MySQL存储索引InnoDB数据结构为什么使用B+树,而不是其他树呢?
InnoDB的一棵B+树可以存放多少行数据?
答案:约2千万
为什么是这么多?
因为这是可以算出来的,要搞清楚这个问题,先从InnoDB索引数据结构、数据组织方式说起。
计算机在存储数据的时候,有最小存储单元,这就好比现金的流通最小单位是一毛。
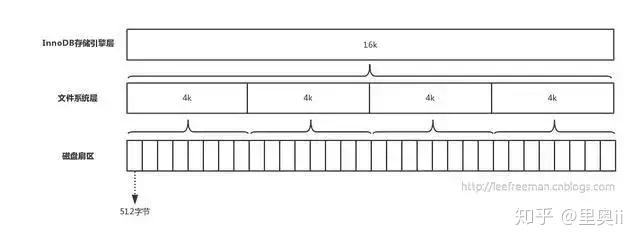
在计算机中,磁盘存储数据最小单元是扇区,一个扇区的大小是512字节,而文件系统(例如XFS/EXT4)的最小单元是块,一个块的大小是4k,而对于InnoDB存储引擎也有自己的最小储存单元,页(Page),一个页的大小是16K。
下面几张图可以理解最小存储单元:
文件系统中一个文件大小只有1个字节,但不得不占磁盘上4KB的空间。
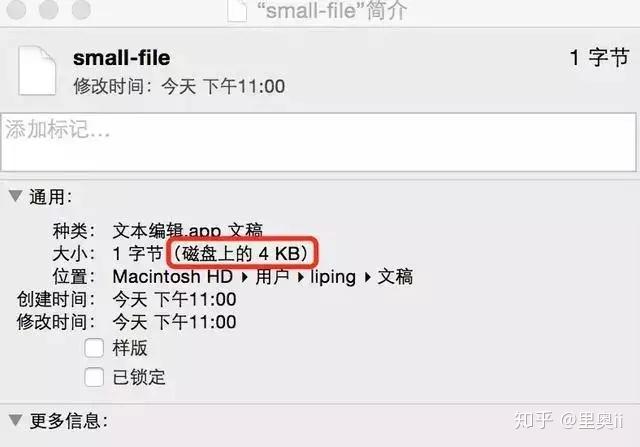
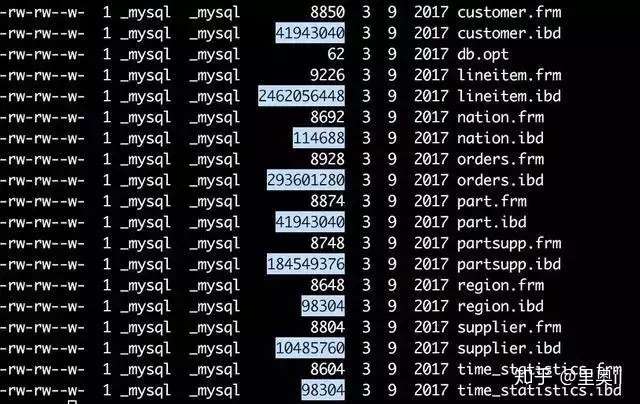
InnoDB的所有数据文件(后缀为ibd的文件),大小始终都是16384(16k)的整数倍。
磁盘扇区、文件系统、InnoDB存储引擎都有各自的最小存储单元。
在MySQL中,InnoDB页的大小默认是16k,当然也可以通过参数设置:

表中的数据都是存储在页中的,所以一个页中能存储多少行数据呢?
