Sogou日志分析(hive)
1. 数据准备
1.1 数据预先放在mac本地桌面的“VB共享文件夹”中,从VisualBox虚拟机中/mnt/VBShare共享目录中转移到resources目标目录。
[cloudera@quickstart VBShare]$ sudo mv /mnt/VBShare/sogou.500w.utf8 ~/resources/
[cloudera@quickstart VBShare]$ cd ~/resources
[cloudera@quickstart resources]$ ls
sogou.500w.utf8
1.2 将数据导入hive
1.2.1 进入hive CLI
[cloudera@quickstart resources]$ hive
1.2.2 建表search_log
CREATE TABLE search_log(
time STRING,
uid STRING,
keyword STRING,
pagerank INT,
clickorder INT,
url STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
1.2.3 查看search_log表是否创建成功
hive> SHOW TABLES; customers
sample_07
sample_08
search_log
1.2.4 将sogou日志数据导入search_log表
LOAD DATA LOCAL INPATH 'sogou.500w.utf8'
OVERWRITE INTO TABLE search_log;
1.2.5 查看数据是否正常导入
SELECT * FROM search_log
LIMIT 10; 20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/
20111230000005 66c5bb7774e31d0a22278249b26bc83a 凡人修仙传 3 1 http://www.booksky.org/BookDetail.aspx?BookID=1050804&Level=1
20111230000007 b97920521c78de70ac38e3713f524b50 本本联盟 1 1 http://www.bblianmeng.com/
20111230000008 6961d0c97fe93701fc9c0d861d096cd9 华南师范大学图书馆 1 1 http://lib.scnu.edu.cn/
20111230000008 f2f5a21c764aebde1e8afcc2871e086f 在线代理 2 1 http://proxyie.cn/
20111230000009 96994a0480e7e1edcaef67b20d8816b7 伟大导演 1 1 http://movie.douban.com/review/1128960/
20111230000009 698956eb07815439fe5f46e9a4503997 youku 1 1 http://www.youku.com/
20111230000009 599cd26984f72ee68b2b6ebefccf6aed 安徽合肥365房产网 1 1 http://hf.house365.com/
20111230000010 f577230df7b6c532837cd16ab731f874 哈萨克网址大全 1 1 http://www.kz321.com/
20111230000010 285f88780dd0659f5fc8acc7cc4949f2 IQ数码 1 1 http://www.iqshuma.com/
Time taken: 0.243 seconds, Fetched: 10 row(s)
1.3 为了获取更多信息,将第一列time字段分解为year,month,day,hour字段,并导入新创立的表格search_log_subfields。
1.3.1 在终端利用awk进行扩展
awk -F '\t' '{print $0"\t"substr($1,1,4)"\t"substr($1,5,2)"\t"substr($1,7,2)"\t"substr($1,9,2)}' ./sogou.500w.utf8 > sogou.subfields.utf8;
经过杨艺同学指点还可以用JAVA进行扩展:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.file.Paths;
import java.util.Scanner; public class Main { public static void main(String[] args) throws Exception{
System.out.println("……数据开始处理……");
long lineNumber=0;
try
{
String filepath=args[0];
File file=new File(filepath);
Scanner in = new Scanner(file, "UTF-8");
String outpath=args[1];
PrintWriter out = new PrintWriter(outpath, "UTF-8"); while(in.hasNextLine())
{
lineNumber++;
String line = in.nextLine();
String date = line.substring(0,14);
String year = date.substring(0,4) + '\t';
String month = date.substring(4,6) + '\t';
String day = date.substring(6,8) + '\t';
String hour = date.substring(8,10) + '\t';
String minute = date.substring(10,12) + '\t';
String seconds = date.substring(12,14);
String newLine = line + '\t' + year + month + day + hour + minute + seconds; String[] linedatas=newLine.split("\t");
boolean flag=false;
for(String data:linedatas)
{
if(data.equals(""))
{
flag=true;
}
}
if(!flag) {
out.println(newLine);
//将缓存区的数据输出
out.flush();
}else
{
System.out.println("第"+lineNumber+"行有空数据");
}
}
out.close();
System.out.println(args[0]+"分解完成\n"+"目标路径为:"+args[1]);
}
catch (IOException e)
{
System.out.println("第"+lineNumber+"行中发生错误");
e.printStackTrace();
}
}
}
1.3.2 创建新表search_log_subfields
CREATE TABLE search_log_subfields(
time STRING,
uid STRING,
keyword STRING,
pagerank INT,
clickorder INT,
url STRING,
year INT,
month INT,
day INT,
hour INT )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
1.3.3 将处理过的数据导入新表search_log_subfields当中
LOAD DATA LOCAL INPATH 'sogou.subfields.utf8'
OVERWRITE INTO TABLE search_log_subfields;
1.3.4 查看表search_log_subfields是否字段完整,字段类型定义是否有误
DESCRIBE FORMATTED search_log_subfields;
OK
# col_name data_type comment time string
uid string
keyword string
pagerank int
clickorder int
