scrapy--selenium(二)
今天学习了很多,还是想给大家讲一讲正题:scrapy的动态加载AJax的网页爬取:selenium。让我们开始
三: 针对大型电商网站:京东网,因为比较有代表性,爬出来有点小成就。先给大家看下效果图。好让大家有点动力QAQ

一: 查看一下京东网加载商品的原理
1.1:将该网页加载的所有商品信息放入<li class="seckill_mod_goods">...</li>

1.2:获取网页源码,可以清楚的知道--无法在源码中找到商品信息所在的<li>...</li>标签

1.3: 那么现在问题来了,这些商品信息是从哪里加载出来的呢?那就是这次要将的Ajax动态加载信息,可以打开网页的审查元素,点击network,f5刷新,可以找到script类型的脚本
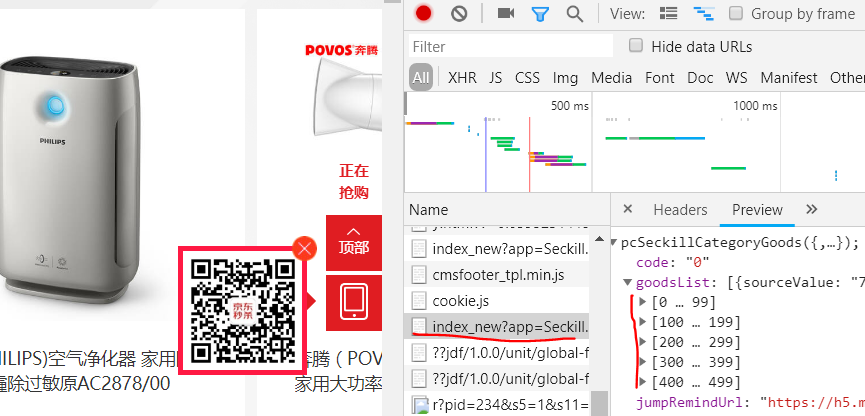
就是上图用红线画出来的script文件,查看中有[0..499]500个商品信息
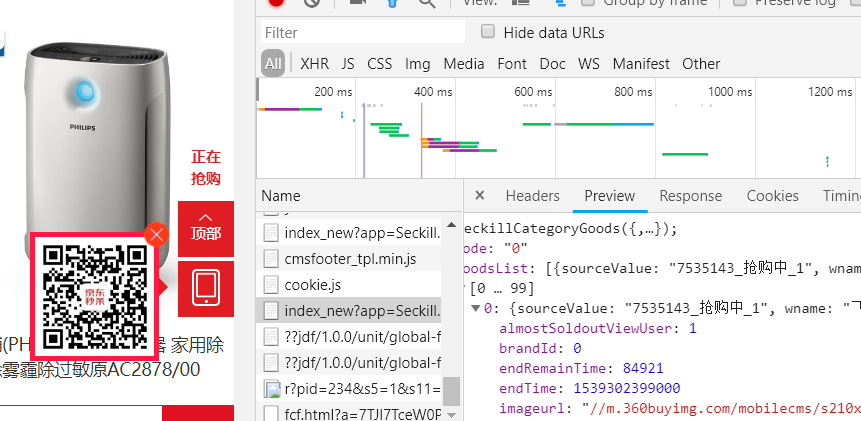
二: 了解了基本原理,再来看看源代码,就能很容易知道原理了__selenimu.py
#-*- coding:utf-8 -*-
import time
from selenium import webdriver
import pdb
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from lxml import etree
import re
from bs4 import BeautifulSoup chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=chrome_options) # 请求京东页面
driver.get(
"https://miaosha.jd.com/category.html?cate_id=19")
time.sleep(3) img_list = []
# 逐渐滚动浏览器窗口,令ajax逐渐加载 for i in range(1,200):
js = ("var q=document.documentElement.scrollTop=" + str(300 * i)) # 谷歌 和 火狐
driver.execute_script(js)
time.sleep(0.3) # 拿到页面源码
html = etree.HTML(driver.page_source)
all_img_list = [] # 得到所有图片
img_group_list = html.xpath("//*[@class='seckill_mod_goods_link_img']/@src") # 收集所有图片链接到列表 for img_group in img_group_list:
img_of_group = re.findall(r'.*q70\.jpg$',img_group)
all_img_list.append(img_of_group) with open('vip.txt', 'w') as f:
#pdb.set_trace()
for img_list_item in all_img_list:
if img_list_item[0]:
f.write(img_list_item[0]+'\n')
else:
driver.quit()
# 退出浏览器
driver.quit()
scrapy--selenium(二)的更多相关文章
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- 使用scrapy爬虫,爬取今日头条首页推荐新闻(scrapy+selenium+PhantomJS)
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面 查看源代码你会发现 全是js代码,说明今日头条的内容是通过js动态生成的. 用火狐浏览器F12查看得知 ...
- Scrapy+selenium爬取简书全站
Scrapy+selenium爬取简书全站 环境 Ubuntu 18.04 Python 3.8 Scrapy 2.1 爬取内容 文字标题 作者 作者头像 发布日期 内容 文章连接 文章ID 思路 分 ...
- python之scrapy篇(二)
一.创建工程 scarpy startproject xxx 二.编写iteam文件 # -*- coding: utf-8 -*- # Define here the models for your ...
