Redis5设计与源码分析读后感(三)跳跃表
一、引言
有序集合在日常开发中相当常见,比如做排名等相关的功能,肯定要用到排序的功能,那么常见底层实现有很多种:
- 数组 :不便于元素的插入和删除
- 链表 :查询效率低,需要遍历所有元素
- 平衡树OR红黑树 :性能高但是实现复杂
所以这里就引出了本文的主角:
- 跳跃表 :性能堪比红黑树,但实现相对简单得多
二、跳跃表简介
首先,学习跳跃链表我们先要明白一个概念:
有序链表:所有元素以递增或者递减方式有序排列的数据结构,每个节点都有指向下个节点的next指针,最后一个节点的next指针指向NULL。
PS:有序链表的修改操作基本不耗时间,耗时主要在查找元素上面。

跳跃表:由于链表结构的耗时操作主要在于查找元素上,跳跃表则使用空间换时间的思想,将有序链表中的部分节点分层,每一层都是一个有序链表。
查找过程:先从最高层开始向后查找,当达到某个节点时,如果next节点值大于要查找的值或next指针指向NULL,则从当前节点下降一层继续向后查找。
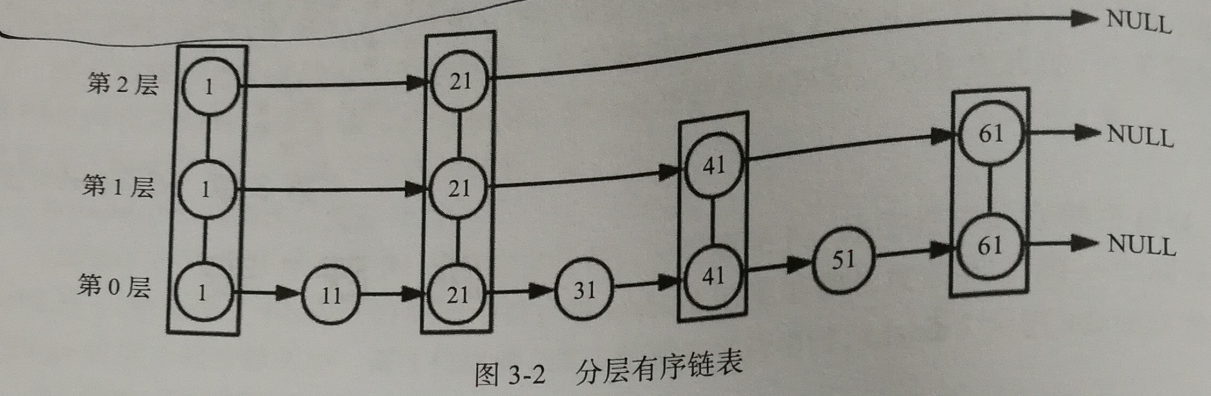
特性:
- 跳跃表由很多层组成
- 头节点(header)中有个64层的结构,每层包含指向本层下个节点的指针(forward)和之间跨越的节点个数跨度(span)
- 除去头节点外,层数最高的节点层高为跳跃表的高度
- 每一层都是有序链表,数据递增
- 除头节点外,一个元素在上层出现时,则一定会在下层有序链表中出现
- 跳跃表每层的最后一个节点指向NULL,表示本层结束
