Python爬虫作业
题目如下:
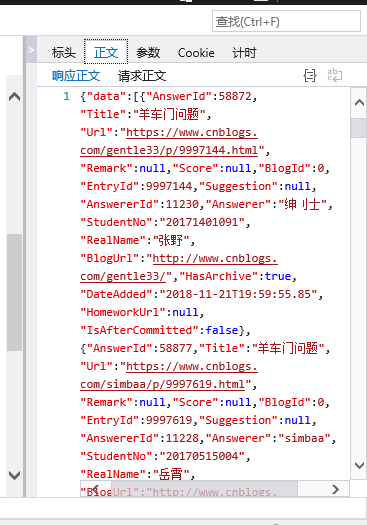

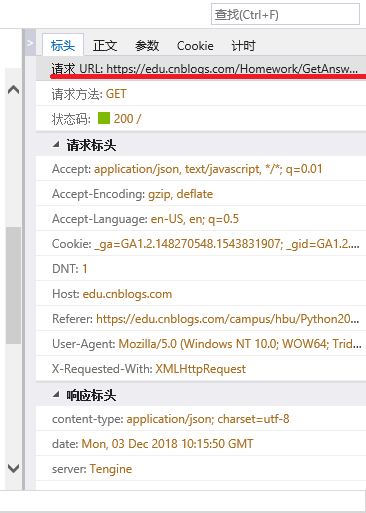
import requests as r
import json
url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543832146743"
try:
myhead = {'user-agent':'Mozilla/5.0'}
wb = r.get(url,headers=myhead,timeout=100)
wb.raise_for_status() #状态码不为200,引发HTttpERROR异常
wb.encoding = wb.apparent_encoding
key1 = wb.text
except:
print ("ERROR!")
#json.load返回字典类型,获取data索引后的信息,即目标json信息
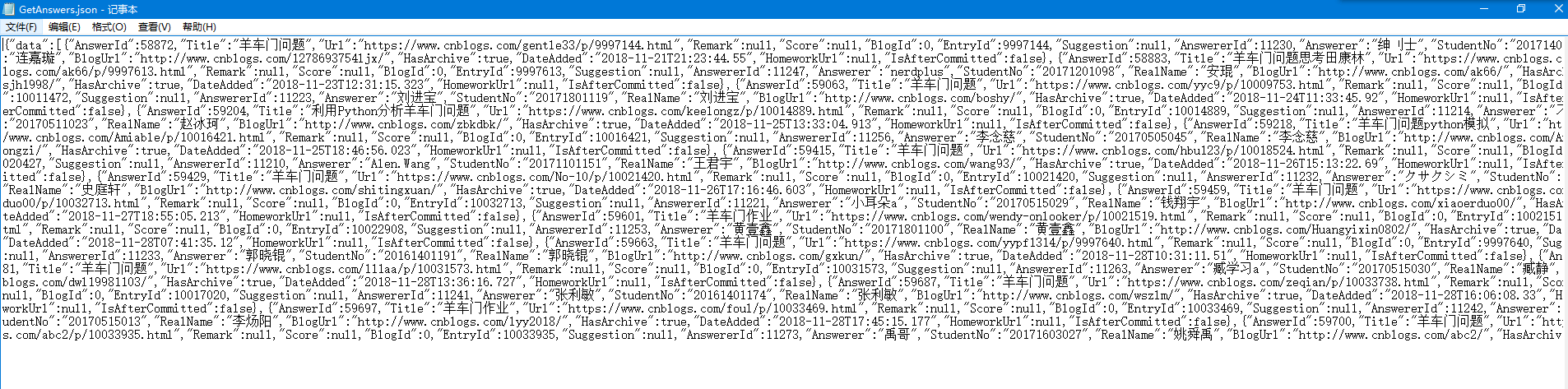
json1=json.loads(key1)['data']
#现在json1是列表了,开始逐行取信息,写到文件中
#注意学号用字符串保存,否则在excel中会按数字处理,即用科学计数法表示
#提交时间中,日期和时间中有个‘T’,用replace替换掉
keydata=' '
with open('hwlist.csv','w') as keyfile:
for index in json1:
keyfile.write(str(index['StudentNo'])+','+index['RealName']+','+index['DateAdded'].replace('T',' ')+','+index['Title']+','+index['Url']+'\n')
