Apache Hudi:CDC的黄金搭档
1. 介绍
Apache Hudi是一个开源的数据湖框架,旨在简化增量数据处理和数据管道开发。借助Hudi可以在Amazon S3、Aliyun OSS数据湖中进行记录级别管理插入/更新/删除。AWS EMR集群已支持Hudi组件,并且可以与AWS Glue Data Catalog无缝集成。此特性可使得直接在Athena或Redshift Spectrum查询Hudi数据集。
对于企业使用AWS云的一种常见数据流如图1所示,即将数据实时复制到S3。
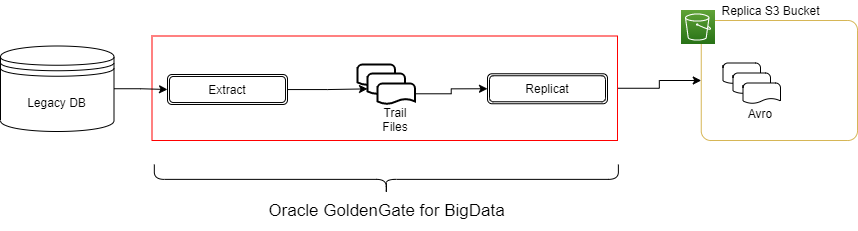
本篇文章将介绍如何使用Oracle GoldenGate来捕获变更事件并利用Hudi格式写入S3数据湖。
Oracle GG可以使用多个处理程序和格式输出,请查看此处获取更多信息。
本篇文章中不关心处理程序,我们假设使用Avro Operation格式,这种格式较为冗长,但有着广泛应用,因为其平衡了数据完整性和性能。如图2所示,此格式包含每个记录的before和after版本。

即使完整且易于生成,此格式也不适合用Athena或Spectrum进行分析,从使用角度也无法替代源数据。此外你可能需要对历史数据进行分区处理以便快速检索。
本文我们将介绍如何利用Apache Hudi框架做到这一点,以构建易于分析的目标数据集。
2. 系统架构
我们不详细介绍如何将avro格式文件放入Replica S3桶中,整个数据体系结构如下所示
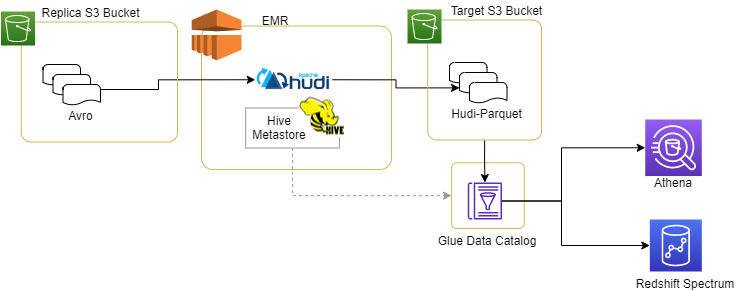
Hudi代码运行在EMR集群中,从Replica S3桶中读取avro数据,并将目标数据集存储到Target S3桶中。
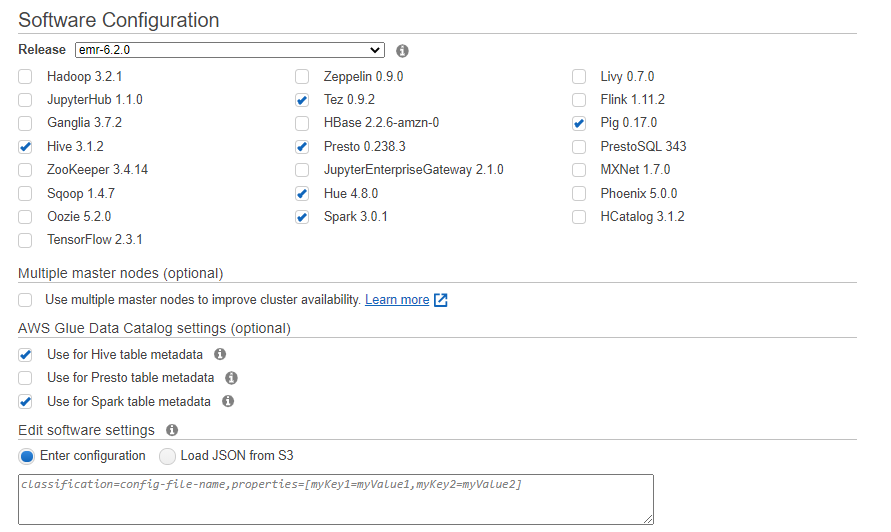
EMR软件配置如下
硬件配置如下
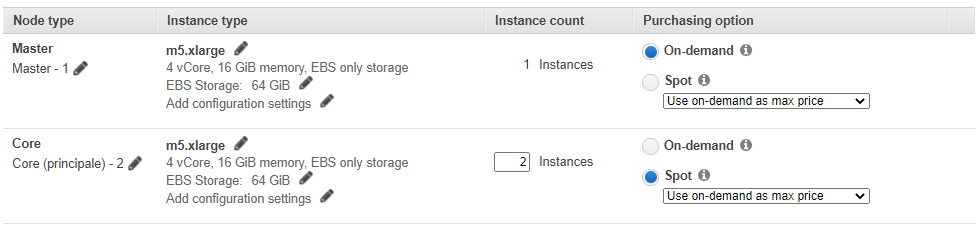
由于插入/更新始终保留最后一条记录,因此Hudi作业非常具有弹性, 因此可以利用Spot Instance(抢占式实例)大大降低成本。
除此之外,还需要设置
- 源bucket(如 my-s3-sourceBucket)
- 目标bucket (如 my-s4-targetBucket)
- Glue数据库(如 sales-db)
配置完后需要确保EMR集群有读写权限。
如果你需要一些样例数据,可以点击此处获取。当设置好桶后,启动EMR集群并将这些样例数据导入Replica桶。
3. 关于分区的注意事项
为构建按时间划分的数据集,必须确定不可变的日期类型字段。参照示例数据集(销售订单),我们假设订单日期永远不会改变,因此我们将DAT_ORDER字段作为写入Hudi数据集的分区字段。
分区方式是YYYY/MM/DD,通过该方式,所有数据将被组织在嵌套的子文件夹中。Hudi框架将提供此分区信息,并将一个特定字段添加到关联的Hive/Glue表中。当查询时,该字段上的过滤条件将转换为超高效的分区修剪扫描条件。
实际上这是我们必须对数据集做的唯一强假设,所有其他信息都在avro文件中(字段名称,字段类型,PK等)。
除此元数据外,GoldenGate通常还会添加一些其他信息,例如表名称,操作时间戳,操作类型(插入/更新/删除)和自定义标记。你可以利用这些字段来构造通用逻辑并构建灵活的迁移平台。
