Python 细聊从暴力(BF)字符串匹配算法到 KMP 算法之间的精妙变化
1. 字符串匹配算法
所谓字符串匹配算法,简单地说就是在一个目标字符串中查找是否存在另一个模式字符串。如在字符串 "ABCDEFG" 中查找是否存在 “EF” 字符串。
可以把字符串 "ABCDEFG" 称为原始(目标)字符串,“EF” 称为子字符串或模式字符串。
本文试图通过几种字符串匹配算法的算法差异性来探究字符串匹配算法的本质。
常见的字符串匹配算法:
- BF(Brute Force,暴力检索算法)
- RK (Robin-Karp 算法)
- KMP (D.E.Knuth、J.H.Morris、V.R.Pratt 算法)
2. BF(Brute Force,暴力检索)
BF 算法是一种原始、低级的穷举算法。
2.1 算法思想
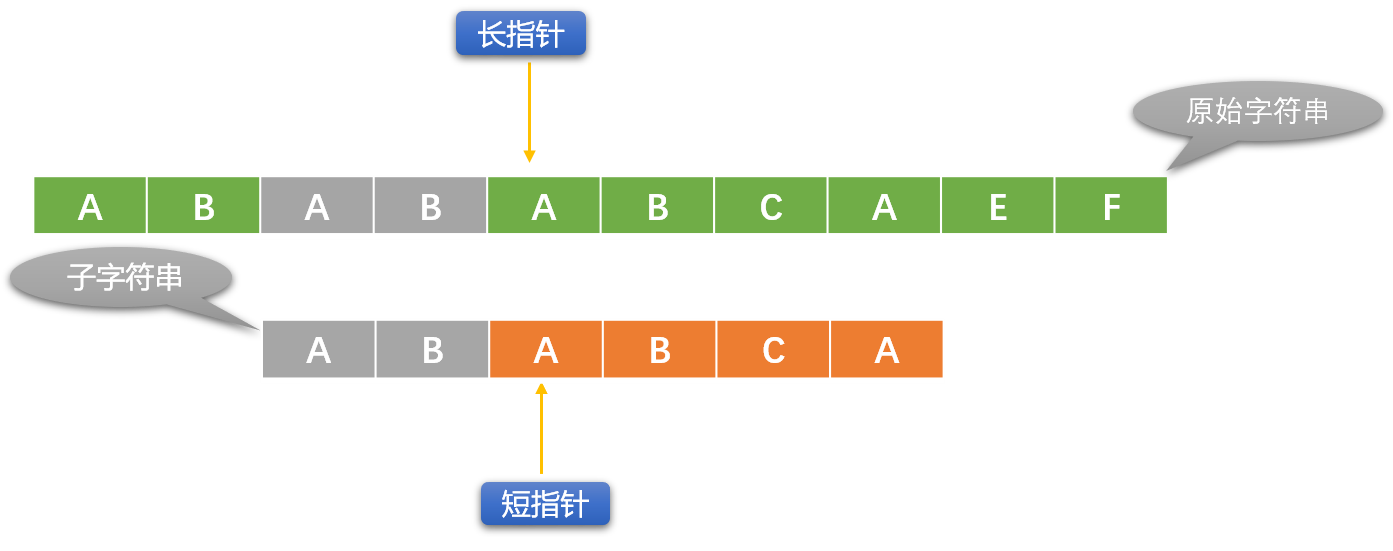
下面使用长、短指针方案描述 BF 算法:
初始指针位置: 长指针指向原始字符串的第一个字符位置、短指针指向模式字符串的第一个字符位置。这里引入一个辅助指针概念,其实可以不用。
辅助指针是长指针的替身,替长指针和短指针所在位置的字符比较。
每次初始化长指针位置时,让辅助指针和长指针指向同一个位置。

- 如果长、短指针位置的字符不相同,则长指针向右移动(短指针不动)。如果长、短指针所指位置的字符相同,则用辅助指针替代长指针(长指针位置暂不动)和短指针位置的字符比较,如果比较相同,则同时向右移动辅助指针和短指针。
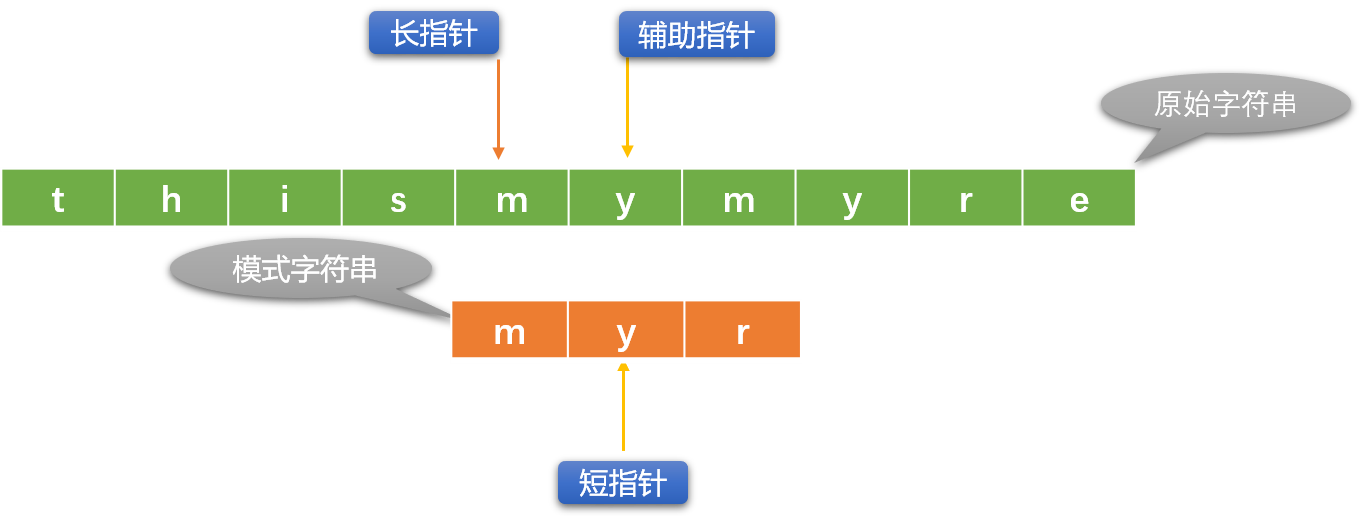
- 如果辅助指针和短指针位置的字符不相同,则重新初始化长指针位置(向右移动),短指针恢复到最原始状态。
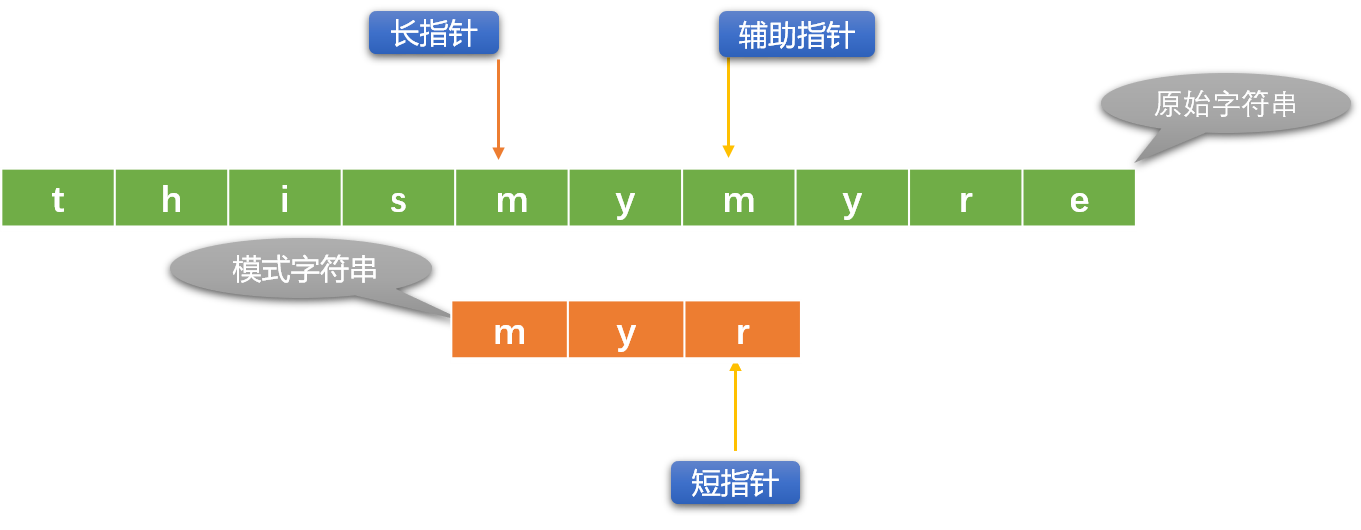
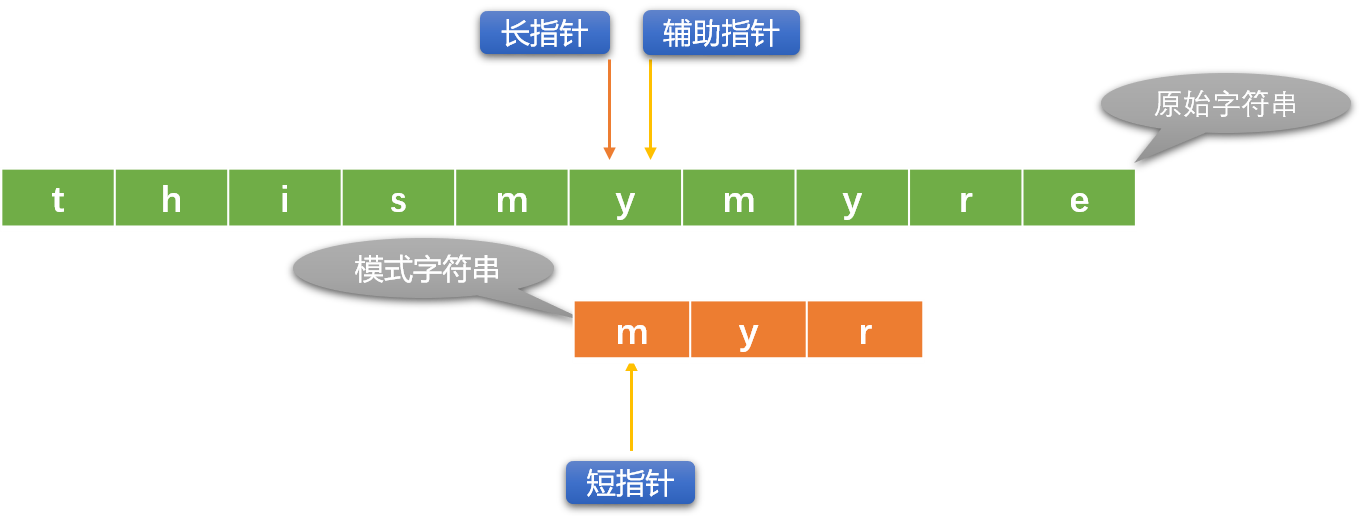
使用重复或者递归的方式重复上述流程,直到出口条件成立。
- 查找失败:长指针到达了原始字符串的尾部。当 长指针位置=原始字符串长度 - 模式字符串长度+1 时就可以认定查找失败。
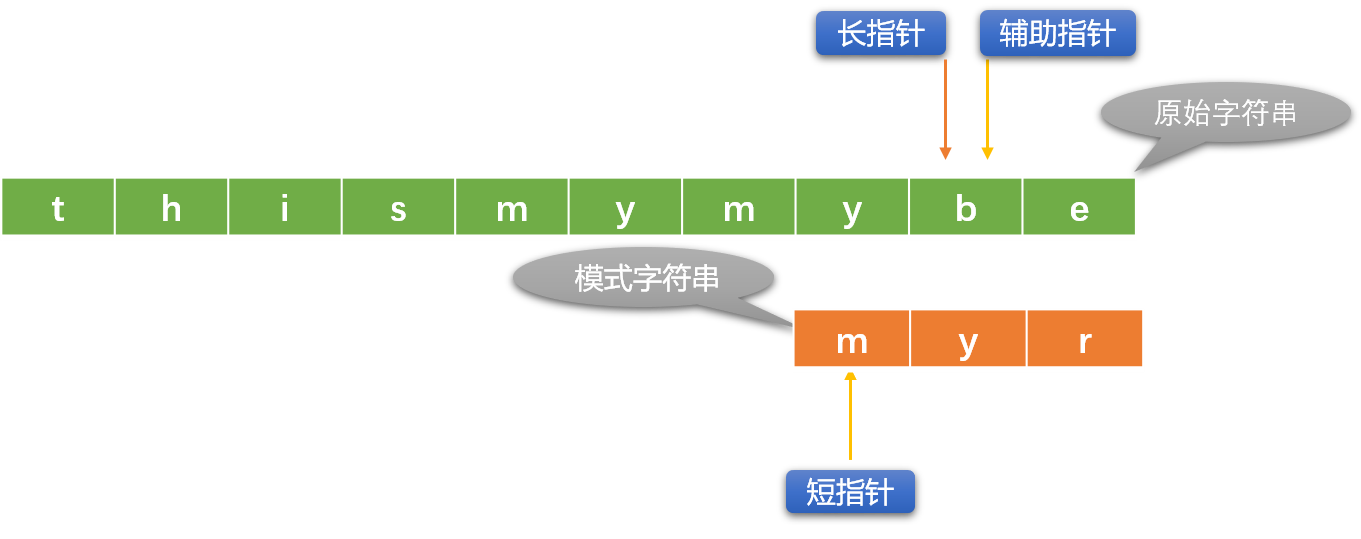
- 查找成功: 短指针到达模式字符串尾部。
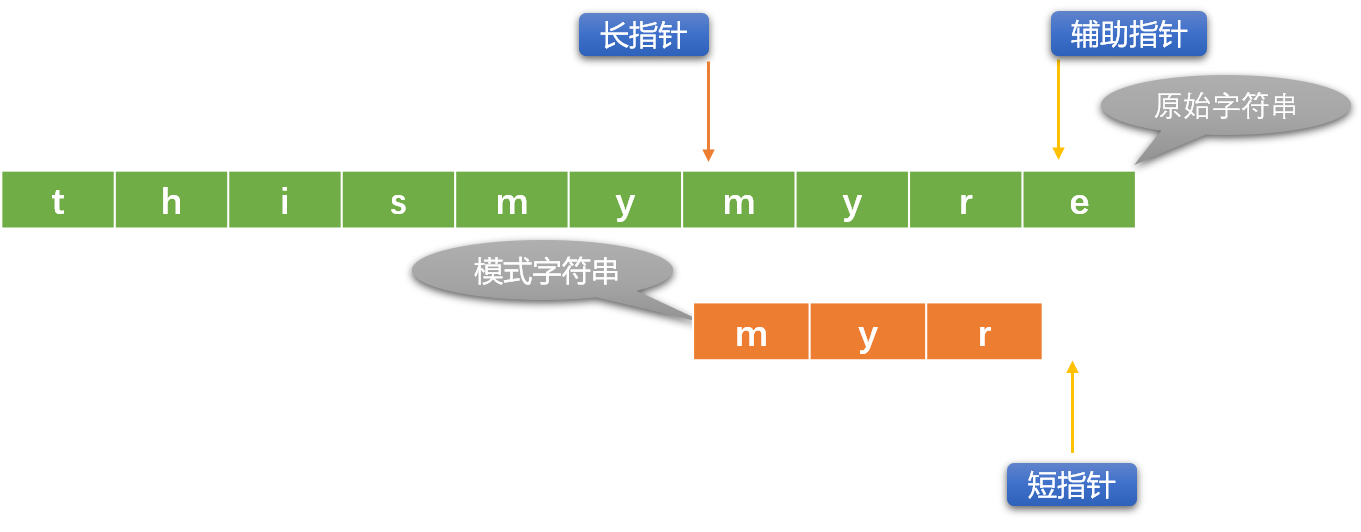
2.2 编码实现
使用辅助指针:
# 原始字符串
src_str = "thismymyre"
# 长指针
sub_str = "myr"
# 长指针 :在原始字符串上移动
long_index = 0