- 跳跃表有一个tail指针,指向跳跃表的最后一个节点
- 最底层的有序链表包含所有节点,最底层的节点个数为跳跃表的长度(不包括头节点)
- 每个节点包含一个后退指针,头节点和第一个节点指向NULL,其他节点指向最底层的前一个节点
排序规则:
- 按分值【score】从小到大排序
- 分值相同时根据成员内容【member即ele储存的字符串值】的字典序进行排序。
三、跳跃表结构
我们结合一张图来分析:
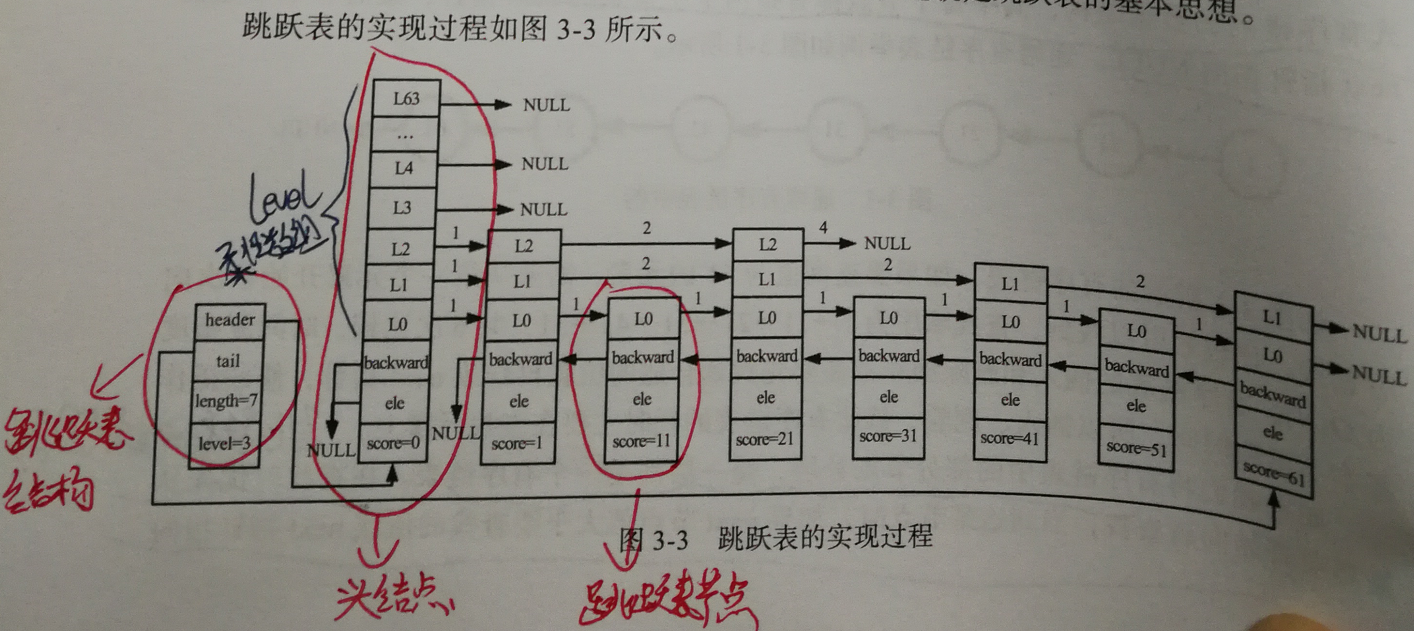
跳跃表节点【zskiplistNode】
- ele :用于储存字符串类型的数据
- score :用于储存排序的分值
- backward :后退指针,指向当前节点最底层的前一个结点,头节点和第一个节点指向NULL
- level :柔性数组,每个节点的数组长度不一样,根据生成时节点的层高来决定【比如当前节点层高为3,则level数组的长度也为3,即有3层存在此节点】,每项包含以下两个元素:
- forward :指向本层的下一个节点,尾节点指向NULL
- span :跨度,即本结点与forward指向的节点,之间的元素个数
跳跃表结构【zskiplist】
- header :指向跳跃表头结点,头结点的level数组元素个数为64,且不储存任何member和score值,ele为NULL,score为0,也不计入跳跃表总长度。
- tail :指向跳跃表尾节点。
- length :跳跃表的长度,表示除头结点之外的节点总数。
- level :跳跃表的高度。
