Karmada跨集群优雅故障迁移特性解析
摘要:在 Karmada 最新版本 v1.3中,跨集群故障迁移特性支持优雅故障迁移,确保迁移过程足够平滑。
本文分享自华为云社区《Karmada跨集群优雅故障迁移特性解析》,作者:Karmada社区。
在多云多集群应用场景中,为了提高业务的高可用性,用户的工作负载可能会被部署在多个集群中。然而当某个集群发生故障时,为保证业务的可用性与连续性,用户希望故障集群上的工作负载被自动的迁移到其他条件适合的集群中去,从而达成故障迁移的目的。

Karmada 在 v1.0 版本发布之前便已支持跨集群故障迁移能力,经历过社区多个版本的开发迭代,跨集群故障迁移能力不断完善。在 Karmada 最新版本 v1.3 (https://github.com/karmada-io/karmada/tree/release-1.3)中,跨集群故障迁移特性支持优雅故障迁移,确保迁移过程足够平滑。
下面我们对该特性展开解析。
▍回顾:单集群故障迁移
在 Kubernetes 的架构中,Node 作为运行 Pod 实例的单元,不可避免地面临出现故障的可能性,故障来源不限于自身资源短缺、与 Kubernetes 控制面失去连接等。提供服务的可靠性、在节点故障发生后保持服务的稳定一直是 Kubernetes 关注的重点之一。在 Kubernetes 管理面,当节点出现故障或是用户不希望在节点上运行 Pod 时,节点状态将被标记为不可用的状态,node-controller 会为节点打上污点,以避免新的实例调度到当前节点上、以及将已有的 Pod 实例迁移到其他节点上。
▍集群故障判定
相较于单集群故障迁移,Karmada 的跨集群故障迁移单位由节点变为了集群。Karmada 支持Push 和 Pull 两种模式来管理成员集群,有关集群注册的信息可以参考Cluster Registration(http://karmada.io/docs/next/userguide/clustermanager/cluster-registration/)。Karmada 根据集群的心跳来判定集群当前的状态。集群心跳探测有两种方式:1.集群状态收集,更新集群的 .status 字段(包括 Push 和 Pull 两种模式);2.控制面中 karmada-cluster 命名空间下的 Lease 对象,每个 Pull 集群都有一个关联的 Lease 对象。
集群状态收集
对于 Push 集群,Karmada 控制面中的 clusterStatus-controller 将定期执行集群状态的收集任务;对于 Pull 集群,集群中部署的 karmada-agent 组件负责创建并定期更新集群的 .status 字段。集群状态的定期更新任务可以通过 --cluster-status-update-frequency 标签进行配置(默认值为10秒)。集群的 Ready 条件在满足以下条件时将会被设置为 False :· 集群持续一段时间无法访问;· 集群健康检查响应持续一段时间不正常。上述持续时间间隔可以通过 --cluster-failure-threshold 标签进行配置(默认值为30秒)。
集群 Lease 对象更新
每当有 Pull 集群加入时,Karmada将为该集群创建一个 Lease 对象和一个 lease-controller。每个 lease-controller 负责更新对应的 Lease 对象,续租时间可以通过 --cluster-lease-duration 和 --cluster-lease-renew-interval-fraction 标签进行配置(默认值为10秒)。由于集群的状态更新由 clusterStatus-controller 负责维护,因此 Lease 对象的更新过程与集群状态的更新过程相互独立。Karmada 控制面中的 cluster-controller 将每隔 --cluster-monitor-period 时间(默认值为5秒)检查 Pull 集群的状态,当 cluster-controller 在 --cluster-monitor-grace-period 时间段(默认值为40秒)内没有收到来着集群的消息时,集群的 Ready 条件将被更改为 Unknown 。
检查集群状态
你可以使用 kubectl 命令来检查集群的状态细节:kubectl describe cluster
▍故障迁移过程
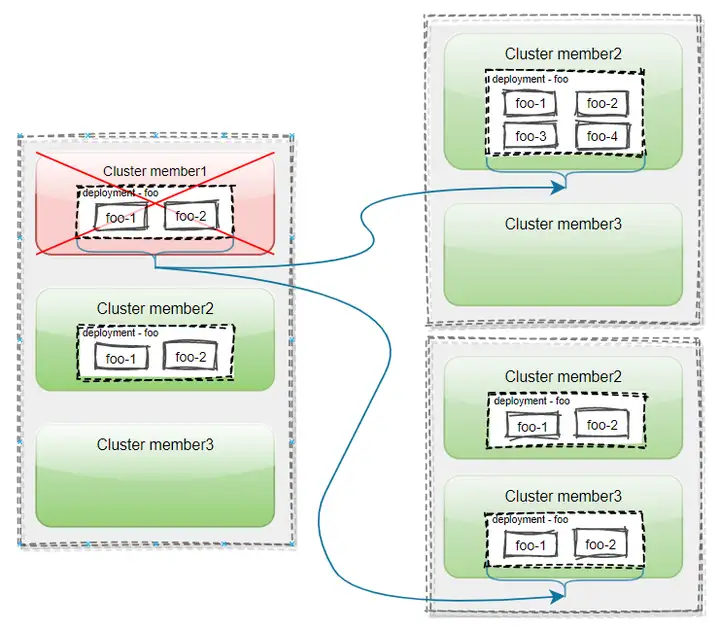
集群污点添加