#有毒,明明IDE上缩进是对的
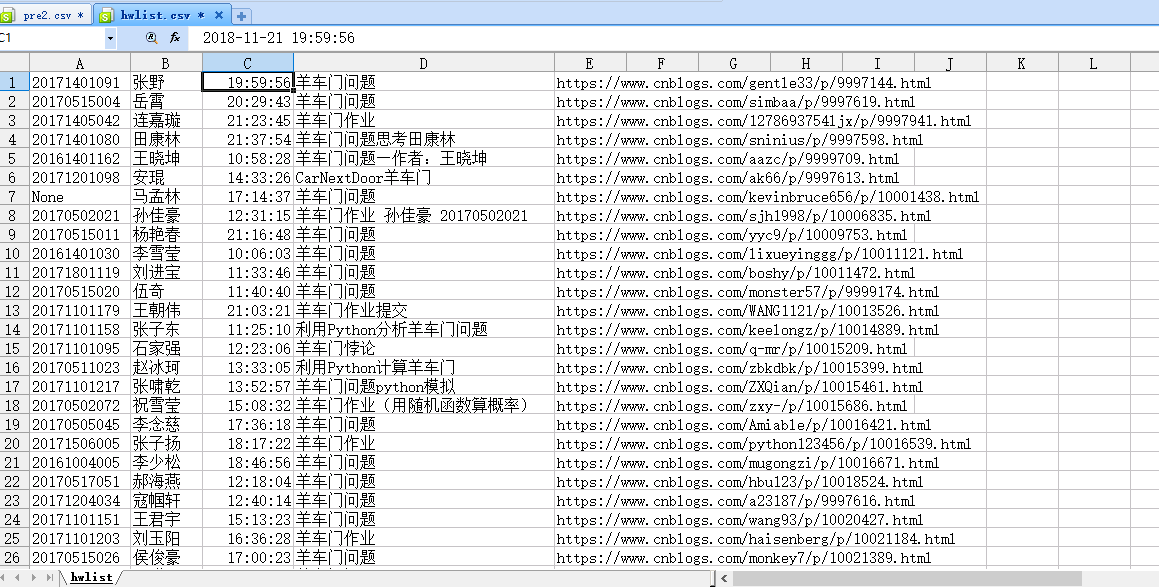
hwlist.csv打开后如下:好像是我excel设置的问题,日期无法好好显示,不过看单元格值应该是正确的
附:
其实上面的方法并不是我的本意…
我一开始看到目标文件是csv,就想到了解析大数据的神器——panda库。
panda库里的read_json可以把json字符串文件解析为panda自带的数据类型——Series或者Dataframe(直观的看上去就是一维数组与二维数组)
然后利用to_csv可以直接实现把数据转为csv文件格式。(当然也有to_txt,to_excel等等,很强大的库)
先看下我的代码:
import requests as r
import json
import pandas as pd
url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543832146743"
keyweb = r.get(url)
json1= json.loads(keyweb.text)['data']
keyjson = json.dumps(json1)
keytable = pd.read_json(keyjson)
#keytable.to_csv('pre1.csv')
keytable.to_csv('pre2.csv',columns=['StudentNo', 'RealName','Title','DateAdded','Url'],index=False,header=True)
