机器学习:逻辑回归(scikit-learn 中的逻辑回归)
一、基础理解
- 使用逻辑回归算法训练模型时,为模型引入多项式项,使模型生成不规则的决策边界,对非线性的数据进行分类;
- 问题:引入多项式项后,模型变的复杂,可能产生过拟合现象;
- 方案:对模型正则化处理,损失函数添加正则项(αL2),生成新的损失函数,并对新的损失函数进行优化;
- 优化新的损失函数:
- 满足了让原来的损失函数尽量的小;
- 另一方面,对于 L2 正则项(包含参数 θ 值),限制 θ 的大小;
- 引入了参数 α ,调节新的损失函数中两部分(原损失函数和 L2 正则项)的重要程度;当然也可以引入 αL1 正则项;
二、正则化的其它方式
- 新的表达正则化的方式:只是方式不同,正则化的原来一样;

- 改变了超参数的位置:α、C;
- 如果超参数 C 越大,原损失函数 J(θ) 的地位相对较重要,优化损失函数时主要集中优化 J(θ) ,使其减少到最小;
- 如果超参数 C 非常小,正则项 L2 的地位相对较重要,优化损失函数时主要集中优化 L2 ,使参数 θ 中的元素尽量的小;
- 如果想让使正则项不重要,需要增大参数 C;
- 其实在 J(θ) 前加参数 C,相当于将原来的 αL2 变为 1/αL2 ,两中方式等效;
- α、C:平衡新的损失函数中两部分的关系;
- 在逻辑回归、SVM算法中,更偏好使用 C.J(θ) + L2 的方式;scikit-learn 的逻辑回归算法中,也是使用此方式;
- 原因:使用 C.J(θ) + L2 方式时,正则项的系数为 1,也就是说优化算法模型时不得不使用正则化;
三、思考
- 多项式回归:假设在特征空间中,样本的分布规律呈多项式曲线状态,可能类似 2 次多项式曲线,也可能是 3 次多项式的曲线,也可能是 n 次多项式的曲线;
- n 次多项式曲线:y = xn + ...,最高 n 次方,还有其他很多项,x 与 y 的关系曲线;
- 疑问1:是不是二维空间的所有不规则曲线都存在一个多项式与其对应?
- 疑问2:如果样本分布规律不是多项式曲线的规律,再使用多项式回归算法,或者逻辑回归的多项式形式进行分类,是不是就不准确?
- 思考:解决具体的问题,通过可视化查看样本相根据特征大致的分布,再判断可以使用哪些算法,组个尝试,找个最合适的一个;
- 最合适:准确度高、效率高;
四、实例scikit-learn中的逻辑回归算法
- scikit-learn中的逻辑回归算法自动封装了模型的正则化的功能,只需要调整 C 和 penalty;
- 主要参数:degree、C、penalty;(还有其它参数)
1)直接使用逻辑回归算法
import numpy as np
import matplotlib.pyplot as plt np.random.seed(666)
X = np.random.normal(0, 1, size=(200, 2))
y = np.array(X[:,0]**2 + X[:,1] < 1.5,dtype='int') # 随机抽取 20 个样本,让其分类为 1,相当于认为更改数据,添加噪音
for _ in range(20):
y[np.random.randint(200)] = 1 plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()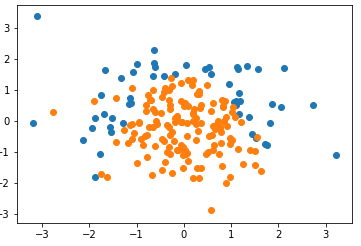
- 为虚拟的测试数据设置种子 666:则每次执行 np.random.normal(0, 1, size=(200, 2)) 时,随机生成的 X 不变;
- 随机生成数据是系统内定的,随机种子是系统随机生成数据时的依据,只要设定的随机种子相同,所有人生成的数据一样;(待考察)
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666) from sklearn.linear_model import LogisticRegression log_reg = LogisticRegression()
log_reg.fit(X_train, y_train)
# LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
C=1.0:默认超参数 C 的值为1.0;
- penalty='l2':默认使用 L2 正则项;
def plot_decision_boundary(model, axis): x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()] y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape) from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) plot_decision_boundary(log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()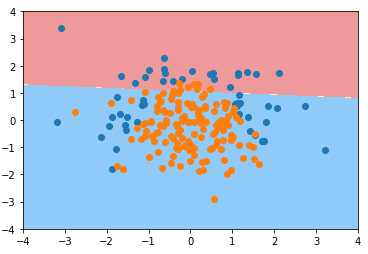
2)为逻辑回归算法的模型添加多项式项
degree = 2、C 默认1.0
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler def PolynomialLogisticRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
]) # 使用管道时,先生成实例的管道对象,在进行 fit;
poly_log_reg = PolynomialLogisticRegression(degree=2)
poly_log_reg.fit(X_train, y_train) plot_decision_boundary(poly_log_reg, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
degree = 20、C 默认1.0
poly_log_reg2 = PolynomialLogisticRegression(degree=20)
poly_log_reg2.fit(X_train, y_train) plot_decision_boundary(poly_log_reg2, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
degree = 20、C = 0.1
def PolynomialLogisticRegression(degree, C):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C))
