 \(\xi\)(例如path tracing 时随机数会用于选择采样方向),我们就需要减少随机数带来的干扰。
为此,应当保持 forward projection 后也依赖于相同的随机数,即令 \(\xi_{i-1,\vec{j}}:=\xi_{i-1, j}\)。这样我们的历史样本还需要存储上对应的随机数种子 \(\xi_{i-1, j}\)
这样,每个样本位置对应的 temporal gradient 就能算出来了:\(\delta_{i, \vec{j}}=f_{i}\left(\vec{G}_{i-1, j}\right)-f_{i-1}\left(G_{i-1, j}\right)\)
接着,就需要根据这些稀疏的 temporal gradient 样本,重建出稠密的 temporal gradient 2D texture
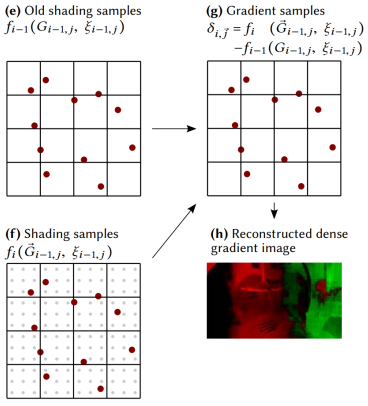
重建 temporal gradient texture
稀疏的 temporal gradient 样本可以看成是 image 中几个特别亮的 texel,而我们可以利用联合双边滤波的思路插值出来得到一张 temporal gradient 2D texture。
重建过程中几个要点:
初始 temporal gradient image 全部 texel 的梯度值设置为 0(全黑),除了 temporal gradient 样本位置所在的 texel 是亮点(含有梯度值)
滤波范围需要大一些(因为样本稀疏)
需要多次迭代的联合双边滤波:
\[\hat{\delta}^{(k+1)}(p)=\frac{\sum_{q \in \Omega} h^{(k)}(p, q) w^{(k)}(p, q) \hat{\delta}^{(k)}(q)}{\sum_{q \in \Omega} h^{(k)}(p, q) w^{(k)}(p, q)}
\]
个人的奇思妙想:不知道 temporal gradient 是否能再利用 temporal 思想,混合上一帧的 temporal gradient,来得到更加精确的 temporal temporal gradient(?)
根据 temporal gradient 控制 temporal 混合系数
已经有了重建好的 temporal gradient image,现在我们要控制时序滤波的因子了,首先加入标准化因子:
\]
因为空的层梯度设置为了 0,并使用了联合双边滤波产生 \({\hat{\Delta}_{i}(p)}\),我们定义密度和标准化历史权重(该式意义在于让 \(λ\) 小于等于 1):
\]
最后我们定义的 adaptive temporal 的混合系数为:
\]
更可靠的 Motion Vectors [2021]
motion vector 并不总是存在或无效,强行应用就会出现鬼影(随着时间的推移,不合理的泄漏或阴影滞后):
- 背景中的静态位置可能被前一帧的运动物体遮挡
- 对于 shadow, glossy reflection 效果,motion vector 可能是错误的(如 receiver 具有长度为 0 的 motion vector,但投射到其上的 shadow 可能随光源任意移动)
总的来说,感觉这篇 paper 实用的地方并不多,就是提供了除了额外三种 motion vector。然后 paper 并没有结合这三种 motion vector 来使用,只是分别在三种场景单独使用 shadow,glossy,dual 测测结果。
如果要落地的话,可以考虑:
- 要不在 temporal filtering 过程中,通过权重来混合三种 motion vector 各自对应的 pixel
- 要不在一条 pipeline 上使用至少三次 temporal filtering,其中三种方法分别处理 shadow,specular,final color 三种信号
shadow motion vector