四、创建跳跃表
计算节点层高
- 层高的最小值为1,最大值为64。
- 通过zslRamdomLevel函数随机生成1~64的值,作为新建节点的高度,值越大出现概率越低。
创建跳跃表节点
- 所有待创建节点的层高、分值和内容都已确定。
- 申请内存,内存大小为zskiplistNode的内存大小和level个zskiplistLevel的内存大小之和。
创建头节点
- 头节点是跳跃表中第一个插入的节点。
- 不储存集合的member信息,即不储存具体字符串内容。
- level数组的每项forward都为NULL,span都为0。
创建步骤
- 创建跳跃表结构体对象zsl。
- 将zsl的头节点指针指向新创建的头节点。
- 跳跃表层高初始化为1,长度初始化为0,尾节点指向NULL。
五、插入节点
查找要插入的位置
为了找到需要更新的节点,我们需要以下两个长度为64的数组来辅助操作:
- update[ ] :记录每层需要更新的节点。
- rank[ ] :记录当前层从header节点到update[ i ]节点所经历的步长,更新update[ i ]的span和设置插入节点的span时用到。

调整跳跃表高度
由于插入节点的高度是随机的,上面的例子中我们要插入一个level为3的节点,而插入前跳跃表的高度为2,则我们需要调整跳跃表的高度【只发生在插入节点高于当前跳跃表高度时】:
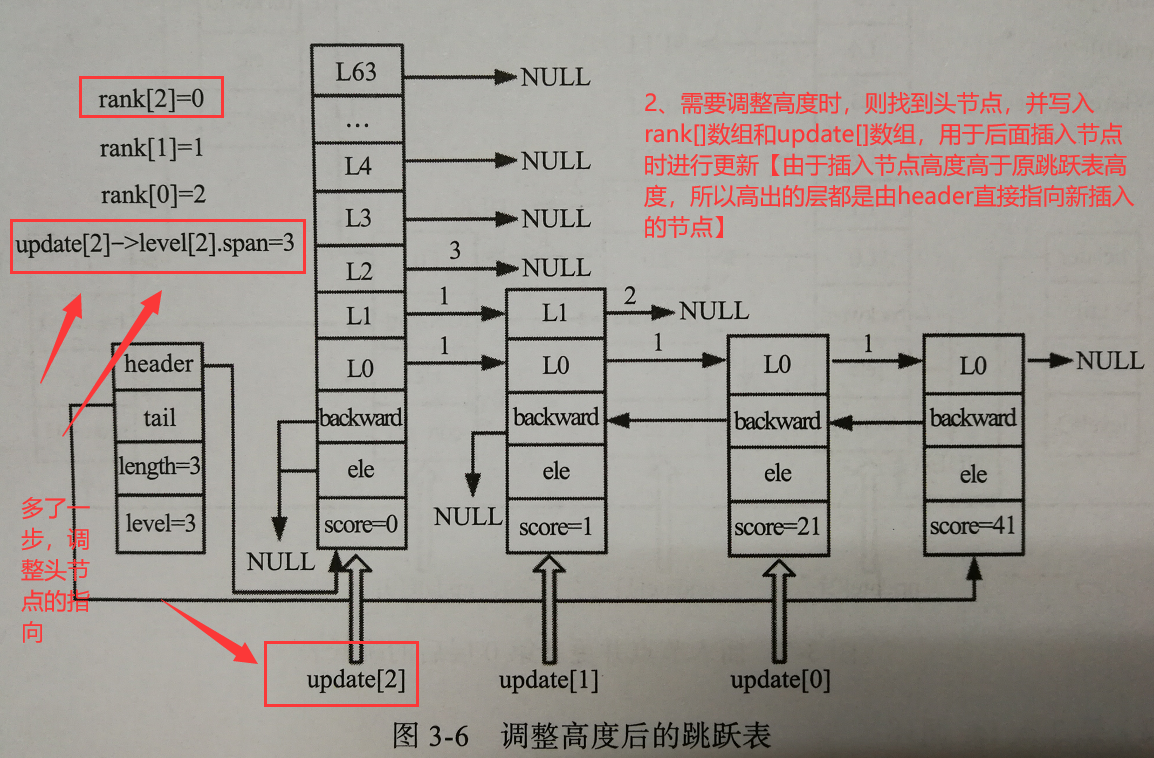
插入节点
经过前面两步,设置好update[ ]和rank[ ]后,我们就可以进行插入节点的操作了:
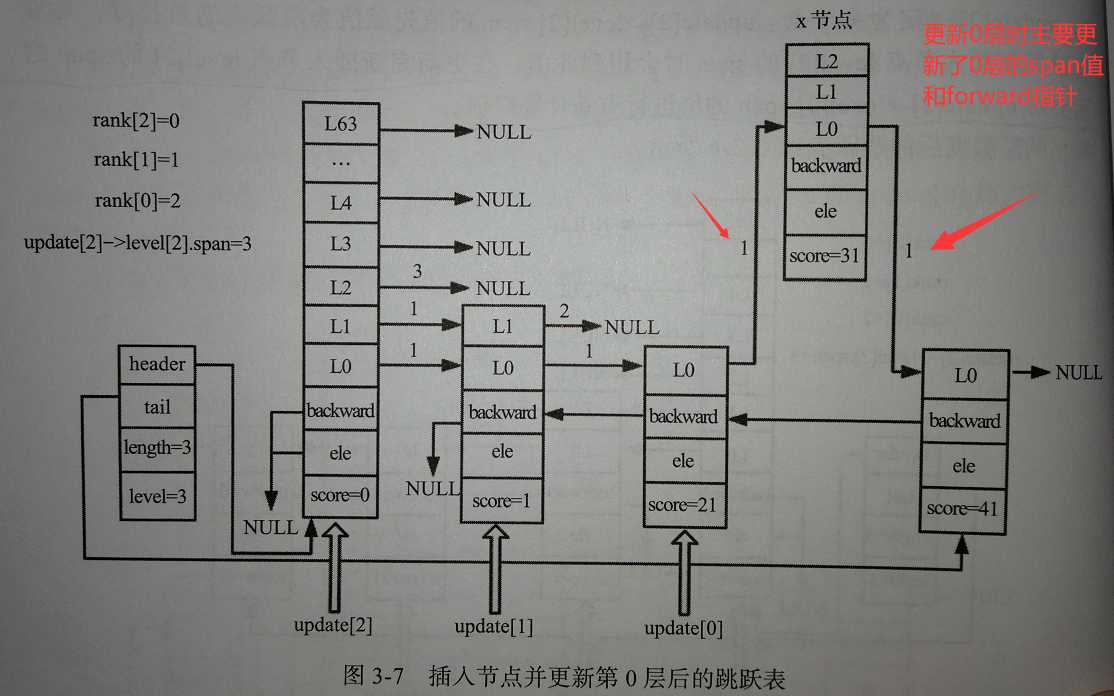

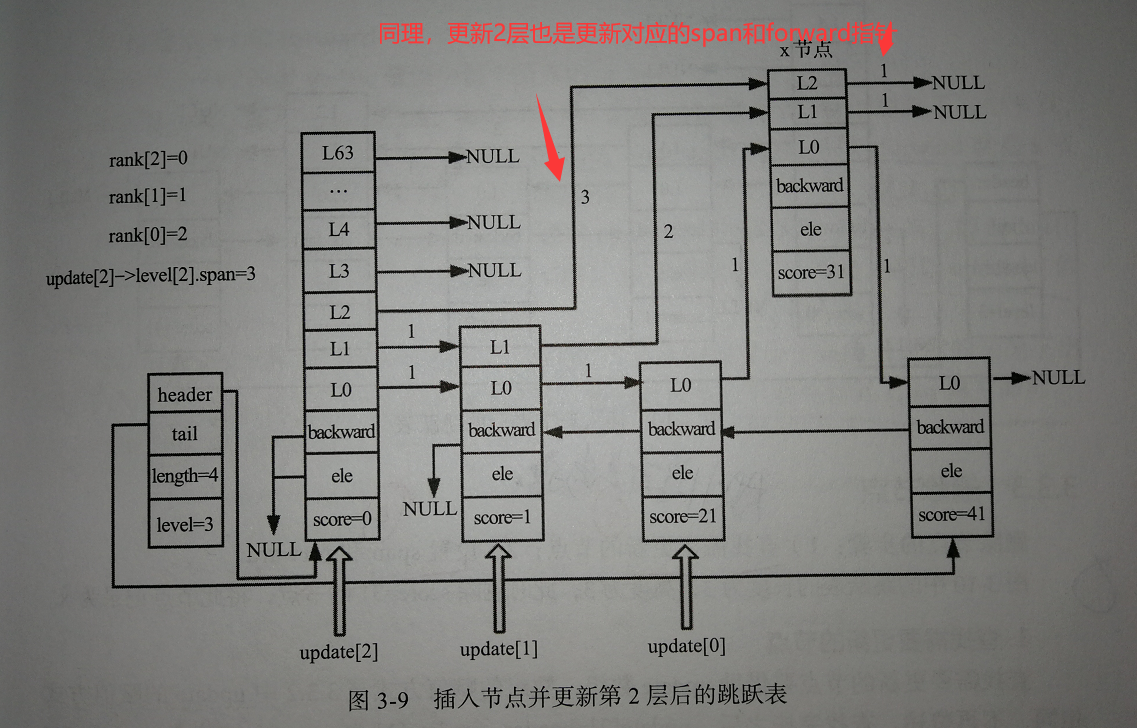
我们可以看出,在插入节点操作时,主要还是在更新被插入节点的level柔性数组,然后再处理好每个节点对应层高与新插入节点之间的关系。
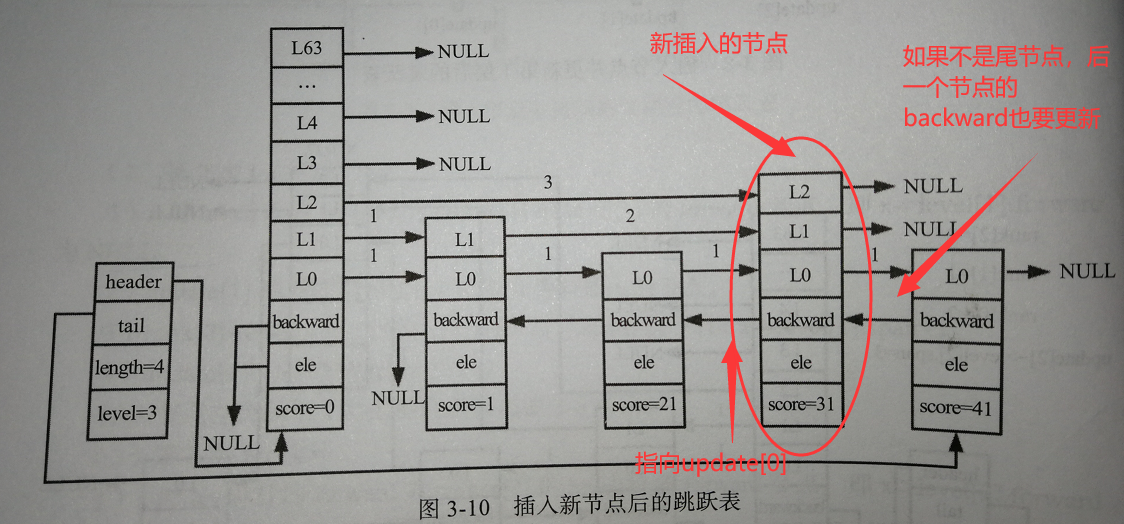
调整backward
根据update[ ]的赋值过程,新插入节点的前一个节点一定是update[0],由于每个节点的后退指针【backward】只有一个,与此节点的层数无关,则:
- 被插入节点的backward指向update[0]
- 如果新插入的节点是最后一个节点,需要指定跳跃表结构的tail【尾节点】指向新插入的节点
- 更新跳跃表的长度+1
六、删除节点
查找需要更新的节点
查找方法与上面类似,也是需要借助update[ ]数组进行记录需要更新的节点:
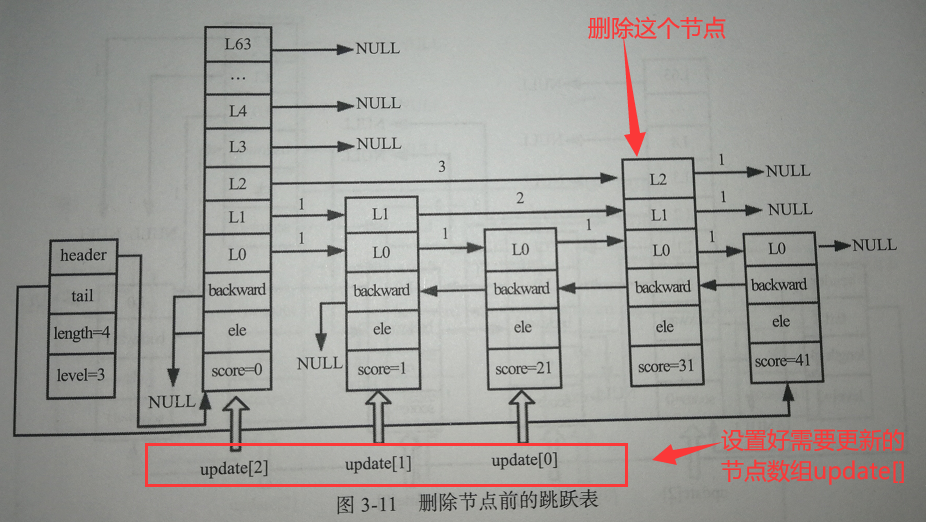
设置span和forward
删除节点前需要设置update[ ]数组中每一个节点的span和forward,有以下几种情况【下面以x来代表需要删除的节点】:
- ① x的第i层的span值为a,update[i]的第i层的span值为b,且update[i]第i层的forward为x时 :
- update[i]的第i层的span :a+b-1
- update[i]的第i层的forward :x节点第i层的forward
