【linux高级程序设计】(第十三章)Linux Socket网络编程基础
IP地址定义:
struct in_addr{
__u32 s_addr;
};
in_addr_t inet_addr (__const char * __cp) :把点分十进制IP地址字符串转换为32位IP地址(网络存储顺序)。
in_addr_t inet_network (__const char * __cp) :把点分十进制IP地址字符串转换为32位IP地址(主机字节顺序)。
char * inet_ntoa (struct in_addr_in) :把32位网络字节顺序的IP地址转换成点分十进制表示。
int inet_aton (__const char *__cp, struct in_addr *__inp) :把点分十进制IP地址字符串转换为32位IP地址(网络字节顺序)。第二个参数是转换结果地址。成功返回0。与第一个函数功能相同。
#include<arpa/inet.h>
#include<netinet/in.h>
#include<stdio.h>
#include<string.h>
#include<sys/socket.h>
int main(int argc, char *argv[])
{
in_addr_t net;
struct in_addr net_addr, ret;
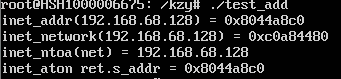
net = inet_addr("192.168.68.128");
net_addr.s_addr = net;
//把点分十进制转换为网络存储顺序的IP
printf("inet_addr(192.168.68.128) = 0x%x\n", inet_addr("192.168.68.128"));
//把点分十进制转换为主机存储顺序的IP
printf("inet_network(192.168.68.128) = 0x%x\n", inet_network("192.168.68.128"));
//把网络存储顺序的IP转换为点分十进制
printf("inet_ntoa(net) = %s\n", inet_ntoa(net_addr));
inet_aton("192.168.68.128", &ret);
printf("inet_aton ret.s_addr = 0x%x\n", ret.s_addr);
}
基于地址类型转换
int inet_pton (int __af, __const char *__restrict __cp, void *__restrict __buf) :将存储在起始位置为cp、地址协议类型为AF的点分十进制地址转换到buf中。如果IPv4,buf应为in_addr型,如果IPv6,buf应为in6_addr型。
char * inet_ntop (int __af, __const void *__restrict __cp, char *__restrict __buf, socklen_t __len) :将网络字节顺序存储的IP地址转为点分十进制。如果IPv4,cp应为in_addr型,如果IPv6,cp应为in6_addr型。
#include<arpa/inet.h>
#include<netinet/in.h>
#include<stdio.h>
#include<string.h>
#include<sys/socket.h>
int main(int argc, char *argv[])
{
in_addr_t net;
struct in_addr net_addr, ret;
char buf[];
inet_pton(AF_INET, "192.168.68.128", &ret);
inet_ntop(AF_INET, &ret, buf, );
printf("buf = %s\n", buf);
}

in_addr_t inet_lnaof (struct in_addr __in) :从32位网络顺序IP地址中提取主机ID。
in_addr_t inet_netof (struct in_addr __in) :从32位网络顺序IP地址中提取网络ID。
struct in_addr inet_makeaddr (in_addr_t __net, in_addr_t __host) :把主机ID和网络ID合成一个IP地址。
IP数据报包头数据结构定义:

TCP包头信息结构体


UDP包头信息结构体

大小端原理
一个整数 0x12345678 中12是高字节,78是低字节
CPU处理数据有大端小端两种方式
小端模式:高字节放在高地址
大端模式:高字节放在低地址
检测当前系统字节顺序:
#include<stdio.h>
#include<endian.h>
int main(void)
{
printf("Big-endian:\t%d\nLittle-endian:\t%d\nmine:\t%d\n", __BIG_ENDIAN, __LITTLE_ENDIAN, __BYTE_ORDER);
return ;
}

共用体检测系统大小端
对于结构体
union word
{
int a;
char b;
}c;
b在基地址开始存储或保存
#include<stdio.h>
#include<stdlib.h>
union word
{
int a;
char b;
}c;
int checkCPU(void)
{
c.a = ;
return (c.b == );
}
int main(void)
{
int i;
i = checkCPU();
if(i == )
printf("this is Big_endian\n");
else if(i == )
printf("this is Little_endian\n");
return ;
}