]) poly_log_reg3 = PolynomialLogisticRegression(degree=20, C=0.1)
poly_log_reg3.fit(X_train, y_train) plot_decision_boundary(poly_log_reg3, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()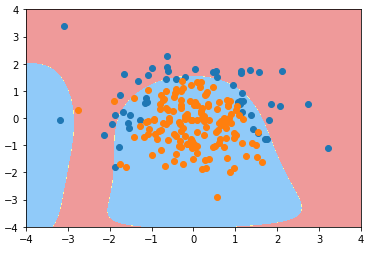
degree = 20、C = 0.1、penalty = 'L1'(penalty:正则项类型, 默认为 L2)
def PolynomialLogisticRegression(degree, C, penalty='l2'):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C, penalty=penalty))
]) poly_log_reg4 = PolynomialLogisticRegression(degree=20, C=0.1, penalty='l1')
poly_log_reg4.fit(X_train, y_train) plot_decision_boundary(poly_log_reg4, axis=[-4, 4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()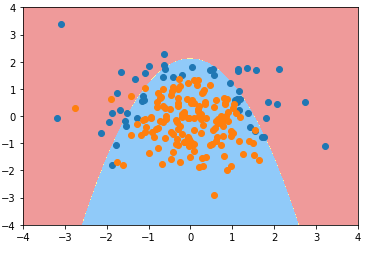
- 分析:degree = 20,模型的决策边界太复杂,模型可能过拟合,使用 L1 正则项进行模型的正则化;
- 分析2:模型过拟合后,有很多多项式项,使用 L1 正则项,使得这些多项式项的系数为 0,进而使模型决策边界更加规则,不会弯弯曲曲,便于可视化;
机器学习:逻辑回归(scikit-learn 中的逻辑回归)的更多相关文章
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- Andrew Ng机器学习课程笔记(二)之逻辑回归
Andrew Ng机器学习课程笔记(二)之逻辑回归 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7364636.html 前言 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- 机器学习之感知器和线性回归、逻辑回归以及SVM的相互对比
线性回归是回归模型 感知器.逻辑回归以及SVM是分类模型 线性回归:f(x)=wx+b 感知器:f(x)=sign(wx+b)其中sign是个符号函数,若wx+b>=0取+1,若wx+b< ...
- SQL Server 中的逻辑读与物理读
首先要理解逻辑读和物理读: 预读:用估计信息,去硬盘读取数据到缓存.预读100次,也就是估计将要从硬盘中读取了100页数据到缓存. 物理读:查询计划生成好以后,如果缓存缺少所需要的数据,让缓存再次去读 ...
- SQL SERVER中的逻辑读取,物理读取,以及预读的理解
在SQLSERVER查询分析器中,当我们用Set Statistics on 语句来统计SQL语句或者存储过程I/O的时候, SQLSERVER会显示几个概念去词语:逻辑读取,物理读取,预读. 如下: ...
- WPF中的逻辑树和可视化树
WPF中的逻辑树是指XAML元素级别的嵌套关系,逻辑树中的节点对应着XAML中的元素. 为了方便地自定义控件模板,WPF在逻辑树的基础上进一步细化,形成了一个“可视化树(Visual Tree)”,树 ...
- Linux中对逻辑卷的移除
移除前先df -mT 看一下:(在上一篇的基础上:Linux中对逻辑卷进行扩容) 1.取消挂载同时删除/etc/fstab下的记录 取消挂载 umount /dev/zhi/lv-zhi 删除记录 v ...
随机推荐
- vm+ubuntu联网
在vm下刚装了ubuntu,就是上不了网,确认以下配置后方可以 1.我的电脑开机自动把VM的相关服务都关闭了,需要手动打开 在控制面板中搜索服务,手动启动vm服务 2.在适配器里启用vm网卡 3.使用 ...
- 定时任务 Linux cron job 初步使用
查看定时任务的命令为:crontab -l 编辑定时任务的命令为:crontab -e (编辑后立即生效 若注释可在行首加# 同vi) 定时任务说明 每一行为一 ...
- Apache与Tomcat三种连接方式JK、http_proxy、ajp_proxy
为什么要让Apache与Tomcat之间进行连接?事实上Tomcat本身已经提供了HTTP服务,该服务默认的端口是8080,也可以改为80.既然Tomcat本身已经可以提供动态加静态web服务,为什么 ...
- Regular Expression Matching,regex,正则表达式匹配,利用动态规划
问题描述:Implement regular expression matching with support for '.' and '*'. '.' Matches any single char ...
- Java中各种集合特点总结
1:集合: (1) Collection(单列集合) List(有序,可重复) ArrayList 底层数据结构是数组,查 ...
- 医院Android项目总结
Eclipse ADT 配置AVD 1.layout布局:xml 如ck_report.xml <Text view ...android:id="ck"> & ...
- Android国际化-图片国际化和文本字符国际化
注意: 1.是在res目录下面,新建文件夹 2.需要国际化的文本资源和图片资源名称是一样的 图片国际化 默认:drawable-xhdpi 中文简体:drawable-zh-rCN-xhdpi(或者不 ...
- tensorflow笔记:流程,概念和简单代码注释
tensorflow是google在2015年开源的深度学习框架,可以很方便的检验算法效果.这两天看了看官方的tutorial,极客学院的文档,以及综合tensorflow的源码,把自己的心得整理了一 ...
- 批量反编译class文件
首先得进入jad的路径中,一般都放在jdk的安装目录的bin中 进入到该目录中,否则无法使用jad命令. jad -o -r -d F:\src -s java F:\classes\**\*.cla ...
- 绑定自己Self
Header="{Binding Path=Command.Text, RelativeSource={RelativeSource Self}}"/>