4. 步骤
启动spark-shell
spark-shell --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer" --conf "spark.sql.hive.convertMetastoreParquet=false" --jars /usr/lib/hudi/hudi-spark-bundle.jar,/usr/lib/spark/external/lib/spark-avro.jar
启动后可以运行如下代码:
val ggDeltaFiles = "s3://" + sourceBucket + "/" + sourceSubFolder + "/" + sourceSystem + "/" + inputTableName + "/";
val rootDataframe:DataFrame = spark.read.format("avro").load(ggDeltaFiles);
// extract PK fields name from first line
val pkFields: Seq[String] = rootDataframe.select("primary_keys").limit(1).collect()(0).getSeq(0);
// take into account the "after." fields only
val columnsPre:Array[String] = rootDataframe.select("after.*").columns;
// exclude "_isMissing" fields added by Oracle GoldenGate
// The second part of the expression will safely preserve all native "**_isMissing" fields
val columnsPost:Array[String] = columnsPre.filter { x => (!x.endsWith("_isMissing")) || (!x.endsWith("_isMissing_isMissing") && (columnsPre.filter(y => (y.equals(x + "_isMissing")) ).nonEmpty))};
val columnsFinal:ArrayBuffer[String] = new ArrayBuffer[String]();
columnsFinal += "op_ts";
columnsFinal += "pos";
// add the "after." prefix
columnsPost.foreach(x => (columnsFinal += "after." + x));
// prepare the target dataframe with the partition additional column
val preparedDataframe = rootDataframe.select("opTypeFieldName", columnsFinal.toArray:_*).