当集群被判定为不健康之后,集群将会被添加上Effect值为NoSchedule的污点,具体情况为: · 当集群 Ready 状态为 False 时,将被添加如下污点:key: cluster.karmada.io/not-ready effect: NoSchedule· 当集群 Ready 状态为 Unknown 时,将被添加如下污点:key: cluster.karmada.io/unreachable effect: NoSchedule 如果集群的不健康状态持续一段时间(该时间可以通过 --failover-eviction-timeout 标签进行配置,默认值为5分钟)仍未恢复,集群将会被添加上Effect值为NoExecute的污点,具体情况为:
·当集群 Ready 状态为 False 时,将被添加如下污点:key: cluster.karmada.io/not-ready effect: NoExecute
·当集群 Ready 状态为 Unknown 时,将被添加如下污点:key: cluster.karmada.io/unreachable effect: NoExecute
容忍集群污点
当用户创建 PropagationPolicy/ClusterPropagationPolicy 资源后,Karmada 会通过 webhook 为它们自动增加如下集群污点容忍(以 PropagationPolicy 为例):
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
namespace: default
spec:
placement:
clusterTolerations:
- effect: NoExecute
key: cluster.karmada.io/not-ready
operator: Exists
tolerationSeconds: 600
- effect: NoExecute
key: cluster.karmada.io/unreachable
operator: Exists
tolerationSeconds: 600
...
其中,tolerationSeconds 值可以通过 --default-not-ready-toleration-seconds 与--default-unreachable-toleration-seconds 标签进行配置,这两个标签的默认值均为600。
故障迁移
当 Karmada 检测到故障群集不再被 PropagationPolicy/ClusterPropagationPolicy 容忍时,该集群将被从资源调度结果中移除,随后,karmada-scheduler 重调度相关工作负载。重调度的过程有以下几个限制:·对于每个重调度的工作负载,其仍然需要满足PropagationPolicy/ClusterPropagationPolicy 的约束,如 ClusterAffinity 或 SpreadConstraints 。· 应用初始调度结果中健康的集群在重调度过程中仍将被保留。
-复制 Duplicated 调度类型
对于 Duplicated 调度类型,当满足分发策略限制的候选集群数量不小于故障集群数量时,将根据故障集群数量将工作负载重新调度到候选集群;否则,不进行重调度。
...
placement:
clusterAffinity:
clusterNames:
- member1
- member2
- member3
- member5
spreadConstraints:
- maxGroups: 2
minGroups: 2
replicaScheduling:
replicaSchedulingType: Duplicated
...
假设有5个成员集群,初始调度结果在 member1和 member2 集群中。当 member2 集群发生故障,触发 karmada-scheduler 重调度。
需要注意的是,重调度不会删除原本状态为 Ready 的集群 member1 上的工作负载。在其余3个集群中,只有 member3 和 member5 匹配 clusterAffinity 策略。由于传播约束的限制,最后应用调度的结果将会是 [member1, member3] 或 [member1, member5] 。
-分发 Divided 调度类型
对于 Divided 调度类型,karmada-scheduler 将尝试将应用副本迁移到其他健康的集群中去。
...