# 短指针:在模式字符串上移动
short_index = 0
# 辅助指针
fu_index = long_index
# 原始字符串长度
str_len = len(src_str)
# 模式字符串的长度
sub_len = len(sub_str)
# 是否存在
is_exist = False
while long_index < str_len-sub_len+1:
# 把长指针的位值赋给辅助指针
fu_index = long_index
# 短指针初始为原始位置
short_index = 0
while short_index < sub_len and src_str[fu_index] == sub_str[short_index]:
# 辅助指针向右
fu_index += 1
# 短指针向右
short_index += 1
if short_index == sub_len:
is_exist = True
break
# 比较不成功,则长指针向右移动
long_index += 1
if not is_exist:
print("{0} 不存在于 {1} 字符串中".format(sub_str, src_str))
else:
print("{0} 存在于 {1} 的 {2} 位置".format(sub_str, src_str, long_index))
使用一个增量:
# 原始字符串
src_str = "thisismymyrdodmyrd"
# 子子符串
sub_str = "myrd"
# 长指针
long_index = 0
# 短指针
short_index = 0
# 原始字符串长度
str_len = len(src_str)
# 模式字符串的长度
sub_len = len(sub_str)
is_exist = False
while long_index < str_len:
i = 0
short_index = 0
while short_index < sub_len and src_str[long_index + i] == sub_str[short_index]:
i += 1
# 短指针向右
short_index += 1
if short_index == sub_len:
is_exist = True
break
long_index += 1
if not is_exist:
print("{0} 不存在于 {1} 字符串中".format(sub_str, src_str))
else:
print("{0} 存在于 {1} 的 {2} 位置".format(sub_str, src_str, long_index))
使用或不使用辅助指针的代码逻辑是一样。
在原始字符串和模式字符串齐头并进逐一比较时,最好不要修改长指针的位置,否则,在比较不成功的情况下,则修正长指针的逻辑就没有单纯的直接向右移动那么好理解。
如下直接使用长指针和短指针进行比较:
# 原始字符串
src_str = "thisismymyrdodmyrd"
# 子子符串
sub_str = "myrd"
# 长指针
long_index = 0
# 短指针
short_index = 0
# 原始字符串长度
str_len = len(src_str)
# 模式字符串的长度
sub_len = len(sub_str)
is_exist = False
while long_index < str_len:
short_index = 0
# 直接使用长指针和短指针位置相比较
while short_index < sub_len and src_str[long_index] == sub_str[short_index]:
long_index+=1
# 短指针向右
short_index += 1
if short_index == sub_len:
is_exist = True
break
# 修正长指针的位置
long_index = long_index-short_index+1
if not is_exist:
print("{0} 不存在于 {1} 字符串中".format(sub_str, src_str))
else:
print("{0} 存在于 {1} 的 {2} 位置".format(sub_str, src_str, long_index-short_index))
使用字符串切片实现: 使用 Python 的切片实现起来更简单。但不利于初学者理解 BF 算法的细节。
# 原始字符串
src_str = "thisismymyrdodmyrd"
# 子子符串
sub_str = "myrd"
# 原始字符串长度
str_len = len(src_str)
# 模式字符串的长度
sub_len = len(sub_str)
is_exist = False
for index in range(str_len - sub_len + 1):
if src_str[index:index + sub_len] == sub_str:
is_exist = True
break
if not is_exist:
print("{0} 不存在于 {1} 字符串中".format(sub_str, src_str))
else:
print("{0} 存在于 {1} 的 {2} 位置".format(sub_str, src_str, index))
BF 算法的时间复杂度:
BF 算法直观,易于实现。但代码中有循环中嵌套循环的结构,这是典型的穷举结构。如果原始字符串的长度为 m ,模式字符串的长度为 n。时间复杂度则是 O(m*n),时间复杂度较高。
3. RK(Robin-Karp 算法)
RK算法 ( 指纹字符串查找) 在 BF 算法的基础上做了些改进,基本思路:
在模式字符串和原始字符串的字符准备开始逐一比较时,能不能通过一种算法,快速判断出本次比较是没有必要。

3.1 RK 的算法思想
选定一个哈希函数(可自定义)。
使用哈希函数计算模式字符串的哈希值。
如上计算 thia 的哈希值
再从原始字符串的开始比较位置起,截取一段和模式字符串长度一样的子串,也使用哈希函数计算哈希值。
如上计算 this 的哈希值
如果两次计算出来的哈希值不相同,则可判断两段模式字符串不相同,没有比较的必要。
如果两次计算的哈希值相同,因存在哈希冲突,还是需要使用 BF 算法进行逐一比较。
RK 算法使用哈希函数算法减少了比较次数。
3.2 编码实现:
# 原始字符串
src_str = "thisismymyrdodmyrd"
# 子子符串
sub_str = "myrd"
# 长指针
long_index = 0
# 短指针
short_index = 0
# 辅助指针
fu_index = 0
# 原始字符串长度
str_len = len(src_str)
# 模式字符串的长度
sub_len = len(sub_str)
is_exist = False
for long_index in range(str_len - sub_len + 1):
# 这里使用 python 内置的 hash 函数
if hash(sub_str) != hash(src_str[long_index:long_index + sub_len]):
# 哈希值一样就没有必要比较了
continue
# 把长指针的位置赋给辅助指针
fu_index = long_index
short_index = 0
while short_index < sub_len and src_str[fu_index] == sub_str[short_index]:
# 辅助指针向右
fu_index += 1
# 短指针向右
short_index += 1