url string
year int
month int
day int
hour int # Detailed Table Information
Database: default
Owner: cloudera
CreateTime: Mon Nov 20 23:22:11 PST 2017
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://quickstart.cloudera:8020/user/hive/warehouse/search_log_subfields
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE true
numFiles 1
numRows 0
rawDataSize 0
totalSize 648670020
transient_lastDdlTime 1511249322 # Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.332 seconds, Fetched: 41 row(s)
共10个字段(原来6个加新定义的4个),每个字段的类型无误。
1.3.5 查看表search_log_subfields前10条纪录
SELECT * FROM search_log_subfields LIMIT 10; 20111230000005 57375476989eea12893c0c3811607bcf 奇艺高清 1 1 http://www.qiyi.com/ 2011 12 30 0
20111230000005 66c5bb7774e31d0a22278249b26bc83a 凡人修仙传 3 1 http://www.booksky.org/BookDetail.aspx?BookID=1050804&Level=1 2011 12 30 0
20111230000007 b97920521c78de70ac38e3713f524b50 本本联盟 1 1 http://www.bblianmeng.com/ 2011 12 30 0
20111230000008 6961d0c97fe93701fc9c0d861d096cd9 华南师范大学图书馆 1 1 http://lib.scnu.edu.cn/ 2011 12 30 0
20111230000008 f2f5a21c764aebde1e8afcc2871e086f 在线代理 2 1 http://proxyie.cn/ 2011 12 30 0
20111230000009 96994a0480e7e1edcaef67b20d8816b7 伟大导演 1 1 http://movie.douban.com/review/1128960/ 2011 12 30 0
20111230000009 698956eb07815439fe5f46e9a4503997 youku 1 1 http://www.youku.com/ 2011 12 30 0
20111230000009 599cd26984f72ee68b2b6ebefccf6aed 安徽合肥365房产网 1 1 http://hf.house365.com/ 2011 12 30 0
20111230000010 f577230df7b6c532837cd16ab731f874 哈萨克网址大全 1 1 http://www.kz321.com/ 2011 12 30 0
20111230000010 285f88780dd0659f5fc8acc7cc4949f2 IQ数码 1 1 http://www.iqshuma.com/ 2011 12 30 0
粗略观察结果,数据插入是成功的,没有大问题。
1.4 清洗数据
1.4.1 观察是否存在缺失值
SELECT * FROM search_log_subfields
WHERE
time IS NULL OR
uid IS NULL OR
keyword IS NULL OR
pagerank IS NULL OR
clickorder IS NULL OR
year IS NULL OR
month IS NULL OR
day IS NULL OR
hour IS NULL
; OK
Time taken: 2.243 seconds
返回0条记录,所以没有缺失值。经过一系列查询(篇幅原因,此处省略),证明了该表不存在脏数据。
2. 数据分析
2.1 了解日志数据产生时间信息
2.1.1 起始时间
SELECT min(time) from search_log_subfields; 20111230000002
2.1.2 终止时间
SELECT max(time) from search_log_subfields; 20111231205232
结论:所获得的记录是sogou搜索引擎从2011年12月30日凌晨到31号晚上9点跨时45h不到的用户搜索数据。
2.2 UID分析
2.2.1 建表uid_stime,用于存储search_log_subfields表中所有用户的搜索次数
CREATE TABLE uid_stime AS SELECT uid, search_time FROM
(SELECT uid, count(*) AS search_time FROM search_log_subfields GROUP BY uid) a
ORDER BY search_time DESC;
2.2.2 查看uid_stime表前10条记录
hive> SELECT * FROM uid_stime LIMIT 10;
OK
02a8557754445a9b1b22a37b40d6db38 11528
cc7063efc64510c20bcdd604e12a3b26 2571
9faa09e57c277063e6eb70d178df8529 2226
7a28a70fe4aaff6c35f8517613fb5c67 1292
b1e371de5729cdda9270b7ad09484c4f 1277
c72ce1164bcd263ba1f69292abdfdf7c 1120
2e89e70371147e04dd04d498081b9f61 837
06c7d0a3e459cab90acab6996b9d6bed 720
b3c94c37fb154d46c30a360c7941ff7e 676
beb8a029d374d9599e987ede4cf31111 676
Time taken: 0.408 seconds, Fetched: 10 row(s)
2.2.3 用户活跃总人数
hive> SELECT count(*) FROM uid_stime; 1352664
2.2.4 观察不同搜索率的用户人数分配
依据uid_stime表制作stime_amt表,用以存储不同搜索频率用户的人数
CREATE TABLE searchtime_amt AS
SELECT * FROM (SELECT search_time, count(*) AS amt FROM uid_stime GROUP BY search_time) a ORDER BY search_time;
将表格导入文件系统
[root@quickstart resources]# touch searchtime_amt
[root@quickstart resources]# hive -e 'SELECT * FROM searchtime_amt' > searchtime_amt
数据导入Rstudio遇到的问题及解决方案:
> searchtime_amt=read.table(file = '/Users/apple/Desktop/VB共享文件夹/searchtime_amt',sep = "\t",header = FALSE)
Error in scan(file = file, what = what, sep = sep, quote = quote, dec = dec, :
253行没有2元素
# 导入失败
观察数据searchtime_amt,发现最后几行存在多余WARN信息问题:
WARN: The method class org.apache.commons.logging.impl.SLF4JLogFactory#release() was invoked.
WARN: Please see http://www.slf4j.org/codes.html#release for an explanation.