- scrapy selenium 登陆zhihu
# -*- coding: utf-8 -*- # 导入依赖包 import scrapy from selenium import webdriver import time import json ...
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
- 使用scrapy+selenium爬取淘宝网
--***2019-3-27测试有效***---- 第一步: 打开cmd,输入scrapy startproject taobao_s新建一个项目. 接着cd 进入我们的项目文件夹内输入scrapy ...
- python3.5以及scrapy,selenium,等 安装
一.python3.5安装和配置 在安装的时候无意间发现了,python3.6没有给我自定义安装的机会,直接就C盘见:因此我选择了python3.5.<安装部分跳过,至于一条吃过痛苦的建议:不要 ...
- java selenium (二) 环境搭建方法一
webdriver 就是selenium 2. webdriver 是一款优秀的,开源的,自动化测试框架. 支持很多语言. 本文描述的是用java Eclipse 如何搭建环境 阅读目录 ...
- scrapy + selenium 的动态爬虫
动态爬虫 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会 ...
随机推荐
- HDU 5340——Three Palindromes——————【manacher处理回文串】
Three Palindromes Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others ...
- activeMq 配置(一)
基础知识补充 1.ActiveMQ从入门到精通(一)https://www.jianshu.com/p/ecdc6eab554c 2.ActiveMQ从入门到精通(二)https://www.jian ...
- REST与DDD
之前在为什么要使用MVC+REST+CQRS架构我曾经提出DDD是核心,REST是壳的观点,我想在这里详细谈谈我的思路. 今天正好看看到老外一篇博文Why REST is so important:按 ...
- Redis学习1
Redis 学习记录 简介 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zs ...
- win8中如何设定editplus为txt默认打开程序
设定EditPlus为TXT默认打开方式吧. 首选,打开我们的EditPlus 接着,点击[工具]菜单,点击[参数设置]这个菜单项 来到设定界面 找到[设置&语法]这个选项,然后可以看到里面有 ...
- dotnetcharting 的简单使用
dotnetcharting 是一个很好用的图表控件,能画出很漂亮的报表,一般常用到的主要有柱状图.饼图.折线图三种. dotnetcharting 有web版.winform版多个版本可供使用,官方 ...
- 命令“mkdir "xxx" xcopy "xxx" "xxx" /S /E /C /Y”已退出,代码为 9009。
前几天公司来了个新同事,使用的VS2013,但我们的所有项目都是使用VS2012创建的,我想用13打开应该没有什么问题.昨天新同事修改完代码提交后,我获取完成后无法编译成功,提示: 错误 3 命令“m ...
- div的浮动(float)
什么是浮动 浮动,故名思议,就是移动位置. 之所以不叫移动,而叫浮动,那是因为给元素设置浮动后,元素会浮到文档上面来,术语叫脱离文档流. 例子 下面我们看例子 <html> <hea ...
- JavaScript new 操作符 OOP(一)
什么是对象 对象是单个实物的抽象,通常需要一个模板,表示某一类实物的共同特征,然后对象根据这个模板生成. 对象是一个容器,封装了属性(property)和方法(method),属性是对象的状态, ...
- 关于如何等待一个元素的出现而不用一些笨拙粗暴的time.sleep()方法
我相信这是一个非常大众化的需求,我们需要等待某一个元素的出现以此来让我们的脚本进入到下一个Step,这个等待方法最好能够设置超时时间,然后找到后迅速callback.我们也很幸运!如果你仔细看Sele ...