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 2
...
Karmada-scheduler 将根据权重表 weightPreference 来划分应用副本数。初始调度结果中, member1 集群上有1个副本,member2 集群上有2个副本。当 member1 集群故障之后,触发重调度,最后的调度结果是 member2 集群上有3个副本。
▍优雅故障迁移
为了防止集群故障迁移过程中服务发生中断,Karmada 需要确保故障集群中应用副本的删除动作延迟到应用副本在新集群上可用之后才执行。ResourceBinding/ClusterResourceBinding 中增加了 GracefulEvictionTasks 字段来表示优雅驱逐任务队列:
// GracefulEvictionTasks holds the eviction tasks that are expected to perform
// the eviction in a graceful way.
// The intended workflow is:
// 1. Once the controller(such as 'taint-manager') decided to evict the resource that
// is referenced by current ResourceBinding or ClusterResourceBinding from a target
// cluster, it removes(or scale down the replicas) the target from Clusters(.spec.Clusters)
// and builds a graceful eviction task.
// 2. The scheduler may perform a re-scheduler and probably select a substitute cluster
// to take over the evicting workload(resource).
// 3. The graceful eviction controller takes care of the graceful eviction tasks and
// performs the final removal after the workload(resource) is available on the substitute
// cluster or exceed the grace termination period(defaults to 10 minutes).
//
// +optional
GracefulEvictionTasks []GracefulEvictionTask `json:"gracefulEvictionTasks,omitempty"`
当故障集群被 taint-manager 从资源调度结果中删除时,它将被添加到优雅驱逐任务队列中。gracefulEvction-controller 负责处理优雅驱逐任务队列中的任务。在处理过程中,gracefulEvction-controller 逐个评估优雅驱逐任务队列中的任务是否可以从队列中移除。判断条件如下:
- 检查当前资源调度结果中资源的健康状态。如果资源健康状态为健康,则满足条件。
- 检查当前任务的等待时长是否超过超时时间,超时时间可以通过graceful-evction-timeout 标签进行配置(默认为10分钟)。如果超过,则满足条件。
▍总结
Karmada 跨集群优雅故障迁移特性提升了集群故障后业务的平滑迁移能力,希望通过上述分析过程能帮大家更好的理解和使用Karmada 跨集群故障迁移能力。有关该特性的更多详细信息可以参考 Karmada 官网。大家也可以查看 Karmada release (https://github.com/karmada-io/karmada/releases)来跟进 Karmada 最新版本动态。如果大家对 Karmada 跨集群故障迁移特性有更多兴趣与见解,或是对其他特性和功能感兴趣,也欢迎大家积极参与到 Karmada 社区中来,参与社区讨论与开发。附:Karmada社区技术交流地址
项目地址:
https://github.com/karmada-io/karmada
Slack地址:https://slack.cncf.io/
Karmada跨集群优雅故障迁移特性解析的更多相关文章
- elasticsearch跨集群数据迁移
写这篇文章,主要是目前公司要把ES从2.4.1升级到最新版本7.8,不过现在是7.9了,官方的文档:https://www.elastic.co/guide/en/elasticsearch/refe ...
- Hadoop跨集群迁移数据(整理版)
1. 什么是DistCp DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具.它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生成.它把文件和目录的列表作为map任务的 ...
- Hive跨集群迁移
Hive跨集群迁移数据工作是会出现的事情, 其中涉及到数据迁移, metastore迁移, hive版本升级等. 1. 迁移hdfs数据至新集群hadoop distcp -skipcrccheck ...
- 使用Karmada实现Helm应用的跨集群部署
摘要:借助Karmada原生API的支持能力,Karmada可以借助Flux轻松实现Helm应用的跨集群部署. 本文分享自华为云社区< 使用Karmada实现Helm应用的跨集群部署[云原生开源 ...
- KingbbaseES V8R6集群维护案例之---集群之间数据迁移
案例说明: 生产环境是集群环境,测试环境是集群,现需要将生产环境的数据迁移到测试集群中运行,本文档详细介绍了从集群环境迁移数据的操作步骤,可以作为生产环境迁移数据的参考. 适用版本: Kingbase ...