结合R的报错信息,可知第253行是导入了多余的信息。在shell中提取前252行数据
appledeMacBook-Air-:VB共享文件夹 apple$ touch searchtime_amt1
appledeMacBook-Air-:VB共享文件夹 apple$ head - searchtime_amt > searchtime_amt1
appledeMacBook-Air-:VB共享文件夹 apple$ rm searchtime_amt
appledeMacBook-Air-:VB共享文件夹 apple$ mv searchtime_amt1 searchtime_amt
(数据导入过程和类似的问题接下来也会碰到,将不细做演示,直接进行分析)
用R语言对search_amt表进行数据分析
# R代码
searchtime_amt=read.table(file = '/Users/apple/Desktop/VB共享文件夹/searchtime_amt',sep = "\t",header = FALSE)
head(searchtime_amt)
library(ggplot2)
names(searchtime_amt)=c('searchtime','amount')
ggplot(data = searchtime_amt, aes(x=searchtime, y=searchtime)) +
geom_point(aes(size=amount,colour=amount,alpha=amount))
ggplot(data = searchtime_amt, aes(x=searchtime,y=amount)) +
geom_line(color='red',alpha=0.5)
ggplot(data = searchtime_amt[1:50,], aes(x=searchtime,y=amount)) +
geom_line(color='red',alpha=0.5)
ggplot(data = searchtime_amt[1:20,], aes(x=searchtime,y=amount)) +
geom_line(color='red',alpha=0.5)
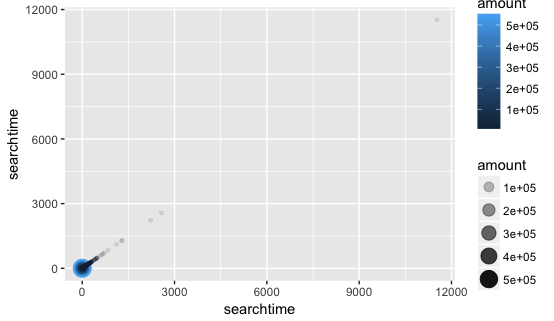
横纵坐标都为用户的搜索次数,通过颜色的深浅、点的大小和蓝色成分的多少可以判断所有用户45小时内的搜索次数的分布情况。
可以看到,用户45小时内的搜索次数几乎全部集中在3000以内,有一个异常点搜索次数几乎达到12000次,可大致判断为爬虫。
接下来通过下图进一步判断,搜索次数的主要集中在哪个区间:
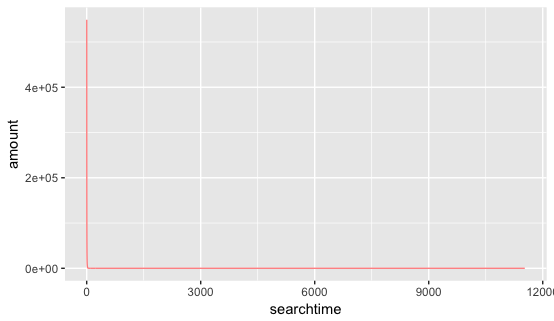
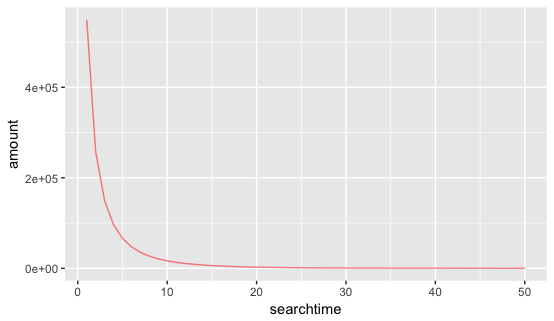
两幅图横纵坐标都相同(横坐标为搜索次数,纵坐标为该次数对应的用户数),可以看出,用户主要集中分布在搜索次数小于20的区间,搜索次数大于20的用户人数分布几乎不变且接近0。进而可以再通过hive得出搜索次数小于等于20的用户占比。
SELECT sum(amt) FROM searchtime_amt WHERE search_time <=20;
1330983 SELECT sum(amt) FROM searchtime_amt;
1352664 SELECT 1330983 / 1352664;
0.9839716293181455
结论:98.4%的用户使用sogou搜索引擎的频率在10.6次/天(即,20次/45h)之内。
进一步观察UID的查询次数不同分段(根据上图,可以将给出合理的分段依据,即:0~10,10~20,20~30,30~40)的人数分布
SELECT sum(IF(search_time <=10 ,amt,0))/ 1352664 max10, sum(IF(search_time >10 and search_time <= 20,amt,0))/ 1352664 max20,sum(IF(search_time >20 and search_time <= 30,amt,0))/ 1352664 max30,sum(IF(search_time >30 and search_time <= 40,amt,0))/ 1352664 max40 FROM searchtime_amt; 0.9356662112690217 0.048305418049123805 0.010077151458159602 0.0031522979838304265