- ② update[i]第i层的forward不为x时 :
- update[i]的第i层span :原span-1

更新backward、跳跃表长度、跳跃表高度
更新backward
- x不为最后一个节点 :把0层后一个节点的backward设置成x节点的backward
- x为最后一个节点 :把跳跃表结构的tail指向x的backward
更新跳跃表长度
删除1个节点,跳跃表长度-1
更新跳跃表高度
如果x节点是最高节点,且没有其他节点与之同高,则跳跃表高度-1
七、删除跳跃表
- 从头结点的第0层开始,通过forward指针逐步向后遍历
- 每遇到一个节点便将其内存释放
- 当所有节点的内存都被释放以后,释放跳跃表对象,此时删除跳跃表完成

八、跳跃表的应用
跳跃表主要应用于有序集合的底层实现(有序集合的另一种实现方式为压缩列表)。
Redis的配置文件中关于有序集合底层实现的两个配置
- zset-max-zip-list-entries 128 :zset采用压缩列表时,元素个数最大值,默认值为128。
- zset-max-zip-list-value 64 :zset采用压缩列表时,每个元素的字符串长度最大值,默认值为64。
插入第一个元素
插入第一个元素时,会判断以下两个条件:
- zset-max-zip-list-entries的值是否等于0。
- zset-max-zip-list-value小于要插入元素的字符串长度。
满足任一条件Redis就会采用跳跃表作为有序集合的底层实现,否则采用压缩列表作为底层实现。
