Tensorflor实现文本分类
下面我们使用CNN做文本分类
cnn实现文本分类的原理
下图展示了如何使用cnn进行句子分类。输入是一个句子,为了使其可以进行卷积,首先需要将其转化为向量表示,通常使用word2vec实现。d=5表示每个词转化为5维的向量,矩阵的形状是[sentence_length × 5],即[7 ×5]。6个filter(卷积核),与图像中使用的卷积核不同的是,nlp使用的卷积核的宽与句子矩阵的宽相同,只是长度不同。这里有(2,3,4)三种size,每种size有两个filter,一共有6个filter。然后开始卷积,从图中可以看出,stride是1,因为对于高是4的filter,最后生成4维的向量,(7-4)/1+1=4。对于高是3的filter,最后生成5维的向量,(7-3)/1+1=5。卷积之后,我们得到句子的特征,使用activation function和1-max-pooling得到最后的值,每个filter最后得到两个特征。将所有特征合并后,使用softmax进行分类。图中没有用到chanel,下文的实验将会使用两个通道,static和non-static,有相关的具体解释。
本文使用的模型
主要包括五层,第一层是embedding layer,第二层是convolutional layer,第三层是max-pooling layer,第四层是fully connected layer,最后一层是softmax layer.接下来依次介绍相关代码实现。
Input placeholder
# Placeholders for input, output and dropout
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")
self.input_y = tf.placeholder(tf.float32, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
tf.placeholder 创建一个占位符变量,在训练或者测试的时候,需要将占位符输入到网络中进行计算,其中的第二个参数是输入张量的形状。None 意味着它可以是任何维度的长度,在我们的实验中它代表批处理的大小,None使得网络可以处理任意长度的batches。
失活率同样也是输入的一部分,在训练的时候使用dropout ,测试的时候不使用dropout 。
EMBEDDING LAYER
这一层将单词索引映射到低维的向量表示,它本质上是一个查找表,我们从数据中通过学习得到。
with tf.device('/cpu:0'), tf.name_scope("embedding"):
W = tf.Variable(tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0), name="W")
self.embedded_chars = tf.nn.embedding_lookup(W, self.input_x)
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)
其中,W 是 在训练时得到的embedding matrix.,用随机均匀分布进行初始化。tf.nn.embedding_lookup 实现embedding操作,得到 一个3-dimensional 的张量,形状是 [None, sequence_length, embedding_size].sequence_length 是数据集中最长句子的长度,其他句子都通过添加“PAD”补充到这个长度。embedding_size是词向量的大小。
TensorFlow的卷积函数-conv2d 需要四个参数, 分别是batch, width, height 以及channel。 embedding之后不包括 channel, 所以我们人为地添加上它,并设置为1。现在就是[None, sequence_length, embedding_size, 1]
CONVOLUTION AND MAX-POOLING LAYERS
由图中可知, 我们有不同size的filters。因为每次卷积都会产生不同形状的张量,所以我们要遍历每个filter,然后将结果合并成一个大的特征向量。
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Max-pooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled)
# Combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(3, pooled_outputs)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])
这里W 是filter 矩阵,h 是对卷积结果进行非线性转换之后的结果。每个 filter都从整个embedding划过,不同之处在于覆盖多少单词。 “VALID” padding意味着没有对句子的边缘进行padding,也就是用了narrow convolution,输出的形状是 [1, sequence_length - filter_size + 1, 1, 1]。narrow convolution与 wide convolution的区别是是否对边缘进行填充。例如,对一个有7个词的句子来说, filter size是5,使用narrow convolution,输出的大小是(7-5)+1=3;使用wide convolution,输出的大小是(7+2*4-5)+1=11.
对输出进行max-pooling后得到形状是 [batch_size, 1, 1, num_filters] 的张量,本质上是一个特征向量,最后一个维度是特征代表数量。把每一个max-pooling之后的张量合并起来之后得到一个长向量[batch_size, num_filters_total]. in tf.reshape 中的 -1表示T将向量展平。
DROPOUT LAYER
Dropout也许是cnn中最流行的正则化方法。dropout的想法很简单,dropout layer随机地选择一些神经元,使其失活。这样可以阻止co-adapting,迫使它们每一个都学习到有用的特征。失活的神经单元个数由dropout_keep_prob 决定。在训练的时候设为 0.5 ,测试的时候设为 1 (disable dropout) .