if short_index == sub_len:
is_exist = True
break
if not is_exist:
print("{0} 不存在于 {1} 字符串中".format(sub_str, src_str))
else:
print("{0} 存在于 {1} 的 {2} 位置".format(sub_str, src_str, long_index))
RK 的时间复杂度:
RK 的代码结构和 BF 看起来一样,使用了循环嵌套。但内置循环只有当哈希值一样时才会执行,执行次数是模式字符串的长度。如果原始子符串长度为 m,模式字符串的长度为 n。则时间复杂度为 O(m+n),如果不考虑哈希冲突问题,时间复杂度为 O(m)。
很显然 RK 算法比 BF 算法要快很多。
4. KMP算法
算法的本质都是穷举,这是由计算机的思维方式决定的。我们在谈论"好"和“坏” 算法时,所谓好就是想办法让穷举的次数少一些。比如前面的 RK 算法,通过一些特性提前判断是否值得比较,这样可以省掉很多不必要的内循环。
KMP 也是一样,也是尽可能减少比较的次数。
4.1 KMP 算法思路:
KMP 的基本思路和 BF 是一样的(字符串逐一比较),BF 算法中,如果比较不成功,长指针每次只会向右移动一位。如下图:辅助指针和短指针对应位置字符不相同,说明比较失败。
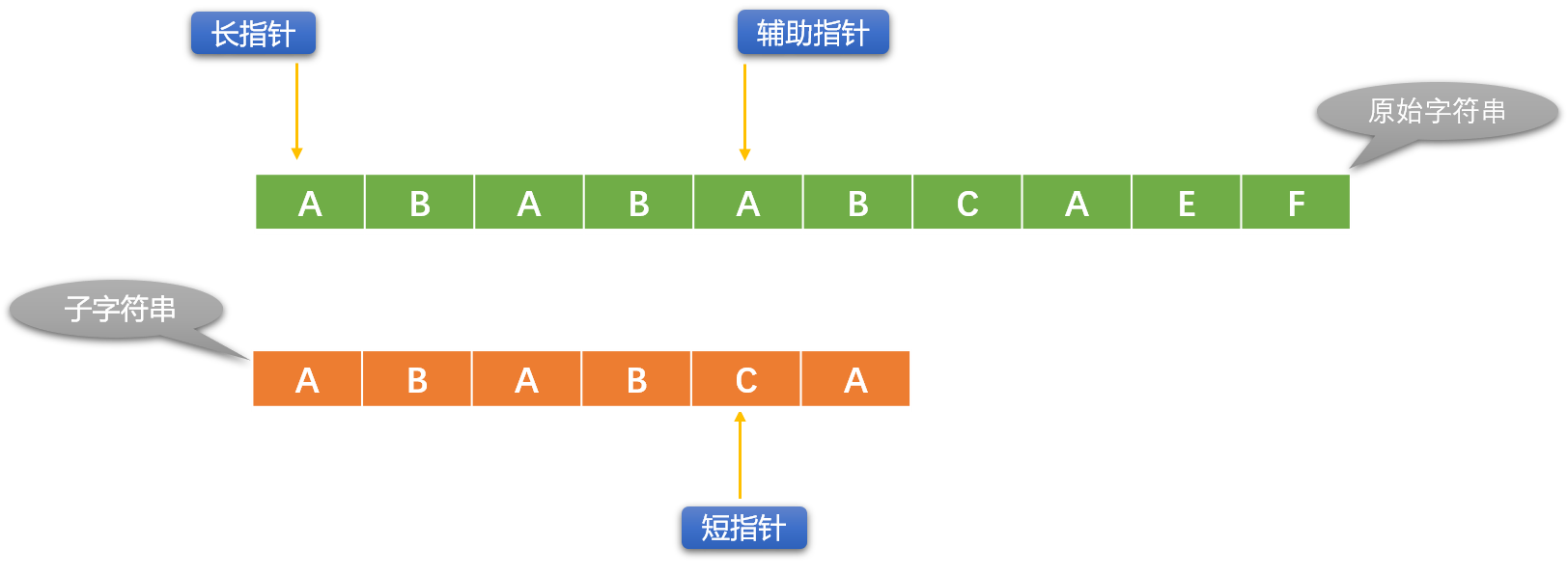
长指针向右移一位,短指针恢复原始状态。重新逐一比较。
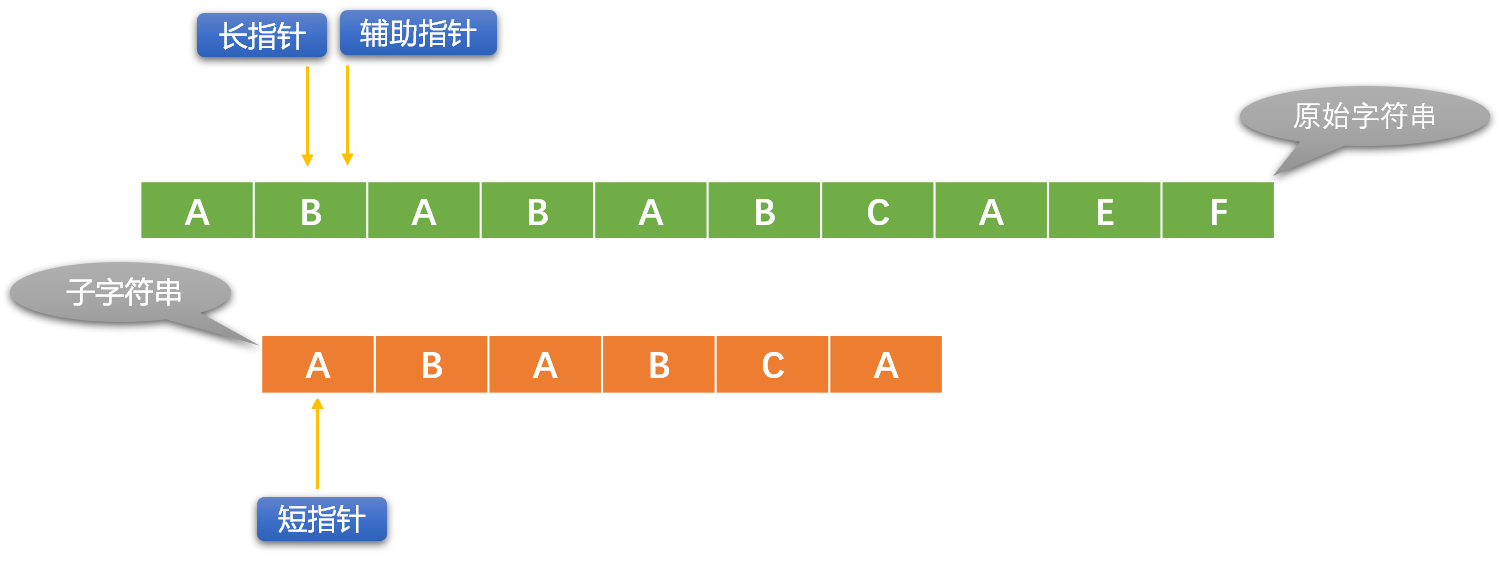
KMP 算法对长、短指针的移位做了优化。
- 没有必要再使用辅助指针。
- 直接把长指针和短指针所在位置的字符逐一比较。
- 比较失败后,长指针位置不动。根据 KMP 算法中事先计算好的 “部分匹配表(PMT:Partial Match Table)” 修改短指针的位置。
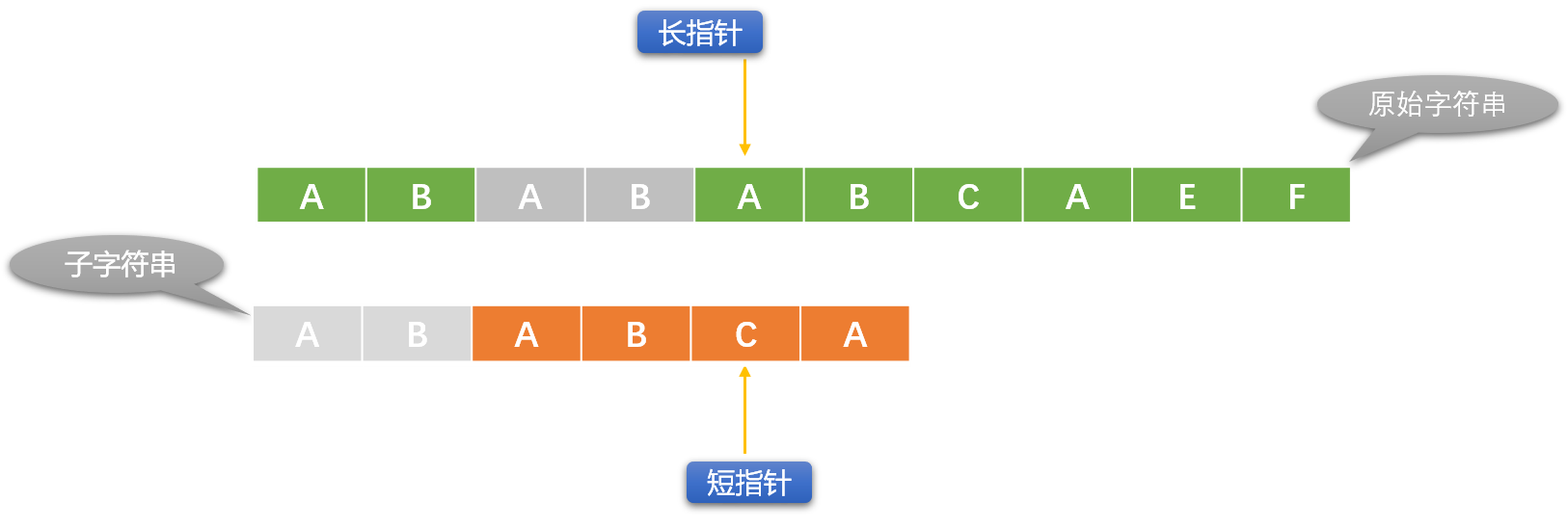
如上图比较失败后,长指针位置保持不变,只需要移动短指针。短指针具体移动哪里,由 PMT 表决定。上图灰色区域就是根据 PMT 表计算出来的可以不用再比较的字符。
在移动短指针之前,先要理解 KMP 算法中 的 "部分匹配表(PMT)" 是怎么计算出来的。
先理解与 PMT 表有关系的 3 个概念:
前缀集合:
如: ABAB 的前缀(不包含字符串本身)集合 {A,AB,ABA}
后缀集合:
如:ABAB 中后缀(不包含字符串本身)集合 { BAB,AB,B }