PS:一般情况下,默认还是使用压缩列表作为底层实现的。
再次插入元素
再次插入元素,会判断以下两个条件:
- zset中元素的个数大于zset-max-zip-list-entries。
- 插入元素的字符串长度大于zset-max-zip-list-value。
满足任一条件Redis便会将zset的底层实现由压缩列表转为跳跃表。
PS:zset在转为跳跃表之后,即使元素被删除,也不会重新转换为压缩列表。
PS:插入、查找、删除操作的平均时间复杂度均为O(logN),主要时间消耗在定位元素上。
Redis5设计与源码分析读后感(三)跳跃表的更多相关文章
- Redis5设计与源码分析读后感(一)认识Redis
一.初识redis 定义 Redis是一个开源的Key-Value数据库,通常被称为数据结构服务器,其值可以是多种常见的数据格式,且读写性能极高,且所有操作都是原子性的. 高性能的主要原因 1.基于内 ...
- Redis5设计与源码分析读后感(四)压缩列表
一.引言 上一节我们总结了跳跃表的知识,我们知道了有序数组可以用跳跃表实现,也可以用压缩列表来实现,这一篇文章我们来总结一下压缩列表相关的知识. 二.压缩列表简介 定义:压缩列表 ziplist 本质 ...
- Redis5设计与源码分析读后感(二)简单动态字符串SDS
一.引言 学习之前先了解几个概念: SDS定义:简单动态字符串,Redis的基本数据结构之一,用于储存字符串和整型数据. 二进制安全:C语言中用"\0"表示字符串结束,如果字符串本 ...