结论:查询次数小于10次的比例占比约有93.6%,随着定长区间的右移,用户数急剧减少。可将第一区间的用户定义为忠实客户、第二区间定义为发展潜力大的客户等等,依此采取不同的CRM商业策略。
2.3 url点击信息
2.3.1 建表url_info,用以保存所有url、其被点击次数(倒序排列,取top100),平均页面排行和平均点击顺序
CREATE TABLE url_info AS
SELECT * FROM (SELECT url, count(*) click_time,avg(pagerank) avg_pr,avg(clickorder) avg_co FROM search_log_subfields GROUP BY url) a
ORDER BY click_time DESC;
2.3.2 分析url信息
查看url_info表前20行结果
SELECT * FROM url_info
LIMIT 20; http://www.baidu.com/ 73737 1.0086794960467609 1.0060756472327326
http://www.4399.com/ 19015 1.0110965027609782 1.0308177754404417
http://www.hao123.com/ 14338 1.0410796484865392 1.0260845306179383
http://www.youku.com/ 14086 1.0466420559420702 1.0137015476359506
http://qzone.qq.com/ 12920 1.2108359133126936 1.01671826625387
http://www.7k7k.com/ 8326 1.1534950756665865 1.040595724237329
http://weibo.com/ 7547 1.083344375248443 1.021597985954684
http://cf.qq.com/ 7544 1.0153764581124072 1.0400318133616118
http://www.xixiwg.com/ 7043 1.0173221638506318 1.0136305551611529
http://www.12306.cn/ 6961 1.2580089067662692 1.1231144950438154
http://dnf.qq.com/ 6835 1.0092172640819312 1.0128749085588882
http://bbs1.people.com.cn/postDetail.do?id=112546724 6325 1.0012648221343874 1.0134387351778655
http://www.a67.com/ 6048 1.1312830687830688 1.0793650793650793
http://www.qqwangming.org/ 6004 1.0804463690872752 1.1079280479680214
http://tv.sogou.com/series/wxt4vu5644qnbqwbyg62g.html?p=40230600 5508 1.1788307915758895 1.1545025417574437
http://www.tudou.com/ 5444 1.0563923585598824 1.0124908155767818
http://www.zhibo8.com/ 4930 1.3352941176470587 1.0523326572008114
http://www.taobao.com/ 4928 1.0633116883116882 1.0133928571428572
http://tv.sogou.com/series/wxt4vu5644qlvwv27q.html?p=40230600 4589 1.0047940727827414 1.1937241229025932
http://www.4399.com/flash/32979aa.htm 4128 1.2051841085271318 1.0559593023255813
用折线图展示最受欢迎的前20名url
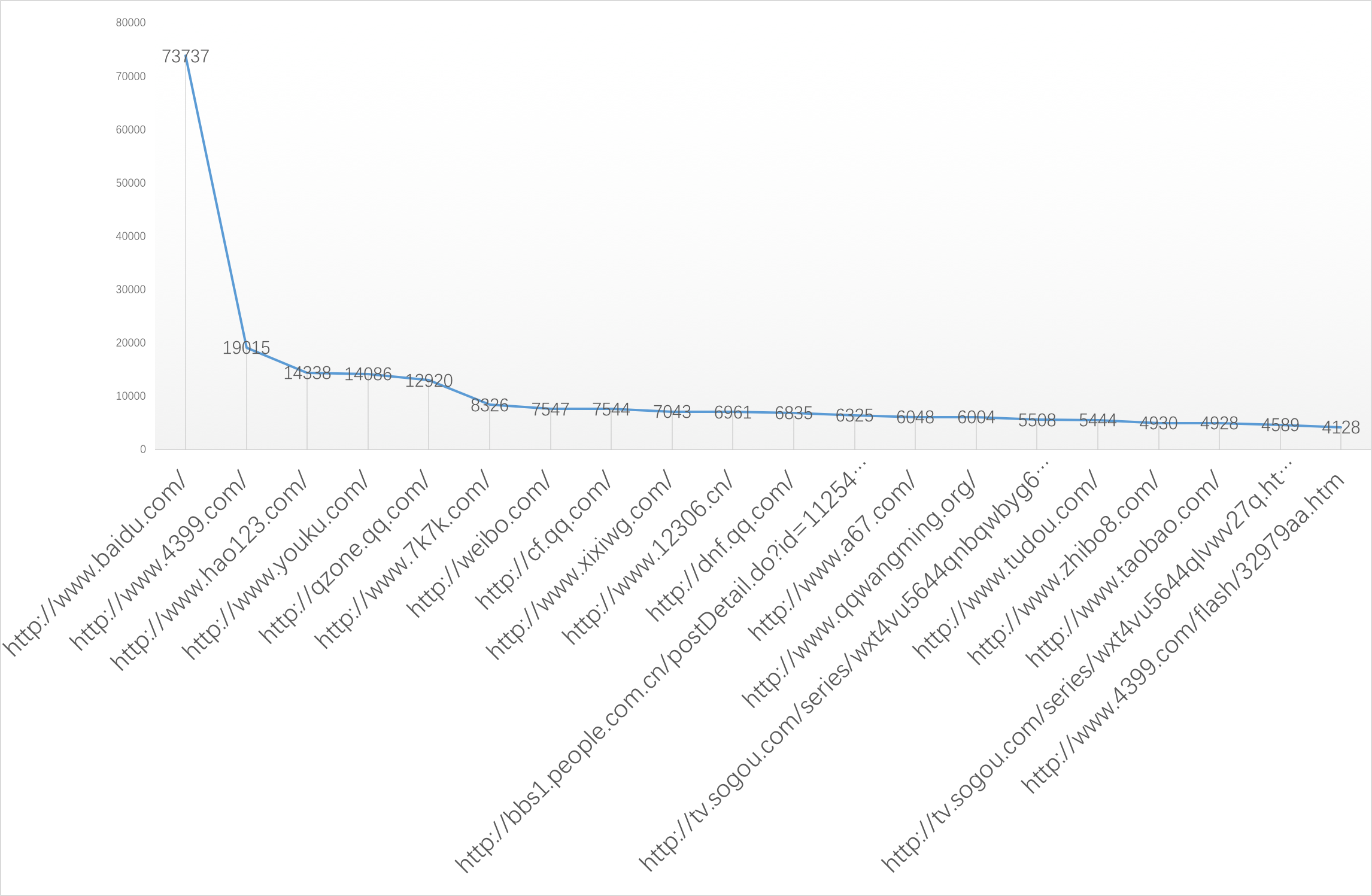
图片中可以看出,点击率中,百度url以压倒性优势胜出。可以推测,有很大一部分sogou用户使用sogou并非主观选择的。sogou不但要在推广上下功夫,更要提高供给侧输出能力,才能更好地避免客户流失问题。