withColumn("HUDI_PART_DATE", date_format(to_date(col("DAT_ORDER"), "yyyy-MM-dd"),"yyyy/MM/dd")).
filter(col(opTypeFieldName).isin(admittedValues.toList: _*));
// write data
preparedDataframe.write.format("org.apache.hudi").
options(hudiOptions).
option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, pkFields.mkString(",")).
mode(SaveMode.Append).
save(hudiTablePath);
上述简化了部分代码,可以在此处找到完整的代码。
5. 结果
输出的S3对象结果如下所示
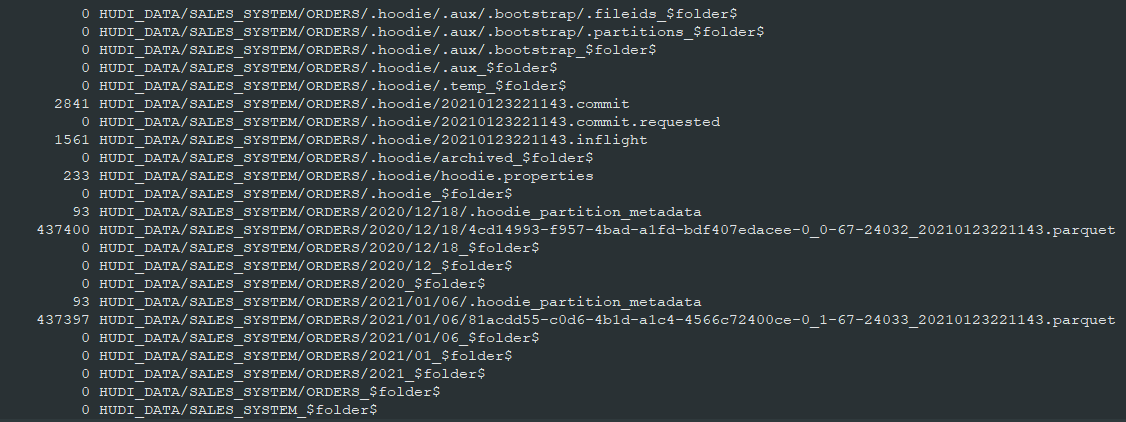
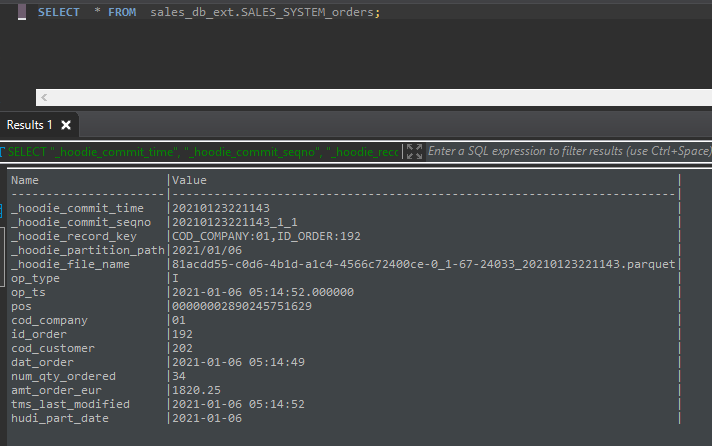
同时Glue数据目录将使该表可用于通过外部模式在Athena或Spectrum中进行查询分析,外部表具有我们用于分区的hudi_part_date附加字段。
Apache Hudi:CDC的黄金搭档的更多相关文章
- 基于Apache Hudi 的CDC数据入湖
作者:李少锋 文章目录: 一.CDC背景介绍 二.CDC数据入湖 三.Hudi核心设计 四.Hudi未来规划 1. CDC背景介绍 首先我们介绍什么是CDC?CDC的全称是Change data Ca ...