# Add dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)
SCORES AND PREDICTIONS
利用特征向量,我们可以用矩阵相乘计算两类的得分,也可以用 softmax函数计算两类的概率值。
with tf.name_scope("output"):
W = tf.Variable(tf.truncated_normal([num_filters_total, num_classes], stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")
LOSS AND ACCURACY
可以用得分定义损失值。损失计算的是网络的误差,我们的目标是将其最小化,分类问题标准的损失函数是交叉熵损失。
# Calculate mean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(self.scores, self.input_y)
self.loss = tf.reduce_mean(losses)
计算正确率
# Calculate Accuracy
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
MINIMIZING THE LOSS
利用TensorFlow 内置的optimizers,例如 Adam optimizer,优化网络损失。
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(1e-4)
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
train_op 是一个新建的操作,我们可以在参数上进行梯度更新。每执行一次 train_op 就是一次训练步骤。 TensorFlow 可以自动地计算才那些变量是“可训练的”然后计算他们的梯度。通过global_step 这个变量可以计算训练的步数,每训练一次自动加一。
CHECKPOINTING
TensorFlow 中可以用checkpointing 保存模型的参数。checkpointing中的参数也可以用来继续训练。
# Checkpointing
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
# Tensorflow assumes this directory already exists so we need to create it
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.all_variables())
DEFINING A SINGLE TRAINING STEP
用一个batch的数据进行一次训练。
def train_step(x_batch, y_batch):
"""
A single training step
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: FLAGS.dropout_keep_prob
}
_, step, summaries, loss, accuracy = sess.run(
[train_op, global_step, train_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
train_summary_writer.add_summary(summaries, step)
train_op 什么也不返回,只是更新网络中的参数。最终,打印出当前训练的损失值与正确率。如果batch的size很小的话,这两者在不同的batch中差别很大。因为使用了dropout,训练的metrics可能要比测试的metrics糟糕。
同样的函数也可以用在测试时。
def dev_step(x_batch, y_batch, writer=None):
"""
Evaluates model on a dev set
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: 1.0
}
step, summaries, loss, accuracy = sess.run(
[global_step, dev_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
if writer:
writer.add_summary(summaries, step)
TRAINING LOOP
通过迭代数据进行训练。
# Generate batches
batches = data_helpers.batch_iter(
zip(x_train, y_train), FLAGS.batch_size, FLAGS.num_epochs)
# Training loop. For each batch...
for batch in batches:
x_batch, y_batch = zip(*batch)
train_step(x_batch, y_batch)
current_step = tf.train.global_step(sess, global_step)
if current_step % FLAGS.evaluate_every == 0:
print("\nEvaluation:")
dev_step(x_dev, y_dev, writer=dev_summary_writer)
print("")
if current_step % FLAGS.checkpoint_every == 0:
path = saver.save(sess, checkpoint_prefix, global_step=current_step)
print("Saved model checkpoint to {}\n".format(path))
VISUALIZING RESULTS IN TENSORBOARD

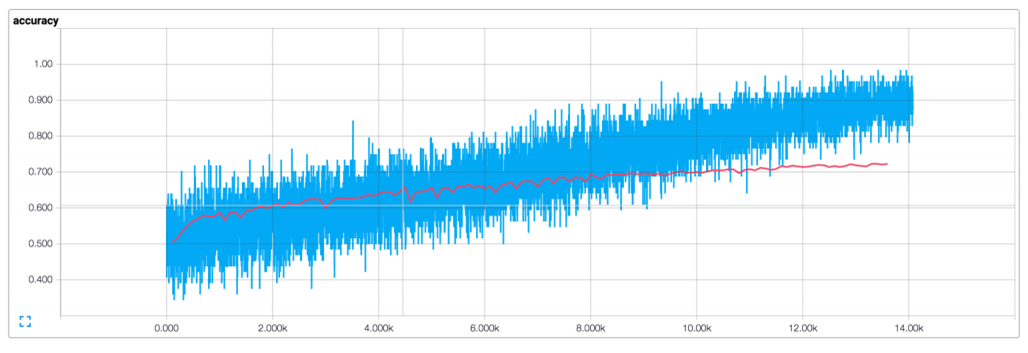
从上图中我们可以观察到:
- 我们的训练 metrics不平滑,因为用的batch sizes很小。如果用大的batches (或者在整个测试集上进行评估),会得到平滑的线。
- 测试集的 accuracy明显比训练集的低,说明网络过拟合了,我们应该用更大的数据集,更强的正则化,更少的模型参数。
- 训练集上的 loss 和 accuracy比测试集低的原因是用了dropout.