观察url点击率与页面排行和点击顺序的关系
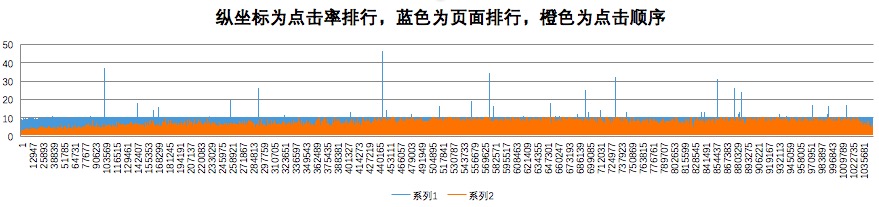
对点击率top20的url进行分类,可以发现
A. 在图片的最左边,随着点击率的减小(沿横坐标轴往右),页面排行有明显的增加。直到到达10之后,随着点击率的减小,页面排行基本没有变化且大多数在10以内。说明点击率非常高的url一般都在页面的前面。当点击率低到一定程度之后,点击率与页面排名就没有相互关系
B. 大部分的页面都在10以内,只有极个别的url的页面排名大于10。这与页面设计应该有关,但是为什么会存在大于10的页面排行,有待以后弄明白。
C. 很长一段区间内,点击顺序随着点击率排行的增大增大。说明大多数点击率高的url都是会在第一时间被用户点击的。这与用户的习惯和心理相吻合:越有名的事物,越容易不容易产生排斥
2.3.3 查看页面排行最大的前20个url信息
SELECT * FROM search_log_subfields
ORDER BY pagerank DESC
LIMIT 20;

可以看见,页面排行最大为50,可以进而猜测sogou搜索引擎的最大页面排行为50。
更明显更突出的结论是:愿意点击页面排行接近50的url的用户,他们使用的搜索关键词中,主要分为两类信息,一种是政治话题,另一种是考试舞弊话题。可以大致推测,人们在这两方面问题的探索上是比较“锲而不舍”的。
有趣的是:用户“95c4b7104504e15218401ec5fa4d964f”在下12月30日9点左右多次查询过“习明泽”信息之后,12点就有用户“3b6b0d2d4c9867d48b75ab028d92799c”搜索“习明泽是谁”,本来并没有值得奇怪的,或者后者是在与前者进行过交流之后,对此话题产生了兴趣,随手拿出手机进行查询,但页面排行28引起了作者的兴趣。为甚么有人会对一个自己不认识的人感兴趣到点击第28个url?于是作者点开sogou搜索引擎,重现了一下操作,发现原来是国父之女儿,这就不奇怪人们会对这个人的身份感兴趣了。
2.4 keyword分析
2.4.1 创建表keyword_times, 用以保存每个关键字,及其被查询的频数
CREATE TABLE keyword_times AS SELECT keyword,count(*) st FROM search_log_subfields GROUP BY keyword ORDER BY st DESC;
2.4.2 可视化关键词搜索频率

2.4.3 关键词中直接输入 URL 作为查询词的比例
SELECT count(*) from search_log_subfields WHERE keyword LIKE '%www%';
73979 SELECT 73979/5000000;
0.0147958
2.4.4 关键词中直接输入URL的查询中,点击的结果就是用户输入的URL的网址所占的比例
SELECT sum(IF(instr(url,keyword)>0,1,0)) from
(SELECT * FROM search_log_fields WHERE keyword LIKE '%www%') A;
27561 SELECT 27561/73979;
0.37255167006853
2.5 用户活跃时间分析
2.5.1 2011年12月30日用户活跃时间段查询,创表time_st
CREATE TABLE time_st AS
SELECT hour, count(*) st FROM (SELECT * FROM search_log_subfields
WHERE time >= 20111230000002 and time < 20111231000002) a
GROUP BY hour
ORDER BY hour;
将表导出,利用Excel进行可视化分析:
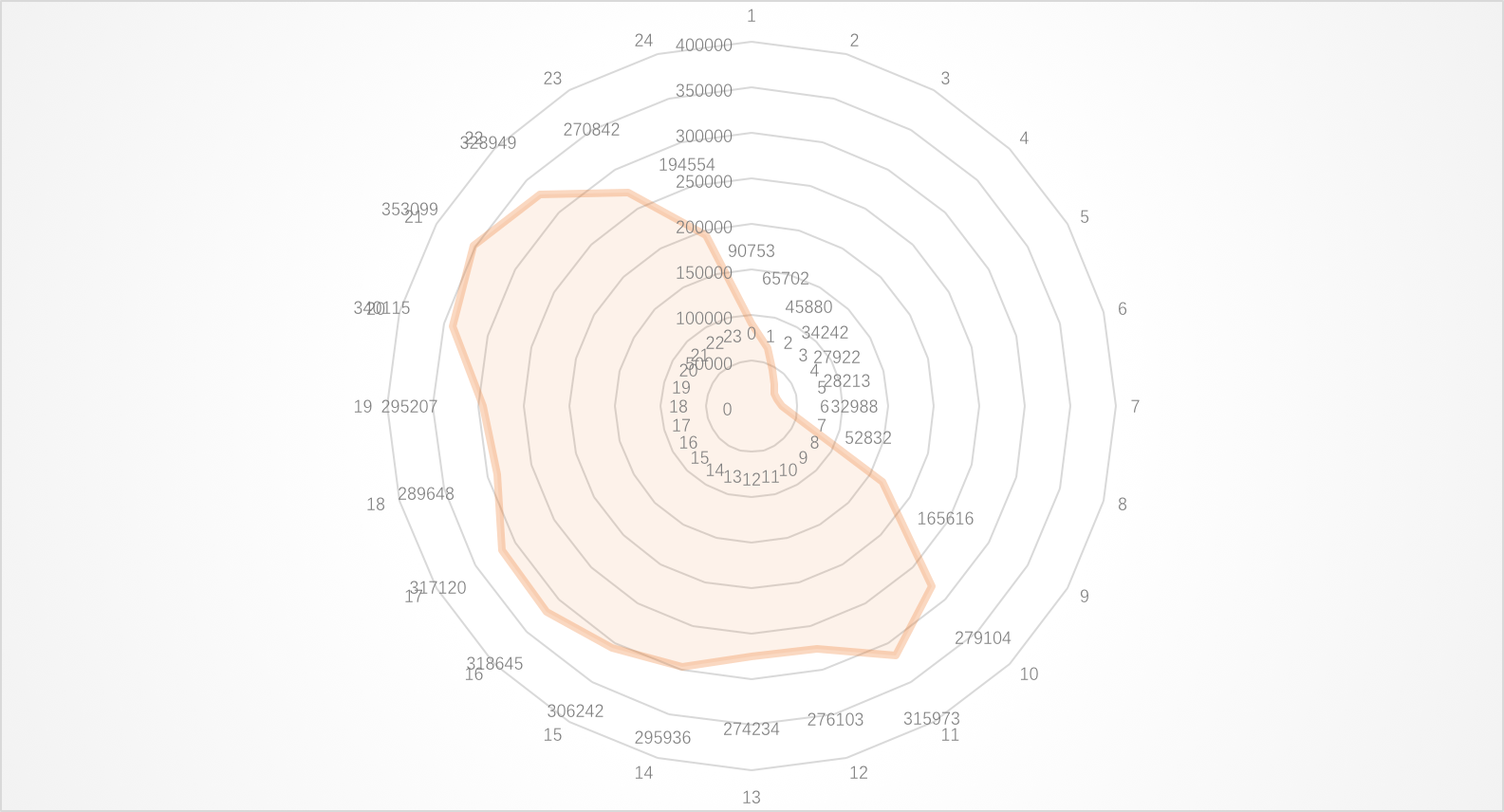
可以把这个圆看作是跨度为24小时的钟,图中圆心到橙色边缘的距离的长短表示此时的在线用户数的多少。 明显在上午6左右,活跃用户数急剧增多,10点左右到达日间活跃状态。夜间9点时,活跃用户最多(35W活跃用户),此后急剧减少,4点半左右到达低潮期,大约3W用户左右。中午10点到1点之间,下午4点到7点之间,用户活跃度会略有减小。可能原因有可能是就餐时间,用户并不活跃。可以推测,用户更愿意在工作时间进行搜索,休息时间更偏向于不主动获取信息的状态。根据这个习惯,sogou可以考虑白天主打新闻类推送,并且避免在就餐时间。夜间主打娱乐休闲类推送,最佳时间为晚上9点。但一定不要超过晚上9点。