- Redis主从,集群部署及迁移
工作中有时会遇到需要把原Redis集群下线,迁移到另一个新的Redis集群的需求(如机房迁移,Redis上云等原因).此时原Redis中的数据需要如何操作才可顺利迁移到一个新的Redis集群呢? 本节 ...
- Elasticsearch 主从同步之跨集群复制
文章转载自:https://mp.weixin.qq.com/s/alHHxXont6XFm_m9PfsGfw 1.什么是跨集群复制? 跨集群复制(Cross-cluster replication, ...
- 实现Kubernetes跨集群服务应用的高可用
在Kubernetes 1.3版本,我们希望降低跨集群跨地区服务部署相关的管理和运营难度.本文介绍如何实现此目标. 注意:虽然本文示例使用谷歌容器引擎(GKE)来提供Kubernetes集群,您可以在 ...
- SqlServer跨集群升级
SqlServer跨集群升级 1.新Server的IP要和旧的在同一网段. 2.安装SQL SERVER(注意:排序要和以前的一样,更改TempDB位置) 3.开启防火墙,并打开1433和5022端口 ...
- Elasticsearch跨集群搜索(Cross Cluster Search)
1.简介 Elasticsearch在5.3版本中引入了Cross Cluster Search(CCS 跨集群搜索)功能,用来替换掉要被废弃的Tribe Node.类似Tribe Node,Cros ...
随机推荐
- OpenFOAM 编程 | One-Dimensional Transient Heat Conduction
0. 写在前面 本文中将对一维瞬态热传导问题进行数值求解,并基于OpenFOAM类库编写求解器.该问题参考自教科书\(^{[1]}\)示例 8.1. 1. 问题描述 一维瞬态热传导问题控制方程如下 \ ...
- 使用 EFKLK 搭建 Kubernetes 日志收集工具栈
转载自:https://mp.weixin.qq.com/s?__biz=MzU4MjQ0MTU4Ng==&mid=2247491992&idx=1&sn=a770252759 ...
- ProxySQL Main库
转载自:https://www.jianshu.com/p/eee03c5ec879 Main库表清单 Admin> SHOW TABLES FROM main; +-------------- ...
- 重要参考文档---MySQL 8.0.29 使用yum方式安装,开启navicat远程连接,搭建主从,读写分离(需要使用到ProxySQL,此文不讲述这个)
yum方式安装 echo "删除系统默认或之前可能安装的其他版本的 mysql" for i in $(rpm -qa|grep mysql);do rpm -e $i --nod ...
- 分布式文件存储 CephFS的应用场景
块存储 (适合单客户端使用) 典型设备:磁盘阵列,硬盘. 使用场景: a. docker容器.虚拟机远程挂载磁盘存储分配. b. 日志存储. 文件存储 (适合多客户端有目录结构) 典型设备:FTP.N ...
- 「国产系统」Tubian 0.3,兼容Windows和Android的GNU/Linux系统!
0.4版已发布:https://www.cnblogs.com/tubentubentu/p/16741197.html Sourceforge.net主页(提供下载):https://sourcef ...
- centos7中配置java + mysql +jdk +使用jar部署项目
centos7中配置java + mysql +jdk +使用jar部署项目 思维导图 1. 配置JDK環境 1.1下载jdk安装包 Java Downloads | Oracle 1.2 将下载j ...
- Pytorch及Yolov5环境配置及踩坑
Pytorch及Yolov5环境配置及踩坑 1.何为Yolov5 yolo是计算机视觉方面用来进行目标检测的一个十分出名的开源框架,我搜不到官方的对此概括性的定义,但实际上也没什么必要,更重要的是会使 ...
- [CG从零开始] 5. 搞清 MVP 矩阵理论 + 实践
在 4 中成功绘制了三角形以后,下面我们来加载一个 fbx 文件,然后构建 MVP 变换(model-view-projection).简单介绍一下: 从我们拿到模型(主要是网格信息)文件开始,模型网 ...
- 关于Oracle-VM-VirtualBox的安装与说明
VirtualBox 是一款开源虚拟机软件.VirtualBox 是由德国 Innotek 公司开发,由Sun Microsystems公司出品的软件 使用Qt编写,在 Sun 被 Oracle 收购 ...