- Spring MVC源码分析(三):SpringMVC的HandlerMapping和HandlerAdapter的体系结构设计与实现
概述在我的上一篇文章:Spring源码分析(三):DispatcherServlet的设计与实现中提到,DispatcherServlet在接收到客户端请求时,会遍历DispatcherServlet ...
- 一个普通的 Zepto 源码分析(三) - event 模块
一个普通的 Zepto 源码分析(三) - event 模块 普通的路人,普通地瞧.分析时使用的是目前最新 1.2.0 版本. Zepto 可以由许多模块组成,默认包含的模块有 zepto 核心模块, ...
- Koa源码分析(三) -- middleware机制的实现
Abstract 本系列是关于Koa框架的文章,目前关注版本是Koa v1.主要分为以下几个方面: Koa源码分析(一) -- generator Koa源码分析(二) -- co的实现 Koa源码分 ...
- Android源码分析(三)-----系统框架设计思想
一 : 术在内而道在外 Android系统的精髓在源码之外,而不在源码之内,代码只是一种实现人类思想的工具,仅此而已...... 近来发现很多关于Android文章都是以源码的方向入手分析Androi ...
- Backbone源码分析(三)
Backbone源码分析(一) Backbone源码分析(二) Backbone中主要的业务逻辑位于Model和Collection,上一篇介绍了Backbone中的Model,这篇文章中将主要探讨C ...
- Spark RPC框架源码分析(三)Spark心跳机制分析
一.Spark心跳概述 前面两节中介绍了Spark RPC的基本知识,以及深入剖析了Spark RPC中一些源码的实现流程. 具体可以看这里: Spark RPC框架源码分析(二)运行时序 Spark ...
随机推荐
- Kafka Producer源码解析一:整体架构
一.Producer整体架构 Kafka Producer端的架构整体也是一个生产者-消费者模式 Producer线程调用send时,只是将数据序列化后放入对应TopicPartition的Deque ...
- You are using pip version 10.0.1, however version 20.2.2 is available.
在安装第三方库时,出现如下提示: You are using pip version 10.0.1, however version 20.2.2 is available.You should co ...
- 第5篇 Scrum冲刺博客
1.站立式会议 1.1 会议图片 1.2 项目进展 成员 昨日任务 今日计划完成任务 陈忠明 歌曲信息的上传/下载包 歌曲批量下载压缩包 吴茂平 完善评论系统 新消息提醒功能设计 黄海钊 修改代码规范 ...
- vue自定义下拉框组件
创建下拉框组件 Select.vue <template> <div class="selects"> <div :class="{sele ...
- python实现对列表的增删查修操作
#定义一个空列表 list_demo=[] #1,向列表中插入元素 def append_demo(): #第一种使用append,可以在列表末尾添加一个函数 for i in range(2): l ...
- Java后台服务慢优化杂谈
Java后台服务慢优化杂谈 前言 你是否遇到过这样的场景,当我们点击页面某个按钮后,页面一直loading,要等待好几分钟才出结果的画面,有时直接502或504,作为一个后台开发,看到自己开发的系统是 ...
- 大型Kubernetes集群的资源编排优化
背景 云原生这个词想必大家应该不陌生了,容器是云原生的重要基石,而Kubernetes经过这几年的快速迭代发展已经成为容器编排的事实标准了.越来越多的公司不论是大公司还是中小公司已经在他们的生产环境中 ...
- ABP开发框架的技术点分析(1)
ABP是ASP.NET Boilerplate的简称,ABP是一个开源且文档友好的应用程序框架.ABP不仅仅是一个框架,它还提供了一个最徍实践的基于领域驱动设计(DDD)的体系结构模型.ABP框架可以 ...
- IntPtr to bytes
byte[] managedArray = new byte[size]; Marshal.Copy(pnt, managedArray, 0, size);
- Spine学习九 - 冰冻效果
想象这样一个效果,一个人被冰霜攻击命中,然后这个人整个就被冰冻了,那么spine动画要如何实现这个效果呢? 1.首先需要一个Spine动画,这个动画应该是相对静止的,因为人物已经被冰冻了,那么这个人儿 ...