Percentage Closer Soft Shadows (PCSS) 需要 shading point 发射若干 rays 来检测可以打到面光源的通过率(也就是 visibility),也就是说需要往 light 采样多次。我们期望利用时序上(上一帧)的样本来增加 PCSS 的采样数。
具体步骤:
- 在本帧,让 shading point 投射一条 shadow ray 打到 light 上,并记下可能穿过 blocker 的点 \(b_i\) 和打到光源面上的点 \(l_i\)
- back projection:\(b_i\) 通过本帧 blocker 的逆变换 \(T^{-1}_i\) 和上一帧 blocker 的变换 \(T_{i-1}\) 得到 \(b_{i-1}\) ;同理 \(l_i\) 也能得到 \(l_{i-1}\)
- 以 \(s_i\) 和其法线 \(n_{s_i}\) 构造一个无限长平面,然后将 \(l_{i-1}\) 与 \(b_{i-1}\) 连成线后相交于该平面,算出该相交点 \(s_{i-1}\)
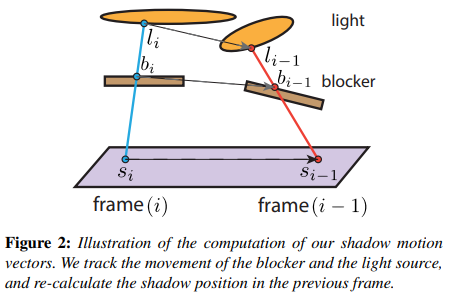
把 \(s_{i-1}\) 投影到本帧 camera 的屏幕中,并得到屏幕 uv 后根据 depth buffer 重建出实际被看到的 shading point 位置 \(s^V_{i-1}\),也就是说计算出的 motion vector = \(s^V_{i-1}-s_{i-1}\)
此外,当 \(s^V_{i-1}\) 与 \(s_i\) 真的如假设那样在同一平面,那么这个 motion vector 极大概率是准确的,也就是说采样历史帧时可以参考 \(s^V_{i-1}\);否则,就不应该过多参考 \(s^V_{i-1}\)
为此,可以根据 \(\theta\) (\(s_i\) 法线与 motion vector 的夹角)来实现加权的 temporal 混合,这样当 \(\theta\) 与 \(\frac{\pi}{2}\) 相差很大时就可以相当于拒绝采样历史帧样本。
weight:
\]
\(cos \theta = \frac{n_{s_i} \cdot (s^V_{i-1}-s_i)}{|s^V_{i-1}-s_i|}\)
不过采样结果是稍微 noisy 的,因此还需要一些 clean-up filter。
个人想法:直接对 color 信号处理可能并不准确,而如果对单纯的 shadow 信号处理会更好。
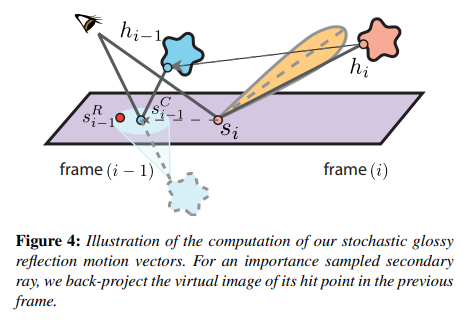
glossy motion vector
对于 glossy motion vector,也是类似思想。我们期望利用时序上(上一帧)的样本来增加 glossy reflection 的采样数。
具体步骤:
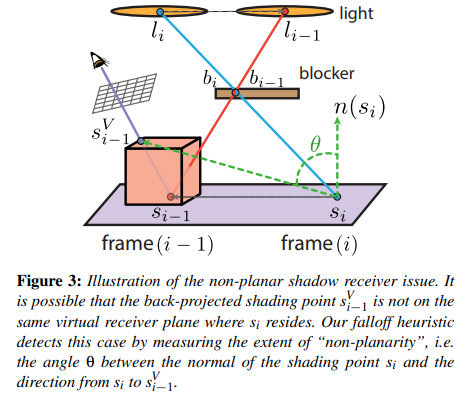
- 在本帧,让 shading point 根据 brdf importance sampling 来生成一条 ray 并打到某个 mesh 上,并记下 hit point \(h_i\)
- back projection:\(h_i\) 通过本帧 mesh 的逆世界变换 \(T^{-1}_i\) 和上一帧 mesh 的世界变换 \(T_{i-1}\) 得到 \(h_{i-1}\)
- 以 \(s_i\) 和其法线 \(n_{s_i}\) 构造一个无限长平面,然后将 \(h_{i-1}\) 于该平面翻转(类似形成一个倒置的虚像),并连接 camera point,算出与该平面的相交点 \(s^C_{i-1}\)
因为 glossy lobe 的中心方向是最强烈的反射方向,因此可以假设退化成纯镜面反射方向,就能得到反射率最高的 shading point
- 以 \(s^C_{i-1}\) 为中心,邻近的 shading point 都可以作为采样的参考(根据 \(s^C_{i-1}\) 的材质 roughness 程度决定半径),并且对这一圈的样本按高斯分布的方式去加权采样结果作为历史帧的 color
- 类似 shadow motion vector,利用 \(\theta\) 检测共平面的程度,当 \(\theta\) 与 \(\frac{\pi}{2}\) 相差很大时就可以相当于拒绝采样历史帧样本