处理源数据的手法都类似。不同的是,我们处理完json数据之后。再用json.dumps把处理好的数据转回为json字符串格式。
然后调用panda库的read_json方法,把这个json字符串转为panda库的dataframe格式。
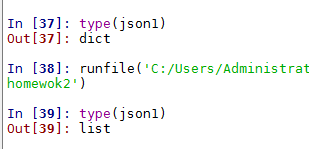
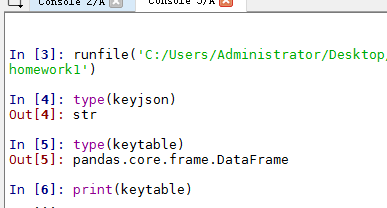
可以type一下,一目了然。
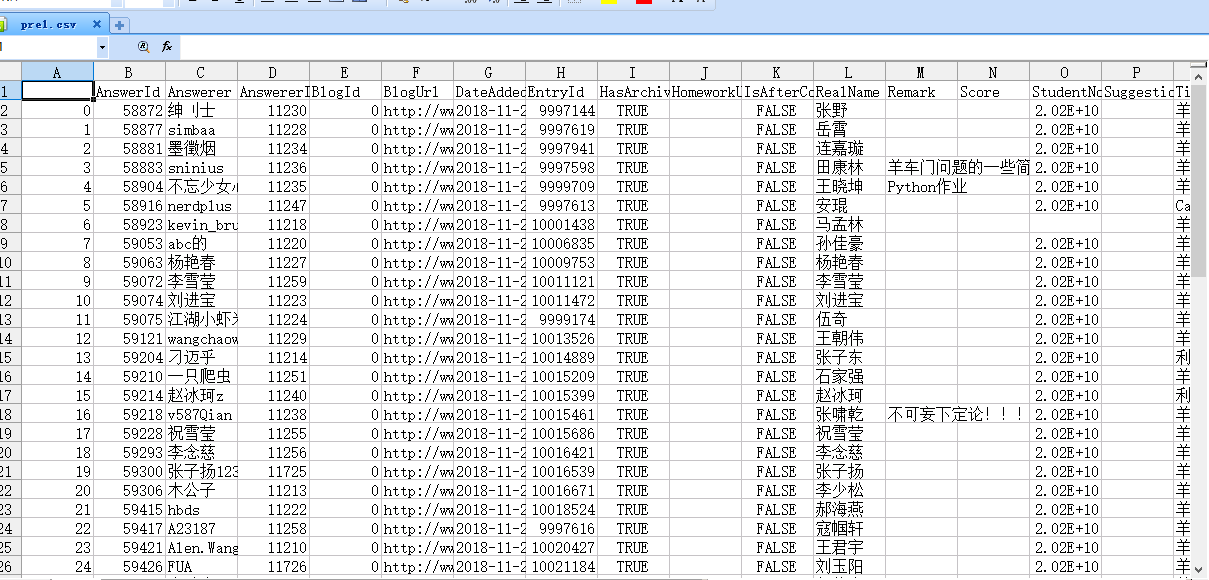
看上去万事俱备了,我们直接to_csv一波。
keytable.to_csv('pre1.csv')
问题出现了:是解析成了一个csv表不错,但是好多列都是我们不需要的。(包括莫名其妙的索引)
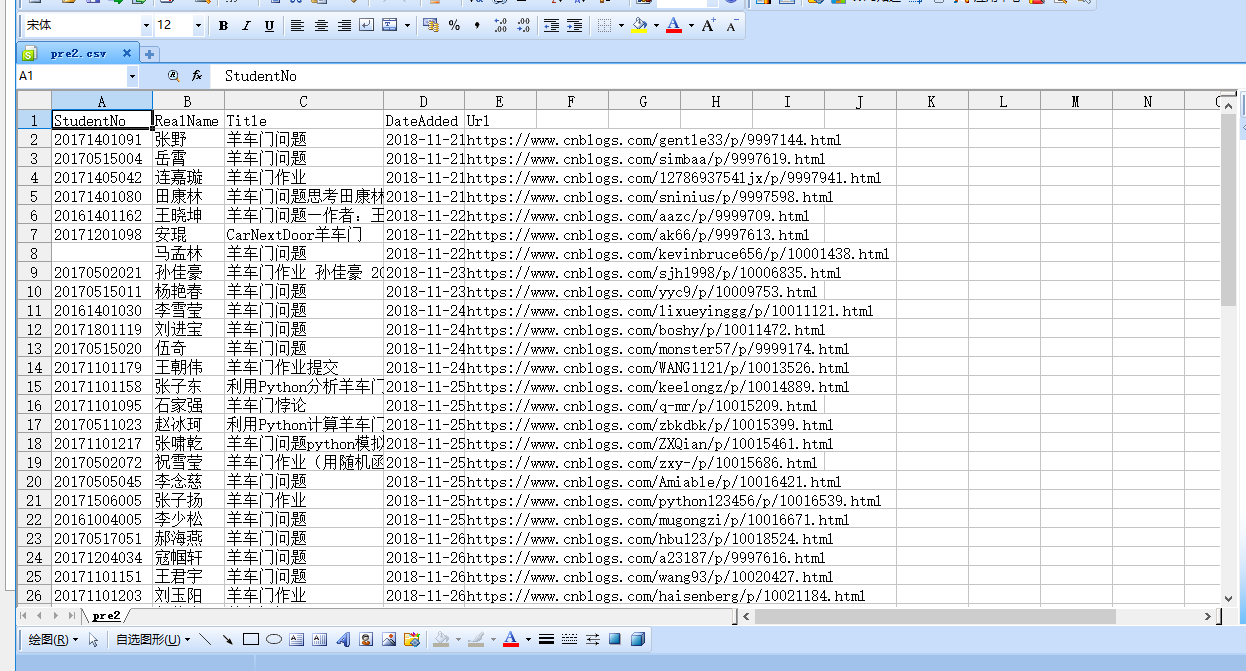
还好,to_csv方法给我们提供了参数来解决这些问题。
keytable.to_csv('pre2.csv',columns=['StudentNo', 'RealName','Title','DateAdded','Url'],index=False,header=True)
columns=['1’,'2'…]:只保留某些列的内容,这里我们保存学号,姓名,标题,提交时间,网址这些列
index=False:不写默认是true,会在第一列添加一列索引。且默认从0开始,我们用excel浏览,不太需要。X掉。
header=True:保留表头,位置在全表第一行。不写默认是true.
于是处理后的pre2.csv如下:
看上去问题解决了?不然:
我在其中遇到最大的问题就是:提交时间中那个“T”到底怎么处理掉?
