《机器学习实战》学习笔记第十四章 —— 利用SVD简化数据
相关博客:
吴恩达机器学习笔记(八) —— 降维与主成分分析法(PCA)
《机器学习实战》学习笔记第十三章 —— 利用PCA来简化数据
主要内容:
一.SVD简介
二.U、∑、VT三个矩阵的求解
三.U、∑、VT三个矩阵的含义
四.SVD用于PCA降维
五.利用SVD优化推荐系统
六.利用SVD进行数据压缩
一.SVD简介
1.SVD分解能够将任意矩阵着矩阵(m*n)分解成三个矩阵U(m*m)、Σ(m*n)、VT(n*n),如下:
Datamxn = Umxm∑mxnVTnxn
2.Σ是一个对角矩阵,其对角元素是从大到小排列的,它们对应了Data矩阵的奇异值。这些奇异值的含义类似于PCA中特征值的含义。
3.V是一个列矩阵(因而VT是一个行矩阵)、是一个标准正交基,可用于将数据集Data矩阵进行列降维(即减少列数),其作用类似于PCA中的正交矩阵P。
4.U是一个列矩阵、是一个标准正交基,可用于将数据集Data矩阵进行行降维(即减少行数)。
二.U、∑、V三个矩阵的求解及其含义
可知:D = U∑VT
则:DTD = V∑TUTU∑VT = V∑T∑VT = V∑2VT,因为U为正交矩阵,所以UTU = I, 因为∑为对角矩阵,所以∑T∑可表示为∑2。
即:DTD = V∑2VT
可知DTD是一个方阵,方阵即可求出他的特征值和特征向量
(DTD)X = λX
其中∑2就是特征值λ构成的对角矩阵,V就是特征向量X构成的正交矩阵。
因此,可以用求解特征值和特征向量的方法求解矩阵∑、V。同理,通过求解DDT的特征值和特征向量可以求解出矩阵U。
三.U、∑、VT三个矩阵的含义
1.矩阵V的含义:根据上一节,可知矩阵V就是DTD的特征向量组成的正交矩阵,也就是正交基。而在PCA中,正交基P也是DTD的特征向量组成的正交矩阵。即,求解矩阵V实际上是在PAC中求解P。而正交基P正是用于对矩阵D进行列降维(减少列数,即减少属性个数),因此得出结论:矩阵V用于对矩阵D进行列降维。
2.矩阵U的含义:与矩阵V相对,矩阵U用于对矩阵D进行行降维(减少行数,即减少数据点个数)。
3.根据上一节,矩阵∑2就的对角元素就是DTD的特征值,那么矩阵∑的对角元素DTD的特征值的开根。∑的对角元素又称为奇异值。注意:求解U和求解V时∑2是不一样的,一个是m*m,一个是n*n,但它们的对角元素是一样的(min(m,n)个奇异值,缺少的用0表示)。
四.SVD用于PCA降维
1.SVD即奇异值分解,可以用来降维。利用PCA降维不挺好的,什么还要用SVD呢?
因为在使用PCA进行降维时,需要计算协方差矩阵XTX,而如果样本数、特征数都特别多时,计算XTX将非常耗时。但利用SVD,可以不用求出协方差矩阵XTX也能得到用于降维的矩阵。实际上,sklearn的PCA就是用SVD求解的。
2.类似于PCA,如果前k个奇异值所对应包含的信息超过了90%,那么可以只利用前k维进行数据压缩,如下:
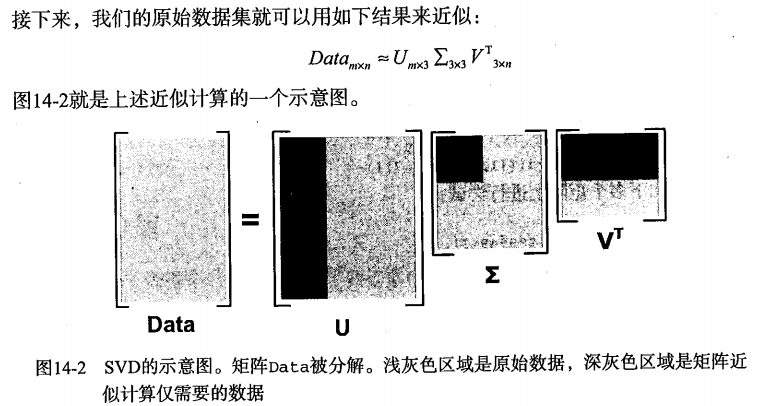
在传输数据时,我们可以只传U(m*k)、Σ(k*k)、VT(k*n)这三个小矩阵。当接受完数据时,就可以将这三个小矩阵进行矩阵乘法,从而得到原始数据集矩阵Data的近似矩阵。这种方式大大压缩了存储(或传输)的数据量,但又保证了高相似度。
2.SVD可用于降维,将求得的U(m*m)矩阵保留前k列,然后将数据集Data映射的U(m*k)上,实现降维。同理矩阵V(m*m)。
五.利用SVD优化推荐系统
def ecludSim(inA, inB): # 计算两数组的相似度
return 1.0 / (1.0 + la.norm(inA - inB)) def pearsSim(inA, inB): # 同上
if len(inA) < 3: return 1.0
return 0.5 + 0.5 * corrcoef(inA, inB, rowvar=0)[0][1] def cosSim(inA, inB): # 同上
num = float(inA.T * inB)
denom = la.norm(inA) * la.norm(inB)
return 0.5 + 0.5 * (num / denom) '''对单个物品进行预测评分'''
def standEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1] # 物品数
simTotal = 0.0; ratSimTotal = 0.0 # 总相似度、总评分, 预测频分 = 总评分/总相似度
for j in range(n): # 枚举所有物品
userRating = dataMat[user, j] # 获取该用户对此物品的评分
if userRating == 0: continue # 如果未进行评分,则下一个物品
overLap = nonzero(logical_and(dataMat[:, item].A > 0, dataMat[:, j].A > 0))[0] #寻找对两个物品都评了分的用户
if len(overLap) == 0: # 计算相似度