假设一行数据的大小是1k,那么一个页可以存放16行这样的数据。
如果数据库只按这样的方式存储,如何查找数据就成为一个问题,因为不知道要查找的数据存在哪个页中,也不可能把所有的页遍历一遍,那样太慢了。
不过,可以使用B+树的方式组织这些数据,如图所示:
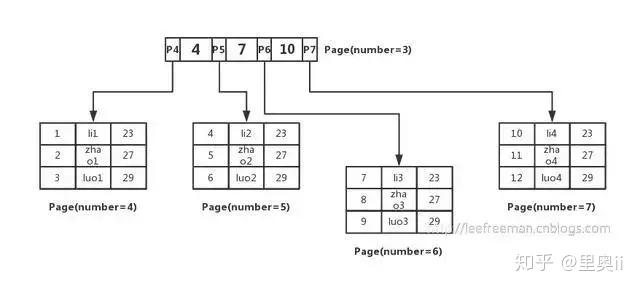
先将数据记录按主键进行排序,分别存放在不同的页中(为了便于理解这里一个页中只存放3条记录,实际情况可以存放很多)
除了存放数据的页以外,还有存放键值+指针的页,如图中page number=3的页,该页存放键值和指向数据页的指针,这样的页由N个键值+指针组成。
当然它也是排好序的。这样的数据组织形式,我们称为索引组织表。
现在来看下,要查找一条数据,怎么查?
如:select * from user where id=5;
这里id是主键,通过这棵B+树来查找,首先找到根页,你怎么知道user表的根页在哪呢?
其实每张表的根页位置在表空间文件中是固定的,即page number=3的页。
找到根页后通过二分查找法,定位到id=5的数据应该在指针P5指向的页中,那么进一步去page number=5的页中查找,同样通过二分查询法即可找到id=5的记录:
| 5 | zhao2 | 27 |
现在清楚了InnoDB中主键索引B+树是如何组织数据、查询数据的。
总结一下:
- InnoDB存储引擎的最小存储单元是页,页可以用于存放数据也可以用于存放键值+指针,在B+树中叶子节点存放数据,非叶子节点存放键值+指针。
- 索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而在去数据页中查找到需要的数据;
那么回到我们开始的问题,通常一棵B+树可以存放多少行数据?
这里我们先假设B+树高为2,即存在一个根节点和若干个叶子节点,那么这棵B+树的存放总记录数为:根节点指针数*单个叶子节点记录行数。
上文已经说明单个叶子节点(页)中的记录数=16K/1K=16。(这里假设一行记录的数据大小为1k,实际上现在很多互联网业务数据记录大小通常就是1K左右)。
那么现在需要计算出非叶子节点能存放多少指针?
其实这也很好算,假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节
我们一个页中能存放多少这样的单元,其实就代表有多少指针,即16384/14=1170。
那么可以算出一棵高度为2的B+树,能存放1170*16=18720条这样的数据记录。
根据同样的原理可以算出一个高度为3的B+树可以存放:1170117016=21902400条这样的记录。
所以在InnoDB中B+树高度一般为1-3层,它就能满足千万级的数据存储。
在查找数据时,一次页的查找代表一次IO,所以通过主键索引查询通常只需要1-3次IO操作即可查找到数据。
怎么得到InnoDB主键索引B+树的高度?
上面通过推断得出B+树的高度通常是1-3,下面从另外一个侧面证明这个结论。
在InnoDB的表空间文件中,约定page number为3的代表主键索引的根页,而在根页偏移量为64的地方存放了该B+树的page level。
如果page level为1,树高为2,page level为2,则树高为3。即B+树的高度=page level+1;下面将从实际环境中尝试找到这个page level。
在实际操作之前,可以通过InnoDB元数据表确认主键索引根页的page number为3,也可以从《InnoDB存储引擎》这本书中得到确认。