2.5.2 2011年12月31日用户活跃时间段查询,创表time_st2
事实上,2011年12月30日和31日分别是星期五和星期六,本来作者想通过对比30号和31号两天的用户活状态,发现一些有意思的信息,但过程中发现,31日的数据量极少(100条以内),因此放弃这部分内容。过程如下:
CREATE TABLE time_st2 AS
SELECT hour, count(*) st FROM (SELECT * FROM search_log_subfields
WHERE time >= 20111231000002) a
GROUP BY hour
ORDER BY hour;
结果汇总:
2.6 简单的用户画像构建的尝试
由于数据主要集中在2011年12月30日一天,理论上不能单纯地根据用户1天内的搜索时间来依此来推测用户的身份。于是我们做个简单的假设,用户每天都是按照同一套作息表进行的。
首先,由于31日的记录在总样本数中可以忽略不计,为了计算1日内用户的平均活跃时间,先将其删除,筛选出所有30号的数据。这样,接下来的操作都是在30号一天内的数据
CREATE TABLE in30th AS
SELECT * FROM search_log_subfields
WHERE time < 20111231000000
;
先尝试对用户网页上活跃的时间段求平均值,通过作图,看是否有聚类现象,若有可以选择根据图中聚类中心的个数进行k-means聚类
CREATE TABLE uid_avghour AS SELECT uid, avg(hour) avg_hour FROM in30th GROUP BY uid;
用R语言对每个点做散点图,可以认为横坐标为用户编号,纵坐标为用户在线时间段的中心值
uid_avghour<-read.table('/Users/apple/Desktop/uid_avghour')
names(uid_avghour)=c('uid','avghour')
library(ggplot2)
uid_avghour$order = seq(length(uid_avghour$uid))
ggplot(uid_avghour[1:100000,], aes(x=order, y=avghour)) +
geom_point(alpha=0.01)#以颜色区分
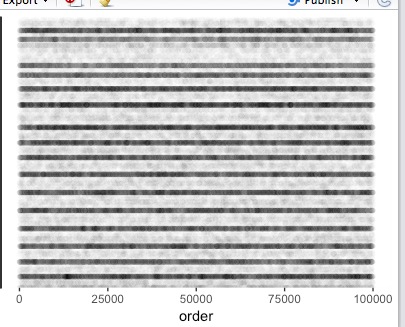
通过纵向颜色的深浅可以发现,并没有很明显的聚类现象。因此可以认为用在线时间段的平均值作为聚类依据并不是很好的选择。于是,我们放弃kmeans聚类的方法。
PS:纵向的横条纹产生的原因是以小时为间隔,有些用户若一天只搜索过1一次,在同一个小时区间内的这些用户的在线时间的平均值就会集中呈现在一条横条纹上。
根据尝试,我们知道,如果某用户凌晨2点到6点之间不进行搜索,则很有可能是正常作息者,相反则很是夜猫子型
依次为依据我们用HiveQL为每个用户新建一个标签列
CREATE TABLE uid_type AS
SELECT uid,if(is_owl >0,'night','day') type
FROM (SELECT uid,sum(if(hour>=2 and hour<6,1,0)) is_owl FROM in30th GROUP BY uid) a;
查看效果:
SELECT * FROM uid_type LIMIT 10; 00005c113b97c0977c768c13a6ffbb95 day
000080fd3eaf6b381e33868ec6459c49 day
0000c2d1c4375c8a827bff5dab0cc0a6 day
0000d08ab20f78881a2ada2528671c58 day
0000e7482034da216ce878a9f16feb49 day
0001520a31ed091fa857050a5df35554 day
0001824d091de069b4e5611aad47463d day
0001894c9f9de37ef9c90b6e5a456767 night
0001b04bf9473458af40acb4c13f1476 day
0001f5bacf60b0ff8c1c9e66e4905c1f day SELECT count(*) FROM uid_type WHERE type=='day'
1308723 SELECT count(*) FROM uid_type
1352664 SELECT 1308723/1352664
0.9675152144213197