PMT值: 前缀、后缀两个集合的交集元素中最长元素的长度。
如:先求 {A,AB,ABA} 和 { BAB,AB,B } 的交集,得到集合 {AB} ,再得到集合中最长元素的长度, 所以 ABAB 字符串的 PMT 值是 2 。
如前面图示,原始字符串和模式字符串逐一比较时,前 4 位即 ABAB 是相同的,而 ABAB 存在最大长度的前缀和后缀 ‘AB’ 子串。意味着下一次比较时,可以直接让模式字符串的前缀和原始字符串中已经比较的字符串的后缀对齐,公共部分不用再比较。
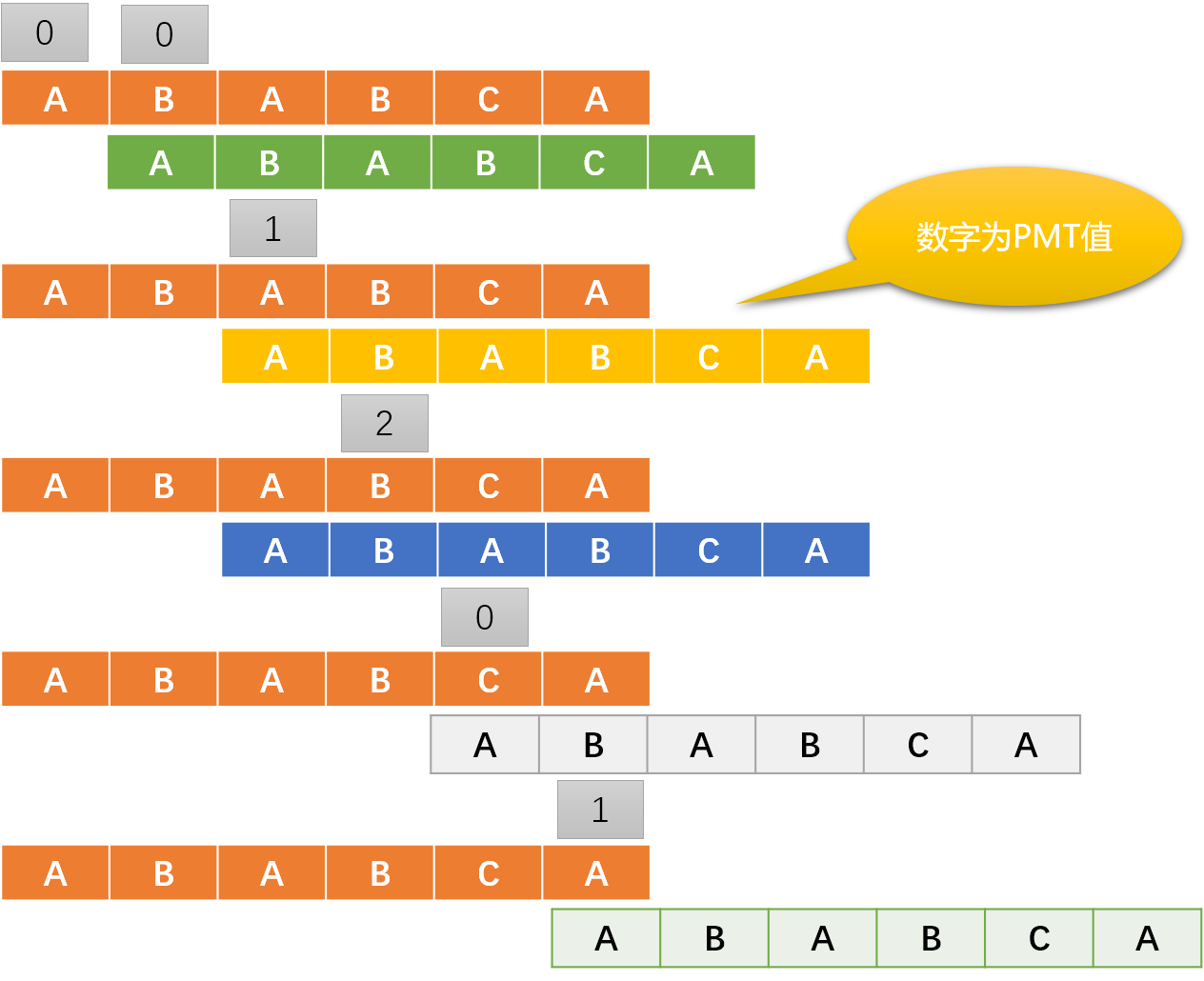
所以,KMP 算法的核心是得到 PMT 表,现使用手工方式计算 ABABCA 的 PMT 值:
当仅匹配第一个字符 A 时,A 没有前缀集合也没有后缀集合,所以 PMT[0]=0,短指针要移到模式字符串的 0 位置。
当仅匹配前二个字符 AB 时,AB的前缀集合{A},后缀集合是{B},没有交集,所以 PMT[1]=0,短指针要移到模式字符串的 0 位置。
当仅匹配前三个字符 ABA 时,ABA 的前缀集合{A,AB} ,后缀集合{BA,A},交集{A},所以 PMT[2]=1,短指针要移到模式字符串 1 的位置。
当仅匹配前四个字符 ABAB 时,ABAB 的前缀集合 {A ,AB,ABA },后缀集合{BAB,AB,B},交集{AB},所以 PMT[3]=2,短指针要移到模式字符串 2 的位置。
当仅匹配前五个字符 ABABC 时,ABABC 的前缀集合{ A,AB,ABA,ABAB },后缀集合{ C,BC,ABC,BABC },没有交集,所以PMT[4]=0,短指针要移到模式字符串的 0 位置。
当全部匹配后,ABABCA 的前缀是{A,AB,ABA,ABABC,ABABCA},后缀是{A,CA,BCA,ABCA,BABCA} 交集是{A},PMT[5]=1。

其实在 KMP 算法中,本没有直接使用 PMT 表,而是引入了next 数组的概念,next 数组中的值是 PMT 的值向右移动一位。

KMP算法实现: 先不考虑 next 数组的算法,先以上面的手工计算值作为 KMP 算法的已知数据。
src_str = 'ABABABCAEF'
sub_str = 'ABABCA'
# next 数组,现在不着急讨论 next 数组如何编码实现,先用上面手工推演出来的结果
p_next = [-1, 0, 0, 1, 2, 0]
# long_index 指向原始字符的第一个位置
long_index = 0
# short_index 指向模式字符串的第一个
short_index = 0