可以看出数据库dbt3下的customer表、lineitem表主键索引根页的page number均为3,而其他的二级索引page number为4。
关于二级索引与主键索引的区别请参考MySQL相关书籍,本文不在此介绍。
下面对数据库表空间文件做想相关的解析:
因为主键索引B+树的根页在整个表空间文件中的第3个页开始,所以可以算出它在文件中的偏移量:16384*3=49152(16384为页大小)。
另外根据《InnoDB存储引擎》中描述在根页的64偏移量位置前2个字节,保存了page level的值
因此我想要的page level的值在整个文件中的偏移量为:16384*3+64=49152+64=49216,前2个字节中。
接下来用hexdump工具,查看表空间文件指定偏移量上的数据:
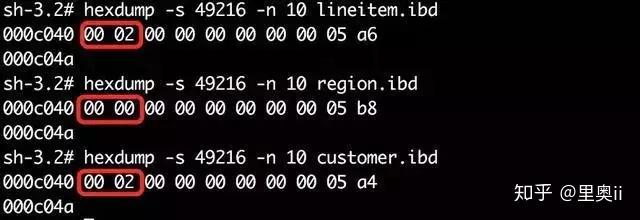
linetem表的page level为2,B+树高度为page level + 1 = 3;
region表的page level为0,B+树高度为page level + 1 = 1;
customer表的page level为2,B+树高度为page level + 1 = 3;
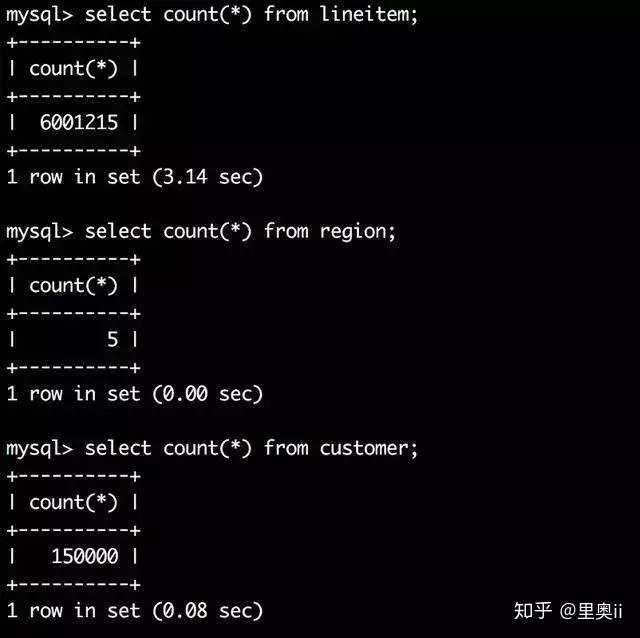
这三张表的数据量如下:
总结:
lineitem表的数据行数为600多万,B+树高度为3,customer表数据行数只有15万,B+树高度也为3。可以看出尽管数据量差异较大,这两个表树的高度都是3
换句话说这两个表通过索引查询效率并没有太大差异,因为都只需要做3次IO。那么如果有一张表行数是一千万,那么他的B+树高度依旧是3,查询效率仍然不会相差太大。
region表只有5行数据,当然他的B+树高度为1。
面试题
有一道MySQL的面试题,为什么MySQL的索引要使用B+树而不是其它树形结构?比如B树?
简单回答是:
因为B树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出)
指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
小结
本文从一个问题出发,逐步介绍了InnoDB索引组织表的原理、查询方式,并结合已有知识,回答该问题,结合实践来证明。
当然为了表述简单易懂,文中忽略了一些细枝末节,比如一个页中不可能所有空间都用于存放数据,它还会存放一些少量的其他字段比如page level,index number等等,另外还有页的填充因子也导致一个页不可能全部用于保存数据。
MySQL存储索引InnoDB数据结构为什么使用B+树,而不是其他树呢?的更多相关文章
- 常用Mysql存储引擎--InnoDB和MyISAM简单总结
常用Mysql存储引擎--InnoDB和MyISAM简单总结 2013-04-19 10:21:52| 分类: CCST|举报|字号 订阅 MySQL服务器采用了模块化风格,各部分之间保持相 ...
- MySQL存储引擎InnoDB,MyISAM
MySQL存储引擎InnoDB,MyISAM1.区别:(1)InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语 ...
- 深入了解MySQL存储索引
(一)关于存储引擎 创建合适的索引是SQL性能调优中最重要的技术之一.在学习创建索引之前,要先了解MySql的架构细节,包括在硬盘上面如何组织的,索引和内存用法和操作方式,以及存储引擎的差异如何影响到 ...