个人想法:直接对 color 信号(包含 diffuse + specular)处理可能并不准确,而如果对单纯的 specular 信号处理会更好。
dual motion vector
假设在本帧 pixel \(x_i\) 可见,而在上一帧它被 occluder \(y\) 遮挡住了。
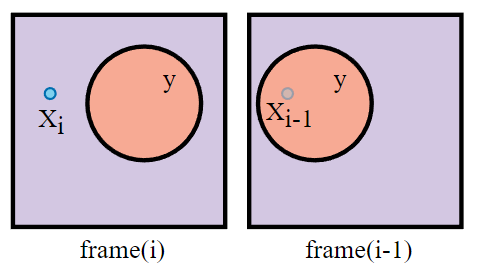
传统 motion vector :
- 对本帧 \(x_i\) 进行 reprojection 得到对应上帧的位置 \(x^o_{i-1}\)(但其实 \(x^o_{i-1}\) 是投影在了上帧的 occluder \(y\) 上,因此得到的上帧 color 是 occluder \(y\) 的 color)
- 强行混合本帧 \(x_i\) 的 color 和上帧的 color,这也是造成鬼影的一大原因
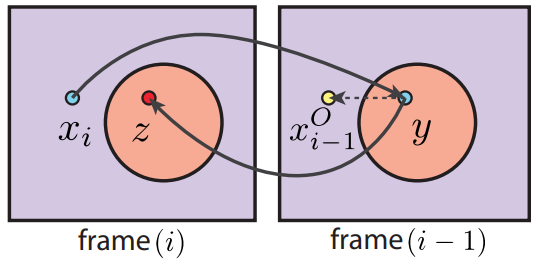
dual motion vectors:基于假设要渲染的 pixel 和 occluder 的相对位置不变。
- 对本帧 \(x_i\) 进行 back projection 得到对应上帧的位置 \(y\)
- 再将上帧 \(y\) 进行 forward projection (需要借助历史 id buffer)得到对应本帧的位置 \(z\)
- 计算相对位移 \(offset = x_i-z\)
- 那么最终找到的对应上帧位置便是 \(x^o_{i-1} = y + offset\)
- 混合本帧 \(x_i\) 的 color 和上帧 \(x^o_{i-1}\)
对于没有遮挡物的案例来说,\(offset\) 往往是 0,即用了 dual motion vectors 会退化成传统 motion vector:
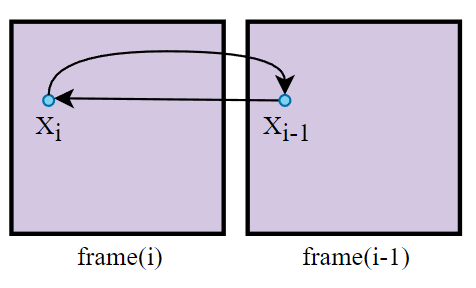
为什么要假设渲染的 pixel 和 occluder 的相对位置不变?
这是因为,根据相对位置算出来的上帧位置虽然一般不是该 pixel 以前的真正位置,但是该位置很大概率是位于与该 pixel 处在同一平面的邻近位置,而这些位置得到的 color 和 pixel 得到的 color 就很大相似度,有一定参考价值。
本方法所需存储的主要历史信息:
- color buffer
- id buffer
- 物体 transforms
个人想法:既然有历史 id buffer,其实这个方法在最后的步骤也可以结合 detection 方法,通过比较 pixel 的历史 id 和当前 id 来进一步规避边缘情况。
参考
- [1] GAMES202-高质量实时渲染-闫令琪
- [2] Temporally Reliable Motion Vectors for Real-time Ray Tracing [EUROGRAPHICS 2021]
- [3] Spatio-Temporal Variance Guided Filter SVGF [Schied 2017]
- [4] Gradient Estimation for Real-Time Adaptive Temporal Filtering [Schied 2018]
- [5] A-SVGF 论文分析
- [6] 光线追踪降噪技术 2020
- [7] Edge-Avoiding À-Trous Wavelet Transform for fast Global Illumination Filtering [Dammertz 2010]
实时降噪(Real-time Denoising):Spatio-Temporal Filtering的更多相关文章
- 实时降噪(Real-time Denoising):Nvidia Real-time Denoisers 源码剖析
目录 Nvidia Real-time Denoisers(NRD) v3.x ReBLUR 前置知识 空间滤波(Spatial Filtering):Diffuse & Specular 泊 ...