# 原始字符串的长度
src_str_len = len(src_str)
# 模式字符串的长度
sub_str_len = len(sub_str)
# 保存长指针、短指针位置有效 当长指针越界时,说明查找失败,当短指针越界,说明查找成功
while long_index < src_str_len and short_index < sub_str_len:
# 理论上 当长指针和短指针所在位置的字符相同时,长、短指针向右移动
# 如果长指针和短指针所在位置的字符不相同时,这里 -1 就起到神奇的作用,长指针可以前进,短指针会变成 0 。
# 下次比较时,如果还是不相同 short_index 又变回 -1, 长指针又可以前进,短指针还是指向 0 位置
if short_index == -1 or src_str[long_index] == sub_str[short_index]:
long_index += 1
short_index += 1
else:
short_index = p_next[short_index]
if short_index == sub_str_len:
print(long_index - short_index)
上面的代码是没有通用性的,因为 next 数组的值是固定的,现在实现求解 netxt 数组的算法:
求 next 也可以认为是一个字符串匹配过程,只是原始字符串和模式字符串都是同一个字符串,因第一个字符没有前缀也没有后缀,所以从第二个字符开始。
# 求解 next 的算法
def getNext(p):
i, j = 0, -1
m = len(p)
pnext = [-1] * m
while i < m - 1:
if j == -1 or p[i] == p[j]:
i += 1
j += 1
pnext[i] = j
else:
j = pnext[j]
return pnext
KMP算法的时间复杂度为 O(m+n)
5. 总结
字符串匹配算法除了上述几种外,还有 Sunday算法、Sunday算法。从暴力算法开始,其它算法可以尽可能减少比较的次数。加快算法的速度。
Python 细聊从暴力(BF)字符串匹配算法到 KMP 算法之间的精妙变化的更多相关文章
- 字符串匹配算法之 kmp算法 (python版)
字符串匹配算法之 kmp算法 (python版) 1.什么是KMP算法 KMP是三位大牛:D.E.Knuth.J.H.MorriT和V.R.Pratt同时发现的.其中第一位就是<计算机程序设计艺 ...