similarity = 0
else:
similarity = simMeas(dataMat[overLap, item], dataMat[overLap, j])
print 'the %d and %d similarity is: %f' % (item, j, similarity)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0:
return 0
else:
return ratSimTotal / simTotal '''对单个物品进行预测评分,利用SVD对用户进行降维'''
def svdEst(dataMat, user, simMeas, item):
n = shape(dataMat)[1]
simTotal = 0.0; ratSimTotal = 0.0
U, Sigma, VT = la.svd(dataMat) # 奇异值分解
Sig4 = mat(eye(4) * Sigma[:4]) # 取前四个奇异值进行降维
xformedItems = dataMat.T * U[:, :4] * Sig4.I # 降维(用户那一栏减少了)
for j in range(n):
userRating = dataMat[user, j]
if userRating == 0 or j == item: continue
similarity = simMeas(xformedItems[item, :].T, xformedItems[j, :].T)
print 'the %d and %d similarity is: %f' % (item, j, similarity)
simTotal += similarity
ratSimTotal += similarity * userRating
if simTotal == 0:
return 0
else:
return ratSimTotal / simTotal '''推荐算法'''
def recommend(dataMat, user, N=3, simMeas=cosSim, estMethod=standEst):
unratedItems = nonzero(dataMat[user, :].A == 0)[1] # 寻找该用户未评分的物品
if len(unratedItems) == 0: return 'you rated everything'
itemScores = [] # 预测评分列表
for item in unratedItems: #枚举每一个未评分的物品,进行预测评分
estimatedScore = estMethod(dataMat, user, simMeas, item)
itemScores.append((item, estimatedScore))
return sorted(itemScores, key=lambda jj: jj[1], reverse=True)[:N] # 对物品按预测评分进行降序排序
六.利用SVD进行数据压缩
def printMat(inMat, thresh=0.8): # 输出图案
for i in range(32):
for k in range(32):
if float(inMat[i, k]) > thresh:
print 1,
else:
print 0,
print '' '''图片压缩, numSV为压缩后的维度'''
def imgCompress(numSV=3, thresh=0.8):
myl = []
for line in open('0_5.txt').readlines(): # 读取图案
newRow = []
for i in range(32):
newRow.append(int(line[i]))
myl.append(newRow)
myMat = mat(myl)
print "****original matrix******"
printMat(myMat, thresh)
U, Sigma, VT = la.svd(myMat) # 奇异值分解
SigRecon = mat(zeros((numSV, numSV)))
for k in range(numSV): # 选取前numSV个奇异值进行压缩
SigRecon[k, k] = Sigma[k]
reconMat = U[:, :numSV] * SigRecon * VT[:numSV, :] # 压缩后的图案
print "****reconstructed matrix using %d singular values******" % numSV
printMat(reconMat, thresh)
《机器学习实战》学习笔记第十四章 —— 利用SVD简化数据的更多相关文章
- 【机器学习实战】第14章 利用SVD简化数据
第14章 利用SVD简化数据 SVD 概述 奇异值分解(SVD, Singular Value Decomposition): 提取信息的一种方法,可以把 SVD 看成是从噪声数据中抽取相关特征.从生 ...