可以看到,96.8%的人都是日间活动者,这与实际情况也是近似相符的。
2.7 夜猫子搜索内容分析
顺着刚才的思路,我们可以进一步探寻,在凌晨2点到6点,夜猫子型用户们最多搜索的内容是什么
CREATE TABLE kw_cnt_night AS
SELECT keyword, count(*) cnt_kw FROM (SELECT * FROM in30th WHERE hour >=2 and hour <6) a
GROUP BY keyword
ORDER BY cnt_kw DESC; SELECT * FROM kw_cnt_night LIMIT 10; 百度 1654
baidu 902
人体艺术 678
百度一下 你就知道 535
优酷 494
新亮剑 480
百度一下 473
快播 364
qq网名 321
qq空间 303
绘制搜索结果图云,可视化结果

很容易发现,在夜深人静的时刻人们往往容易更容易陷入情感困扰,因此奉劝年轻人夜场是非多,千万不要熬夜!不要熬夜!不要熬夜!
搜索最多的还有游戏,影视作品、网站等说明“夜猫子”中绝大多数都并非是因为工作因素熬夜,二是为了休闲娱乐,或是陷入感情困扰。
此外,金正日的搜索频率非常之高,是同类话题中唯一可以跻身最高频搜索关键词的一个。回忆当时的历史背景:2011年12月17日,朝鲜民主主义人民共和国最高领导人金正日(김정일)病逝。但总的来说,人们在晚上并不会对政治问题非常感兴趣。
因此,搜狗可以有选择性地在夜间进行热门话题、情感类、游戏类资讯的推送,减少政治新闻类的推送。
3 总结
从之前的分析中,能用文字总结出的点列在下面:
1. 所获得的500万条记录是sogou搜索引擎从2011年12月30日凌晨到31号晚上9点跨时45h不到的用户搜索数据。
2. 用户45小时内的搜索次数几乎全部集中在3000以内,有一个异常点搜索次数几乎达到12000次,可大致判断为爬虫。
3. 用户主要集中分布在搜索次数小于20的区间,搜索次数大于20的用户人数分布几乎不变且接近0。
4. 98.4%的用户使用sogou搜索引擎的频率在10.6次/天(即,20次/45h)之内。
5. 查询次数小于10次的比例占比约有93.6%,随着定长区间的右移,用户数急剧减少。可将第一区间的用户定义为忠实客户、第二区间定义为发展潜力大的客户等等,依此采取不同的CRM商业策略。
6. 点击率中,百度url以压倒性优势胜出。可以推测,有很大一部分sogou用户使用sogou并非主观选择的。sogou不但要在推广上下功夫,更要提高供给侧输出能力,才能更好地避免客户流失问题。
7. 说明点击率非常高的url一般都在页面的前面。当点击率低到一定程度之后,点击率与页面排名就没有相互关系。
8. 大部分的页面都在10以内,只有极个别的url的页面排名大于10。
9. 很长一段区间内,点击顺序随着点击率排行的增大增大。说明大多数点击率高的url都是会在第一时间被用户点击的。这与用户的习惯和心理相吻合:越有名的事物,越容易不容易产生排斥
10. 愿意点击页面排行接近50的url的用户,他们使用的搜索关键词中,主要分为两类信息,一种是政治话题,另一种是考试舞弊话题。
11. 关键词中直接输入 URL 作为查询词的比例约为1.5%。
12. 关键词中直接输入URL的查询中,点击的结果就是用户输入的URL的网址所占的比例约为37.3%。
13. 在上午6左右,活跃用户数急剧增多,10点左右到达日间活跃状态。夜间9点时,活跃用户最多(35W活跃用户),此后急剧减少,4点半左右到达低潮期,大约3W用户左右。中午10点到1点之间,下午4点到7点之间,用户活跃度会略有减小。可能原因有可能是就餐时间,用户并不活跃。可以推测,用户更愿意在工作时间进行搜索,休息时间更偏向于不主动获取信息的状态。根据这个习惯,sogou可以考虑白天主打新闻类推送,并且避免在就餐时间。夜间主打娱乐休闲类推送,最佳时间为晚上9点。但一定不要超过晚上9点。
14. 31日的数据量极少(100条以内)。
15. 96.8%的人都是日间活动者。
16. “夜猫子”中绝大多数都并非是因为工作因素熬夜,二是为了休闲娱乐,或是陷入感情困扰。可以有选择性地在夜间进行热门话题、情感类、游戏类资讯的推送,减少政治新闻类的推送。
填坑笔记:
1. 使用hive -e 'sql语句' > 文件名这种方式将数据从hive导出到文件系统时,最后2行会导入WARN信息问题:
WARN: The method class org.apache.commons.logging.impl.SLF4JLogFactory#release() was invoked.