- 降噪自动编码器(Denoising Autoencoder)
起源:PCA.特征提取.... 随着一些奇怪的高维数据出现,比如图像.语音,传统的统计学-机器学习方法遇到了前所未有的挑战. 数据维度过高,数据单调,噪声分布广,传统方法的“数值游戏”很难奏效.数据挖 ...
- Unity3d 游戏中的实时降噪-对Square Enix文档的研究与实现
看到SE的技术文档关于降噪的决定研究一下,本次试验场景: 文章中提到了3中主要滤波方法,最后一种方法又有三种方式分别为Conventional geometry-aware filtering,Dist ...
- 基于theano的降噪自动编码器(Denoising Autoencoders--DA)
1.自动编码器 自动编码器首先通过下面的映射,把输入 $x\in[0,1]^{d}$映射到一个隐层 $y\in[0,1]^{d^{'}}$(编码器): $y=s(Wx+b)$ 其中 $s$ 是非线性的 ...
- Big Spatio temporal Data(R-tree Index and NN & RNN & Skyline)
一.简单介绍大数据技术产物 “大数据”一词首先出现在2008年9月<Nature>杂志发表的一篇名为“Big Data: Wikiomics”的文章上(Mitch,2008).“大数据科学 ...
- 堆叠降噪自编码器SDAE
https://blog.csdn.net/satlihui/article/details/81006906 https://blog.csdn.net/github_39611196/articl ...
- 编解码再进化:Ali266 与下一代视频技术
过去的一年见证了人类百年不遇的大事记,也见证了多种视频应用的厚积薄发.而因此所带来的视频数据量的爆发式增长更加加剧了对高效编解码这样的底层硬核技术的急迫需求. 新视频编解码标准 VVC 定稿不久之后, ...
- 【论文阅读】CVPR2021: MP3: A Unified Model to Map, Perceive, Predict and Plan
Sensor/组织: Uber Status: Reading Summary: 非常棒!端到端输出map中间态 一种建图 感知 预测 规划的通用框架 Type: CVPR Year: 2021 引用 ...
- 论文翻译:2020_Lightweight Online Noise Reduction on Embedded Devices using Hierarchical Recurrent Neural Networks
论文地址:基于分层递归神经网络的嵌入式设备轻量化在线降噪 引用格式:Schröter H, Rosenkranz T, Zobel P, et al. Lightweight Online Noise ...
随机推荐
- Git出现“filename too long”错误处理
更新记录 本文迁移自Panda666原博客,原发布时间:2021年5月8日. 怎么肥事? Windows系统下,在Git使用过程中,出现"filename too long"错误提 ...
- 腾讯视频的qlv格式转换为mp4格式
1.点击设置->下载设置->缓存管理 下的文件目录复制; 2复制在 我的电脑路径栏目中 找到缓存目录 文件夹vodcache; 3.打开视频对应文件; 4.打开cmd命令窗口 5.跳转 到 ...
- ABAP CDS DDHEADANNO
- Linux 文件的打包压缩
压缩和解压 压缩:为了节约磁盘空间. gzip --- .gz bzip2 --- .bz2 xz --- .xz compress --- .z 压缩比例:xz > bzip2 > gz ...
- Python控制自己的手机摄像头拍照,并把照片自动发送到邮箱
写在前面的一些P话: 今天这个案例,就是控制自己的摄像头拍照,并且把拍下来的照片,通过邮件发到自己的邮箱里.想完成今天的这个案例,只要记住一个重点:你需要一个摄像头 思路 通过opencv调用摄像头拍 ...
- 网络通讯之Socket-Tcp(一)
网络通讯之Socket-Tcp 分成3部分讲解: 网络通讯之Socket-Tcp(一): 1.如何理解Socket 2.Socket通信重要函数 网络通讯之Socket-Tcp(二): 1.简单So ...
- JDBC:Statement问题
1.Statement问题 2.解决办法:通过PreparedStatement代替 实践: package com.dgd.test; import java.io.FileInputStrea ...
- 实战模拟│单点登录 SSO 的实现
目录 什么是单点登录 单点登录的凭证 父域 Cookie 方式 用户认证中心方式 localstorage方式 什么是单点登录 单点登录: SSO(Single Sign On) 用户只需登录一次,就 ...
- Zend Studio,php 生成报错
Zend Studio Description Resource Path Location Type Undefined CSS file ("../red-treeview.css&q ...
- WCF全局捕获日志
/// <summary> /// WCF服务端异常处理器 /// </summary> public class WCF_ExceptionHandler : IErrorH ...