- 动画演示Sunday字符串匹配算法——比KMP算法快七倍!极易理解!
前言 上一篇我用动画的方式向大家详细说明了KMP算法(没看过的同学可以回去看看). 这次我依旧采用动画的方式向大家介绍另一个你用一次就会爱上的字符串匹配算法:Sunday算法,希望能收获你的点赞关注收 ...
- 字符串匹配算法之————KMP算法
上一篇中讲到暴力法字符串匹配算法,但是暴力法明显存在这样一个问题:一次只移动一个字符.但实际上,针对不同的匹配情况,每次移动的间隔可以更大,没有必要每次只是移动一位: 关于KMP算法的描述,推荐一篇博 ...
- 字符串匹配算法(三)-KMP算法
今天我们来聊一下字符串匹配算法里最著名的算法-KMP算法,KMP算法的全称是 Knuth Morris Pratt 算法,是根据三位作者(D.E.Knuth,J.H.Morris 和 V.R.Prat ...
- 字符串匹配算法之kmp算法
kmp算法是一种效率非常高的字符串匹配算法,是由Knuth,Morris,Pratt共同提出的模式匹配算法,所以简称KMP算法 算法思想 在一个字符串中查找另一个字符串时,会遇到如下图的情况 我们通常 ...
- 字符串匹配算法之Sunday算法(转)
字符串匹配算法之Sunday算法 背景 我们第一次接触字符串匹配,想到的肯定是直接用2个循环来遍历,这样代码虽然简单,但时间复杂度却是Ω(m*n),也就是达到了字符串匹配效率的下限.于是后来人经过研究 ...
- 字符串匹配算法之BM算法
BM算法,全称是Boyer-Moore算法,1977年,德克萨斯大学的Robert S. Boyer教授和J Strother Moore教授发明了一种新的字符串匹配算法. BM算法定义了两个规则: ...
- 字符串匹配算法(二)-BM算法详解
我们在字符串匹配算法(一)学习了BF算法和RK算法,那有没更加高效的字符串匹配算法呢.我们今天就来聊一聊BM算法. BM算法 我们把模式串和主串的匹配过程,可以看做是固定主串,然后模式串不断在往后滑动 ...
- 字符串匹配算法(KMP)
字符串匹配运用很广泛,举个简单例子,我们每天登QQ时输入账号和密码,大家有没有想过账号和密码是怎样匹配的呢?登录需要多长时间和匹配算法的效率有直接的关系. 首先理解一下前缀和后缀的概念: 给出一个问题 ...
随机推荐
- Solution -「CF 487E」Tourists
\(\mathcal{Description}\) Link. 维护一个 \(n\) 个点 \(m\) 条边的简单无向连通图,点有点权.\(q\) 次操作: 修改单点点权. 询问两点所有可能路 ...
- 前端生成PDF,让后端刮目相看
PDF 简介 PDF 全称Portable Document Format (PDF)(便携文档格式),该格式的显示与操作系统.分辨率.设备等因素没有关系,不论是在Windows,Unix还是在苹果公 ...
- 利用iptables做网络转发
常见的网络拓扑图结构如下: 但是内网服务器偶尔有上网需求,比如yum工具,wget文件.而我们又不能让重要业务直接暴露在公网上. 好用的安全策略有:三层交换机.路由器做nat映射,防火墙做安全策略. ...
- 每日一题:codeforces题解
题目 B. Peculiar Movie Preferences time limit per test 2 seconds memory limit per test 512 megabytes i ...
- Python_time库_特定字符串格式的时间、struct_time、时间戳的处理
time库 时间戳:格林威治时间1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数. # time.strptime(),功能:将特定字符串格 ...
- Stroke
// A simple blur shader, weighted on alphauniform sampler2D texture;void main(){ float radius = 0 ...
- 这个数据分析工具秒杀Excel,可视化分析神器!
入门Excel容易,想要精通就很难了,大部分人通过学习能掌握60%的基础操作,但是一些复杂数据可视化分析就需要用到各种技巧,操作理解难度加深 Excel作为一直是使用最广泛的数据表格工具,在数据量日 ...
- SUSCTF2022 Misc-AUDIO&RA2
前言:这次参加了susctf感受颇深,题目难度不是很大很大,但是很考验基础的技术熟练度,比如re这次就因为不会套脚本去解密,导致卡死在了第一道题,一道没做出来.所以只做了做misc和web. RA2 ...
- 【windows 操作系统】窗口指针 和 窗口句柄 有什么区别
句柄是指针的"指针" 指针对应着一个数据在内存中的地址,得到了指针就可以自由地修改该数据.Windows并不希望一般程序修改其内部数据结构,因为这样太不安全.所以Windows给每 ...
- 原生数据类型 nint,nuint,nfloat
原生数据类型根据操作系统32位 64位的不同,用这个关键定义的数据大小也不一样. 比如 nint 在 Xamarin.iOS 中,是 native int(原生整数)的缩写.当设备是 Apple 发布 ...