- 基于Apache Hudi和Debezium构建CDC入湖管道
从 Hudi v0.10.0 开始,我们很高兴地宣布推出适用于 Deltastreamer 的 Debezium 源,它提供从 Postgres 和 MySQL 数据库到数据湖的变更捕获数据 (CDC ...
- 使用Amazon EMR和Apache Hudi在S3上插入,更新,删除数据
将数据存储在Amazon S3中可带来很多好处,包括规模.可靠性.成本效率等方面.最重要的是,你可以利用Amazon EMR中的Apache Spark,Hive和Presto之类的开源工具来处理和分 ...
- 直播 | Apache Kylin & Apache Hudi Meetup
千呼万唤始出来,Meetup 直播终于来啦- 本次线上 Meetup 由 Apache Kylin 与 Apache Hudi 社区联合举办,将于 3 月 14 日晚进行直播,邀请到来自丁香园.腾讯. ...
- 官宣!ASF官方正式宣布Apache Hudi成为顶级项目
马萨诸塞州韦克菲尔德(Wakefield,MA)- 2020年6月 - Apache软件基金会(ASF).350多个开源项目和全职开发人员.管理人员和孵化器宣布:Apache Hudi正式成为Apac ...
- 使用Apache Hudi构建大规模、事务性数据湖
一个近期由Hudi PMC & Uber Senior Engineering Manager Nishith Agarwal分享的Talk 关于Nishith Agarwal更详细的介绍,主 ...
- 官宣!AWS Athena正式可查询Apache Hudi数据集
1. 引入 Apache Hudi是一个开源的增量数据处理框架,提供了行级insert.update.upsert.delete的细粒度处理能力(Upsert表示如果数据集中存在记录就更新:否则插入) ...
- Apache Hudi和Presto的前世今生
一篇由Apache Hudi PMC Bhavani Sudha Saktheeswaran和AWS Presto团队工程师Brandon Scheller分享Apache Hudi和Presto集成 ...
- Apache Hudi助力nClouds加速数据交付
1. 概述 在nClouds上,当客户的业务决策取决于对近实时数据的访问时,客户通常会向我们寻求有关数据和分析平台的解决方案.但随着每天创建和收集的数据量都在增加,这使得使用传统技术进行数据分析成为一 ...
随机推荐
- node.js module.exports & exports & module.export all in one
node.js module.exports & exports & module.export all in one cjs const log = console.log; log ...
- ES6 arrow function vs ES5 function
ES6 arrow function vs ES5 function ES6 arrow function 与 ES5 function 区别 this refs xgqfrms 2012-2020 ...
- Chrome new features preview
Chrome new features preview CSS Overview https://css-tricks.com/new-in-chrome-css-overview/ capture ...
- server sent events
server sent events server push https://html5doctor.com/server-sent-events/ https://developer.mozilla ...
- NGK.IO超级节点是我们掌握的下一个财富密码吗?
从日前NGK.IO发布的新闻中,我们捕捉到了一个非常重要的信息,那就是反复被提到的"超级节点".很多人都对这个"超级节点"一头雾水,这个"超级节点&q ...
- 瞧一瞧React Fiber
啥是React Fiber? React Fiber,简单来说就是一个从React v16开始引入的新协调引擎,用来实现Virtual DOM的增量渲染. 说人话:就是一种能让React视图更新过程变 ...
- JMM内存模型相关笔记整理
JMM 内存模型是围绕并发编程中原子性.可见性.有序性三个特征来建立的 原子性:就是说一个操作不能被打断,要么执行完要么不执行,类似事务操作,Java 基本类型数据的访问大都是原子操作,long 和 ...
- 解决ROS及Fast-RTPS安装和使用中raw.githubusercontent.com无法连接的问题
资料参考: https://blog.csdn.net/weixin_44692299/article/details/105869229
- Unity3d 拖拽脚本报错Can't add the script component "" because the script class cannot be found
解决办法: ①报错原因:文件名与文件内容中的类名不相符. ②关闭360.鲁大师等防护软件,重新安装系统.
- 1079 Total Sales of Supply Chain ——PAT甲级真题
1079 Total Sales of Supply Chain A supply chain is a network of retailers(零售商), distributors(经销商), a ...