- 学习笔记 第十四章 使用CSS3动画
第14章 使用CSS3动画 [学习重点] 设计2D动画 设计3D动画 设计过渡动画 设计帧动画 能够使用CSS3动画功能设计页面特效样式 14.1 设计2D动画 CSS2D Transform表 ...
- 《机器学习实战》学习笔记——第14章 利用SVD简化数据
一. SVD 1. 基本概念: (1)定义:提取信息的方法:奇异值分解Singular Value Decomposition(SVD) (2)优点:简化数据, 去除噪声,提高算法的结果 (3)缺点: ...
- [HeadFirst-HTMLCSS学习笔记][第十四章交互活动]
表单 <form action="http://wickedlysmart.com/hfhtmlcss/contest.php" method="POST" ...
- JavaScript高级程序设计学习笔记第十四章--表单
1.在 HTML 中,表单是由<form>元素来表示的,而在 JavaScript 中,表单对应的则是 HTMLFormElement 类型. HTMLFormElement 继承了 HT ...
- 机器学习实战 - 读书笔记(14) - 利用SVD简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第14章 - 利用SVD简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. 基 ...
- VSTO学习笔记(十四)Excel数据透视表与PowerPivot
原文:VSTO学习笔记(十四)Excel数据透视表与PowerPivot 近期公司内部在做一种通用查询报表,方便人力资源分析.统计数据.由于之前公司系统中有一个类似的查询使用Excel数据透视表完成的 ...
- Python学习笔记(十四)
Python学习笔记(十四): Json and Pickle模块 shelve模块 1. Json and Pickle模块 之前我们学习过用eval内置方法可以将一个字符串转成python对象,不 ...
- python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法
python3.4学习笔记(二十四) Python pycharm window安装redis MySQL-python相关方法window安装redis,下载Redis的压缩包https://git ...
随机推荐
- 转:使用rsync在linux(服务端)与windows(客户端)之间同步
转自:http://blog.csdn.net/old_imp/article/details/8826396 一 在linux(我用的是centos系统)上安装rsync和xinetd前先查看lin ...
- 压力测试工具集合(ab,webbench,Siege,http_load,Web Application Stress)
压力测试工具集合(ab,webbench,Siege,http_load,Web Application Stress) 1 Apache附带的工具ab ab的全称是ApacheBench,是Apac ...
- python截取搜索引擎关键词
这段代码是自己学了python的基本语法之后,参考一个网上视频写的代码,功能是截取搜索引擎360的关键词. 代码: #!/usr/bin/python #encoding:utf-8 import u ...
- oracle分区表和分区索引概述
㈠ 分区表技术概述 ⑴ Range 分区 ① 例子 create table t (...列定义...) ...
- 《HBase in Action》 第一章节的学习总结 ---- HBase是个啥
1.HBase模仿了Google的BigTable,是一种开源的,面向列族的数据库.它基于行键(rowkey),列键(column key)和时间戳(TimeStamp)来建立索引.HBase是建立在 ...
- 第三篇:Logstash 安装配置
Logstash 简介: Logstash 是一个实时数据收集引擎,可收集各类型数据并对其进行分析,过滤和归纳.按照自己条件分析过滤出符合数据导入到可视化界面.Logstash 建议使用java1.8 ...
- Boost学习总结(一)VS2010环境下编译STLport和Boost
Boost学习总结(一)VS2010环境下编译STLport和Boost Boost简介 Boost库是一个功能强大.构造精巧.跨平台.开源并且完全免费的C++程序库.1998年,Beman G.Da ...
- Unity Texture2D的sRGB(Color Texture)的作用
在gramma空间下,勾选与否无关. 在liner空间下,勾选shader会自动将读到的像素作gramma矫正,即x的0.45次方 不勾选,shader读到的就是原始的颜色值 然后unity如果选了g ...
- Netty实战
一.Netty异步和事件驱动1.Java网络编程回顾socket.accept 阻塞socket.setsockopt /非阻塞2.NIO异步非阻塞a).nio 非阻塞的关键时使用选择器(java.n ...
- Sumdiv(较难数学题)
Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 20971 Accepted: 5290 Description Cons ...