字节顺序转换函数
unsigned long int ntohl (unsigned long int) :long 网络字节顺序 转为 主机字节顺序
unsigned long int htonl (unsigned long int) :long 主机字节顺序 转为 网络字节顺序
unsigned short int ntohs (unsigned short int) :short 网络字节顺序 转为 主机字节顺序
unsigned short int htons (unsigned short int) :short 主机字节顺序 转为 网络字节顺序
网络编程统一使用大端模式!
----------------------------------------------------------------------------
插播知识点 #pragma pack(1) 的用途
设置结构体的边界对齐为1个字节,也就是所有数据在内存中是连续存储的。
比如你在C语言中定义下面这样的结构体:
struct s {
char ch;
int i;
};
然后在主函数中写一句:printf("%d", sizeof(struct s))
也就是输出结构体s所占的字节数
你觉得输出结果会是多少呢?
我们知道,char型占用1个字节,int型占4个字节,那么输出的结果是5吗?
答案是否定的。你可以自己试一下,输出结果为8。
为什么会这样呢?这是因为编译器为了让程序跑得跟快,减少CPU读取数据的指令周期,对结构体的存储进行了优化。实际上第一个char型成员虽然本来只有1个字节,但实际上却占用掉了4个字节,为的是让第二个int型成员的地址能够被4整除。因此实际占用的是8个字节。
而#pragma pack(1)让编译器将结构体数据强制连续排列,这样的话,sizeof(struct s)输出的结果就是5了。
------------------------------------------------------------------------------------------------
在数据传输时统一转换大小端的处理:
1.单字节数据,不需要转换大小端。如char buf[] = "Hello"
2.多字节数据,用字节顺序转换函数
3.自定义结构体:如果双方都知道结构体内成员,可以一个成员一个成员的转换
也可以用#pragm pack(1) 处理, 让两边字节对齐方式一致, 整体转换。
【linux高级程序设计】(第十三章)Linux Socket网络编程基础的更多相关文章
- 【linux高级程序设计】(第十三章)Linux Socket网络编程基础 2
BSD Socket网络编程API 创建socket对象 int socket (int __domain, int __type, int __protocol) :成功返回socket文件描述符, ...
- Socket网络编程-基础篇
Socket网络编程 网络通讯三要素: IP地址[主机名] 网络中设备的标识 本地回环地址:127.0.0.1 主机名:localhost 端口号 用于标识进程的逻辑地址 有效端口:0~65535 其 ...
- python全栈开发从入门到放弃之socket网络编程基础
网络编程基础 一 客户端/服务器架构 1.硬件C/S架构(打印机) 2.软件C/S架构 互联网中处处是C/S架构 如黄色网站是服务端,你的浏览器是客户端(B/S架构也是C/S架构的一种) 腾讯作为服务 ...
- 第九章:Python の 网络编程基础(一)
本課主題 何为TCP/IP协议 初认识什么是网络编程 网络编程中的 "粘包" 自定义 MySocket 类 本周作业 何为TCP/IP 协议 TCP/IP协议是主机接入互网以及接入 ...
- 【linux高级程序设计】(第十三章)Linux Socket网络编程基础 4
网络调试工具 tcpdump 功能:打印指定网络接口中与布尔表达式匹配的报头信息 关键字: ①类型:host(默认).net.port host 210.27.48.2 //指明是一台主机 net 2 ...
- 第十三章:Python の 网络编程进阶(二)
本課主題 SQLAlchemy - Core SQLAlchemy - ORM Paramiko 介紹和操作 上下文操作应用 初探堡垒机 SQLAlchemy - Core 连接 URL 通过 cre ...
- 第十三篇:socket网络编程
本篇主要介绍网络编程的基础,以及UDP/TCP网络的socket编程,关于UDP套接字聊天器的实现.以及基于TCP套接字的服务器/客户端的实现上传下载功能. 一.网络通信 关于网络通信即通过网络(介质 ...
- socket网络编程基础小记
"一切皆Socket!" 话虽些许夸张.可是事实也是,如今的网络编程差点儿都是用的socket. --有感于实际编程和开源项目研究. 我们深谙信息交流的价值,那网络中进程之间怎样通 ...
- java架构《Socket网络编程基础篇》
本章主要介绍Socket的基本概念,传统的同步阻塞式I/O编程,伪异步IO实现,学习NIO的同步非阻塞编程和NIO2.0(AIO)异步非阻塞编程. 目前为止,Java共支持3种网络编程模型:BIO.N ...
随机推荐
- 手把手写代码学习C语言基础
- 小白日记54:kali渗透测试之Web渗透-补充概念(AJAX,WEB Service)
补充概念 AJAX(异步javascript和XML) Asynchronous javascript and xml 是一个概念,而非一种新的编程语言,是一组现有技术的组合 通过客户端脚本动态更新页 ...
- Hibernate---数据操作示例BY实体类注释
通过实体的映射文件创建表的示例,除了基本jar包外,还需要jar包如下 ejb3-persistence.jar.hibernate-annotations.jar这两个包均在hibernate-an ...
- Javascript Step by Step - 02
DOM 操作 DOM是面向HTML和XML文档的API,为文档提供了结构化表示.在DOM中一切都是节点Node,文档就是由许多的Node组成的.文档里的每个节点都有属性 nodeName.nodeVa ...
- AD RMS总结
AD RMS 认识篇 AD RMS(Active Directory Right Mangement Servic)活动目录权限服务. 首先我通过了解AD RMS的用途去深入学习AD RMS.在过去用 ...
- 【APUE】Chapter8 Process Control
这章的内容比较多.按照小节序号来组织笔记的结构:再结合函数的示例带代码标注出来需要注意的地方. 下面的内容只是个人看书时思考内容的总结,并不能代替看书(毕竟APUE是一本大多数人公认的UNIX圣经). ...
- 通过命令行安装或卸载Tomcat服务
一.安装Tomcat服务 1.打开命令提示符 方法1: 按住win+R,打开运行,输入cmd,打开命令提示符 方法2:在开始菜单>所有程序>附件>命令提示符 2. 通过命令进入到to ...
- Oracle 数据库导出时 EXP-00008;ORA-00904
问题是客户端和服务器端版本问题,我本地是11g,而服务器端是10g. 规则1:低版本的exp/imp可以连接到高版本(或同版本)的数据库服务器,但高版本的exp/imp不能连接到低版本的数据库服务器. ...
- 为啥shmem不回收 | drop_caches
内核在哪里禁止对tmpfs中内存页的回收 mem.limit_in_bytes同样会触发shrink_zones过程! shrink_zones是代码中的直接内存回收路径 1.try_to_free_ ...
- Scala 基础(4)—— 类和对象
1. 类.字段和方法 Scala 用 class 关键字定义类,一旦定义好一个类,就可以使用 new 关键字创建对象. Scala 使用 new 调用无参构造器时,可以不使用 (),推荐不使用括号: ...