- MySQL存储引擎——InnoDB和MyISAM的区别
MySQL5.5后,默认存储引擎是InnoDB,5.5之前默认是MyISAM. InnoDB(事务性数据库引擎)和MyISAM的区别补充: InnoDB是聚集索引,数据结构是B+树,叶子节点存K-V, ...
- MySQL存储引擎 InnoDB/ MyISAM/ MERGE/ BDB 的区别
MyISAM:默认的MySQL插件式存储引擎,它是在Web.数据仓储和其他应用环境下最常使用的存储引擎之一.注意,通过更改 STORAGE_ENGINE 配置变量,能够方便地更改MySQL服务器的默认 ...
- 浅谈MySQL存储引擎-InnoDB&MyISAM
存储引擎在MySQL的逻辑架构中位于第三层,负责MySQL中的数据的存储和提取.MySQL存储引擎有很多,不同的存储引擎保存数据和索引的方式是不同的.每一种存储引擎都有它的优势和劣势,本文只讨论最常见 ...
- MySQL存储引擎InnoDB与Myisam
InnoDB与Myisam的六大区别 InnoDB与Myisam的六大区别 MyISAM InnoDB 构成上的区别: 每个MyISAM在磁盘上存储成三个文件.第一个 文件的名字以表的名字开始,扩展名 ...
- MySQL存储引擎InnoDB大量数据下的问题
MySQL如果只有MyISAM一个引擎的话,那你们黑真的也有道理,但问题是InnoDB现在已经是MySQL默认的引擎,而且这个引擎综合能力很强,能用好这个引擎其实就已经能解决大多数需要数据库的业务逻辑 ...
- mysql 存储引擎 InnoDB 与 MyISAM 的区别和选择
http://www.blogjava.net/jiangshachina/archive/2009/05/31/279288.html 酷壳 - MySQL: InnoDB 还是 MyISA ...
随机推荐
- spring boot:用zxing生成二维码,支持logo(spring boot 2.3.2)
一,zxing是什么? 1,zxing的用途 如果我们做二维码的生成和扫描,通常会用到zxing这个库, ZXing是一个开源的,用Java实现的多种格式的1D/2D条码图像处理库. zxing还可以 ...
- package wang/test is not in GOROOT (/usr/local/go/src/wang/test)
如果要用 gopath模式 引入包 从src目录下开始引入 需要关闭 go mod 模式 export GO111MODULE=off 如果使用go mod 模式 export GO111MODULE ...
- spring boot:redis+lua实现顺序自增的唯一id发号器(spring boot 2.3.1)
一,为什么需要生成唯一id(发号器)? 1,在分布式和微服务系统中, 生成唯一id相对困难, 常用的方式: uuid不具备可读性,作为主键存储时性能也不够好, mysql的主键,在分库时使用不够方便, ...
- nginx优化: timeout超时配置
一,为什么要做连接超时设置? nginx在保持着与客户端的连接时,要消耗cpu/内存/网络等资源, 如果能在超出一定时间后自动断开连接, 则可以及时释放资源,起到优化性能.提高效率的作用 说明:刘宏缔 ...
- html的keywords标签
<link rel="shortcut icon" href="favicon.ico" type="image/x-icon" /& ...
- Centos7 安装python环境
保留python2 找到python所在位置,把python指向python2.7备份 [root@sun /usr/bin]# cd ~ [root@sun ~]# whereis python p ...
- mybatis逆向工程配置
1.准备配置文件 <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE generatorConf ...
- java数据结构-06双向循环链表
双向循环链表跟单向链表一样,都是头尾相连,不过单向是尾指向头,双向是头尾互相指,可以从前往后查,也可以从后往前查 无头结点的双向循环链表 public class CircleLinkedList&l ...
- 关于transition中嵌套keep-alive的问题解决
需求:在使用keep-alive的同时使用transition动画效果 最开始是这样写的,但是发现报错,而且动画效果失效 <transition name="container-rig ...
- Luogu P5087 数学
题意 给定一个长度为 \(n\) 的序列 \(a_i\),求出在这个序列中所有选出 \(k\) 个元素方案中元素的乘积之和. \(\texttt{Data Range:}1\leq n\leq 10^ ...