Tensorflor实现文本分类的更多相关文章
- Tensorflow二分类处理dense或者sparse(文本分类)的输入数据
这里做了一些小的修改,感谢谷歌rd的帮助,使得能够统一处理dense的数据,或者类似文本分类这样sparse的输入数据.后续会做进一步学习优化,比如如何多线程处理. 具体如何处理sparse 主要是使 ...
- Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案
Atitti 文本分类 以及 垃圾邮件 判断原理 以及贝叶斯算法的应用解决方案 1.1. 七.什么是贝叶斯过滤器?1 1.2. 八.建立历史资料库2 1.3. 十.联合概率的计算3 1.4. 十一. ...
- 基于weka的文本分类实现
weka介绍 参见 1)百度百科:http://baike.baidu.com/link?url=V9GKiFxiAoFkaUvPULJ7gK_xoEDnSfUNR1woed0YTmo20Wjo0wY ...
- LingPipe-TextClassification(文本分类)
What is Text Classification? Text classification typically involves assigning a document to a catego ...
- 文本分类之特征描述vsm和bow
当我们尝试使用统计机器学习方法解决文本的有关问题时,第一个需要的解决的问题是,如果在计算机中表示出一个文本样本.一种经典而且被广泛运用的文本表示方法,即向量空间模型(VSM),俗称“词袋模型”. 我们 ...
- R语言做文本挖掘 Part4文本分类
Part4文本分类 Part3文本聚类提到过.与聚类分类的简单差异. 那么,我们需要理清训练集的分类,有明白分类的文本:測试集,能够就用训练集来替代.预測集,就是未分类的文本.是分类方法最后的应用实现 ...
- Spark ML下实现的多分类adaboost+naivebayes算法在文本分类上的应用
1. Naive Bayes算法 朴素贝叶斯算法算是生成模型中一个最经典的分类算法之一了,常用的有Bernoulli和Multinomial两种.在文本分类上经常会用到这两种方法.在词袋模型中,对于一 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- 文本分类学习 (五) 机器学习SVM的前奏-特征提取(卡方检验续集)
前言: 上一篇比较详细的介绍了卡方检验和卡方分布.这篇我们就实际操刀,找到一些训练集,正所谓纸上得来终觉浅,绝知此事要躬行.然而我在躬行的时候,发现了卡方检验对于文本分类来说应该把公式再变形一般,那样 ...
随机推荐
- 笨办法学Python(二十九)
习题 29: 如果(if) 下面是你要写的作业,这段向你介绍了“if语句”.把这段输入进去,让它能正确执行.然后我们看看你是否有所收获. people = 20 cats = 30 dogs = 15 ...
- Wampserver由橙变绿的解决过程
因为C盘的内存问题,就重装了win7系统,那么就面临着很对软件要重新进行安装,安装wampserver时,再次遇到了服务器的图标一直是橙色的而不变绿色,安装包地址: http://download.c ...
- April 23 2017 Week 17 Sunday
It is a characteristic of wisdom not to do desperate things. 不做孤注一掷的事情是智慧的表现. We are told that we ha ...
- 使用函数BAPISDORDER_GETDETAILEDLIST读取S/4HANA中Sales Order行项目数据
事务码MM03查看物料主数据,如下图所示的行项目数据,包含物料ID,描述信息,数量,单价等等: 使用如下代码进行行项目读取: DATA: ls_read TYPE order_view, lt_ite ...
- openstack kilo python cinderclient
➜ ~ pythonPython 2.7.5 (default, Oct 30 2018, 23:45:53) [GCC 4.8.5 20150623 (Red Hat 4.8.5-36)] on ...
- numpy+pandas+matplotlib+tushare股票分析
一.数据导入 安装tushare模块包 pip install tushare http://tushare.org/ tushare是一个财经数据接口包 import numpy as np imp ...
- spring中使用i18n(国际化)
简单了解i18n i18n(其来源是英文单词internationalization的首末字符i和n,18为中间的字符数)是“国际化”的简称.在资讯领域,国际化(i18n)指让产品(出版物,软件,硬件 ...
- url 解析
最近在做一个单页应用,使用AngularJS来处理一些页内路由(哈希#后的路由变化).自然会要解析URL中的参数.使用AngularJS自带的方法$location.search();可以自动将参数整 ...
- Juery返回Json数据格式,webForm中使用
此篇的详细篇 //webForm中使用异步就会用到一般处理程序,前台调用一般处理程序这个页面去执行里面的方法 using System.Web.Script.Serialization; Newton ...
- (转)ActionContext和ServletActionContext
前面已经了解到ActionContext是Action执行时的上下文,里面存放着Action在执行时需要用到的对象,我们也称之为广义值栈. Struts2在每次执行Action之前都会创建新的Acti ...