有一位仁兄也用的panda库完成的作业,我参考了一下:是先把json数据处理好后,用panda库的DataFrame()将其转换成dataframe格式,并用colums给每个列命名,之后再用to_csv解析成csv格式。
这不失为一种很好的解决方案。
那么,可以不可以对我这种“暴力”转换的dataframe格式中的数据直接进行查值替换这类的操作呢?
研究了半天,最后也没有解决,可能是对panda库操作还是太少。希望有人能指点一下,不胜感激。
总结:
爬虫对我来说并不新鲜,但我却一直没有多加应用。
爬虫并不是get个url,直接.text这么简单的。
对于requests库的掌握都有些生疏。更不要提bs4和re这些了,对于信安专业的学生,不客气的说,这是不可原谅的。
努力弥补吧。
Python爬虫作业的更多相关文章
- 【Python】:简单爬虫作业
使用Python编写的图片爬虫作业: #coding=utf-8 import urllib import re def getPage(url): #urllib.urlopen(url[, dat ...
- Python爬虫之12306-分析请求总概述
python爬虫也学了一段时间了.也爬过不少网站,最后我想用12306抢票器这个项目做一个对之前的学习的效果成见也是一个目标(开始学爬虫的时候,看到说,会爬12306,就会爬80%的网站),本人纯自学 ...
- 路飞学城Python爬虫课第一章笔记
前言 原创文章,转载引用务必注明链接.水平有限,如有疏漏,欢迎指正. 之前看阮一峰的博客文章,介绍到路飞学城爬虫课程限免,看了眼内容还不错,就兴冲冲报了名,99块钱满足以下条件会返还并送书送视频. 缴 ...
- 从零起步 系统入门Python爬虫工程师 ✌✌
从零起步 系统入门Python爬虫工程师 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 大数据时代,python爬虫工程师人才猛增,本课程专为爬虫工程师打造, ...
- 路飞学城-Python爬虫集训-第三章
这个爬虫集训课第三章的作业讲得是Scrapy 课程主要是使用Scrapy + Redis实现分布式爬虫 惯例贴一下作业: Python爬虫可以使用Requests库来进行简单爬虫的编写,但是Reque ...
- 风变编程笔记(二)-Python爬虫精进
第0关 认识爬虫 1. 浏览器的工作原理首先,我们在浏览器输入网址(也可以叫URL),然后浏览器向服务器传达了我们想访问某个网页的需求,这个过程就叫做[请求]紧接着,服务器把你想要的网站数据发送给浏 ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
随机推荐
- js学习笔记之随机数
一. JS获取任意两个数之间的随机数 参考:https://www.jb51.net/article/89629.htm 二.获取一个10–100范围的数 参考:https://zhidao.baid ...
- IOS 九宫图解锁(封装)
NJLockView.h /.m @class NJLockView; @protocol NJLockViewDelegate <NSObject> - (void)lockViewDi ...
- UVA 12169 Disgruntled Judge(Extended_Euclid)
用扩展欧几里德Extended_Euclid解线性模方程,思路在注释里面了. 注意数据范围不要爆int了. /********************************************* ...
- iOS keychain注解
+ (NSMutableDictionary *)getKeychainQuery:(NSString *)service { return [NSMutableDictionary dictiona ...
- 【转】iOS开发之压缩与解压文件
ziparchive是基于开源代码”MiniZip”的zip压缩与解压的Objective-C 的Class,使用起来非常的简单方法:从http://code.google.com/p/ziparch ...
- CopyOnWriteArrayList分析——能解决什么问题
CopyOnWriteArrayList主要可以解决的问题是并发遍历读取无锁(通过Iterator) 对比CopyOnWriteArrayList和ArrayList 假如我们频繁的读取一个可能会变化 ...
- oc block排序
NSArray *sortArr=[arr sortedArrayUsingSelector:@selector(compareWithClassAndName:)]; //数组排序--block N ...
- 第三篇:彻底解决ssh.invoke_shell() 返回的中文问题
接上一篇,前两篇解决中文的问题主要是在字符集上做的手脚,即将中文转成英文,但是有一种情况我们都来不及做转换,即登录时服务器直接返回了中文内容: 此时程序报了如下错误,其实还是字符集问题: 为此:我们可 ...
- 用户和用户组以及 Linux 权限管理
1.从 /etc/passwd 说起 前面的基本命令学习中,我们介绍了使用 passwd 命令可以修改用户密码.对于操作系统来说,用户名和密码是存放在哪里的呢?我们都知道一个站点的用户名和密码是存放在 ...
- windows_Bat_Scripts查看系统IP-更改regedit-更新系统补丁
1.1 脚本名称 Update_patch.bat 1.2 脚本代码 @echo off :menu cls mode con cols=48 lines=27 & color 0 ...