WARN: Please see http://www.slf4j.org/codes.html#release for an explanation。需要另外进行删除。这样才能顺利在别的数据分析软件内成功读入数据。
2. 运行Hadoop程序时,有时候会报以下错误:
org.apache.hadoop.dfs.SafeModeException: Cannot ... . Name node is in safe mode。只要在Hadoop的目录下输入:
bin/hadoop dfsadmin -safemode leave命令,就可以关闭安全模式
3. 重启虚拟机后,宿主机和虚拟机之间的共享文件夹会分隔,需要重新挂载。 sudo mount -t vboxsf gongxiang(这个是宿主机中要共享文件名) /mnt/share(linux下共享路径)
Sogou日志分析(hive)的更多相关文章
- 基于hive的日志分析系统
转自 http://www.cppblog.com/koson/archive/2010/07/19/120773.html hive 简介 hive 是一个基于 ...
- Hadoop学习笔记—20.网站日志分析项目案例(一)项目介绍
网站日志分析项目案例(一)项目介绍:当前页面 网站日志分析项目案例(二)数据清洗:http://www.cnblogs.com/edisonchou/p/4458219.html 网站日志分析项目案例 ...
- Hadoop学习笔记—20.网站日志分析项目案例(三)统计分析
网站日志分析项目案例(一)项目介绍:http://www.cnblogs.com/edisonchou/p/4449082.html 网站日志分析项目案例(二)数据清洗:http://www.cnbl ...
- yhd日志分析(一)
yhd日志分析(一) 依据yhd日志文件统计分析每日各时段的pv和uv 建hive表, 表列分隔符和文件保持一致 load数据到hive表 写hive sql统计pv和uv, 结果保存到hive表2 ...
- 海量WEB日志分析
Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, ...
- HDInsight-Hadoop实战(一)站点日志分析
HDInsight-Hadoop实战(一)站点日志分析 简单介绍 在此演示样例中.你将使用分析站点日志文件的 HDInsight 查询来深入了解客户使用站点的方式.借助此分析.你可查看外部站点一天内对 ...
- 基于SQL的日志分析工具myselect
基本介绍 程序开发者常常要分析程序日志,包括自己打印的日志及使用的其他软件打印的日志,如php,nginx日志等,linux环境下分析日志有一些内置命令能够使用,如grep,sort,uniq,awk ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- Hadoop日志分析系统启动脚本
Hadoop日志分析系统启动脚本 #!/bin/bash #Flume日志数据的根文件夹 root_path=/flume #Mapreduce处理后的数据文件夹 process_path=/proc ...
随机推荐
- /usr/local/sbin/fping -s www.baidu.com www.google.com
/usr/local/sbin/fping -s www.baidu.com www.google.com
- 常用css和js组件
1 . input框中插入图标 <div class="col-sm-12 col-xs-12 setLineHeight"> <div class=" ...
- Azure 镜像市场支持一键部署到云
本视频教程介绍了Azure 镜像市场和一键部署到云. Azure 镜像市场(AMP)由世纪互联运营,是一个联机应用程序和服务市场,它通过独立软件服务商(ISV)能够成为 Azure 客户(Custom ...
- Python+selenium之跳过测试和预期失败
在运行测试时,需要直接跳过某些测试用例,或者当用例符合某个条件时跳过测试,又或者直接将测试用例设置为失败.unittest单元测试框架提供了实现这些需求的装饰器. 1.unittest.skip(re ...
- JAVA-WEB总结01
1 工具常用的快捷键 1) Eclipse和MyEclipse,IBM,2001,Java编写,开源,跨平台跨语言 2)Alt+/快速内容提示(自己习惯定义) 3)Ctrl+1快速修补错误 ...
- iphone开发思维导图
- 2018.4.18 Ubuntu 的telnet命令详解
Ubuntu 的telnet命令详解 1.作用用途 Telnet 命令通常用来远程登录,Telnet 程序是基于 Telnet 协议的远程登录客户端程序.Telnet 协议是TCP/IP协议族中的一员 ...
- CentOS安装RabbitMQ步骤
1.安装gcc yum install gcc 安装 ncurses-devel yum install ncurses-devel 2.安装erlang 下载安装包 http://www.erlan ...
- Java中的ArrayList类和LinkedList
集合的体系: ----------| Collection 单列集合的根接口----------------| List 如果实现了List接口的集合类,具备的特点: 有序,可重复.--------- ...
- C# 数据结构 - 单链表 双链表 环形链表
链表特点(单链表 双链表) 优点:插入和删除非常快.因为单链表只需要修改Next指向的节点,双链表只需要指向Next和Prev的节点就可以完成插入和删除操作. 缺点:当需要查找某一个节点的时候就需要一 ...